") PyTorch GPU 加速訓(xùn)練模型方法
PyTorch GPU 加速訓(xùn)練模型方法
在深度學(xué)習(xí)領(lǐng)域,GPU加速訓(xùn)練模型已經(jīng)成為提高訓(xùn)練效率和縮短訓(xùn)練時(shí)間的重要手段。PyTorch作為一個(gè)流行的深度學(xué)習(xí)框架,提供了豐富的工具和方法來利用GPU進(jìn)行模型訓(xùn)練。
1. 了解GPU加速的基本原理
GPU(圖形處理單元)最初是為圖形渲染設(shè)計(jì)的,但隨著技術(shù)的發(fā)展,人們發(fā)現(xiàn)GPU在并行計(jì)算方面有著天然的優(yōu)勢。GPU擁有成千上萬個(gè)核心,可以同時(shí)處理大量數(shù)據(jù),這使得它在進(jìn)行矩陣運(yùn)算和并行計(jì)算時(shí)比CPU更加高效。
2. 檢查GPU設(shè)備
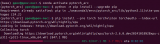
在開始訓(xùn)練之前,我們需要檢查系統(tǒng)中是否有可用的GPU設(shè)備。PyTorch提供了torch.cuda模塊來管理GPU設(shè)備。
import torch
# 檢查是否有可用的GPU
if torch.cuda.is_available():
print("CUDA is available. Training on GPU.")
else:
print("CUDA is not available. Training on CPU.")
3. 將模型和數(shù)據(jù)移動(dòng)到GPU
要利用GPU進(jìn)行訓(xùn)練,我們需要將模型和數(shù)據(jù)都移動(dòng)到GPU上。PyTorch提供了.to()方法來實(shí)現(xiàn)這一點(diǎn)。
# 假設(shè)model是我們的PyTorch模型
model = model.to('cuda')
# 將數(shù)據(jù)移動(dòng)到GPU
inputs, labels = inputs.to('cuda'), labels.to('cuda')
4. 使用DataLoader進(jìn)行數(shù)據(jù)加載
PyTorch的DataLoader類可以自動(dòng)將數(shù)據(jù)批次加載到GPU上。我們只需要在創(chuàng)建DataLoader時(shí)指定pin_memory=True。
from torch.utils.data import DataLoader
# 假設(shè)dataset是我們的數(shù)據(jù)集
dataloader = DataLoader(dataset, batch_size=32, shuffle=True, pin_memory=True)
5. 優(yōu)化器和損失函數(shù)
在GPU上訓(xùn)練模型時(shí),優(yōu)化器和損失函數(shù)也需要在GPU上。我們可以將它們直接傳遞給.to('cuda')方法。
# 假設(shè)optimizer是我們的優(yōu)化器,loss_function是我們的損失函數(shù)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001).to('cuda')
loss_function = torch.nn.CrossEntropyLoss().to('cuda')
6. 訓(xùn)練循環(huán)
在訓(xùn)練循環(huán)中,我們需要確保所有的計(jì)算都在GPU上進(jìn)行。
for epoch in range(num_epochs):
for inputs, labels in dataloader:
# 前向傳播
outputs = model(inputs)
# 計(jì)算損失
loss = loss_function(outputs, labels)
# 反向傳播和優(yōu)化
optimizer.zero_grad()
loss.backward()
optimizer.step()
7. 混合精度訓(xùn)練
混合精度訓(xùn)練是一種在訓(xùn)練過程中同時(shí)使用單精度(float32)和半精度(float16)數(shù)據(jù)的方法。這種方法可以減少內(nèi)存使用,提高計(jì)算速度,同時(shí)保持模型的精度。
PyTorch提供了torch.cuda.amp模塊來實(shí)現(xiàn)混合精度訓(xùn)練。
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for inputs, labels in dataloader:
with autocast():
outputs = model(inputs)
loss = loss_function(outputs, labels)
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
8. 多GPU訓(xùn)練
如果系統(tǒng)中有多個(gè)GPU,我們可以使用PyTorch的torch.nn.DataParallel或torch.nn.parallel.DistributedDataParallel來實(shí)現(xiàn)多GPU訓(xùn)練。
# 使用DataParallel
model = torch.nn.DataParallel(model)
# 或者使用DistributedDataParallel
# model = torch.nn.parallel.DistributedDataParallel(model)
9. 保存和加載模型
在訓(xùn)練過程中,我們可能需要保存模型的狀態(tài),以便在以后繼續(xù)訓(xùn)練或進(jìn)行模型評(píng)估。
# 保存模型
torch.save(model.state_dict(), 'model.pth')
# 加載模型
model.load_state_dict(torch.load('model.pth'))
10. 注意事項(xiàng)
- 在使用GPU訓(xùn)練時(shí),確保所有的數(shù)據(jù)和模型參數(shù)都在GPU上。
- 混合精度訓(xùn)練可以提高訓(xùn)練速度,但需要仔細(xì)調(diào)整以避免精度損失。
- 多GPU訓(xùn)練可以顯著提高訓(xùn)練速度,但需要更多的內(nèi)存和計(jì)算資源。
通過以上步驟,我們可以有效地利用PyTorch在GPU上加速模型訓(xùn)練。這不僅可以提高訓(xùn)練效率,還可以幫助我們更快地迭代和優(yōu)化模型。
-
gpu
+關(guān)注
關(guān)注
28文章
4703瀏覽量
128723 -
模型
+關(guān)注
關(guān)注
1文章
3178瀏覽量
48729 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5493瀏覽量
120998 -
pytorch
+關(guān)注
關(guān)注
2文章
803瀏覽量
13152
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
PyTorch 數(shù)據(jù)加載與處理方法
如何在 PyTorch 中訓(xùn)練模型
使用PyTorch在英特爾獨(dú)立顯卡上訓(xùn)練模型
Pytorch深度學(xué)習(xí)訓(xùn)練的方法

GPU深度學(xué)習(xí)應(yīng)用案例
為什么ai模型訓(xùn)練要用gpu
基于Pytorch訓(xùn)練并部署ONNX模型在TDA4應(yīng)用筆記






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論