 AI推理CPU當道,Arm驅動高效引擎
AI推理CPU當道,Arm驅動高效引擎
AI的訓練和推理共同鑄就了其無與倫比的處理能力。在AI訓練方面,GPU因其出色的并行計算能力贏得了業界的青睞,成為了當前AI大模型最熱門的芯片;而在 AI 推理方面,具備卓越通用性和靈活性的CPU本應發揮關鍵作用,但其重要性卻常常被忽視。
“對于那些希望將大語言模型(LLM)集成到產品和服務中的企業和開發者來說,CPU 通常是首選”。Arm 中國區業務全球副總裁鄒挺在接受采訪時表示。為了適應AI推理的應用落地,CPU有針對性的優化必不可少,Arm Neoverse平臺通過增加如SVE2指令集使得AI 推理具有更好的性能和效率。

Arm中國區業務全球副總裁 鄒挺
CPU對于AI推理的重要性
CPU長期以來廣泛應用于傳統的AI和機器學習任務,其通用性和靈活性使其在部署AI推理時更具優勢。鄒挺表示,在AI場景落地初期,專用AI處理器的開發周期較長,因此,高能效CPU 自然成為了推理的核心;隨著 AI 技術的深入發展和應用場景的多樣化,定制化專用 AI 加速器應運而生。在這一過程中,高能效的CPU不僅作為核心控制單元,還與 GPU、NPU、FPGA、ASIC 等異構單元協同工作,管理和調度系統資源,成為AI推理的“靈魂捕手”。
相比于單純依賴 GPU 的高成本和高功耗,CPU在推理過程中具有更高的能效比。CPU 的設計更適合處理多任務負載,并且無需復雜的冷卻和電力解決方案。這使得CPU在大規模部署中能夠以更低的成本運行,特別是在資源受限的環境中,其低功耗的特性尤為顯著。這對于那些需要長期、穩定運行的 AI 應用來說,是一個可持續且經濟高效的選擇。
Arm Neoverse平臺集成SVE2技術,對AI計算至關重要
Arm Neoverse CPU在 AI 推理中展現了其獨特優勢,這一點要從其技術底層開始剖析。
鄒挺分析,Armv9架構已經引入 Arm Neoverse 平臺,在Armv9架構中Arm 集成SVE2(可擴展向量擴展)指令集。SVE2 作為一種可擴展的向量處理技術,允許處理器同時執行多個數據元素操作,從而提供了更高效的向量計算和AI 硬件加速。
SVE2 在AI推理中的一個關鍵應用是矩陣運算。矩陣乘法是許多AI任務中的常見計算,而 SVE2 向量指令可以同時處理多個數據元素,使矩陣乘法能夠以向量化的方式進行,從而提高了計算效率。
例如,SVE2 中的 FMMLA 指令可以實現 FP32 格式下的矩陣乘法,BFMMLA 指令能夠在 BF16 格式下進行高效運算,而 UMMLA、SMMLA 等指令則優化了 INT8 格式下的矩陣運算。通過這些指令和硬件加速功能,AI 推理在Arm架構上能夠實現更高效的矩陣運算和更優的能效比。
這種技術不僅提升了 AI 推理中矢量運算的效率,尤其是在深度學習和自然語言處理(NLP)等核心任務上,加快了推理速度,并在能效表現上進行了優化。通過 SVE2 的支持,Arm Neoverse CPU 可以在邊緣計算和資源受限的環境中高效運行,從而減少對 GPU 和其他硬件資源的依賴。
基于Arm Neoverse的CPU顯著提升推理性能
亞馬遜云服務(AWS)、微軟、Google和甲骨文 (Oracle) 等全球最大的 AI 頭部云服務提供商們都通過 Arm Neoverse 進行通用計算和基于 CPU 的 AI 推理與訓練。Arm Neoverse 不僅為這些頭部云服務商提供了定制芯片的靈活性,還優化了嚴苛的工作負載,確保在每瓦功率的使用上實現更高的計算效率。
例如,基于Arm架構的AWS Graviton,與其他同行業產品相比,Amazon Sagemaker 的 AI 推理性能提高了 25%,Web 應用程序提高了 30%,數據庫提高了 40%,效率則提升了 60%。基于 Arm 架構的 Google Cloud Axion,與傳統架構相比,其性能和能效分別提高了 50% 和 60%,可為基于 CPU 的 AI 推理和訓練、YouTube、Google 地球等服務提供支持。
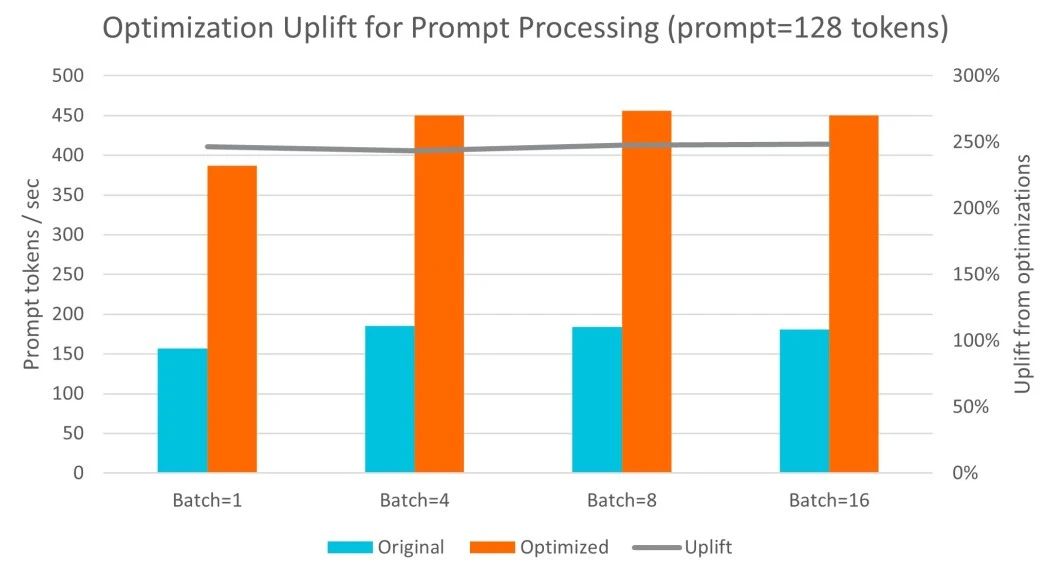
基于 Arm Neoverse N2 架構的阿里云倚天 710,在運行 Llama 3 和 Qwen1.5 等業內標準大語言模型時展現了極高的靈活性和擴展性。通過與 Arm 軟件團隊的緊密合作,阿里云對 llama.cpp 中的 int4 和 int8 GEMM 內核進行了優化,特別是利用了 SMMLA 指令來提高計算效率。在 ecs.g8y.16xlarge 實例上(配置64個 vCPU 和 256GB 內存),多次實驗結果顯示,每秒處理的詞元數量增加了 2.7 倍。此外,詞元生成的吞吐量在處理更大批次數據時最多提高了 1.9 倍。詞元生成的延遲對于交互式 LLM 部署非常關鍵。實驗表明,阿里云倚天 710 在單次操作和批量處理場景下均能保持 100 毫秒以內的延遲目標,這符合人們每秒 5-10 個單詞的典型閱讀速度。因此,這一架構非常適合常規體量的 LLM 部署。
與其他服務器 CPU 的對比中,阿里云倚天 710 的優勢顯著。在與 Intel Icelake 和 Sapphire Rapids 的對比中,倚天 710 在提示詞處理性能上提升了 3.2 倍,詞元生成性能則提升了 2.2 倍。這表明,倚天 710 不僅在處理性能上有明顯優勢,其成本效益也極具吸引力,成為了 LLM 推理應用中的理想選擇。
小模型的推理優化
越來越多的企業將開發重心轉向小語言模型(Small Language Models, SLM)或小型 LLM,小模型尤其是在處理對話、翻譯、摘要、分類等任務時,效率更高且耗能更少。與需要高昂的基礎設施成本和復雜漫長的開發部署周期的大語言模型相比,這些模型在訓練過程中消耗的電力也相對較低,適合更靈活、可定制的應用場景。
鄒挺分析,在提升模型效率方面,量化技術是一個重要的優化手段。通過將神經網絡的權重降低到更低的精度,量化技術顯著減少了模型的內存和計算需求。比如,將16位浮點數壓縮為4位整數,可以大幅降低內存占用和計算成本,同時對精度的影響微乎其微。
以 Llama 2 模型為例,原本擁有 70 億參數的模型在量化后,從 13.5 GB 縮減至 3.9 GB;130 億參數的版本從 26.1 GB 縮減至7.3 GB;而700 億參數模型則從 138 GB 減少至 40.7 GB。這些優化顯著提升了模型的運行速度,同時降低了在 CPU 上運行的成本。
結合高效的 Arm CPU 技術,這些優化讓輕量級模型可以直接在移動設備上運行,不僅提升了性能,還實現了數據隱私保護和用戶體驗的優化。
他進一步表示,在針對 FunASR 語音識別模型的優化方面,Arm 充分利用了Armv9 架構中的 SVE2 指令、BF16 數據類型等特性,并引入了動態量化技術,使得 FunASR 模型在 Arm Neoverse 服務器上實現了高效運行。FunASR 是阿里巴巴達摩院開發的開源大模型,基于 Paraformer 架構,具備語音識別、語音端點檢測、標點恢復、語言模型、說話人驗證和分離等多種功能。
SVE2 指令集在Arm架構處理器中,對 INT8 數據的并行處理非常高效,一次指令周期可以完成 16 個 INT8 的乘累加操作。因此,在對模型執行效率有更高要求的場景下,可以采用 INT8 動態量化來提升效率。此外,INT8 和 BF16 的數據格式組合也進一步優化了模型計算效率,在保持精度的前提下,實現了 1. 5 倍的效率提升。這樣的優化確保了 FunASR 等大模型在 Arm 架構上的高效運行,使其能夠在特定領域 AI 應用中發揮重要作用。
不斷優化AI推理的性能與能耗
當前全球數據中心每年消耗約460太瓦時的電力,隨著AI技術和應用的快速發展,這一數字預計在2030年將增長至當前的三倍。目前,數據中心中約有85%的AI負載用于推理任務,這些任務涵蓋了眾多應用和設備。
Arm Neoverse的架構不僅提升了云端計算的性能和能效,還為大規模云服務提供商和數據中心優化了TCO。例如,基于Arm Neoverse 平臺的 AWS Graviton3 在AI推理過程中節約了50%的成本。
據悉,Arm在Neoverse的產品線目前有V、N、E三個平臺系列,其中Neoverse V與Neoverse N又進一步推出計算子系統CSS產品,為想快速推出產品,掌握人工智能機遇的合作伙伴,縮減產品開發時間,加速產品上市進程。
迄今為止,合作伙伴基于Arm架構的芯片出貨量已達到 3,000 億顆,這一龐大的市場基礎使Arm能夠支持各種AI 技術領域的發展,并成為推動AI創新的重要平臺。AI 推理正從集中在云端擴展到更多的邊緣應用,以實現更廣泛的覆蓋和更高效的響應。
鄒挺說道: “從移動設備到 AI 領域,高性能和出色能效始終是Arm的DNA。Arm 將繼續推動 AI 的技術變革,帶來更高效、更可持續的計算解決方案,確保我們的技術能夠支持合作伙伴在 AI 時代的多樣化需求,同時推動 AI 技術在更多領域的廣泛落地和普及。”
-
ARM
+關注
關注
134文章
9057瀏覽量
366873
發布評論請先 登錄
相關推薦
Arm成功將Arm KleidiAI軟件庫集成到騰訊自研的Angel 機器學習框架
CPU推理:AI算力配置新范式

高效大模型的推理綜述

NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案

李開復:中國擅長打造經濟實惠的AI推理引擎
澎峰科技高性能大模型推理引擎PerfXLM解析

OpenAI開啟推理算力新Scaling Law,AI PC和CPU的機會來了
AMD助力HyperAccel開發全新AI推理服務器

Arm CPU如何推動AI創新
基于Arm平臺的服務器CPU在LLM推理方面的能力
基于CPU的大型語言模型推理實驗







 工商網監
工商網監
評論