 數據倉庫的基本架構及架構圖介紹
數據倉庫的基本架構及架構圖介紹
數據倉庫簡介
數據倉庫,英文名稱為DataWarehouse,可簡寫為DW或DWH。數據倉庫,是為企業所有級別的決策制定過程,提供所有類型數據支持的戰略集合。它是單個數據存儲,出于分析性報告和決策支持目的而創建。為需要業務智能的企業,提供指導業務流程改進、監視時間、成本、質量以及控制。
數據倉庫的用途
2.產生業務報表,用于作出決策
3.為網站運營提供運營上的數據支持
4.可以作為各個業務的數據源,形成業務數據互相反饋的良性循環
5.分析用戶行為數據,通過數據挖掘來降低投入成本,提高投入效果
6.開發數據產品,直接或間接地為公司盈利
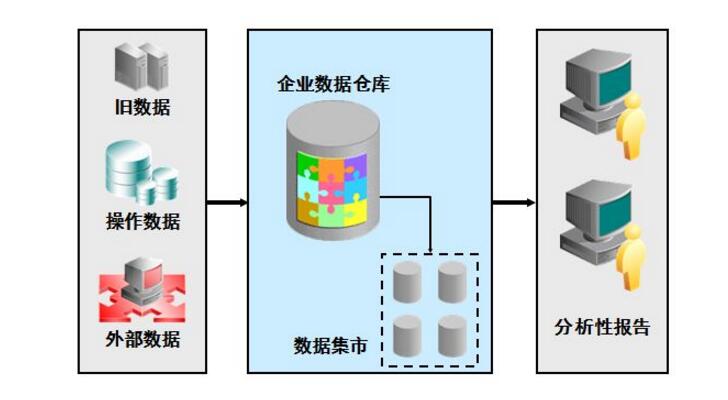
數據倉庫分層的原因
1通過數據預處理提高效率,因為預處理,所以會存在冗余數據
2如果不分層而業務系統的業務規則發生變化,就會影響整個數據清洗過程,工作量巨大
3通過分層管理來實現分步完成工作,這樣每一層的處理邏輯就簡單了
標準的數據倉庫分層:ods(臨時存儲層),pdw(數據倉庫層),mid(數據集市層),app(應用層)
ods:歷史存儲層,它和源系統數據是同構的,而且這一層數據粒度是最細的,這層的表分為兩種,一種是存儲當前需要加載的數據,一種是用于存儲處理完后的數據。
pdw:數據倉庫層,它的數據是干凈的數據,是一致的準確的,也就是清洗后的數據,它的數據一般都遵循數據庫第三范式,數據粒度和ods的粒度相同,它會保存bi系統中所有歷史數據
mid:數據集市層,它是面向主題組織數據的,通常是星狀和雪花狀數據,從數據粒度將,它是輕度匯總級別的數據,已經不存在明細的數據了,從廣度來說,它包含了所有業務數量。從分析角度講,大概就是近幾年
app:應用層,數據粒度高度匯總,倒不一定涵蓋所有業務數據,只是mid層數據的一個子集。

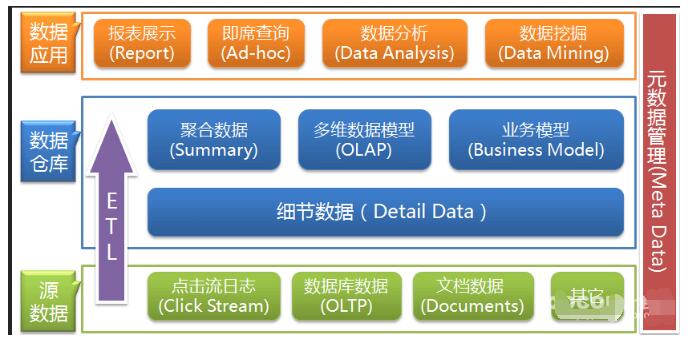
數據倉庫的架構圖介紹
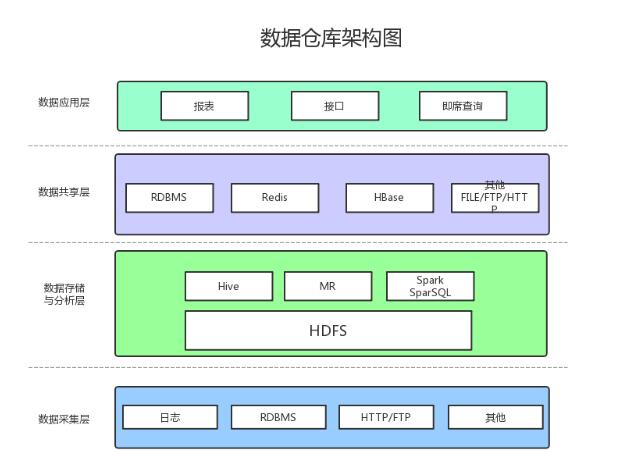
1、數據采集
數據采集層的任務就是把數據從各種數據源中采集和存儲到數據存儲上,期間有可能會做一些ETL操作。
數據源種類可以有多種:
日志:所占份額最大,存儲在備份服務器上
來自HTTP/FTP的數據:合作伙伴提供的接口
其他數據源:如Excel等需要手工錄入的數據
2、數據存儲與分析
HDFS是大數據環境下數據倉庫/數據平臺最完美的數據存儲解決方案。
離線數據分析與計算,也就是對實時性要求不高的部分,Hive是不錯的選擇。
使用Hadoop框架自然而然也提供了MapReduce接口,如果真的很樂意開發Java,或者對SQL不熟,那么也可以使用MapReduce來做分析與計算。
Spark性能比MapReduce好很多,同時使用SparkSQL操作Hive。
3、數據共享
前面使用Hive、MR、Spark、SparkSQL分析和計算的結果,還是在HDFS上,但大多業務和應用不可能直接從HDFS上獲取數據,那么就需要一個數據共享的地方,使得各業務和產品能方便的獲取數據。
這里的數據共享,其實指的是前面數據分析與計算后的結果存放的地方,其實就是關系型數據庫和NOSQL數據庫。
4、數據應用
報表:報表所使用的數據,一般也是已經統計匯總好的,存放于數據共享層。
接口:接口的數據都是直接查詢數據共享層即可得到。
即席查詢:即席查詢通常是現有的報表和數據共享層的數據并不能滿足需求,需要從數據存儲層直接查詢。一般都是通過直接操作SQL得到。
理想的數據倉庫架構
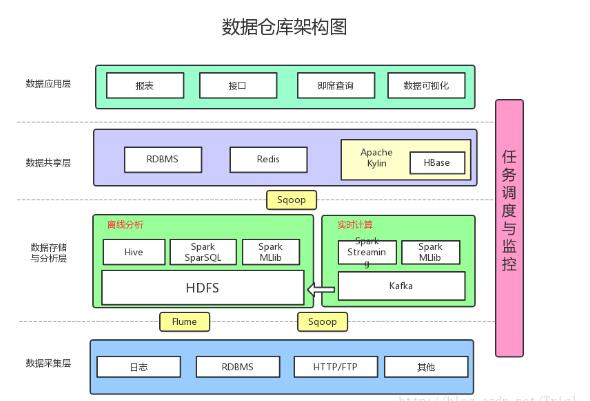
增加了以下內容:
數據采集:采用Flume收集日志,采用Sqoop將RDBMS以及NoSQL中的數據同步到HDFS上
消息系統:可以加入Kafka防止數據丟失
實時計算:實時計算使用SparkStreaming消費Kafka中收集的日志數據,實時計算結果大多保存在Redis中
多維分析OLAP:使用Kylin作為OLAP引擎
數據可視化:提供可視化前端頁面,方便運營等非開發人員直接查詢
-
數據倉庫
+關注
關注
0文章
61瀏覽量
10431
發布評論請先 登錄
相關推薦
基于阿里云數加MaxCompute的企業大數據倉庫架構建設思路
RT-Thread 架構圖
PCIE基本概念與拓撲架構圖
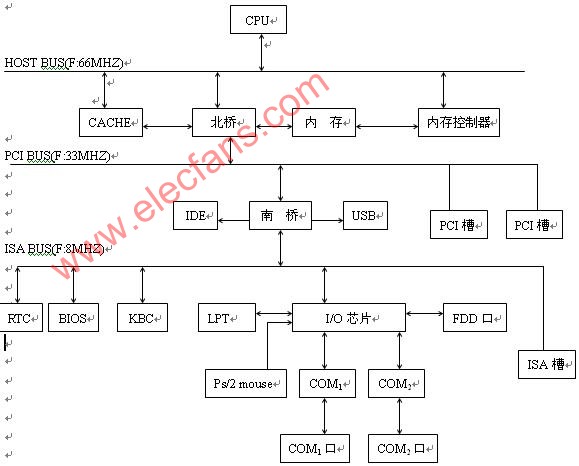
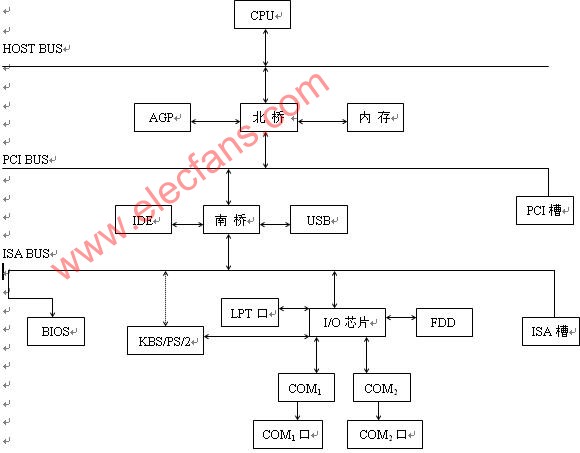
什么是paas平臺_paas邏輯架構圖






 工商網監
工商網監
評論