 在設備上利用AI Edge Torch生成式API部署自定義大語言模型
在設備上利用AI Edge Torch生成式API部署自定義大語言模型
我們很高興地發布 AI Edge Torch 生成式 API,它能將開發者用 PyTorch 編寫的高性能大語言模型 (LLM) 部署至 TensorFlow Lite (TFLite) 運行時,從而無縫地將新的設備端生成式 AI 模型部署到邊緣設備上。本文是 Google AI Edge 博客連載的第二篇。上一篇文章為大家介紹了 Google AI Edge Torch,該產品可以在使用 TFLite 運行時的設備上實現高性能的 PyTorch 模型推理。
AI Edge Torch 生成式 API 使開發者能夠在設備上引入強大的新功能,例如摘要生成、內容生成等。我們之前已經通過 MediaPipe LLM Inference API 讓開發者們能夠將一些最受歡迎的 LLM 部署到設備上。現在,我們很高興能進一步拓展對模型的支持范圍,并讓大家部署到設備,而且具備優秀的性能表現。今天發布的 AI Edge Torch 生成式 API 是初始版本,提供以下功能:
簡單易用的模型創作 API,支持自定義 Transformer。
在 CPU 上性能表現出色,并即將支持 GPU 和 NPU。
作為 AI Edge Torch 的擴展,支持 PyTorch。
完全兼容現有的 TFLite 部署流程,包括量化和運行時。
支持 TinyLlama、Phi-2 和 Gemma 2B 等模型。
兼容 TFLite 運行時和 Mediapipe LLM 運行時接口,支持 Android、iOS 和 Web。
MediaPipe LLM Inference API
https://ai.google.dev/edge/mediapipe/solutions/genai/llm_inference
AI Edge Torch
https://ai.google.dev/edge/lite/models/convert_pytorch
我們將在本文中為大家深入介紹該 API 的性能、可移植性、創作開發體驗、端到端推理流水線和調試工具鏈。更具體的文檔和示例請查看: https://github.com/google-ai-edge/ai-edge-torch/tree/main/ai_edge_torch/generative/examples
性能表現
為了讓 MediaPipe LLM Inference API 順利支持最受歡迎的一些 LLM,我們的團隊手工打造了幾款在設備上擁有最佳性能的 Transformer 模型。通過這項工作,我們確定了幾個主要課題: 如何有效地表示注意力機制、量化的使用以及良好的 KV 緩存。生成式 API 很好地完成了這些課題 (本文后面會具體提到),而且依然能達到之前手寫版本性能的 90% 以上,并大大提高開發速度。
通過 MediaPipe 和 TensorFlow Lite 在設備上運行大語言模型 https://developers.googleblog.com/en/large-language-models-on-device-with-mediapipe-and-tensorflow-lite/
下表顯示了三種模型樣本的關鍵基準測試結果:
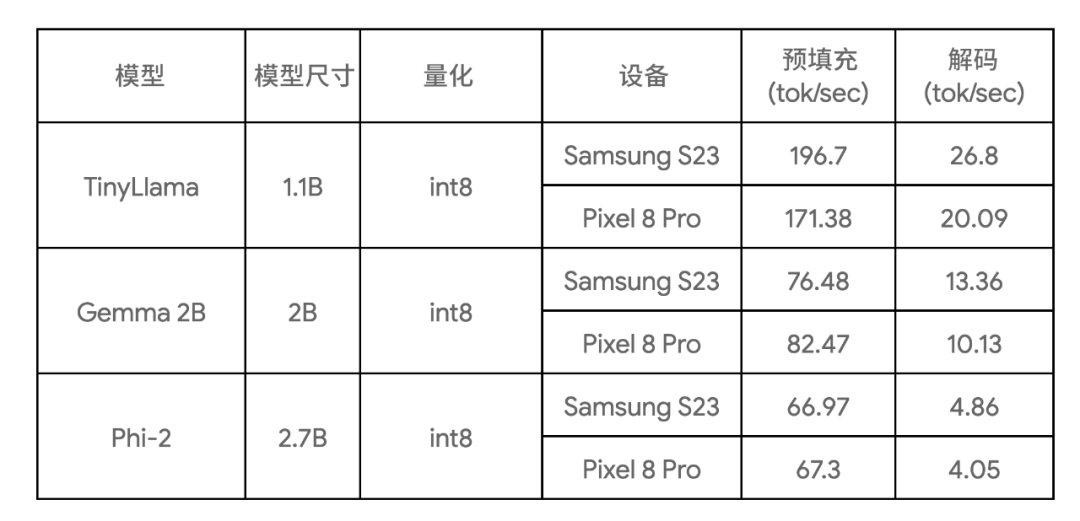
三種模型樣本 https://github.com/google-ai-edge/ai-edge-torch/blob/main/ai_edge_torch/generative/examples/README.md
這些基準測試是在大核上運行,使用 4 個 CPU 線程,并且使用了這些模型在所列設備上目前所知最快的 CPU 實現。
創作體驗
核心創作庫提供了常見 Transformer 模型 (僅編碼器、僅解碼器或編碼-解碼器等樣式) 的基本構建模塊。您可以用它從頭開始創作模型,或重新創作現有模型以提高性能。我們建議大多數用戶采用重新創作的方式,因為這樣就不需要訓練 / 微調的步驟了。使用生成式 API 創作的核心優勢如下:
一組針對可轉換性、性能和平臺可移植性進行了優化的核心 Transformer 構建模塊,可以輕松與常規 PyTorch 算子進行混合和匹配。
一個簡單的權重重映射機制。
直觀的量化 API。
支持多簽名導出,包括預填充、解碼或自定義簽名,并能無縫接入現成的 MP 任務 / LLM Inference API。
作為示例,下面展示如何使用新的生成式 API 以約 50 行 Python 代碼重新創作 TinyLLama (1.1B) 的核心功能。
TinyLLama (1.1B)
https://github.com/jzhang38/TinyLlama
步驟 1: 定義模型結構
import torch
import torch.nn as nn
from ai_edge_torch.generative.layers.attention import TransformerBlock
import ai_edge_torch.generative.layers.attention_utils as attn_utils
import ai_edge_torch.generative.layers.builder as builder
import ai_edge_torch.generative.layers.model_config as cfg
class TinyLLamma(nn.Module):
def __init__(self, config: cfg.ModelConfig):
super().__init__()
self.config = config
# Construct model layers.
self.lm_head = nn.Linear(
config.embedding_dim, config.vocab_size, bias=config.lm_head_use_bias
)
self.tok_embedding = nn.Embedding(
config.vocab_size, config.embedding_dim, padding_idx=0
)
self.transformer_blocks = nn.ModuleList(
TransformerBlock(config) for _ in range(config.num_layers)
)
self.final_norm = builder.build_norm(
config.embedding_dim,
config.final_norm_config,
)
self.rope_cache = attn_utils.build_rope_cache(
size=config.kv_cache_max,
dim=int(config.attn_config.rotary_percentage * config.head_dim),
base=10_000,
condense_ratio=1,
dtype=torch.float32,
device=torch.device("cpu"),
)
self.mask_cache = attn_utils.build_causal_mask_cache(
size=config.kv_cache_max, dtype=torch.float32, device=torch.device("cpu")
)
self.config=config
步驟 2: 定義模型的前向函數
@torch.inference_mode
def forward(self, idx: torch.Tensor, input_pos: torch.Tensor) -> torch.Tensor:
B, T = idx.size()
cos, sin = self.rope_cache
cos = cos.index_select(0, input_pos)
sin = sin.index_select(0, input_pos)
mask = self.mask_cache.index_select(2, input_pos)
mask = mask[:, :, :, : self.config.kv_cache_max]
# forward the model itself
x = self.tok_embedding(idx) # token embeddings of shape (b, t, n_embd)
for i, block in enumerate(self.transformer_blocks):
x = block(x, (cos, sin), mask, input_pos)
x = self.final_norm(x)
res = self.lm_head(x) # (b, t, vocab_size)
returnres
步驟 3: 映射舊模型權重
您可以使用庫中的 ModelLoaderAPI 輕松映射權重,就像這樣:
import ai_edge_torch.generative.utilities.loader as loading_utils # This map will associate old tensor names with the new model. TENSOR_NAMES = loading_utils.ModelLoader.TensorNames( ff_up_proj="model.layers.{}.mlp.up_proj", ff_down_proj="model.layers.{}.mlp.down_proj", ff_gate_proj="model.layers.{}.mlp.gate_proj", attn_query_proj="model.layers.{}.self_attn.q_proj", attn_key_proj="model.layers.{}.self_attn.k_proj", attn_value_proj="model.layers.{}.self_attn.v_proj", attn_output_proj="model.layers.{}.self_attn.o_proj", pre_attn_norm="model.layers.{}.input_layernorm", pre_ff_norm="model.layers.{}.post_attention_layernorm", embedding="model.embed_tokens", final_norm="model.norm", lm_head="lm_head", )
完成這些步驟后,您可以運行一些示例輸入來驗證重新創作過的模型的數值正確性。如果數值檢查達標,您就可以繼續進行后續的轉換和量化操作。
驗證重新創作的模型
https://github.com/google-ai-edge/ai-edge-torch/blob/59946008def0ab867c2f4cd8931eaf607ac0d768/ai_edge_torch/generative/test/test_model_conversion.py#L132
轉換和量化
通過 ai_edge_torch 提供的轉換 API,您可以將 (重新創作的) Transformer 模型轉換為高度優化的 TensorFlow Lite 模型。轉換過程包含以下關鍵步驟:
導出到 StableHLO。通過 torch dynamo 編譯器對 PyTorch 模型進行追蹤和編譯,生成帶有 Aten 算子的 FX 計算圖,然后由 ai_edge_torch 將其降為 StableHLO 計算圖。
ai_edge_torch 在 StableHLO 上執行進一步的編譯器操作,包括算子融合 / 折疊等,生成高性能的 TFLite flatbuffer (包含用于 SDPA、KVCache 的融合算子)。
StableHLO
https://github.com/openxla/stablehlo
量化
核心生成式 API 庫還提供了一組量化 API,涵蓋了常見的 LLM 量化模式。這些模式作為額外參數傳遞給 ai_edge_torch 轉換器 API,由該 API 自動完成量化。我們會在未來的版本中提供更多的量化模式。
多簽名導出
我們發現在實際推理場景中,LLM 模型需要有明確分離 (細分) 的推理函數 (預填充、解碼),才能實現最佳的服務性能。這部分基于這樣的觀察: 預填充 / 解碼可能需要采用不同的 tensor 形狀,預填充受到算力限制,而解碼則受到內存限制。對于大型 LLM,避免在預填充 / 解碼之間重復模型權重至關重要。我們使用 TFLite 和 ai_edge_torch 中現有的多簽名特性來實現這一點,使得開發者能輕松地為模型定義多個入口,如下所示:
def convert_tiny_llama_to_tflite(
prefill_seq_len: int = 512,
kv_cache_max_len: int = 1024,
quantize: bool = True,
):
pytorch_model = tiny_llama.build_model(kv_cache_max_len=kv_cache_max_len)
# Tensors used to trace the model graph during conversion.
prefill_tokens = torch.full((1, prefill_seq_len), 0, dtype=torch.long)
prefill_input_pos = torch.arange(0, prefill_seq_len)
decode_token = torch.tensor([[0]], dtype=torch.long)
decode_input_pos = torch.tensor([0], dtype=torch.int64)
# Set up Quantization for model.
quant_config = quant_recipes.full_linear_int8_dynamic_recipe() if quantize else None
edge_model = (
ai_edge_torch.signature(
'prefill', pytorch_model, (prefill_tokens, prefill_input_pos)
)
.signature('decode', pytorch_model, (decode_token, decode_input_pos))
.convert(quant_config=quant_config)
)
edge_model.export(f'/tmp/tiny_llama_seq{prefill_seq_len}_kv{kv_cache_max_len}.tflite')
針對 LLM 的性能優化
我們在性能調查階段發現了幾個改善 LLM 性能的關鍵要素:
高性能的 SDPA 和 KVCache: 我們發現,如果沒有足夠的編譯器優化 / 融合,轉換后的 TFLite 模型會因為這些函數中算子的粒度問題,性能不會很好。為了解決這個問題,我們引入了高級函數邊界和 StableHLO 復合算子。
利用 TFLite 的 XNNPack 代理進一步加速 SDPA: 確保大量 MatMul / 矩陣-向量計算得到很好的優化至關重要。XNNPack 庫能在廣泛的移動 CPU 上以出色的性能完成這些基礎計算。
避免不必要的計算: 靜態形狀模型如果在預填充階段有長且固定的輸入消息大小,或者在解碼階段有大的固定序列長度,則帶來的計算量會大于該模型需要的最小計算量。
運行時內存消耗: 我們在 TFLite 的 XNNPack 代理中引入了權重緩存 / 預打包機制,顯著降低了內存的峰值使用量。
SDPA
https://github.com/google-ai-edge/ai-edge-torch/blob/7f52f70709bc12cf041b3b1fd4a49bc0d52c889a/ai_edge_torch/generative/layers/attention.py#L74
部署
LLM 推理通常涉及許多預處理 / 后處理步驟和復雜的編排,例如令牌化、采樣和自回歸解碼邏輯。為此,我們提供了基于 MediaPipe 的解決方案以及一個純 C++ 推理示例。
基于 MediaPipe 的解決方案
https://ai.google.dev/edge/mediapipe/solutions/genai/llm_inference
純 C++ 推理示例
https://github.com/google-ai-edge/ai-edge-torch/tree/main/ai_edge_torch/generative/examples/c%2B%2B
使用 MediaPipe LLM Inference API
MediaPipe LLM Inference API 是一個高級 API,支持使用 prompt-in / prompt-out 接口進行 LLM 推理。它負責處理底層所有的 LLM 復雜流水線操作,讓模型得以更輕松和順暢地部署。要使用 MediaPipe LLM Inference API 進行部署,您需要使用給定的預填充和解碼簽名來轉換模型,并創建一個任務包,如下方代碼所示:
def bundle_tinyllama_q8():
output_file = "PATH/tinyllama_q8_seq1024_kv1280.task"
tflite_model = "PATH/tinyllama_prefill_decode_hlfb_quant.tflite"
tokenizer_model = "PATH/tokenizer.model"
config = llm_bundler.BundleConfig(
tflite_model=tflite_model,
tokenizer_model=tokenizer_model,
start_token="",
stop_tokens=[""],
output_filename=output_file,
enable_bytes_to_unicode_mapping=False,
)
llm_bundler.create_bundle(config)
在 TFLite 運行時使用純 C++ 推理
我們還提供了一個簡單易用的 C++ 示例 (無需 MediaPipe 依賴),來展示如何運行端到端的文本生成。如果您需要將導出的模型與自己獨有的生產流水線和需求進行集成,這個示例是一個很好的起點,來幫助您實現更好的定制和靈活性。
跨平臺支持
由于核心推理運行時都支持 TFLite,所以整個流水線都可以輕松集成到您的 Android (包括在 Google Play 中) 或 iOS 應用中,無需進行任何修改。這意味著用新的生成式 API 轉換的模型只需添加幾個自定義算子依賴即可立即部署。在未來的版本中,我們將為 Android 和 iOS 帶來 GPU 支持,并支持 ML 加速器 (TPU、NPU)。
工具
最近發布的模型探索器 (Model Explorer) 是一款很好用的工具,可用于可視化諸如 Gemma 2B 之類的大型模型。分層查看和并排比較可以讓您輕松查看和比較原始、重新創作和轉換后的模型。我們也準備了專門的文章為您進一步介紹該工具,以及如何通過可視化基準信息來優化模型性能。
模型探索器
https://ai.google.dev/edge/model-explorer
模型探索器: 大模型開發的計算圖可視化工具
https://research.google/blog/model-explorer/
以下是我們在編寫 PyTorch TinyLlama 模型時使用該工具的示例。我們并排顯示了 PyTorch export() 模型與 TFLite 模型。通過使用模型探索器,我們可以輕松比較每個層級 (如 RMSNorms、SelfAttention) 的表達情況。
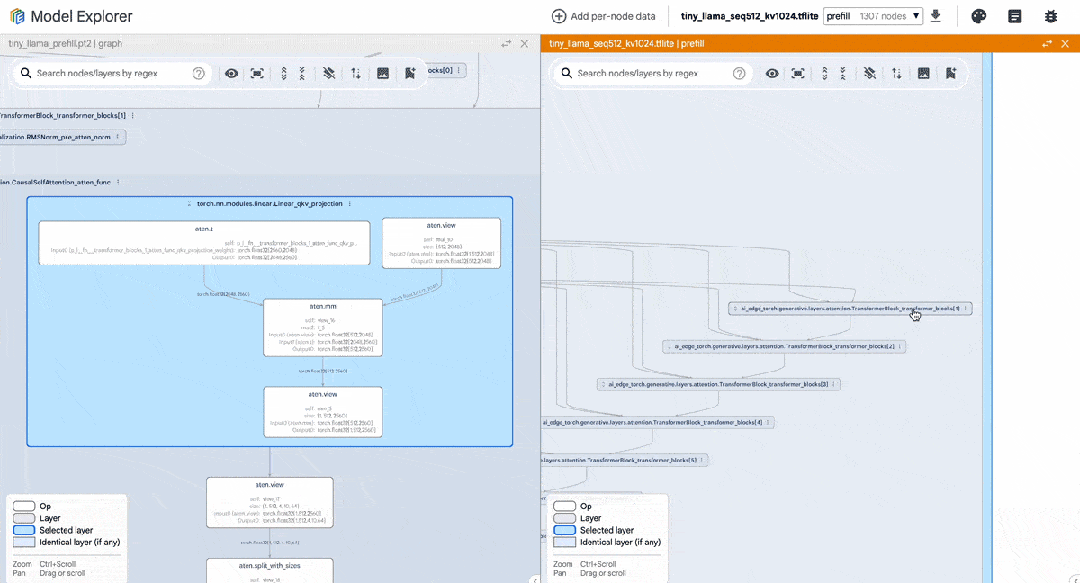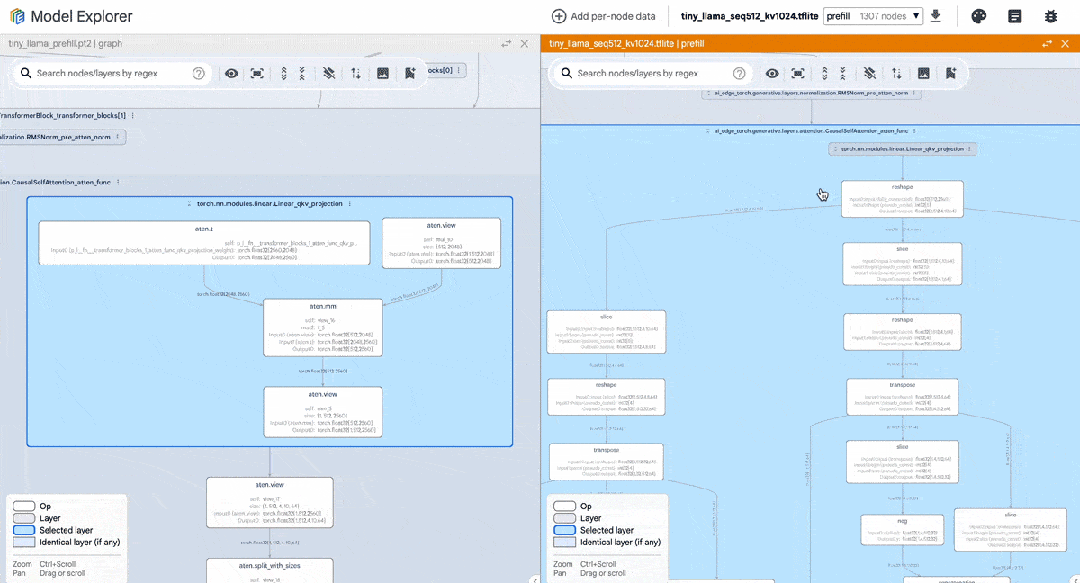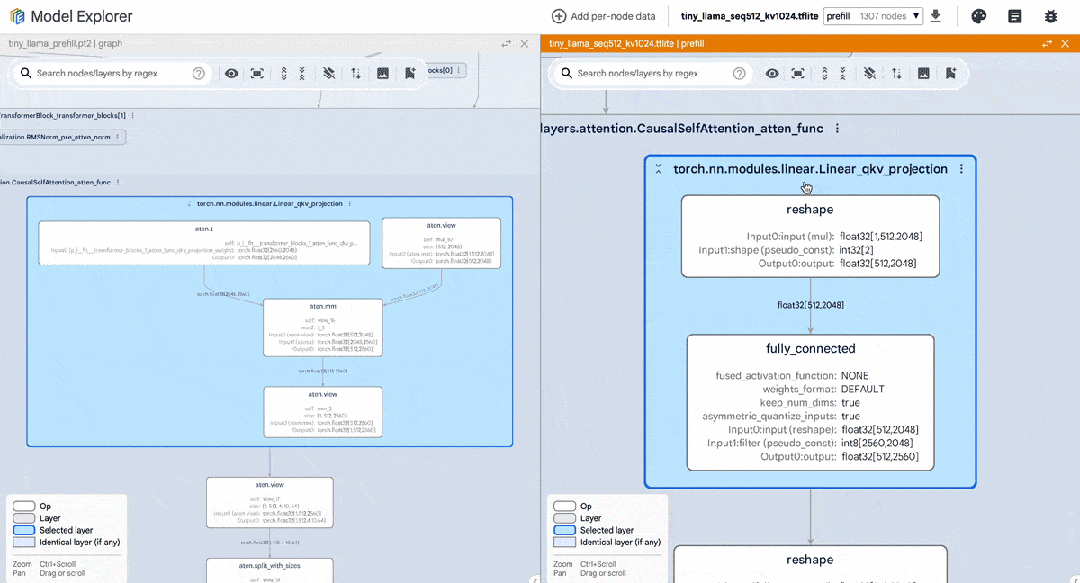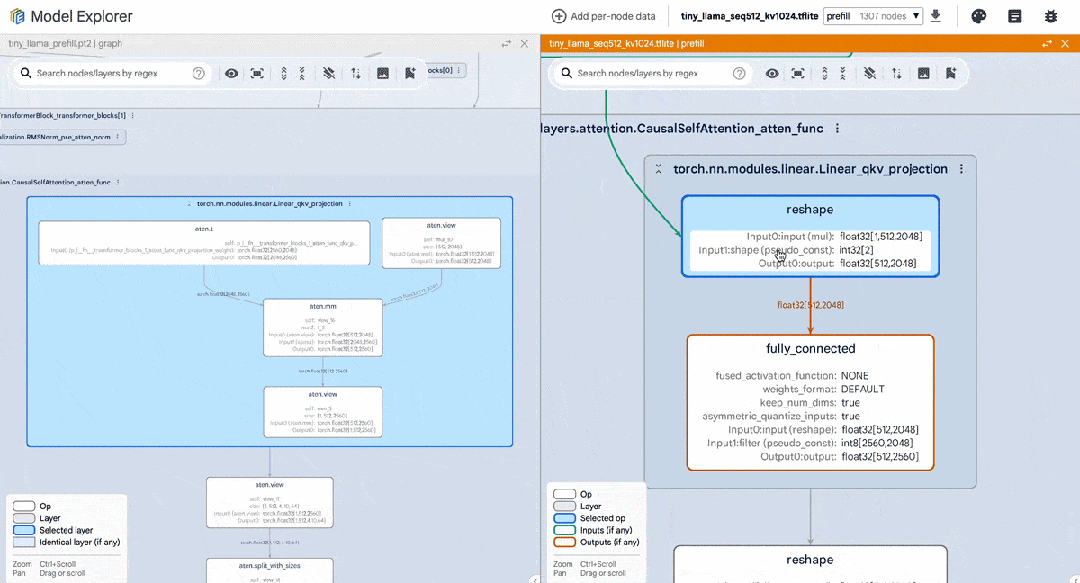
△ 并排比較 TinyLlama PyTorch 和轉換后的 TFLite
總結以及下一步
AI Edge Torch 生成式 API 是為 MediaPipe LLM Inference API 預構建優化模型的強大補充,適用于希望在設備上運行自己的生成式 AI 模型的開發者。我們會在接下來的幾個月繼續帶來更新,包括 Web 支持、更好的量化和對 CPU 之外的硬件的支持。我們也會嘗試探索更好的框架集成方案。
目前發布的是開發庫的早期預覽版本,該版本依然處于實驗階段,旨在與開發者社區進行開放互動。API 可能會發生變化,且存在不完善之處,并且對量化和模型的支持有限。但我們已經在 GitHub repo 中為大家提供了很多用于上手的內容,歡迎大家測試和體驗,并隨時和我們分享 PR、問題和功能需求。
-
API
+關注
關注
2文章
1487瀏覽量
61829 -
AI
+關注
關注
87文章
30239瀏覽量
268475 -
EDGE
+關注
關注
0文章
179瀏覽量
42628
原文標題:通過 AI Edge Torch 生成式 API 在設備上使用自定義大語言模型
文章出處:【微信號:Google_Developers,微信公眾號:谷歌開發者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何在Android上構建自定義AI功能
Google AI Edge Torch的特性詳解

NVIDIA NIM助力企業高效部署生成式AI模型
三行代碼完成生成式AI部署

使用OpenVINO GenAI API的輕量級生成式AI
NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型

生成式AI的定義和特征
AWTK 開源串口屏開發(18) - 用 C 語言自定義命令

TSMaster 自定義 LIN 調度表編程指導

Edge Impulse發布新工具,助 NVIDIA 模型大規模部署
使用CUBEAI部署tflite模型到STM32F0中,模型創建失敗怎么解決?
基于YOLOv8實現自定義姿態評估模型訓練

基于YOLOv8的自定義醫學圖像分割






 工商網監
工商網監
評論