 讓機器人通過一段只有一個人的視頻來模仿學習
讓機器人通過一段只有一個人的視頻來模仿學習
人類和動物在學習新行為時,大部分只需要觀察一次就能學會,然而想讓機器人學習就沒那么容易了。隨著計算機視覺的發展,目前的技術能讓機器人依靠人體姿勢檢測系統,模仿人類的動作進行學習。不過每次都需要人類“做示范”未免有些麻煩,本篇論文的研究人員們想出了新方法:讓機器人通過一段只有一個人的視頻來模仿學習。
此前的研究表明,機器人能通過觀察示范學習一系列復雜的技能,例如倒水、打乒乓球、打開抽屜等。然而,機器人模仿最有效的方法與人類學習有很大的不同:機器人通常需要接到具體的動作示范或遙控操作,人類只需看別人做一遍就能了解。另外,人類還能根據環境變化改變策略,適應新情況。所以,我們怎樣能讓機器人像人類一樣,通過觀察第三方示范進行學習?
從原始視頻中獲得技能存在兩大挑戰。首先,人類演示者和機器人的外觀及形態的差異會帶來系統性的域轉移(domain shift),即對應問題(correspondence problem)。其次,從原始視覺輸入中學習通常需要大量數據,深度學習視覺系統一般要使用數十萬至數百萬的圖像。而在本文中,我們展示了通過基于元學習的單一方法解決這兩個挑戰。
前期準備
該方法建立在之前的工作成果或者元學習的基礎上,我們將對模型元學習算法進行擴展,它能夠處理提供的數據(即人類演示)和評估設置(即機器人動作)之間的域轉移。
元學習算法能快速有效地學習新任務,一般來說,元學習可以看作是發現任務之間存在的結構的功能。當模型從元測試集中提出新任務時,模型可以使用已知結構快速學習。算法(MAML)通過對深度網絡的初始參數設置進行優化來實現這一點。在元訓練之后,根據新任務的數據對學習參數進行微調。
模仿人類
在這一部分,我們將說明機器人一次性模仿人類學習的問題,并介紹我們的試驗方法。從含有人類的視頻中進行學習可以看做是一個推理問題,其目標是推斷機器人的策略參數,它能將先驗知識與少量證據結合來完成任務。為了從只有一個人的視頻中有效學習,我們需要包含著對世界有著豐富視覺和物體理解的先驗知識。
而試驗方法包括兩個階段,在元訓練階段,我們需要利用人類和機器人的動作數據獲取先驗知識,然后通過快速學習模仿動作。這一方法的關鍵部分在于,它可以遷移到其他元學習算法中去。如MAML算法一樣,我們將學習一系列初始參數,在經歷過幾次梯度下降后,模型還能有效地完成新任務。最終用于元目標的算法可以總結為:

在元訓練階段之后,學習到的先驗知識將用于第二階段。當機器人模仿人類的新動作時,必須將先驗知識與新的人類示范動作結合,來推斷解決新任務的策略參數。算法總結為:

時序適應目標學習
為了從人的視頻中學習,我們需要一個適應目標,可以有效地捕捉視頻中的相關信息,比如人的意圖和與任務有關的對象。由于時序卷積在處理時序和數據序列時是有用的,所以我們選擇用一個卷積網絡表示適應目標。效果如圖所示:
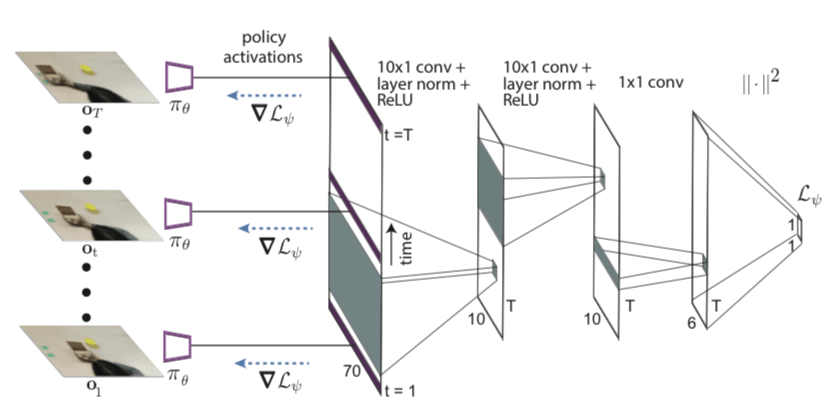
網絡架構
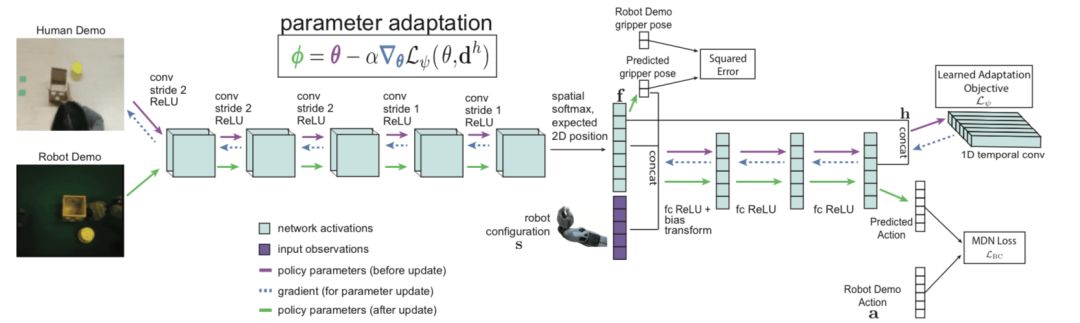
如圖所示,網絡架構是一個卷積神經網絡,將RGB圖像映射到動作分布。卷積網絡從幾個卷積層開始,然后被輸送到通道空間的argmax中,為每個通道提取二維特征點f。接著我們將這些特征點與機器人結構連接在一起,該結構包括夾具上的3個非軸對齊的點。然后,我們將連接的特征點和機器人姿態傳遞給多個完全連接層。
實驗過程
我們的實驗主要想解決三個問題:
我們的方法能否有效地學習先驗知識,讓機器人能夠通過僅有一人的視頻學習操作新物體?
我們的方法能否從新的角度讓機器人模仿人類動作?
我們所提出的方法與元學習方法以及其他方法有何不同?
為了進一步了解我們的方法以及其實用性,我們還要另外評估:
時序適應目標有多重要?
我們的方法能否用于多個機器人平臺,以及用于動作或遙控示范的元訓練?
為了進行評估,我們在7軸的PR2機械臂和Sawyer機器人上進行實驗。
PR2實驗過程
首先是用機械臂PR2進行物體的放置、前推、撿拾等動作的測試,具體過程如圖:
從左至右分別是:物體放置、推動以及撿拾-放下動作。上面一排是人類示范
整個過程的裝置情況是這樣的:
用于拍攝的是一臺智能手機,從中看到的情況是這樣的:
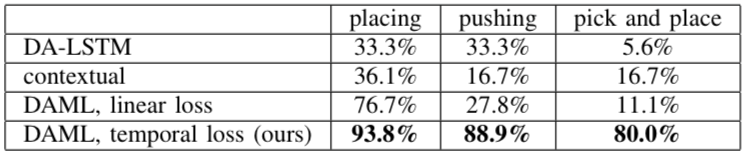
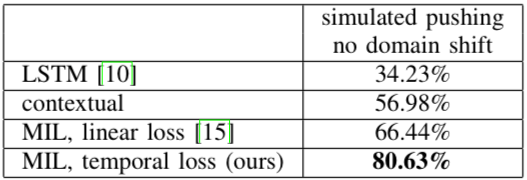
最后,PR2一次學習的評估情況展示在下表中,可以看到成功率大大高于之前的方法:
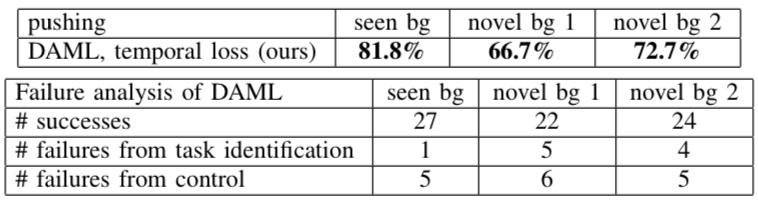
另外,研究人員還統計了PR2在做“推動”時發生的錯誤:
Sawyer實驗過程
實驗的另一個目標是我們的方法能否應用于別的平臺上,于是我們選擇了7個自由度的Sawyer進行驗證。不同與PR2實驗,動作空間將是末端執行器的單個指令姿態,我們將使用均方誤差作為外部的元目標。

最終,在使用時序適應目標的實驗中,成功率比沒有使用的提高了14%,證明了從視頻中學習時融合時間信息的重要性。
實驗的局限性
雖然我們的工作成果能讓機器人從視頻中一次性學習操作新的物體,但是目前的實驗還沒有證明模型能夠一次性學習全新動作。希望未來有更多的數據和更高性能的模型能實現這一目標。
-
機器人
+關注
關注
210文章
28231瀏覽量
206615 -
深度學習
+關注
關注
73文章
5493瀏覽量
120999
原文標題:利用自適應域的元學習讓機器人一次學會人類動作
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論