") 騰訊發(fā)布開源MoE大語(yǔ)言模型Hunyuan-Large
騰訊發(fā)布開源MoE大語(yǔ)言模型Hunyuan-Large
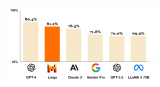
近日,騰訊公司宣布成功推出業(yè)界領(lǐng)先的開源MoE(Mixture of Experts,專家混合)大語(yǔ)言模型——Hunyuan-Large。這款模型不僅在參數(shù)量上刷新了業(yè)界紀(jì)錄,更在效果上展現(xiàn)出了卓越的性能,標(biāo)志著騰訊在自然語(yǔ)言處理領(lǐng)域邁出了重要的一步。
據(jù)了解,Hunyuan-Large的總參數(shù)量高達(dá)389B(即3890億),這一數(shù)字遠(yuǎn)超當(dāng)前許多主流的大語(yǔ)言模型。而其激活參數(shù)也達(dá)到了驚人的52B(即520億),這意味著模型在處理復(fù)雜任務(wù)時(shí)能夠展現(xiàn)出更強(qiáng)的學(xué)習(xí)能力和泛化性能。
除了參數(shù)量上的優(yōu)勢(shì),Hunyuan-Large在訓(xùn)練數(shù)據(jù)上也下足了功夫。據(jù)悉,該模型訓(xùn)練時(shí)所使用的token數(shù)量達(dá)到了7T(即7萬(wàn)億),這確保了模型能夠充分學(xué)習(xí)到語(yǔ)言的多樣性和復(fù)雜性。同時(shí),Hunyuan-Large還支持最大上下文長(zhǎng)度為256K的文本輸入,這一特性使得模型在處理長(zhǎng)文本或?qū)υ拡?chǎng)景時(shí)能夠更準(zhǔn)確地捕捉上下文信息,從而生成更加連貫和自然的回復(fù)。
騰訊此次推出的Hunyuan-Large大語(yǔ)言模型,不僅展示了其在人工智能領(lǐng)域的深厚技術(shù)積累,也為整個(gè)自然語(yǔ)言處理領(lǐng)域的發(fā)展注入了新的活力。
-
人工智能
+關(guān)注
關(guān)注
1791文章
46896瀏覽量
237657 -
騰訊
+關(guān)注
關(guān)注
7文章
1646瀏覽量
49402 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
508瀏覽量
10247 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
287瀏覽量
13334
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
騰訊混元Large模型及云TI平臺(tái)全新上線
搭建開源大語(yǔ)言模型服務(wù)的方法
昆侖萬(wàn)維開源2千億稀疏大模型Skywork-MoE
浪潮信息發(fā)布“源2.0-M32”開源大模型
騰訊云大模型價(jià)格調(diào)整:混元-lite、混元-standard免費(fèi),混元-pro降價(jià)
紅帽發(fā)布RHEL AI開發(fā)者預(yù)覽版,集成IBM Granite模型,簡(jiǎn)化AI開發(fā)流程
Mistral Large模型現(xiàn)已在Amazon Bedrock上正式可用
Mistral發(fā)布Mistral Large旗艦模型,但沒(méi)有開源
昆侖萬(wàn)維發(fā)布新版MoE大語(yǔ)言模型天工2.0
大模型開源開放評(píng)測(cè)體系司南正式發(fā)布
Meta發(fā)布CodeLlama70B開源大模型
幻方量化發(fā)布了國(guó)內(nèi)首個(gè)開源MoE大模型—DeepSeekMoE
機(jī)器人基于開源的多模態(tài)語(yǔ)言視覺大模型

對(duì)標(biāo)OpenAI GPT-4,MiniMax國(guó)內(nèi)首個(gè)MoE大語(yǔ)言模型全量上線
大語(yǔ)言模型推斷中的批處理效應(yīng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論