 dubbo3.0 服務導入導出原理
dubbo3.0 服務導入導出原理
不管是服務導出還是服務引入,都發生在應用啟動過程中,比如:在啟動類上加上 @EnableDubbo 時,該注解上有一個 @DubboComponentScan 注解,@DubboComponentScan 注解 Import 了一個 DubboComponentScanRegistrar,DubboComponentScanRegistrar 中會調用 DubboSpringInitializer.initialize(),該方法中會注冊一個 DubboDeployApplicationListener,而 DubboDeployApplicationListener 會監聽 Spring 容器啟動完成事件 ContextRefreshedEvent,一旦接收到這個事件后,就會開始 Dubbo 的啟動流程,就會執行 DefaultModuleDeployer 的 start() 進行服務導出與服務引入。
在啟動過程中,在做完服務導出與服務引入后,還會做幾件非常重要的事情:
1.導出一個應用元數據服務(就是一個 MetadataService 服務,這個服務也會注冊到注冊中心),或者將應用元數據注冊到元數據中心;
2.生成當前應用的實例信息對象 ServiceInstance,比如:應用名、實例 ip、實例 port,并將實例信息注冊到注冊中心,也就是應用級注冊;
服務導出
當在某個接口的實現類上加上 @DubboService 后,就表示定義了一個 Dubbo 服務,應用啟動時 Dubbo 只要掃描到了 @DubboService,就會解析對應的類,得到服務相關的配置信息,比如:
1.服務的類型,也就是接口,接口名就是服務名;
2.服務的具體實現類,也就是當前類;
3.服務的 version、timeout 等信息,就是 @DubboService 中所定義的各種配置;
解析完服務的配置信息后,就會把這些配置信息封裝成為一個 ServiceConfig 對象,并調用其 export() 進行服務導出,此時一個 ServiceConfig 對象就表示一個Dubbo 服務。
而所謂的服務導出,主要就是完成三件事情:
1.確定服務的最終參數配置;
2.按不同協議啟動對應的 Server(服務暴露);
3.將服務注冊到注冊中心(服務注冊);
確定服務參數
一個 Dubbo 服務,除開服務的名字,也就是接口名,還會有很多其他的屬性,比如:超時時間、版本號、服務所屬應用名、所支持的協議及綁定的端口等眾多信息。
但是,通常這些信息并不會全部在 @DubboService 中進行定義,比如:一個 Dubbo 服務肯定是屬于某個應用的,而一個應用下可以有多個 Dubbo 服務,所以可以在應用級別定義一些通用的配置,比如協議。
在 application.yml 中定義:
dubbo:
application:
name: dubbo-springboot-demo-provider
protocol:
name: tri
port: 20880
表示當前應用下所有的 Dubbo 服務都支持通過 tri 協議進行訪問,并且訪問端口為 20880,所以在進行某個服務的服務導出時,就需要將應用中的這些配置信息合并到當前服務的配置信息中。
另外,除開可以通過 @DubboService 來配置服務,也可以在配置中心對服務進行配置,比如:在配置中心中配置:
dubbo.service.org.apache.dubbo.samples.api.DemoService.timeout=5000
表示當前服務的超時時間為 5s。
所以,在服務導出時,也需要從配置中心獲取當前服務的配置,如果在 @DubboService 中也定義了 timeout,那么就用配置中心的覆蓋掉,配置中心的配置優先級更高。
最終確定出服務的各種參數,這塊內容和 Dubbo2.7 一致。
服務注冊
當確定好了最終的服務配置后,Dubbo 就會根據這些配置信息生成對應的服務 URL,比如:
tri://192.168.65.221:20880/org.apache.dubbo.springboot.demo.DemoService?application=dubbo-springboot-demo-provider&timeout=3000
這個 URL 就表示了一個 Dubbo 服務,服務消費者只要能獲得到這個服務 URL,就知道了關于這個 Dubbo 服務的全部信息,包括服務名、支持的協議、ip、port、各種配置。
確定了服務 URL 之后,服務注冊要做的事情就是把這個服務 URL 存到注冊中心(比如:Zookeeper)中去,說的再簡單一點,就是把這個字符串存到 Zookeeper中去,這個步驟其實是非常簡單的,實現這個功能的源碼在 RegistryProtocol 中的 export() 方法中,最終服務 URL 存在了 Zookeeper 的 /dubbo/ 接口名 /providers 目錄下。
但是服務注冊并不僅僅就這么簡單,既然上面的這個 URL 表示一個服務,并且還包括了服務的一些配置信息,那這些配置信息如果改變了呢?比如:利用 Dubbo管理臺中的動態配置功能(注意,并不是配置中心)來修改服務配置,動態配置可以應用運行過程中動態的修改服務的配置,并實時生效。
如果利用動態配置功能修改了服務的參數,那此時就要重新生成服務 URL 并重新注冊到注冊中心,這樣服務消費者就能及時的獲取到服務配置信息。
而對于服務提供者而言,在服務注冊過程中,還需要能監聽到動態配置的變化,一旦發生了變化,就根據最新的配置重新生成服務 URL,并重新注冊到中心。
應用級注冊
在 Dubbo3.0 之前,Dubbo 是接口級注冊,服務注冊就是把接口名以及服務配置信息注冊到注冊中心中,注冊中心存儲的數據格式大概為:
接口名1:tri://192.168.1.221:20880/接口名1?application=應用名
接口名2:tri://192.168.1.221:20880/接口名2?application=應用名
接口名3:tri://192.168.1.221:20880/接口名3?application=應用名
key 是接口名,value 就是服務 URL,上面的內容就表示現在有一個應用,該應用下有 3 個接口,應用實例部署在 192.168.1.221,此時,如果給該應用增加一個實例,實例 ip 為192.168.1.222,那么新的實例也需要進行服務注冊,會向注冊中心新增 3 條數據:
接口名1:tri://192.168.1.221:20880/接口名1?application=應用名
接口名2:tri://192.168.1.221:20880/接口名2?application=應用名
接口名3:tri://192.168.1.221:20880/接口名3?application=應用名
接口名1:tri://192.168.1.222:20880/接口名1?application=應用名
接口名2:tri://192.168.1.222:20880/接口名2?application=應用名
接口名3:tri://192.168.1.222:20880/接口名3?application=應用名
可以發現,如果一個應用中有 3 個 Dubbo 服務,那么每增加一個實例,就會向注冊中心增加 3 條記錄,那如果一個應用中有 10 個 Dubbo 服務,那么每增加一個實例,就會向注冊中心增加 10 條記錄,注冊中心的壓力會隨著應用實例的增加而劇烈增加。
反過來,如果一個應用有 3 個 Dubbo 服務,5 個實例,那么注冊中心就有 15 條記錄,此時增加一個 Dubbo 服務,那么注冊中心就會新增 5 條記錄,注冊中心的壓力也會劇烈增加。
注冊中心的數據越多,數據就變化的越頻繁,比如:修改服務的 timeout,那么對于注冊中心和應用都需要消耗資源用來處理數據變化。
所以為了降低注冊中心的壓力,Dubbo3.0 支持了應用級注冊,同時也兼容接口級注冊,用戶可以逐步遷移成應用級注冊,而一旦采用應用級注冊,最終注冊中心的數據存儲就變成為:
應用名:192.168.1.221:20880
應用名:192.168.1.222:20880
表示在注冊中心中,只記錄應用所對應的實例信息(IP + 綁定的端口),這樣只有一個應用的實例增加了,那么注冊中心的數據才會增加,而不關心一個應用中到底有多少個 Dubbo 服務。
這樣帶來的好處就是,注冊中心存儲的數據變少了,注冊中心中數據的變化頻率變小了,并且使用應用級注冊,使得 Dubbo3 能實現與異構微服務體系如:Spring Cloud、Kubernetes Service 等在地址發現層面更容易互通, 為連通 Dubbo 與其他微服務體系提供可行方案。
應用級注冊帶來了好處,但是對于 Dubbo 來說又出現了一些新的問題,比如:原本,服務消費者可以直接從注冊中心就知道某個 Dubbo 服務的所有服務提供者以及相關的協議、ip、port、配置等信息,那現在注冊中心上只有 ip、port,那對于服務消費者而言:服務消費者怎么知道現在它要用的某個 Dubbo 服務,也就是某個接口對應的應用是哪個呢?
對于這個問題,在進行服務導出的過程中,會在 Zookeeper 中存一個映射關系,在服務導出的最后一步,在 ServiceConfig 的 exported() 方法中,會保存這個映射關系:接口名:應用名。這個映射關系存在 Zookeeper 的 /dubbo/mapping 目錄下,存了這個信息后,消費者就能根據接口名找到所對應的應用名了。
消費者知道了要使用的 Dubbo 服務在哪個應用,那也就能從注冊中心中根據應用名查到應用的所有實例信息( ip + port ),也就是可以發送方法調用請求了,但是在真正發送請求之前,還得知道服務的配置信息,對于消費者而言,它得知道當前要調用的這個 Dubbo 服務支持什么協議、timeout 是多少,那服務的配置信息從哪里獲取呢?
之前的服務配置信息是直接從注冊中心就可以獲取到的,就是服務 URL 后面,但是現在不行了,現在需要從服務提供者的元數據服務獲取,前面提到過,在應用啟動過程中會進行服務導出和服務引入,然后就會暴露一個應用元數據服務,其實這個應用元數據服務就是一個 Dubbo 服務(Dubbo 框架內置的,自己實現的 ),消費者可以調用這個服務來獲取某個應用中所提供的所有 Dubbo 服務以及服務配置信息,這樣也就能知道服務的配置信息了。
知道了應用注冊的好處,以及相關問題的解決方式,那么來看它到底是如何實現的。
首先,我們可以通過配置 dubbo.application.register-mode 來控制:
1.instance:表示只進行應用級注冊;
2.interface:表示只進行接口級注冊;
3.all:表示應用級注冊和接口級注冊都進行,默認;
不管是什么注冊,都需要存數據到注冊中心,而 Dubbo3 的源碼實現中會根據所配置的注冊中心生成兩個 URL(不是服務 URL,可以理解為注冊中心 URL,用來訪問注冊中心的):
1.service-discovery-registry://127.0.0.1:2181/org.apache.dubbo.registry.RegistryService?application=dubbospringboot-demoprovider& dubbo=2.0.2&pid=13072&qos.enable=false?istry=zookeeper×tamp=1651755501660
2.registry://127.0.0.1:2181/org.apache.dubbo.registry.RegistryService?application=dubbo-springboot-demoprovider& dubbo=2.0.2&pid=13072&qos.enable=false?istry=zookeeper×tamp=1651755501660
這兩個 URL 只有 schema 不一樣,一個是 service-discovery-registry,一個是 registry,而 registry 是 Dubbo3 之前就存在的,也就代表接口級服務注冊,而service-discovery-registry 就表示應用級服務注冊。
在服務注冊相關的源碼中,當調用 RegistryProtocol 的 export() 方法處理 registry:// 時,會利用 ZookeeperRegistry 把服務 URL 注冊到 Zookeeper 中去,這就是接口級注冊。
而類似,當調用 RegistryProtocol 的 export() 方法處理 service-discovery-registry:// 時,會利用 ServiceDiscoveryRegistry 來進行相關邏輯的處理,那是不是就是在這里把應用信息注冊到注冊中心去呢?并沒有這么簡單。
1.首先,不可能每導出一個服務就進行一次應用注冊,太浪費了,應用注冊只要做一次就行了
2.其次,如果一個應用支持了多個端口,那么應用注冊時只要挑選其中一個端口作為實例端口就可以了(該端口只要能接收到數據就行)
3.前面提到,應用啟動過程中要暴露應用元數據服務,所以在此處也還是要收集當前所暴露的服務配置信息,以提供給應用元數據服務
所以 ServiceDiscoveryRegistry 在注冊一個服務 URL 時,并不會往注冊中心存數據,而只是把服務 URL 存到到一個 MetadataInfo 對象中,MetadataInfo 對象中就保存了當前應用中所有的 Dubbo 服務信息:服務名、支持的協議、綁定的端口、timeout 等。
前面提到過,在應用啟動的最后,才會進行應用級注冊,而應用級注冊就是當前的應用實例上相關的信息存入注冊中心,包括:
1.應用的名字;
2.獲取應用元數據的方式;
3.當前實例的 ip 和 port;
4.當前實例支持哪些協議以及對應的 port;
比如:
{
"name":"dubbo-springboot-demo-provider",
"id":"192.168.65.221:20882",
"address":"192.168.65.221",
"port":20882,
"sslPort":null,
"payload":{
"@class":"org.apache.dubbo.registry.zookeeper.ZookeeperInstance",
"id":"192.168.65.221:20882",
"name":"dubbo-springboot-demo-provider",
"metadata":{
"dubbo.endpoints":"[{"port":20882,"protocol":"dubbo"},{"port":50051,"protocol":"tri"}]",
"dubbo.metadata-service.url-params":"{"connections":"1","version":"1.0.0","dubbo":"2.0.2","side":"provider","port":"20882","protocol":"dubbo"}",
"dubbo.metadata.revision":"65d5c7b814616ab10d32860b54781686",
"dubbo.metadata.storage-type":"local"
}
},
"registrationTimeUTC":1654585977352,
"serviceType":"DYNAMIC",
"uriSpec":null
}
一個實例上可能支持多個協議以及多個端口,那如何確定實例的 ip 和端口呢?
答案是:獲取 MetadataInfo 對象中保存的所有服務 URL,優先取 dubbo 協議對應 ip 和 port,沒有 dubbo 協議則所有服務 URL 中的第一個 URL 的 ip 和 port。
另外一個協議一般只會對應一個端口,但是如何就是對應了多個,比如:
dubbo:
application:
name: dubbo-springboot-demo-provider
protocols:
p1:
name: dubbo
port: 20881
p2:
name: dubbo
port: 20882
p3:
name: tri
port: 50051
如果是這樣,最終存入 endpoint 中的會保證一個協議只對應一個端口,另外那個將被忽略,最終服務消費者在進行服務引入時將會用到這個 endpoint 信息。
確定好實例信息后之后,就進行最終的應用注冊了,就把實例信息存入注冊中心的 /services/應用名,目錄下:
?

??
可以看出 services 節點下存的是應用名,應用名的節點下存的是實例 ip 和實例 port,而 ip 和 port 這個節點中的內容就是實例的一些基本信息。
額外,我們可以配置 dubbo.metadata.storage-type,默認時 local,可以通過配置改為 remote:
dubbo:
application:
name: dubbo-springboot-demo-provider
metadata-type: remote
這個配置其實跟應用元數據服務有關系:
1.如果為 local,那就會啟用應用元數據服務,最終服務消費者就會調用元數據服務獲取到應用元數據信息;
2.如果為 remote,那就不會暴露應用元數據服務,那么服務消費者從元數據中心獲取應用元數據;
在 Dubbo2.7 中就有了元數據中心,它其實就是用來減輕注冊中心的壓力的,Dubbo 會把服務信息完整的存一份到元數據中心,元數據中心也可以用 Zookeeper來實現,在暴露完元數據服務之后,在注冊實例信息到注冊中心之前,就會把 MetadataInfo 存入元數據中心,比如:
?
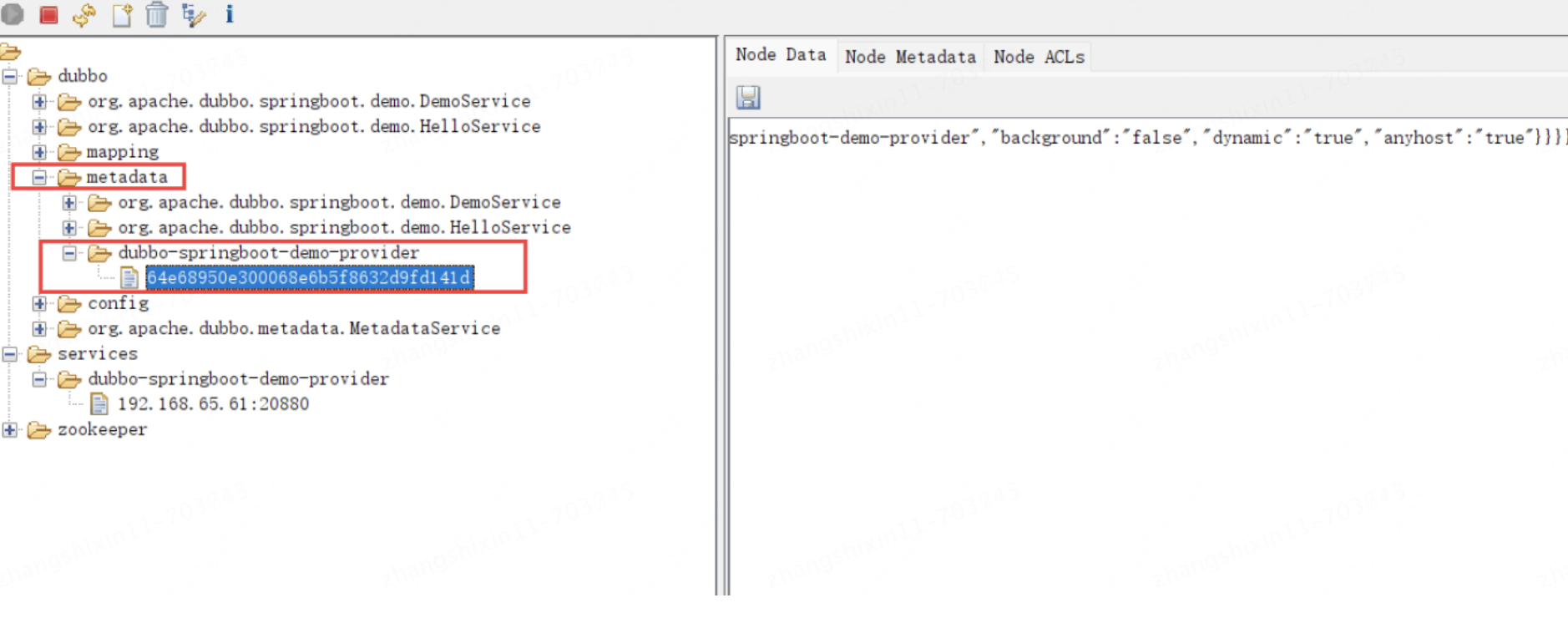
??
節點內容為:
{
"app":"dubbo-springboot-demo-provider",
"revision":"64e68950e300068e6b5f8632d9fd141d",
"services":{
"org.apache.dubbo.springboot.demo.HelloService:tri":{
"name":"org.apache.dubbo.springboot.demo.HelloService",
"protocol":"tri",
"path":"org.apache.dubbo.springboot.demo.HelloService",
"params":{
"side":"provider",
"release":"",
"methods":"sayHello",
"deprecated":"false",
"dubbo":"2.0.2",
"interface":"org.apache.dubbo.springboot.demo.HelloService",
"service-name-mapping":"true",
"generic":"false",
"metadata-type":"remote",
"application":"dubbo-springboot-demo-provider",
"background":"false",
"dynamic":"true",
"anyhost":"true"
}
},
"org.apache.dubbo.springboot.demo.DemoService:tri":{
"name":"org.apache.dubbo.springboot.demo.DemoService",
"protocol":"tri",
"path":"org.apache.dubbo.springboot.demo.DemoService",
"params":{
"side":"provider",
"release":"",
"methods":"sayHelloStream,sayHello,sayHelloServerStream",
"deprecated":"false",
"dubbo":"2.0.2",
"interface":"org.apache.dubbo.springboot.demo.DemoService",
"service-name-mapping":"true",
"generic":"false",
"metadata-type":"remote",
"application":"dubbo-springboot-demo-provider",
"background":"false",
"dynamic":"true",
"anyhost":"true"
}
}
}
}
這里面就記錄了當前實例上提供了哪些服務以及對應的協議,注意并沒有保存對應的端口......,所以后面服務消費者得利用實例信息中的 endpoint,因為endpoint 中記錄了協議對應的端口....
其實元數據中心和元數據服務提供的功能是一樣的,都可以用來獲取某個實例的 MetadataInfo,上面中的 UUID 表示實例編號,只不過元數據中心是集中式的,元數據服務式分散在各個提供者實例中的,如果整個微服務集群壓力不大,那么效果差不多,如果微服務集群壓力大,那么元數據中心的壓力就大,此時單個元數據服務就更適合,所以默認也是采用的元數據服務。
至此,應用級服務注冊的原理就分析完了,總結一下:
1.在導出某個 Dubbo 服務 URL 時,會把服務 URL 存入 MetadataInfo 中;
2.導出完某個 Dubbo 服務后,就會把服務接口名:應用名存入元數據中心(可以用 Zookeeper 實現);
3.導出所有服務后,完成服務引入后;
4.判斷要不要啟動元數據服務,如果要就進行導出,固定使用 Dubbo 協議;
5.將 MetadataInfo 存入元數據中心;
6.確定當前實例信息(應用名、ip、port、endpoint);
7.將實例信息存入注冊中心,完成應用注冊;
服務暴露
服務暴露就是根據不同的協議啟動不同的 Server,比如:dubbo 和 tri 協議啟動的都是 Netty,像 Dubbo2.7 中的 http 協議啟動的就是 Tomcat,這塊在服務調用的時候再來分析。
服務引入
@DubboReference
private DemoService demoService;
需要利用 @DubboReference 注解來引入某一個 Dubbo 服務,應用在啟動過程中,進行完服務導出之后,就會進行服務引入,屬性的類型就是一個 Dubbo 服務接口,而服務引入最終要做到的就是給這個屬性賦值一個接口代理對象。
在 Dubbo2.7 中,只有接口級服務注冊,服務消費者會利用接口名從注冊中心找到該服務接口所有的服務 URL,服務消費者會根據每個服務 URL 的 protocol、ip、port 生成對應的 Invoker 對象,比如生成 TripleInvoker、DubboInvoker 等,調用這些 Invoker 的 invoke() 方法就會發送數據到對應的 ip、port,生成好所有的 Invoker 對象之后,就會把這些 Invoker 對象進行封裝并生成一個服務接口的代理對象,代理對象調用某個方法時,會把所調用的方法信息生成一個 Invocation 對象,并最終通過某一個 Invoker 的 invoke() 方法把 Invocation 對象發送出去,所以代理對象中的 Invoker 對象是關鍵,服務引入最核心的就是要生成這些 Invoker 對象。
Invoker 是非常核心的一個概念,也有非常多種類,比如:
1.TripleInvoker:表示利用 tri 協議把 Invocation 對象發送出去;
2.DubboInvoker:表示利用 dubbo 協議把 Invocation 對象發送出去;
3.ClusterInvoker:有負載均衡功能;
4.MigrationInvoker:遷移功能,Dubbo3.0 新增的
像 TripleInvoker 和 DubboInvoker 對應的就是具體服務提供者,包含了服務提供者的 ip 地址和端口,并且會負責跟對應的 ip 和 port 建立 Socket 連接,后續就可以基于這個 Socket 連接并按協議格式發送 Invocation 對象。
比如現在引入了 DemoService 這個服務,那如果該服務支持:
1.一個 tri 協議,綁定的端口為 20881;
2.一個 tri 協議,綁定的端口為 20882;
3.一個 dubbo 協議,綁定的端口為 20883;
那么在服務消費端這邊,就會生成兩個 TripleInvoker 和一個 DubboInvoker,代理對象執行方法時就會進行負載均衡選擇其中一個 Invoker 進行調用。
接口級服務引入
在服務導出時,Dubbo3.0 默認情況下即會進行接口級注冊,也會進行應用級注冊,目的就是為了兼容服務消費者應用,用的還是 Dubbo2.7,用 Dubbo2.7 就只能老老實實的進行接口級服務引入。
接口級服務引入核心就是要找到當前所引入的服務有哪些服務 URL,然后根據每個服務 URL 生成對應的 Invoker,流程為:
1.首先,根據當前引入的服務接口生成一個 RegistryDirectory 對象,表示動態服務目錄,用來查詢并緩存服務提供者信息;
2.RegistryDirectory 對象會根據服務接口名去注冊中心,比如:Zookeeper 中的 /dubbo/服務接口名/providers/ 節點下查找所有的服務 URL;
3.根據每個服務 URL 生成對應的 Invoker 對象,并把 Invoker 對象存在 RegistryDirectory 對象的 invokers 屬性中;
4.RegistryDirectory 對象也會監聽 /dubbo/服務接口名/providers/ 節點的數據變化,一旦發生了變化就要進行相應的改變;
5.最后將 RegistryDirectory 對象生成一個 ClusterInvoker 對象,到時候調用 ClusterInvoker 對象的 invoke() 方法就會進行負載均衡選出某一個 Invoker 進行調用;
?

??
應用級服務引入
在 Dubbo 中,應用級服務引入,并不是指引入某個應用,這里和 SpringCloud 是有區別的,在 SpringCloud 中,服務消費者只要從注冊中心找到要調用的應用的所有實例地址就可以了,但是在 Dubbo 中找到應用的實例地址還遠遠不夠,因為在 Dubbo 中是直接使用的接口,所以在 Dubbo 中就算是應用級服務引入,最終還是得找到服務接口有哪些服務提供者。
所以,對于服務消費者而言,不管是使用接口級服務引入,還是應用級服務引入,最終的結果應該得是一樣的,也就是某個服務接口的提供者 Invoker 是一樣的,不可能使用應用級服務引入得到的 Invoker 多一個或少一個,但是!!!,目前會有情況不一致,就是一個協議有多個端口時,比如在服務提供者應用這邊支持:
dubbo:
application:
name: dubbo-springboot-demo-provider
protocols:
p1:
name: dubbo
port: 20881
p2:
name: tri
port: 20882
p3:
name: tri
port: 50051
那么在消費端進行服務引入時,比如:引入 DemoService 時,接口級服務引入會生成 3 個 Invoker(2個 TripleInvoker,1個DubboInvoker),而應用級服務引入只會生成 2 個 Invoker(1個TripleInvoker,1個DubboInvoker),原因就是在進行應用級注冊時是按照一個協議對應一個port存的。
那既然接口級服務引入和應用級服務引入最終的結果差不多,可能就不理解了,那應用級服務引入有什么好處呢?要知道應用級服務引入和應用級服務注冊是對應,服務提供者應用如果只做應用級注冊,那么對應的服務消費者就只能進行應用級服務引入,好處就是前面所說的,減輕了注冊中心的壓力等,那么帶來的影響就是服務消費者端尋找服務 URL 的邏輯更復雜了。
只要找到了當前引入服務對應的服務 URL,然后生成對應的 Invoker,并最終生成一個 ClusterInvoker。
在進行應用級服務引入時:
1.首先,根據當前引入的服務接口生成一個 ServiceDiscoveryRegistryDirectory 對象,表示動態服務目錄,用來查詢并緩存服務提供者信息;
2.根據接口名去獲取 /dubbo/mapping/服務接口名節點的內容,拿到的就是該接口所對應的應用名;
3.有了應用名之后,再去獲取 /services/應用名節點下的實例信息;
4.依次遍歷每個實例,每個實例都有一個編號 revision
5.根據 metadata-type 進行判斷如果是 local:則調用實例上的元數據服務獲取應用元數據(MetadataInfo);如果是 remote:則根據應用名從元數據中心獲取應用元數據(MetadataInfo);
6.獲取到應用元數據之后就進行緩存,key 為 revision,MetadataInfo 對象為 value
7.這里為什么要去每個實例上獲取應用的元數據信息呢?因為有可能不一樣,雖然是同一個應用,但是在運行不同的實例的時候,可以指定不同的參數,比如不同的協議,不同的端口,雖然在生產上基本不會這么做,但是 Dubbo 還是支持了這種情況
8.根據從所有實例上獲取到的 MetadataInfo 以及 endpoint 信息,就能知道所有實例上所有的服務 URL(注意:一個接口+一個協議+一個實例 : 對應一個服務URL)
9.拿到了這些服務 URL 之后,就根據當前引入服務的信息進行過濾,會根據引入服務的接口名+協議名,消費者可以在 @DubboReference 中指定協議,表示只使用這個協議調用當前服務,如果沒有指定協議,那么就會去獲取 tri、dubbo、rest 這三個協議對應的服務 URL(Dubbo3.0 默認只支持這三個協議)
10.這樣,經過過濾之后,就得到了當前所引入的服務對應的服務 URL 了
11.根據每個服務 URL 生成對應的 Invoker 對象,并把 Invoker 對象存在 ServiceDiscoveryRegistryDirectory 對象的 invokers 屬性中
12.最后將 ServiceDiscoveryRegistryDirectory 對象生成一個 ClusterInvoker 對象,到時候調用 ClusterInvoker 對象的 invoke() 方法就會進行負載均衡選出某一個 Invoker 進行調用
MigrationInvoker 的生成
上面分析了接口級服務引入和應用級服務引入,最終都是得到某個服務對應的服務提供者 Invoker,那最終進行服務調用時,到底該怎么選擇呢?
所以在 Dubbo3.0 中,可以配置:
# dubbo.application.service-discovery.migration 僅支持通過 -D 以及 全局配置中心 兩種方式進行配置。
dubbo.application.service-discovery.migration=APPLICATION_FIRST
# 可選值
# FORCE_INTERFACE,強制使用接口級服務引入
# FORCE_APPLICATION,強制使用應用級服務引入
# APPLICATION_FIRST,智能選擇是接口級還是應用級,默認就是這個
對于前兩種強制的方式,沒什么特殊,就是上面走上面分析的兩個過程,沒有額外的邏輯,那對于 APPLICATION_FIRST 就需要有額外的邏輯了,也就是 Dubbo 要判斷,當前所引入的這個服務,應該走接口級還是應用級,這該如何判斷呢?
事實上,在進行某個服務的服務引入時,會統一利用 InterfaceCompatibleRegistryProtocol 的 refer 來生成一個 MigrationInvoker 對象,在 MigrationInvoker 中有三個屬性:
private volatile ClusterInvoker invoker; // 用來記錄接口級ClusterInvoker
private volatile ClusterInvoker serviceDiscoveryInvoker; // 用來記錄應用級的ClusterInvoker
private volatile ClusterInvoker currentAvailableInvoker; // 用來記錄當前使用的ClusterInvoker,要么是接口級,要么應用級
一開始構造出來的 MigrationInvoker 對象中三個屬性都為空,接下來會利用 MigrationRuleListener 來處理 MigrationInvoker 對象,也就是給這三個屬性賦值。
在 MigrationRuleListener 的構造方法中,會從配置中心讀取 DUBBO_SERVICEDISCOVERY_MIGRATION 組下面的"當前應用名+.migration"的配置項,配置項為 yml 格式,對應的對象為 MigrationRule,也就是可以配置具體的遷移規則,比如:某個接口或某個應用的 MigrationStep(FORCE_INTERFACE、APPLICATION_FIRST、FORCE_APPLICATION),還可以配置 threshold,表示一個閾值,比如:配置為 2,表示應用級 Invoker 數量是接口級 Invoker 數量的兩倍時才使用應用級 Invoker,不然就使用接口級數量,可以參考:https://cn.dubbo.apache.org/zh/docs/advanced/migration-invoker/
如果沒有配置遷移規則,則會看當前應用中是否配置了 migration.step,如果沒有,那就從全局配置中心讀取 dubbo.application.service-discovery.migration 來獲取 MigrationStep,如果也沒有配置,那 MigrationStep 默認為 APPLICATION_FIRST
如果沒有配置遷移規則,則會看當前應用中是否配置了 migration.threshold,如果沒有配,則 threshold 默認為 -1。
在應用中可以這么配置:
dubbo:
application:
name: dubbo-springboot-demo-consumer
parameters:
migration.step: FORCE_APPLICATION
migration.threshold: 2
確定了 step 和 threshold 之后,就要真正開始給 MigrationInvoker 對象中的三個屬性賦值了,先根據 step 調用不同的方法
switch (step) {
case APPLICATION_FIRST:
// 先進行接口級服務引入得到對應的ClusterInvoker,并賦值給invoker屬性
// 再進行應用級服務引入得到對應的ClusterInvoker,并賦值給serviceDiscoveryInvoker屬性
// 再根據兩者的數量判斷到底用哪個,并且把確定的ClusterInvoker賦值給currentAvailableInvoker屬性
migrationInvoker.migrateToApplicationFirstInvoker(newRule);
break;
case FORCE_APPLICATION:
// 只進行應用級服務引入得到對應的ClusterInvoker,并賦值給serviceDiscoveryInvoker和currentAvailableInvoker屬性
success = migrationInvoker.migrateToForceApplicationInvoker(newRule);
break;
case FORCE_INTERFACE:
default:
// 只進行接口級服務引入得到對應的ClusterInvoker,并賦值給invoker和currentAvailableInvoker屬性
success = migrationInvoker.migrateToForceInterfaceInvoker(newRule);
}
這里只需要分析當 step 為 APPLICATION_FIRST 時,是如何確定最終要使用的 ClusterInvoker 的。
得到了接口級 ClusterInvoker 和應用級 ClusterInvoker 之后,就會利用 DefaultMigrationAddressComparator 來進行判斷:
1.如果應用級 ClusterInvoker 中沒有具體的 Invoker,那就表示只能用接口級 Invoker
2.如果接口級 ClusterInvoker 中沒有具體的 Invoker,那就表示只能用應用級 Invoker
3.如果應用級 ClusterInvoker 和接口級 ClusterInvoker 中都有具體的 Invoker,則獲取對應的 Invoker 個數
4.如果在遷移規則和應用參數中都沒有配置 threshold,那就讀取全局配置中心的 dubbo.application.migration.threshold 參數,如果也沒有配置,則threshold 默認為 0(不是-1了)
5.用應用級 Invoker 數量 / 接口級 Invoker 數量,得到的結果如果大于等于 threshold,那就用應用級 ClusterInvoker,否則用接口級 ClusterInvoker
threshold 默認為 0,那就表示在既有應用級 Invoker 又有接口級 Invoker 的情況下,就一定會用應用級 Invoker,兩個正數相除,結果肯定為正數,當然你自己可以控制 threshold,如果既有既有應用級 Invoker 又有接口級 Invoker 的情況下,你想在應用級 Invoker 的個數大于接口級 Invoker 的個數時采用應用級Invoker,那就可以把 threshold 設置為 1,表示個數相等,或者個數相除之后的結果大于 1 時用應用級 Invoker,否者用接口級 Invoker
這樣 MigrationInvoker 對象中的三個數據就能確定好值了,和在最終的接口代理對象執行某個方法時,就會調用 MigrationInvoker 對象的 invoke,在這個invoke 方法中會直接執行 currentAvailableInvoker 對應的 invoker 的 invoker 方法,從而進入到了接口級 ClusterInvoker 或應用級 ClusterInvoker 中,從而進行負載均衡,選擇出具體的 DubboInvoer 或 TripleInvoker,完成真正的服務調用。
服務調用底層原理
在 Dubbo2.7 中,默認的是 Dubbo 協議,因為 Dubbo 協議相比較于 Http1.1 而言,Dubbo 協議性能上是要更好的。
但是 Dubbo 協議自己的缺點就是不通用,假如現在通過 Dubbo 協議提供了一個服務,那如果想要調用該服務就必須要求服務消費者也要支持 Dubbo 協議,比如想通過瀏覽器直接調用 Dubbo 服務是不行的,想通過 Nginx 調 Dubbo 服務也是不行得。
而隨著企業的發展,往往可能會出現公司內部使用多種技術棧,可能這個部門使用 Dubbo,另外一個部門使用 Spring Cloud,另外一個部門使用 gRPC,那此時部門之間要想相互調用服務就比較復雜了,所以需要一個通用的、性能也好的協議,這就是 Triple 協議。
Triple 協議是基于 Http2 協議的,也就是在使用 Triple 協議發送數據時,會按 HTTP2 協議的格式來發送數據,而 HTTP2 協議相比較于 HTTP1 協議而言,HTTP2是 HTTP1 的升級版,完全兼容 HTTP1,而且 HTTP2 協議從設計層面就解決了 HTTP1 性能低的問題。
另外,Google 公司開發的 gRPC,也基于的 HTTP2,目前 gRPC 是云原生事實上協議標準,包括 k8s/etcd 等都支持 gRPC 協議。
所以 Dubbo3.0 為了能夠更方便的和 k8s 進行通信,在實現 Triple 的時候也兼容了 gRPC,也就是可以用 gPRC 的客戶端調用 Dubbo3.0 所提供的 triple 服務,也可以用 triple 服務調用 gRPC 的服務。
Triple 的底層原理分析
就是因為 HTTP2 中的數據幀機制,Triple 協議才能支持 UNARY、SERVER_STREAM、BI_STREAM 三種模式。
1.UNARY:就是最普通的,服務端只有在接收到完請求包括的所有的 HEADERS 幀和 DATA 幀之后(通過調用 onCompleted() 發送最后一個 DATA 幀),才會處理數據,客戶端也只有接收完響應包括的所有的 HEADERS 幀和 DATA 幀之后,才會處理響應結果。
2.SERVER_STREAM:服務端流,特殊的地方在于,服務端在接收完請求包括的所有的 DATA 幀之后,才會處理數據,不過在處理數據的過程中,可以多次發送響應 DATA 幀(第一個 DATA 幀發送之前會發送一個 HEADERS 幀),客戶端每接收到一個響應 DATA 幀就可以直接處理該響應 DATA 幀,這個模式下,客戶端只能發一次數據,但能多次處理響應 DATA 幀。
3.BI_STREAM:雙端流,或者客戶端流,特殊的地方在于,客戶端可以控制發送多個請求 DATA 幀(第一個 DATA 幀發送之前會發送一個 HEADERS 幀),服務端會不斷的接收到請求 DATA 幀并進行處理,并且及時的把處理結果作為響應 DATA 幀發送給客戶端(第一個 DATA 幀發送之前會發送一個 HEADERS 幀),而客戶端每接收到一個響應結果 DATA 幀也會直接處理,這種模式下,客戶端和服務端都在不斷的接收和發送 DATA 幀并進行處理,注意請求 HEADER 幀和響應 HEADERS 幀都只發了一個。
Triple 請求調用和響應處理
創建一個 Stream 的前提是先得有一個 Socket 連接,所以我們得先知道 Socket 連接是在哪創建的。
在服務提供者進行服務導出時,會按照協議以及對應的端口啟動 Server,比如:Triple 協議就會啟動 Netty 并綁定指定的端口,等待 Socket 連接,在進行服務消費者進行服務引入的過程中,會生成 TripleInvoker 對象,在構造 TripleInvoker 對象的構造方法中,會利用 ConnectionManager 創建一個 Connection 對象,而Connection 對象中包含了一個 Bootstrap 對象(Netty 中用來建立 Socket 連接的),不過以上都只是創建對象,并不會真正和服務去建立 Socket 連接,所以在生成 TripleInvoker 對象過程中不會真正去創建 Socket 連接,那什么時候創建的呢?
當我們在服務消費端執行以下代碼時:demoService.sayHello("habit")
demoService 是一個代理對象,在執行方法的過程中,最終會調用 TripleInvoker 的 doInvoke() 方法,在 doInvoke() 方法中,會利用 Connection 對象來判斷Socket 連接是否可用,如果不可用并且沒有初始化,那就會創建 Socket 連接。
一個 Connection 對象就表示一個 Socket 連接,在 TripleInvoker 對象中也只有一個 Connection 對象,也就是一個 TripleInvoker 對象只對應一個 Socket 連接,這個和 DubboInvoker 不太一樣,一個 DubboInvoker 中可以有多個 ExchangeClient,每個 ExchangeClient 都會與服務端創建一個 Socket 連接,所以一個DubboInvoker 可以對應多個 Socket 連接,當然多個 Socket 連接的目的就是提高并發,不過在 TripleInvoker 對象中就不需要這么來設計了,因為可以 Stream機制來提高并發。
以上,我們知道了,當我們利用服務接口的代理對象執行方法時就會創建一個 Socket 連接,就算這個代理對象再次執行方法時也不會再次創建 Socket 連接了,值得注意的是,有可能兩個服務接口對應的是一個 Socket 連接,舉個例子。
比如服務提供者應用 A,提供了 DemoService 和 HelloService 兩個服務,服務消費者應用 B 引入了這兩個服務,那么在服務消費者這端,這個兩個接口對應的代理對象對應的 TripleInvoker 是不同的兩個,但是這兩個 TripleInvoker 會公用一個 Socket 連接,因為 ConnectionManager 在創建 Connection 對象時會根據服務 URL 的 address 進行緩存,后續這兩個代理對象在執行方法時使用的就是同一個 Socket 連接,但是是不同的 Stream。
Socket 連接創建好之后,就需要發送 Invocation 對象給服務提供者了,因為是基于的 HTTP2,所以要先創建一個 Stream,然后再通過 Stream 來發送數據。
TripleInvoker 中用的是 Netty,所以最終會利用 Netty 來創建 Stream,對應的對象為 Http2StreamChannel,消費端的 TripleInvoker 最終會利用Http2StreamChannel 來發送和接收數據幀,數據幀對應的對象為 Http2Frame,它又分為 Http2DataFrame、Http2HeadersFrame 等具體類型。
正常情況下,會每生成一個數據幀就會通過 Http2StreamChannel 發送出去,但是在 Triple 中有一個小小的優化,會有一個批量發送的思想,當要發送一個數據幀時,會先把數據幀放入一個 WriteQueue 中,然后會從線程池中拿到一個線程調用 WriteQueue 的 flush 方法,該方法的實現為:
private void flush() {
try {
QueuedCommand cmd;
int i = 0;
boolean flushedOnce = false;
// 只要隊列中有元素就取出來,沒有則退出while
while ((cmd = queue.poll()) != null) {
// 把數據幀添加到Http2StreamChannel中,添加并不會立馬發送,調用了flush才發送
cmd.run(channel);
i++;
// DEQUE_CHUNK_SIZE=128
// 連續從隊列中取到了128個數據幀就flush一次
if (i == DEQUE_CHUNK_SIZE) {
i = 0;
channel.flush();
flushedOnce = true;
}
}
// i != 0 表示從隊列中取到了數據但是沒滿128個
// 如果i=0,flushedOnce=false也flush一次
if (i != 0 || !flushedOnce) {
channel.flush();
}
} finally {
scheduled.set(false);
// 如果隊列中又有數據了,則繼續會遞歸調用flush
if (!queue.isEmpty()) {
scheduleFlush();
}
}
}
總體思想是,只要向 WriteQueue 中添加一個數據幀之后,那就會嘗試開啟一個線程,要不要開啟線程要看 CAS,比如現在有 10 個線程同時向 WriteQueue 中添加了一個數據幀,那么這 10 個線程中的某一個會 CAS 成功,其他會 CAS 失敗,那么此時 CAS 成功的線程會負責從線程池中獲取另外一個線程執行上面的 flush 方法,從而獲取 WriteQueue 中的數據幀然后發送出去。
有了底層這套設計之后,對于 TripleInvoker 而 ,它只需要把要發送的數據封裝為數據幀,然后添加到 WriteQueue 中就可以了。
在 TripleInvoker 的 doInvoke() 源碼中,在創建完成 Socket 連接后,就會:
1.基于 Socket 連接先構造一個 ClientCall 對象
2.根據當前調用的方法信息構造一個 RequestMetadata 對象,這個對象表示,當前調用的是哪個接口的哪個方法,并且記錄了所配置的序列化方式,壓縮方式,超時時間等
3.緊接著構造一個 ClientCall.Listener,這個 Listener 是用來處理響應結果的,針對不同的流式調用類型,會構造出不同的 ClientCall.Listener:UNARY:會構造出一個 UnaryClientCallListener,內部包含了一個 DeadlineFuture,DeadlineFuture 是用來控制 timeout 的SERVER_STREAM:會構造出一個 ObserverToClientCallListenerAdapter,內部包含了調用方法時傳入進來的 StreamObserver 對象,最終就是由這個StreamObserver 對象來處理響應結果的BI_STREAM:和 SERVER_STREAM 一樣,也會構造出來一個 ObserverToClientCallListenerAdapter
4.緊著著,就會調用 ClientCall 對象的 start 方法創建一個 Stream,并且返回一個 StreamObserver 對象
5.得到了 StreamObserver 對象后,會根據不同的流式調用類型來使用這個 StreamObserver 對象UNARY:直接調用 StreamObserver 對象的 onNext() 方法來發送方法參數,然后調用 onCompleted 方法,然后返回一個 new AsyncRpcResult(future, invocation),future 就是 DeadlineFuture,后續會通過 DeadlineFuture 同步等待響應結果的到來,并最終把獲取到的響應結果返回給業務方法。SERVER_STREAM:直接調用 StreamObserver 對象的 onNext() 方法來發送方法參數,然后調用 onCompleted 方法,然后返回一個 new AsyncRpcResult(CompletableFuture.completedFuture(new AppResponse()), invocation),后續不會同步了,并且返回 null 給業務方法。BI_STREAM:直接返回 new AsyncRpcResult( CompletableFuture.completedFuture(new AppResponse(requestObserver)), invocation),也不同同步等待響應結果了,而是直接把 requestObserver 對象返回給了業務方法。所以我們可以發現,不管是哪種流式調用類型,都會先創建一個 Stream,得到對應的一個 StreamObserver 對象,然后調用 StreamObserver 對象的onNext 方法來發送數據,比如發送服務接口方法的入參值,比如一個 User 對象:在發送 User 對象之前,會先發送請求頭,請求頭中包含了當前調用的是哪個接口、哪個方法、版本號、序列化方式、壓縮方式等信息,注意請求頭中會包含一些 gRPC 相關的 key,主要就是為了兼容 gRPC然后就是發送請求體然后再對 User 對象進行序列化,得到字節數組然后再壓縮字節數組然后把壓縮之后的字節數組以及是否壓縮標記生成一個 DataQueueCommand 對象,并且把這個對象添加到 writeQueue 中去,然后執行scheduleFlush(),該方法就會開啟一個線程從 writeQueue 中獲取數據進行發送,發送時就會觸發 DataQueueCommand 對象的 doSend 方法進行發送,該方法中會構造一個 DefaultHttp2DataFrame 對象,該對象中由兩個屬性 endStream,表示是不是 Stream 中的最后一幀,另外一個屬性為content,表示幀攜帶的核心數據,該數據格式為:第一個字節記錄請求體是否被壓縮緊著的四個字節記錄字節數組的長度后面就真正的字節數據以上是 TripleInvoker 發送數據的流程,接下來就是 TripleInvoker 接收響應數據的流程,ClientCall.Listener 就是用來監聽是否接收到的響應數據的,不同的流式調用方式會對應不同的 ClientCall.Listener:UNARY:UnaryClientCallListener,內部包含了一個 DeadlineFuture,DeadlineFuture 是用來控制 timeout 的SERVER_STREAM:ObserverToClientCallListenerAdapter,內部包含了調用方法時傳入進來的 StreamObserver 對象,最終就是由這個StreamObserver 對象來處理響應結果的BI_STREAM:和 SERVER_STREAM 一樣,也會構造出來一個 ObserverToClientCallListenerAdapter那現在要了解的就是,如何知道某個 Stream 中有響應數據,然后觸發調用 ClientCall.Listener 對象的相應的方法。要監聽某個 Stream 中是否有響應數據,這個肯定是 Netty 來做的,實際上,在之前創建 Stream 時,會向 Http2StreamChannel 綁定一個TripleHttp2ClientResponseHandler,很明顯這個 Handler 就是用來處理接收到的響應數據的。在 TripleHttp2ClientResponseHandler 的 channelRead0 方法中,每接收一個響應數據就會判斷是 Http2HeadersFrame 還是 Http2DataFrame,然后調用 ClientTransportListener 中對應的 onHeader 方法和 onData 方法:onHeader 方法通過處理響應頭,會生成一個 TriDecoder,它是用來解壓并處理響應體的onData 方法會利用 TriDecoder 的 deframe() 方法來處理響應體另外如果服務提供者那邊調用了 onCompleted 方法,會向客戶端響應一個請求頭,endStream 為 true,表示響應結束,也會觸發執行 onHeader 方法,從而會調用 TriDecoder 的 close() 方法.TriDecoder 的 deframe() 方法在處理響應體數據時,會分為兩個步驟:先解析前 5 個字節,先解析第 1 個字節確定該響應體是否壓縮了,再解析后續 4 個字節確定響應體內容的字節長度然后再取出該長度的字節作為響應體數據,如果壓縮了,那就進行解壓,然后把解壓之后的字節數組傳遞給 ClientStreamListenerImpl 的onMessage() 方法,該方法就會按對應的序列化方式進行反序列化,得到最終的對象,然后再調用到最終的 UnaryClientCallListener 或者ObserverToClientCallListenerAdapter 的 onMessage() 方法。TriDecoder 的 close() 方法最終也會調用到 UnaryClientCallListener 或者 ObserverToClientCallListenerAdapter 的 close() 方法。UnaryClientCallListener,構造它時傳遞了一個 DeadlineFuture 對象:onMessage() 接收到響應結果對象后,會把結果對象賦值給 appResponse 屬性onClose() 會取出 appResponse 屬性記錄的結果對象構造出來一個 AppResponse 對象,然后調用 DeadlineFuture 的 received 方法,從而將方法調用線程接阻塞,并得到響應結果對象。ObserverToClientCallListenerAdapter,構造它時傳遞了一個 StreamObserver 對象:onMessage() 接收到響應結果對象后,會調用 StreamObserver 對象的 onNext(),并把結果對象傳給 onNext() 方法,從觸發了程序員的 onNext() 方法邏輯。onClose() 就會調用 StreamObserver 對象的 onCompleted(),或者調用 onError() 方法
Triple 請求處理和響應結果發送
其實這部分內容和發送請求和處理響應是非常類似的,無非就是把視角從消費端切換到服務端,前面分析的是消費端發送和接收數據,現在要分析的是服務端接收和發送數據。
消費端在創建一個 Stream 后,會生成一個對應的 StreamObserver 對象用來發送數據和一個 ClientCall.Listener 用來接收響應數據,對于服務端其實也一樣,在接收到消費端創建 Stream 的命令后,也需要生成一個對應的 StreamObserver 對象用來響應數據以及一個 ServerCall.Listener 用來接收請求數據。
在服務導出時,TripleProtocol 的 export 方法中會開啟一個 ServerBootstrap,并綁定指定的端口,并且最重要的是,Netty 會負責接收創建 Stream 的信息,一旦就收到這個信號,就會生成一個 ChannelPipeline,并給 ChannelPipeline 綁定一個 TripleHttp2FrameServerHandler,而這個TripleHttp2FrameServerHandler 就可以用來處理 Http2HeadersFrame 和 Http2DataFrame。
比如在接收到請求頭后,會構造一個 ServerStream 對象,該對象有一個 ServerTransportObserver 對象,ServerTransportObserver 對象就會真正來處理請求頭和請求體:
1.onHeader() 方法,用來處理請求頭比如從請求頭中得到當前請求調用的是哪個服務接口,哪個方法構造一個 TriDecoder 對象,TriDecoder 對象用來處理請求體構造一個 ReflectionServerCall 對象并調用它的 doStartCall() 方法,從而生成不同的 ServerCall.ListenerUNARY:UnaryServerCallListenerSERVER_STREAM:ServerStreamServerCallListenerBI_STREAM:BiStreamServerCallListener并且在構造這些 ServerCall.Listener 時會把 ReflectionServerCall 對象傳入進去,ReflectionServerCall 對象可以用來向客戶端發送數據
2.onData() 方法,用來處理請求體,調用 TriDecoder 對象的 deframe 方法來處理請求體,如果是 endStream,那還會調用 TriDecoder 對象的 close 方法
TriDecoder:
deframe():這個方法的作用和客戶端時一樣的,都是先解析請求體的前 5 個字節,然后解壓請全體,然后反序列化得到請求參數對象,然后調用不同的ServerCall.Listener 中的 onMessage()
close():當客戶端調用 onCompleted 方法時,就表示發送數據完畢,此時會發送一個 DefaultHttp2DataFrame 并且 endStream 為 true,從而會觸發服務端TriDecoder 對象的 close() 方法,從而調用不同的 ServerCall.Listener 中的 onComplete()
UnaryServerCallListener:
1.在接收到請求頭時,會構造 UnaryServerCallListener 對象,沒什么特殊的
2.然后接收到請求體時,請求體中的數據就是調用接口方法的入參值,比如 User 對象,那么就會調用 UnaryServerCallListener 的 onMessage() 方法,在這個方法中會把 User 對象設置到 invocation 對象中
3.當消費端調用 onCompleted() 方法,表示請求體數據發送完畢,從而觸發 UnaryServerCallListener 的 onComplete() 方法,在該方法中會調用 invoke() 方法,從而執行服務方法,并得到結果,得到結果后,會調用 UnaryServerCallListener 的 onReturn() 方法,把結果通過 responseObserver 發送給消費端,并調用 responseObserver 的 onCompleted() 方法,表示響應數據發送完畢,responseObserver 是 ReflectionServerCall 對象的一個 StreamObserver 適配對象(ServerCallToObserverAdapter)。
再來看 ServerStreamServerCallListener:
1.在接收到請求頭時,會構造 ServerStreamServerCallListener 對象,沒什么特殊的
2.然后接收到請求體時,請求體中的數據就是調用接口方法的入參值,比如 User 對象,那么就會調用 ServerStreamServerCallListener 的 onMessage() 方法,在這個方法中會把 User 對象以及 responseObserver 對象設置到 invocation 對象中,這是和 UnaryServerCallListener 不同的地方,UnaryServerCallListener 只會把 User 對象設置給 invocation,而 ServerStreamServerCallListener 還會把 responseObserver 對象設置進去,因為服務 端流需要這個 responseObserver 對象,服務方法拿到這個對象后就可以自己來控制如何發送響應體,并什么時候調用 onCompleted() 方法來表示響應體發送完畢。
3.當消費端調用 onCompleted() 方法,表示請求體數據發送完畢,從而觸發 ServerStreamServerCallListener 的 onComplete() 方法,在該方法中會調用invoke() 方法,從而執行服務方法,從而會通過 responseObserver 對象來發送數據
4.方法執行完后,仍然會調用 ServerStreamServerCallListener的onReturn() 方法,但是個空方法
再來看最后一個 BiStreamServerCallListener:
1.在接收到請求頭時,會構造 BiStreamServerCallListener 對象,這里比較特殊,會把 responseObserver 設置給 invocation 并執行 invoke() 方法,從而執行服務方法,并執行 onReturn() 方法,onReturn() 方法中會把服務方法的執行結果,也是一個 StreamObserver 對象,賦值給 BiStreamServerCallListener 對象的requestObserver 屬性。
2.這樣,在接收到請求頭時,服務方法就會執行了,并且得到了一個 requestObserver,它是程序員定義的,是用來處理請求體的,另外的 responseObserver是用來發送響應體的。
3.緊接著就會收到請求體,從而觸發 onMessage() 方法,該方法中會調用 requestObserver 的 onNext() 方法,這樣就可以做到,服務端能實時的接收到消費端每次所發送過來的數據,并且進行處理,處理過程中,如果需要響應就可以利用 responseObserver 進行響應
4.一旦消費端那邊調用了 onCompleted() 方法,那么就會觸發 BiStreamServerCallListener 的 onComplete 方法,該方法中也就是調用 requestObserver 的onCompleted(),主要就觸發程序員自己寫的 StreamObserver 對象中的 onCompleted(),并沒有針對底層的 Stream 做什么事情。
總結
不管是 Unary,還是 ServerStream,還是 BiStream,底層客戶端和服務端之前都只有一個 Stream,它們三者的區別在于:
1.Unary:通過流,將方法入參值作為請求體發送出去,而且只發送一次,服務端這邊接收到請求體之后,會執行服務方法,得到結果,把結果返回給客戶端,也只響應一次。
2.ServerStream:通過流,將方法入參值作為請求體發送出去,而且只發送一次,服務端這邊接收到請求體之后,會執行服務方法,并且會把當前流對應的StreamObserver 對象也傳給服務方法,由服務方法自己控制如何響應,響應幾次,響應什么數據,什么時候響應結束,都由服務方法自己控制。
3.BiStream,通過流,客戶端和服務端,都可以發送和響應多次。
審核編輯 黃宇
-
URL
+關注
關注
0文章
139瀏覽量
15312 -
Dubbo
+關注
關注
0文章
19瀏覽量
3170
發布評論請先 登錄
相關推薦
獨家專訪阿里高級技術專家北緯:Dubbo開源重啟半年來的快意江湖
聊聊Dubbo - Dubbo可擴展機制實戰
Dubbo開源現狀與未來規劃
Dubbo解析及原理淺析
Dubbo源代碼實現服務調用的動態代理和負載均衡
PCB設計:如何導入導出設計規則
服務化改造實踐(一)| Dubbo + ZooKeeper
服務化改造實踐(一)| Dubbo + ZooKeeper
Dubbo 如何成為連接異構微服務體系的最佳服務開發框架
PCB技術:Altium怎么安裝導入導出插件
MACSV數據庫導出、導入的方法







 工商網監
工商網監
評論