") 推理王者o1到底怎么落地?
推理王者o1到底怎么落地?

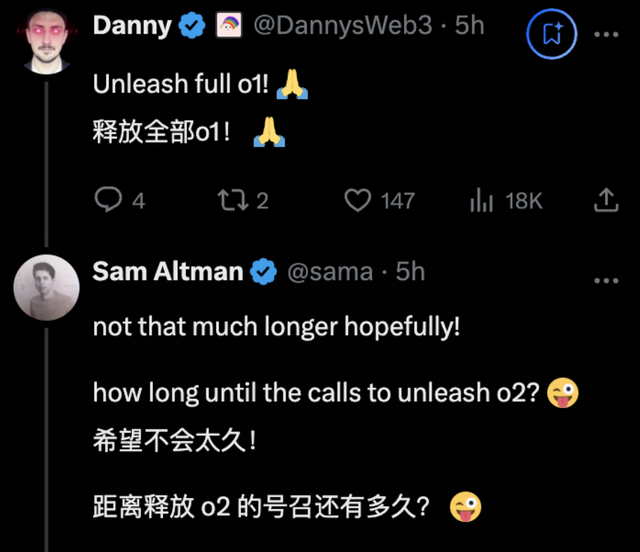
完整版o1“被泄露”,成了上周AI界的大新聞。
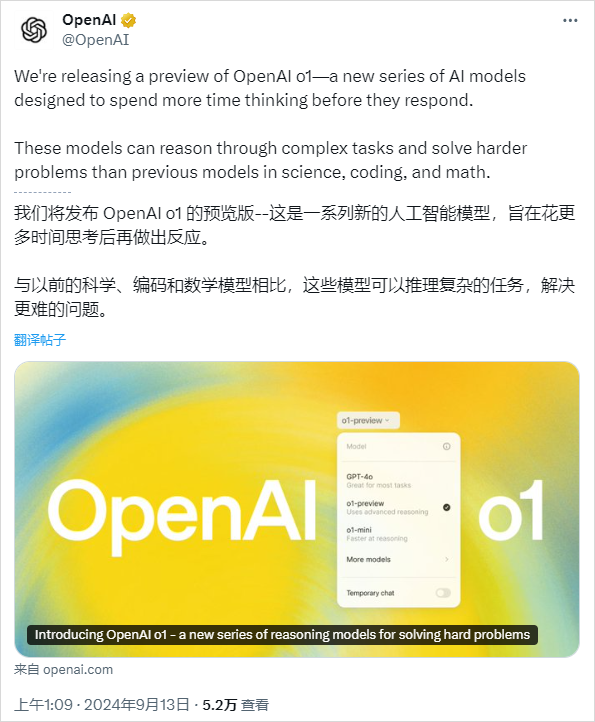
9月13日,OpenAI發(fā)布了傳說中代號“草莓”的全新模型系列的預覽版o1 preview,隨后又上線了o1 mini。o1模型系列,能夠模仿人類思維過程“慢思考”,提升了AI的邏輯推理能力,成為AI模型領(lǐng)域的王炸,牽動著整個行業(yè)的神經(jīng)。
而就在上周,有不少用戶突然發(fā)現(xiàn),能在ChatGPT官網(wǎng)上用到完整版o1了。奧特曼更是不小心“登錯賬號”,在社交媒體宣布“o2即將登場”。
從o1 preview到o2,這一系列模型,炸裂歸炸裂,但所謂的推理能力好像并沒有真正融入產(chǎn)業(yè)應(yīng)用,以至于大家都有種狼來了的感覺,開始猜測這不過是奧特曼的又一次宣傳噱頭。
比如,就有網(wǎng)友覺得完整版o1被釋放,并不是“不小心”,而是“精心策劃”的炒作,奧特曼“登錯號劇透o2”也是裝的。
如何避免真實的技術(shù)價值淪為“狼來了”的戲碼?答案就是,別讓模型能力成為空中樓閣,而是加速落地到產(chǎn)業(yè)中。
到底哪些場景才能充分發(fā)揮o1“慢思考”的技術(shù)潛力呢?本文就來找找產(chǎn)業(yè)化落地的路子。

落地產(chǎn)業(yè),前提是正確認識到技術(shù)的價值。o1模型系列與老前輩們的最大區(qū)別和價值究竟是啥呢?就是慢思考。
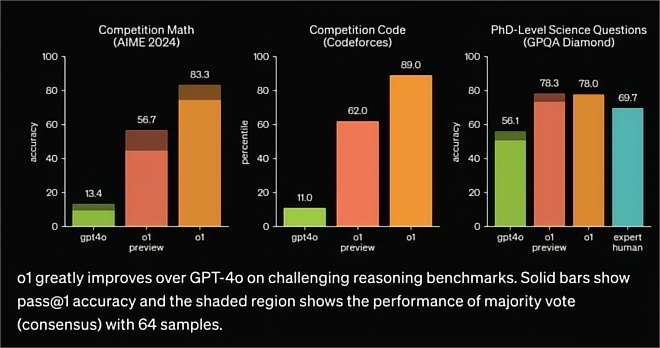
我們都知道GPT-4o啥的處理些日常瑣事還行,但時不時就會犯點小迷糊,算個小學數(shù)學題加減法都錯漏百出。而o1就像是經(jīng)過嚴格訓練的學霸,專克邏輯推理、復雜任務(wù)難題。前不久的OpenAI倫敦開發(fā)者日上,完整版o1的五大能力包括:函數(shù)調(diào)用、開發(fā)者message、流式傳輸、結(jié)構(gòu)化輸出、圖像理解。
如果說4o的數(shù)學水平是高中生程度,那么9月發(fā)布的o1-preview就有大學生水平了,即將發(fā)布的o2在GPQA研究生級別基準中取得了105%的成績,未來是妥妥的研究生了。

而上述能力靠的就是o1的獨門秘籍——慢思考。
已知人腦有兩種模式:一種是快思考,就是咱們平時“一拍腦門”那種憑直覺、靠經(jīng)驗的快速決策;另一種是慢思考,指的是在解數(shù)學題、進行科學推理需要花時間、費精力去琢磨的思考模式,更注重邏輯和理性分析。
o1通過學習人腦深思熟慮、穩(wěn)扎穩(wěn)打的思考模式,o1采用強化學習+思維鏈,把復雜問題拆成小塊,一步步來,直到得出最準確的答案,極大地提高了模型的推理能力。
研究生級別的學霸o1模型系列,給AI界帶來了全新的可能。但如何將“慢思考”的技術(shù)潛力真正轉(zhuǎn)化為實際應(yīng)用,讓o1成為推動產(chǎn)業(yè)進步的重要力量?還是一個需要進一步探索的話題。
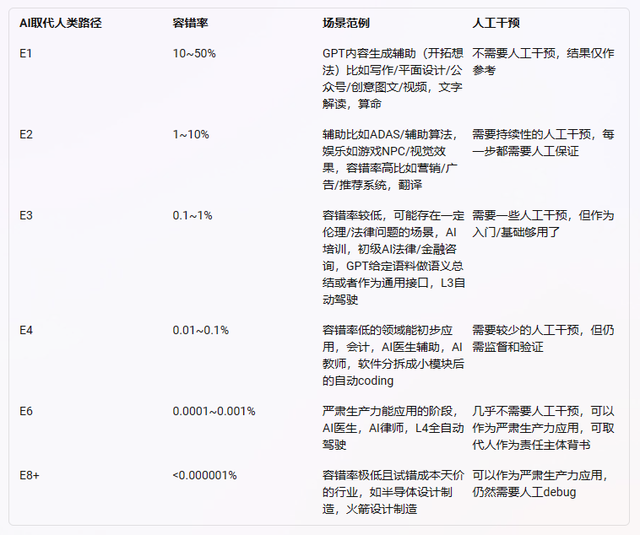
產(chǎn)業(yè)大不同,落地有先后。按照落地的難易程度,我們可能會看到類o1的“慢思考”能力,在以下產(chǎn)業(yè)逐步應(yīng)用開來。

堅實的數(shù)字化基礎(chǔ)、對新技術(shù)的高接受度、強大的付費能力,這些特性使得金融成為大模型技術(shù)落地的理想場所。
幾乎所有的大模型廠商,都將金融行業(yè)作為業(yè)務(wù)開拓的第一站。然而,在金融與大模型的結(jié)合過程中,由于大模型的推理能力不強,加上幻覺問題,導致大模型在金融領(lǐng)域的復雜應(yīng)用中表現(xiàn)并不理想。
此前,大模型在金融行業(yè)的應(yīng)用范圍,主要是一些容錯率較高的淺層應(yīng)用上,如智能客服、報表文檔助手。而風控、信貸、投資分析等的嚴肅生產(chǎn)力場景,需要對多種模態(tài)的數(shù)據(jù),進行深入分析和推理,決策質(zhì)量要求極高。這些核心業(yè)務(wù)中,大模型在工作流中發(fā)揮的價值相對有限,主要還是得靠人類專家來做。
一位銀行從業(yè)者表示,客戶需要我們的理財分析師給出犀利、專業(yè)的觀點來幫助決策,而大模型只會泛泛而談,沒什么參考價值。
人人都希望由專業(yè)的金融從業(yè)人員來服務(wù),如果AI模型能夠在一些容錯率低的嚴肅場景中應(yīng)用,只需要少量人工干預、監(jiān)督和驗證,那么專業(yè)人士的時間精力,不就可以解放出來了嗎?隨著“慢思考”邏輯推理能力的出現(xiàn),這一期待真的有可能實現(xiàn)。
基于類o1的邏輯推理能力,我們有望看到AI在金融核心業(yè)務(wù)中承擔起專家角色,發(fā)揮更重要的作用。比如像專業(yè)審核員一樣讀征信報告、看賬單流水,甚至能解讀網(wǎng)絡(luò)大數(shù)據(jù),思考和捕捉數(shù)據(jù)之間的關(guān)聯(lián),并生成風險判斷的依據(jù)和結(jié)論。
又或者像專業(yè)分析師一樣,根據(jù)用戶需求進行個性化的產(chǎn)品設(shè)計,縝密分析投資策略,給出理財、投資、投保等建議。
慢思考可以讓AI從淺層、邊緣、單一的場景,進入到復雜、核心、高價值的核心業(yè)務(wù)中,突破大模型在金融行業(yè)的價值上限。

“o1實在太強了……我的博士作業(yè)做了20個小時,被它3分鐘思考就拿下了。剛讀博就出這個,感覺人生都灰暗了[流淚] 。”邏輯推理能力達到研究生水平的o1模型系列,讓不少人類研究生、博士生感到了切實的危機。
但用一句流行語來說,“o1不是來拆散科研這個家,而是來加入這個家的”。
近幾十年來,神經(jīng)網(wǎng)絡(luò)算法已經(jīng)被廣泛應(yīng)用于科研領(lǐng)域,從宏觀世界的天文探索、引力波探測,到微觀世界的蛋白質(zhì)折疊、同步光源等,數(shù)據(jù)科學和算法工程提供了大量的操作手段,幫助科學領(lǐng)域的探索性課題取得突破。AI技術(shù)已經(jīng)成為科學研究不可或缺的一部分,AI4S的大趨勢不可阻擋。
面對這個過程,一位高校力學老師曾對我們說過一個比喻:AI和力學的結(jié)合,就像是成功的婚姻才剛剛開始,會有甜蜜期,也會有磨合期。
傳統(tǒng)模型算法雖然有強大的計算能力和手段,但缺乏深入的邏輯推理能力和對科學原理的深刻理解,面對復雜的科學問題時,往往力不從心,難以提供準確且可靠的解決方案。思考方式跟追求嚴謹?shù)目茖W家們大相徑庭,此前的AI4S全靠人類遷就。
而o1慢思考強調(diào)的逐步分析、深入推理,這種思考方式與科學研究的本質(zhì)不謀而合。具備慢思考能力的AI模型,相當于掌握了碩博們的學習方法,可以逐步拆解問題、分析數(shù)據(jù)、反復驗算、推導結(jié)論。
在科研領(lǐng)域,類o1模型可以作為科學家們的“科研伴侶”,扮演好幾種角色:
1.靈感繆斯。在一些經(jīng)典的科學問題,或者已經(jīng)成熟的科研結(jié)果上,科學家們往往還要開發(fā)新方法、新理論。這個過程中,AI的邏輯推理能力可以發(fā)現(xiàn)數(shù)據(jù)之間的潛在聯(lián)系和規(guī)律,提出新的假設(shè)和預測,為科學研究開辟新的道路。
2.科研助理。隨著科學領(lǐng)域“低垂的果實”被摘完,科學家們要去解決更復雜的問題。以力學為例,在深水探索任務(wù)中,不僅要做簡單的維度對比,還需要做更細節(jié)的探索研究,包括復雜的洋流環(huán)境、水下潛入等復雜動作,這些是傳統(tǒng)的流體控制方法所難以預測的。而邏輯推理大模型可以在這類非線性、高維度的科學問題與科研應(yīng)用上,有更好的性能表現(xiàn)。比如馬克思普朗克研究所的量子物理學者Mario Krenn,就展示了o1-preview正確完成計算的復雜量子物理問題。
3.工程師助理。科研目的不是簡單地開發(fā)新方法、新理論,最終成果要轉(zhuǎn)化到工業(yè)界,去解決工業(yè)、生活中的現(xiàn)實問題,這就不單單需要新穎的想法,還需要技術(shù)的安全性、成熟度、容錯率等。這時候,具備邏輯推理能力的大模型,可以在工業(yè)場景中處理復雜問題,降低幻覺,如同工程師助理一樣,減少實際應(yīng)用中的故障率。
無論是容錯率較高的創(chuàng)造型任務(wù),還是容錯率較低的工程類任務(wù),擁有“慢思考”能力的大模型,都會是一名更得力的助手,與科學長相廝守。

ChatGPT的第一個應(yīng)用案例,就是幫學生寫作業(yè),為此遭到了各國多所學校的嚴格限制。這種應(yīng)用場景雖然不可取,但說明了一個道理:充斥著大量文本、重復任務(wù)的教育行業(yè),是大模型落地的絕佳場景。
過去一年多來,“大模型+教育”這個新風口的爆發(fā),也證實了教育產(chǎn)業(yè)AI化的價值切實存在。但真正落地的應(yīng)用,主要還是以AI口語對話、AI批改作文、LLM翻譯、中英文寫作等功能為主。
一旦覆蓋到復雜的學科內(nèi)容,比如數(shù)學、物理、化學等,連“9.9跟9.11誰大”都搞不清楚的GPT們就集體熄火了。國產(chǎn)大模型也同樣如此,一位國產(chǎn)數(shù)學大模型的工作人員告訴我,做數(shù)學題的正確率是60%。試問哪個家長敢讓數(shù)學成績剛及格,還熱愛“胡說八道”的AI給孩子當家教呢?
邏輯推理,限制了模型的能力邊界。而模型的能力限制,又進一步影響了智能教育硬件、個性化AI在線輔導服務(wù)的市場化推廣步伐。可以說,解決大模型+教育的商業(yè)化問題,最關(guān)鍵的是問技術(shù)要出路,這也是慢思考模型的價值所在。
首先,具備慢思考的大模型,數(shù)學推理的能力飛躍,數(shù)學正確率更是肉眼可見地高漲。在剛剛結(jié)束的2024 IOI信息學奧賽題目中,o1的微調(diào)版本在每題嘗試50次條件下取得了213分,屬于人類選手中前49%的成績。如果允許它每道題嘗試10000次,能獲得362.14分,可以獲得金牌。對于有算力、有開發(fā)能力的教育大模型公司來說,完全有可能開發(fā)出數(shù)學能力很強的垂類大模型,提供面向復雜學科或高年齡學段的AI輔導功能。
其次,疊加了多模態(tài)的推理大模型,進一步開拓教育應(yīng)用。在泄露出來的完整版o1,已經(jīng)具備多模態(tài)能力了,支持上傳附件,或直接識圖。有網(wǎng)友將一道普特南數(shù)學競賽的證明題截圖發(fā)給o1,就被具有圖像推理能力的o1成功搞定。這意味著教育類大模型不再局限于文本、語言對話類的功能,可以跟物理世界產(chǎn)生交互,比如拍照答題、實時視頻問答等,不管學生問的是現(xiàn)實世界中的什么問題,AI都能大概率找出正確答案。
更為關(guān)鍵的是,由于慢思考的模型不再一味追求參數(shù)、追求scaling law,而是著重于提高推理能力和認知效率。也就是說,面對一個復雜問題或任務(wù),AI大模型開始以“更聰明”的方法,而非“力大飛磚”的笨辦法,模型的參數(shù)規(guī)模更小,更便于在硬件終端上部署,在同樣的終端配置下,推理大模型可以表現(xiàn)更出色,這有利于AI學習機等教育類智能硬件的普及,為教育行業(yè)帶來新的增長點。

雖然慢思考的類o1大模型還是個新鮮事物,OpenAI噱頭大于實際的營銷手段也招人吐槽,但可以肯定的是,更強邏輯推理能力的大模型,將成為模廠與行業(yè)在智能化領(lǐng)域所必須拿下的高地,去解決此前LLM+行業(yè)的結(jié)合止于淺層應(yīng)用、難以應(yīng)對復雜業(yè)務(wù)的產(chǎn)業(yè)化痛點,進而打開大模型的商業(yè)化空間。
究其核心,是AI大模型開始走出語言類任務(wù)的局限,可以在容錯率低、專業(yè)性強的嚴肅工作中發(fā)揮價值。
專家型人才稀缺的行業(yè)場景,往往也是高價值所在。懂得慢思考的大模型,正慢慢行業(yè)專家化,這讓大模型更有價值,也讓會思考的人更有價值了。

審核編輯 黃宇
-
AI
+關(guān)注
關(guān)注
87文章
30106瀏覽量
268398 -
OpenAI
+關(guān)注
關(guān)注
9文章
1042瀏覽量
6404
發(fā)布評論請先 登錄
相關(guān)推薦
OpenAI發(fā)布o1大模型,數(shù)理化水平比肩人類博士,國產(chǎn)云端推理芯片的新藍海?
昆侖萬維天工大模型4.0 O1版即將邀測
Kimi發(fā)布新一代推理模型k0-math
天工大模型4.0 O1版即將啟動邀測
Kimi發(fā)布新一代數(shù)學推理模型k0-math
高效大模型的推理綜述

AI推理CPU當?shù)溃珹rm驅(qū)動高效引擎

FPGA和ASIC在大模型推理加速中的應(yīng)用

李開復:中國擅長打造經(jīng)濟實惠的AI推理引擎

S8393獨立三路電子按鍵開關(guān)芯片中文手冊
LLM大模型推理加速的關(guān)鍵技術(shù)
深度探討VLMs距離視覺演繹推理還有多遠?

ChatGPT是一個好的因果推理器嗎?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論