 介紹基于不確定的語法條件生成類似Java的強類型程序
介紹基于不確定的語法條件生成類似Java的強類型程序
已經有不少使用神經網絡生成程序的研究,但目前的工作基本上都基于嚴格的語義(semantic)限制。Rice大學的研究人員Vijayaraghavan Murali等將在ICLR 2018上做口頭報告,介紹他們的新研究,基于不確定的語法(syntactic)條件生成類似Java的強類型程序。
AML
對于程序生成而言,Java還是有些復雜。因此研究人員對Java做了一些簡化,設計了一門新的語言AML。AML刻畫了Java類語言的API使用的精髓。
AML使用有限的API數據類型的集合,類型同樣是由API方法名稱(包括constructor)指定的有限集合。方法a的類型簽名用(τ1, ..., τk) -> τ0表示。

AML語法
其中,c表示變量,x、x1……表示變量,let用于變量綁定。
訓練數據
訓練數據為標注過的程序:
{(X1, Prog1), (X2, Prog2), ...
其中,Prog1、Prog2……為AML程序。X1、X2為標簽。訓練之后,模型將根據標簽生成程序,因此標簽應當包含關于代碼的信息。
具體是哪些信息呢?
首先,AML主要是基于API調用設計的語言,因此API調用是重要的信息。
其次,AML脫胎于Java這一靜態類型語言,因此類型也是重要的信息。
理論上,給定關鍵的API調用和類型,就可以生成程序。但實際上模型還沒有這么智能,有時還需要一些額外的信息,一些關鍵詞。
因此,標簽共分3類:
X調用
X類型
X關鍵詞
其中,關鍵詞主要是根據類型和調用方法的命名CamelCase切分所得。例如,readLine會被切分為2個關鍵詞read和line。
草圖
如前一節所述,訓練數據為標簽(X)和AML程序(Prog)。然而,研究人員并沒有直接學習標簽和程序間的關系。因為,程序包含一些低層的信息,這些信息其實無關緊要,并不需要學習。比如,具體的變量命名,替換一下,并不會影響程序的語義(λ演算中的α-等價)。因此,需要將程序再轉換一下,轉換成某種刻畫程序的高層結構和形狀(控制結構、API調用順序、參數類型、返回值類型)的表示。基于這一思路,研究人員將程序中的一些低層信息(變量命名、基本操作)抽象掉,從而將程序轉化為草圖(Sketch),并基于標簽學習草圖上的概率分布。之后,再使用組合方法將草圖具體化為類型安全的AML程序(通過類型引導的隨機搜索過程)。

Prog、X、Y的貝葉斯網絡
其中,Yi= α(Progi),Y(草圖)的語法如下:
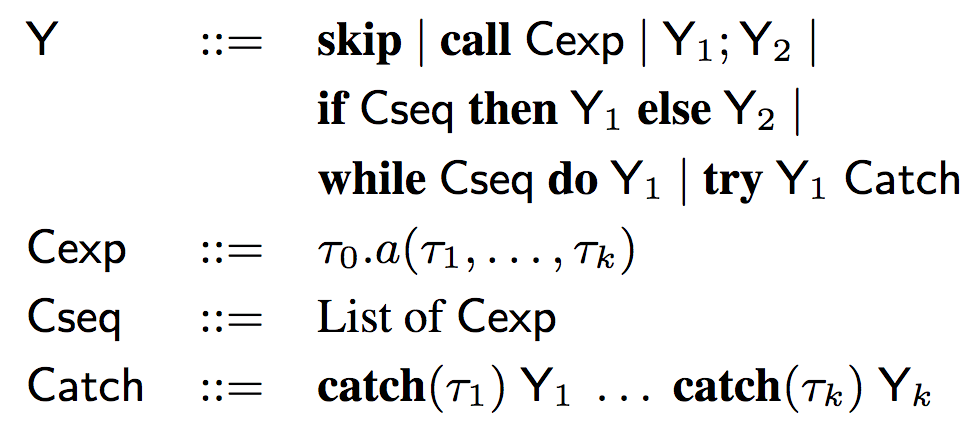
可以看到,草圖的語法和AML的語法類似,抽象掉了其中的變量名稱(x、x1等),保留了控制結構、類型信息和API調用。
對比草圖的語法和AML的語法,α函數(從程序中抽象出草圖的操作)的定義也就不言自明了:

GED
如前所述,模型將基于草圖進行學習:
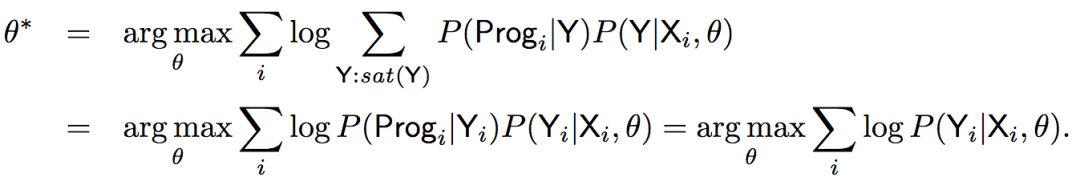
上式表明,最終我們需要計算:
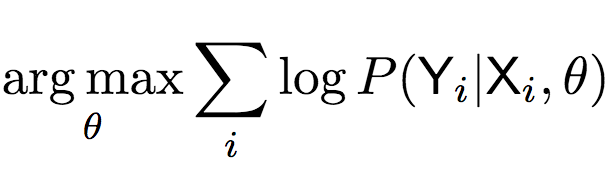
為了計算上式,研究人員提出了高斯編碼-解碼器(Gaussian Encoder-Decoder)(簡稱GED)模型,引入了一個潛向量Z,以隨機連接標簽和草圖:
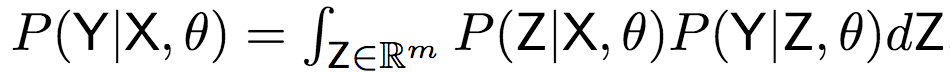
下面我們以編碼X調用為例,說明編碼器具體是如何工作的。
首先,將X調用的每個元素X調用,i轉換成one-hot向量表示,記為X'調用,i。然后,通過下式編碼X'調用,i

XCalls,i即X調用,i
其中,h為神經隱藏單元的數量,Wh∈ R|調用| x h、bh∈ Rh、Wd∈ Rh x d、bd∈ Rd為網絡的權重和偏置,可通過訓練學習。
基于f,可以計算P(X | Z,θ)
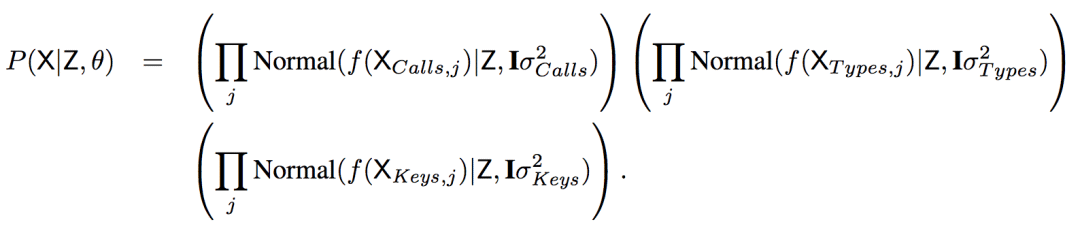
也就是說,X編碼后的值從以Z為中心的高維正態分布取樣。
P(X | Z,θ)的計算需要編碼,P(Y | Z,θ)的計算與之相反,需要解碼。
草圖Y可以看成一個樹形結構。
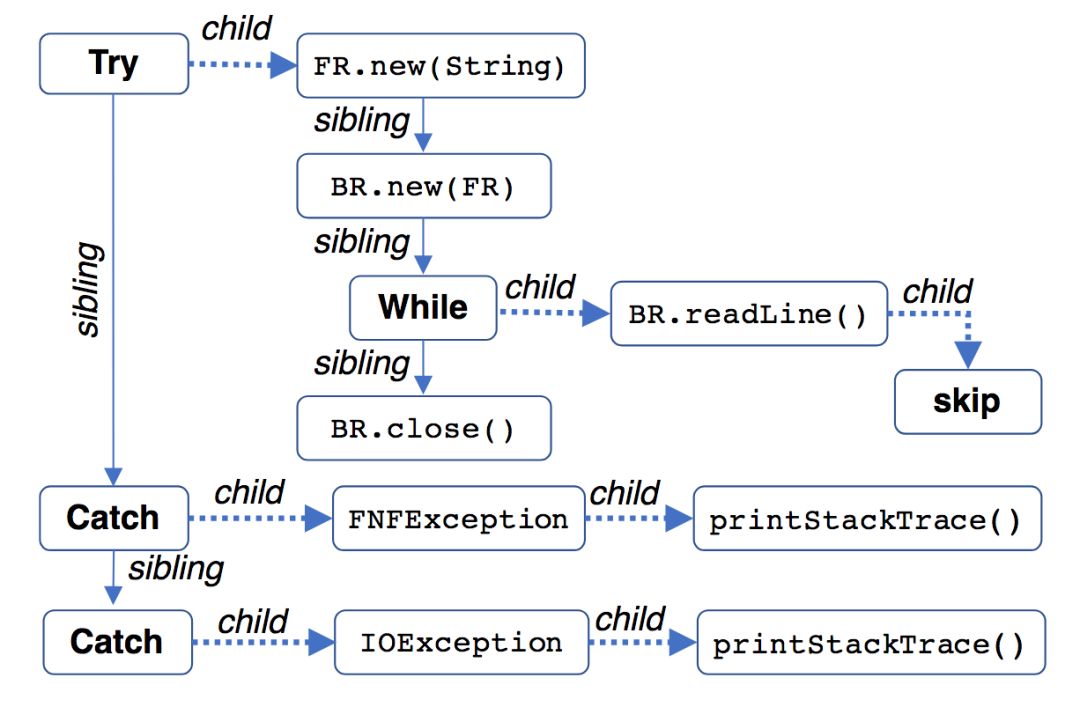
研究人員采用了自頂向下的搜索方法,從樹形的頂端,一路往下,遞歸地計算輸出分布yi。“一路往下”的“路”,研究人員稱為生產路徑(production path)。生產路徑定義為有序對的序列<(v1, e1), (v2, e2), ..., (vk, ek)>,其中,vi為草圖中的節點(即語法中的項),ei為連接vi與vi+1的邊的類型。具體而言,邊包括兩種類型:sibling(兄弟姊妹,上圖中的實線)和child(子女,上圖中的虛線)。
比如,上圖中有4條生產路徑:
(try,c), (FR.new(String),s), (BR.new(FR),s), (while,c), (BR.readLine(),c), (skip,·)
(try,c), (FR.new(String),s), (BR.new(FR),s), (while,s), (BR.close(),·)
(try,s), (catch,c), (FNFException,c), (T.printStackTrace(),·)
(try,s), (catch,s), (catch,c), (IOException,c), (T.printStackTrace(),·)
其中,·表示路徑的終結。另外,為了簡明,以上路徑均省略了(root,c),用s和c表示sibling和child,并縮寫了部分類名。
給定Z和某條生產路徑上的序列Yi= <(v1,e1), ..., (vi,ei)>,為了簡化計算,假定路徑中的下一個節點僅僅取決于Z和Yi,從而解碼器只需使用單個推理步驟即可計算概率P(vi+1| Yi,Z)。具體而言,解碼器使用了兩個循環神經網絡,一個用于c邊,一個用于s邊。
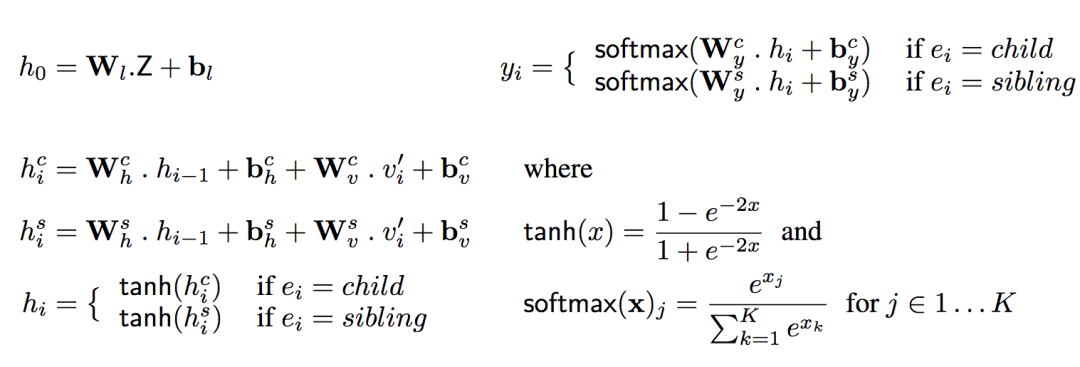
其中,v'i為vi轉換成的one-hot向量。h為解碼器的隱藏單元數目,|G|為解碼器的輸出詞匯。Whe、bhe為解碼器的隱藏狀態權重和偏置矩陣,Wve、bve為輸入權重和偏置矩陣,Wye、bye為輸出權重和偏置矩陣(e為邊的類型)。Wl和bl是“提升”權重和偏置,將d維向量Z提升到解碼器的高維隱藏空間h。
可視化
研究人員可視化了32維潛向量空間的聚類。研究人員從測試數據中得到標簽X,然后從P(Z | X)取樣潛向量Z,進而從P(Y | Z)取樣草圖Y。接著使用t-SNE降維Z到2維,然后基于Y中的API使用標注每個點。下圖顯示了這一2維空間,每個標簽對應不同的顏色。
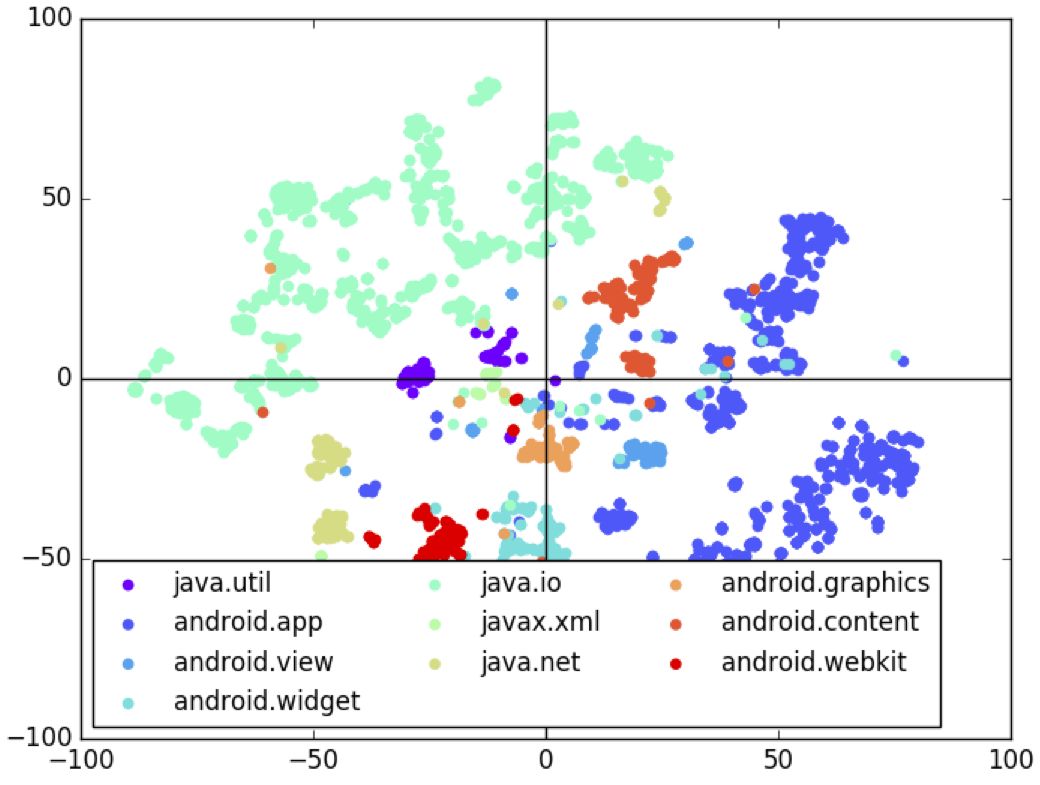
從上圖我們可以很明顯地看到,模型很好地根據API的不同學習了潛空間的聚類。
定量測試
研究人員基于1500個Android應用(收集自網絡),進行了測試。研究人員使用JADX反編譯這1500個Android應用安裝文件(APK)到1億行源代碼,并從中提取出了15萬Java方法。隨后,研究人員將這15萬Java方法轉換成了AML程序。然后,從AML程序中提取出草圖Y和X調用、X類型、X關鍵詞,供模型訓練。其中,分別隨機選擇了1萬個AML程序,作為驗證集和測試集。
理論上來說,驗證生成程序的正確性需要驗證程序的所有輸入對應的輸出符合預期。然而,這是一個不可判定問題。因此,研究人員轉而使用一些間接的標準進行衡量。
期望AST
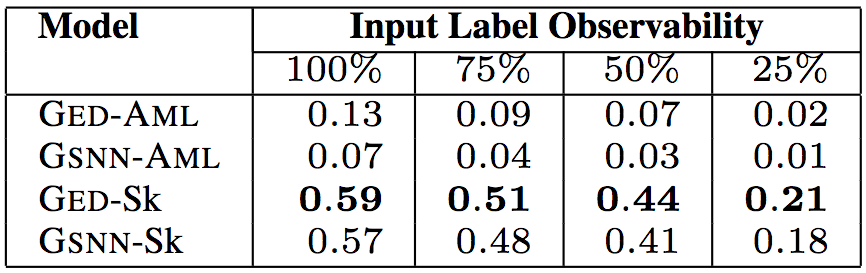
API調用順序的相似程度(具體而言,研究人員使用了平均最小Jaccard距離)
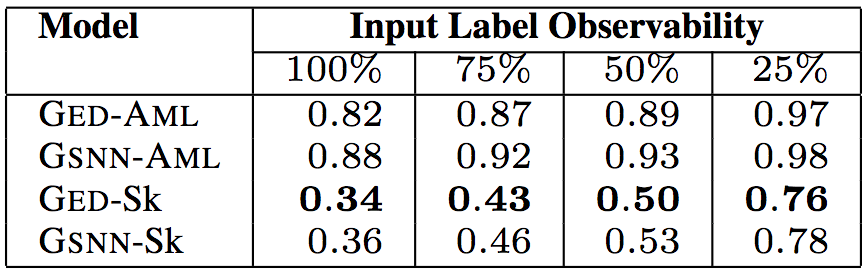
API調用方法的相似程度(同樣基于平均最小Jaccard距離)
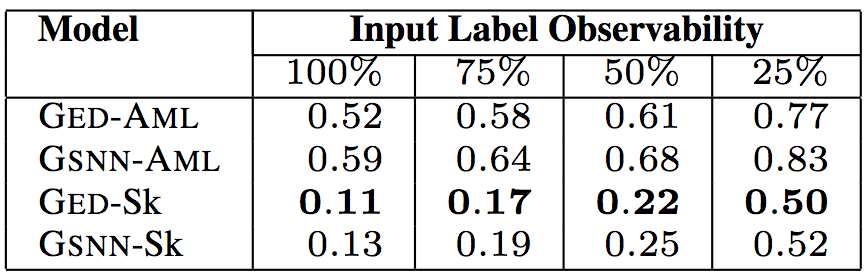
語句數目
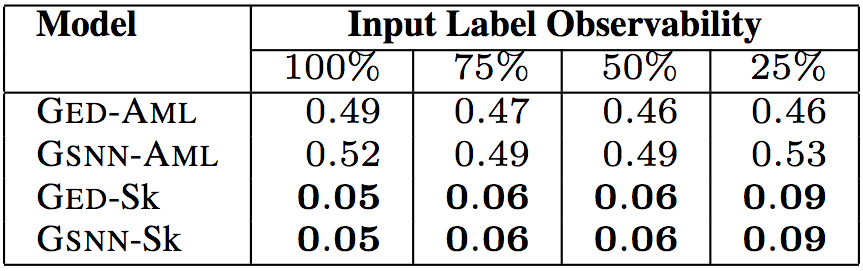
控制結構數目(例如,分支、循環、try-catch)數
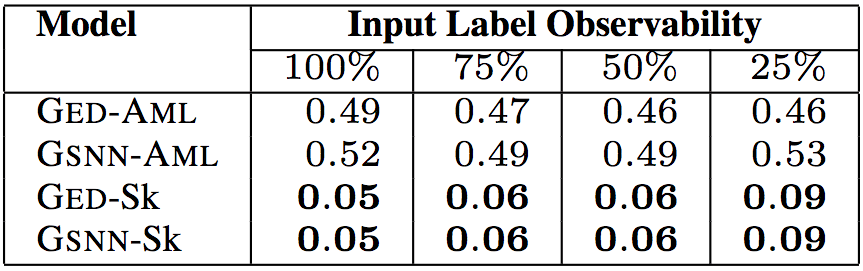
上面5張表格中,“Input Label Observability”(輸入標簽可觀察性)表示測試數據提供的輸入標簽(API調用、類型、關鍵詞)的信息比例。研究人員試驗了75%、50%、25%的可觀察性,相應的中位數分別為9、6、2。這樣,研究人員可以評估給定少量關于代碼的信息時,模型的預測能力。
下表顯示了在50%可觀察性下,模型在未見數據上的表現。
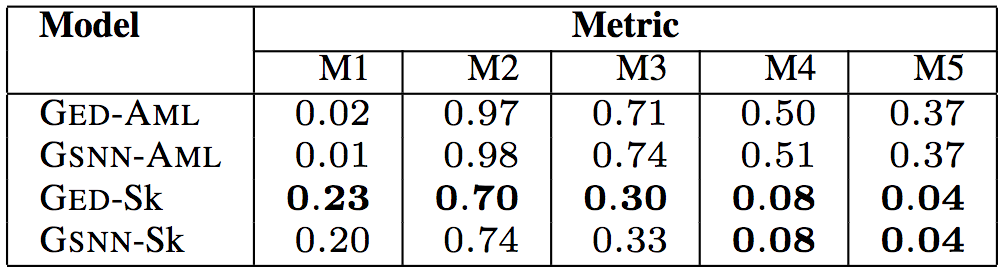
以上6個表格中,“Model”(模型)一列中,GED為研究人員所用的模型,GSNN(高斯隨機神經網絡)為當前最先進的條件生成式模型(Sohn等在2015年提出)。為了驗證草圖學習的有效性,研究人員進行了消融測試。帶-Sk后綴的為基于草圖學習的模型,帶-AML后綴的為直接基于程序進行學習的模型。
測試結果表明,研究人員提出的模型GED-Sk表現最優,超過了當前的最先進模型GSNN。另外,GSNN-Sk的表現也不錯,而直接基于程序進行學習的模型表現很糟糕。這說明草圖學習是條件程序生成的關鍵。
定性測試
除了定量測試之外,研究人員也進行了定性測試。
文件讀寫
研究人員希望Bayou能生成一個寫入文件的程序。想想看,如果你希望指示Bayou生成寫入文件的程序,你會給出怎么樣的提示呢?最低限度的提示,應該是兩個關鍵詞,write、file,或者,甚至僅僅是一個類型FileWriter。Bayou還沒有這么智能,但它的表現已經相當搶眼了。研究人員給Bayou的輸入僅僅是一個類型和一個關鍵詞,幾乎就是最低限度的信息了:
X類型= {FileWriter}
X調用= {write}
X關鍵詞= {}
Bayou生成了如下的程序(選取自top-5):
BufferedWriter bw;
FileWriter fw;
try {
fw = newFileWriter($String, $boolean);
bw = newBufferedWriter(fw);
bw.write($String);
bw.newLine();
bw.flush();
bw.close();
} catch (IOException _e) {
}
注意,盡管輸入只提供了FileWriter類型,程序使用了BufferedWriter,因為在Java中,文件讀寫經常基于buffer。Bayou自行學習到了這一點。另外,Bayou也正確地在關閉文件前清空了buffer。
Android對話框
研究人員希望生成一個程序,設定Android對話框的標題和信息。這次研究人員給定的輸入已經到了最低限度:
X類型= {}
X調用= {}
X關鍵詞= {android, dialog, set, title, message}
生成的程序如下:
Builder builder2;
Builder builder1;
AlertDialog alertDialog;
Builder builder4;
Builder builder3;
builder1 = newBuilder($Context);
builder2 = builder1.setTitle($String);
builder3 = builder2.setMessage($String);
builder4 = builder3.setNeutralButton($String,
$OnClickListener);
alertDialog = builder4.show();
雖然輸入信息中沒有指定,Bayou很智能地使用了幫助類AlertDialog.Builder。另外,Bayou還額外給對話框加上了一個按鈕,這是因為Bayou學習到Android對話框經常配備一個按鈕(通常用于關閉對話框)。
預覽拍攝
最后一個例子是生成預覽拍攝效果的程序。這次給定的輸入可以說是極簡了:
X類型= {}
X調用= {startPreview}
X關鍵詞= {}
Bayou生成的程序:
parameters = $Camera.getParameters();
parameters.setPreviewSize($int, $int);
parameters.setRecordingHint($boolean);
$Camera.setParameters(parameters);
$Camera.startPreview();
這個例子充分體現了Bayou的智能之處。首先,Bayou自動識別出startPreview屬于camera API。其次,Bayou在開始預覽前,首先獲取了相機參數,然后設定了預覽顯示尺寸。這正是Android camera API文檔的推薦做法!
實現細節
研究人員將整個系統命名為Bayou,該系統由兩部分組成,基于TensorFlow構建的GED,以及基于Eclipse IDE構建的草圖抽象和組合具體化。
研究人員基于網格搜索進行交叉驗證,選擇表現最優的模型。
超參數設定如下:
編碼器:調用64單元、類型32單元、關鍵詞64單元。
解碼器:128單元。
32維潛向量空間。
mini-batch尺寸:50。
Adam優化,學習率0.0006。
epoch:50。
整個模型的訓練大約需要10小時(AWS p2.xlarge、K80、12G Ram)
結語
這是首個使用神經網絡基于不確定的條件生成程序的研究。未來的IDE可能基于類似的模型提供極為智能的代碼補全。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
JAVA
+關注
關注
19文章
2957瀏覽量
104544
原文標題:萊斯大學新研究:神經草圖學習,根據條件生成程序
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Java入門基礎知識了解
N4373C:了解測量不確定度的規范和程序
淺談Java編程學習 Java基礎語法注意項
JAVA教程之JSP基礎語法的詳細資料說明

面向對象程序設計 - 課內實驗1(Java語言概述)
Java的基礎語法





 工商網監
工商網監
評論