 緩存之美——如何選擇合適的本地緩存?
緩存之美——如何選擇合適的本地緩存?
作者:京東保險 郭盼
1、簡介
小編最近在使用系統的時候,發現盡管應用已經使用了redis緩存提高查詢效率,但是仍然有進一步優化的空間,于是想到了比分布式緩存性能更好的本地緩存,因此對領域內常用的本地緩存進行了一番調研,有早期的Guava緩存、在Guava上進一步傳承的Caffine以及自稱在Java中使用最廣泛的EhCache,那么我們該怎么選擇適合自己應用的緩存呢,小編下面會簡單介紹,并將以上緩存進行一個對比,希望幫助大家選擇最適合自己系統的本地緩存。
2、Guava緩存簡介
Guava cache是Google開發的Guava工具包中一套完善的JVM本地緩存框架,底層實現的數據結構類似于ConcurrentHashMap,但是進行了更多的能力拓展,包括緩存過期時間設置、緩存容量設置、多種淘汰策略、緩存監控等,下面簡單介紹下這些功能及其使用方式。
2.1、緩存過期時間設置
Guava的過期時間設置有基于創建時間和最后一次訪問時間兩種策略.
(1) 基于創建時間
通過對比緩存記錄的插入時間來判斷,比如設置過期時間為5分鐘,不管中間有沒有訪問,到時過期。
public Cache createCache() { return CacheBuilder.newBuilder() .expireAfterWrite(5L, TimeUnit.MINUTES) .build(); }
(2) 基于過期時間
通過對比最近最后一次的訪問時間,比如設置5分鐘,每次訪問之后都會刷新過期時間為5分鐘,只有持續5分鐘沒有被訪問到才會過期。
public Cache createCache() {
return CacheBuilder.newBuilder()
.expireAfterAccess(5L, TimeUnit.MINUTES)
.build();
}
2.2、緩存容量和淘汰策略設置
Guava cache是內存型緩存,有內存溢出風險,因此需要設置緩存的最大存儲上限,通過緩存的條數或每條緩存的權重來判斷是否達到了設定閾值,當緩存的數據量達到設定閾值之后,Guava cache支持使用FIFO和LRU的策略對緩存記錄采取淘汰的措施。
(1)限制緩存記錄條數
public Cache createCache() {
return CacheBuilder.newBuilder()
.maximumSize(100L)
.build();
}
(2)限制緩存記錄權重
public Cache createCache() {
return CacheBuilder.newBuilder()
.maximumWeight(100L)
.weigher((key, value) -> (int) Math.ceil(instrumentation.getObjectSize(value) / 1024L))
.build();
}
使用限制緩存記錄權重時要先計算weight的value對象的字節數,每1kb字節作為一個權重,對比限制緩存記錄,我們就能將緩存的總占用限制在100kb左右。
2.3緩存監控
緩存記錄的加載和命中情況是評價緩存處理能力的重要指標,Guava cache提供了stat統計日志對這兩個指標進行了統計,我們只需要在創建緩存容器的時候加上recordStats就可以開啟統計。
public Cache createCache() {
return CacheBuilder.newBuilder()
.recordStats()
.build();
}
2.4 Guava cache的優劣勢和適用場景
優劣勢:Guava cache通過內存處理數據,具有減少IO請求,讀寫性能快的優勢,但是受內存容量限制,只能處理少量數據的讀寫,還有可能對本機內存造成壓力,并且在分布式部署中,會存在不同機器節點數據不一致的情況,即緩存漂移。
適用場景:讀多寫少,對數據一致性要求不高的場景。
3、Caffeine簡介
Caffeine同樣是Google開發的,是在Guava cache的基礎上改良而來的,底層設計思路、功能和使用方式與Guava非常類似,但是各方面的性能都要遠遠超過前者,可以看做是Guava cache的升級版,因此,之前使用過Guava cache,也能夠很快的上手Caffeine,下面是Caffeine和Guava cache的緩存創建對比,基本可以無門檻過渡。
public Cache createCache() {
return Caffeine.newBuilder()
.initialCapacity(1000)
.maximumSize(100L)
.expireAfterWrite(5L, TimeUnit.MINUTES)
.recordStats()
.build();
}
public Cache createCache() {
return CacheBuilder.newBuilder()
.initialCapacity(1000)
.maximumSize(100L)
.expireAfterWrite(5L, TimeUnit.MINUTES)
.recordStats()
.build();
}
那么Caffeine底層又做了哪些優化,才能讓其性能高于Guava cache呢?主要包含以下三點:
3.1、對比Guava cache的性能主要優化項
(1)異步策略
Guava cache在讀操作中可能會觸發淘汰數據的清理操作,雖然自身也做了一些優化來減少讀的時候的清理操作,但是一旦觸發,就會降低查詢效率,對緩存性能產生影響。而在Caffeine支持異步操作,采用異步處理的策略,查詢請求在觸發淘汰數據的清理操作后,會將清理數據的任務添加到獨立的線程池中進行異步操作,不會阻塞查詢請求,提高了查詢性能。
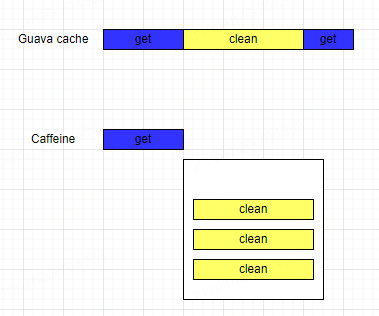
?
(2)ConcurrentHashMap優化
Caffeine底層都是通過ConcurrentHashMap來進行數據的存儲,因此隨著Java8中對ConcurrentHashMap的調整,數組+鏈表的結構升級為數組+鏈表+紅黑樹的結構以及分段鎖升級為syschronized+CAS,降低了鎖的粒度,減少了鎖的競爭,這兩個優化顯著提高了Caffeine在讀多寫少場景下的查詢性能。
?
(3)新型淘汰算法W-TinyLFU
傳統的淘汰算法,如LRU、LFU、FIFO,在實際的緩存場景中都存在一些弊端,如FIFO算法,如果緩存使用的頻率較高,那么緩存數據會一直處在進進出出的狀態,間接影響到緩存命中率。LRU算法,在批量刷新緩存數據的場景下,可能會將其他緩存數據淘汰掉,從而帶來緩存擊穿的風險。LFU算法,需要保存緩存記錄的訪問次數,帶來內存空間的損耗。
因此,Caffeine引入了W-TinyLFU算法,由窗口緩存、過濾器、主緩存組成。緩存數據剛進入時會停留在窗口緩存中,這個部分只占總緩存的1%,當被擠出窗口緩存時,會在過濾器匯總和主緩存中淘汰的數據進行比較,如果頻率更高,則進入主緩存,否則就被淘汰,主緩存被分為淘汰段和保護段,兩段都是LRU算法,第一次被訪問的元素會進入淘汰段,第二次被訪問會進入保護段,保護段中被淘汰的元素會進入淘汰段,這種算法實現了高命中率和低內存占用。更詳細的解釋可以參考論文:https://arxiv.org/pdf/1512.00727.pdf?
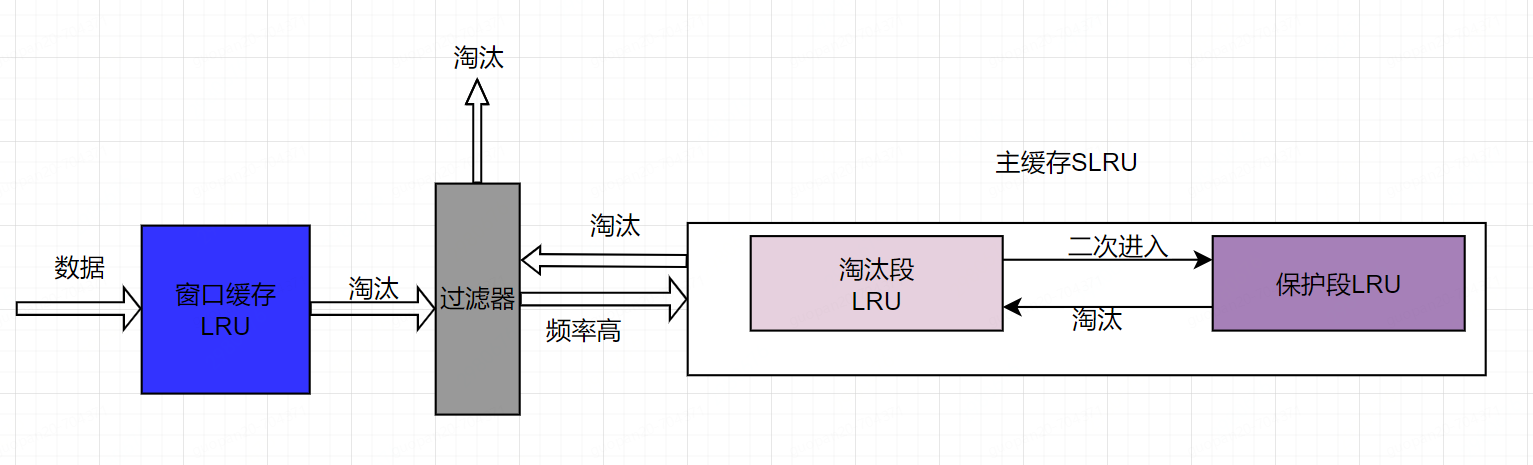
3.2、Caffeine的優劣勢和適用場景
優勢:對比Guava cache有更高的緩存性能,劣勢:仍然存在緩存漂移的問題;JDK版本過低無法使用
適用場景:1、適用場景:讀多寫少,對數據一致性要求不高的場景;2、純內存緩存,JDK8及更高版本中,追求比Guava cache更高的性能。
4、Ehcache簡介
Guava cache和Caffeine都是JVM緩存,會受到內存大小的制約,最新的Ehcache采用堆內緩存+堆外緩存+磁盤的方式,打破了這一制約。堆內緩存就是被JVM管理的那一部分緩存,而堆外緩存,就是在內存中另外在開辟一塊不被JVM管理的部分。堆外緩存這部分既可以享受內存的高速讀寫能力,而且又避免的JVM頻繁的GC,缺點是需要自行清理數據。
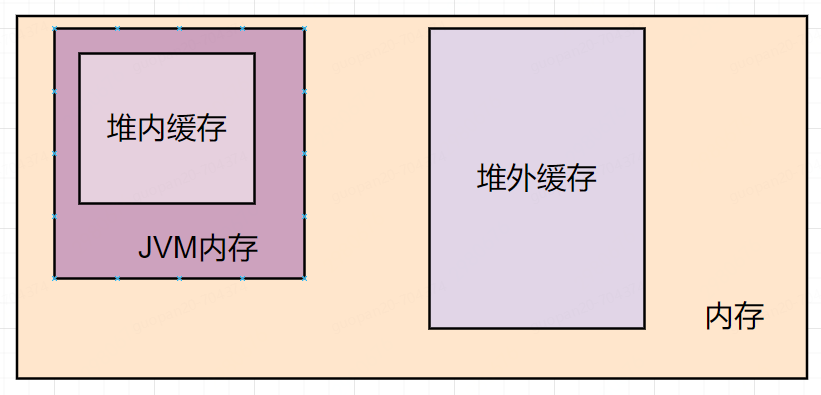
下面是Ehcache緩存的創建,指定了堆內、堆外緩存和磁盤緩存的大小。
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(20, MemoryUnit.MB)
.offheap(10, MemoryUnit.MB)
.disk(5, MemoryUnit.GB);
為了解決緩存漂移的問題,Ehcache支持通過集群的方式,實現了分布式節點之間的數據互通。關于Ehcache的集群策略,后續文章再詳細闡述。
5、不同本地緩存對比
| 框架 | 命中率 | 速度 | 回收算法 | 使用難度 | 集群 | 適用場景 |
|---|---|---|---|---|---|---|
| Guava cache | 中 | 第三 | LRU、LFU、FIFO | 易 | 不支持 | 讀多寫少,允許少量緩存偏移 |
| Caffeine | 高 | 第一 | W-TinyLFU | 易 | 不支持 | 讀多寫少,允許少量緩存偏移,能用Caffeine就別用Guava cache |
| Ehcache | 中 | 第二 | LRU、LFU、FIFO | 中 | 支持 | 分布式系統中對數據一致性要求高 |
?
-
JAVA
+關注
關注
19文章
2960瀏覽量
104562 -
緩存
+關注
關注
1文章
233瀏覽量
26649 -
Redis
+關注
關注
0文章
371瀏覽量
10848
發布評論請先 登錄
相關推薦
高并發系統中的緩存 緩存系統存在的三大問題
本地緩存的技術實踐
如何選擇合適的本地緩存?
Mybatis緩存之一級緩存
什么是Web緩存,HTTP緩存和瀏覽器緩存的區別

ThingJS平臺推出3D場景本地緩存技術
聊聊本地緩存和分布式緩存
如何在 Linux 上查看本地 DNS 緩存

Ehcache!這才是Java本地緩存之王!






 工商網監
工商網監
評論