 時空引導下的時間序列自監督學習框架
時空引導下的時間序列自監督學習框架
【導讀】最近,香港科技大學、上海AI Lab等多個組織聯合發布了一篇時間序列無監督預訓練的文章,相比原來的TS2Vec等時間序列表示學習工作,核心在于提出了將空間信息融入到預訓練階段,即在預訓練階段考慮各個序列之間的關系。因此,本文提出的方法更適合作為時空預測領域的預訓練模型。下面為大家詳細介紹一下這篇文章。

摘要
相關時間序列分析在許多現實行業中扮演著重要的角色。為進一步的下游任務學習這個大規模數據的有效表示是必要的,但也具有挑戰性。在本文中,我們提出了一個通過時空引導表示預測的單個實例的時間步長級表示學習框架。我們評估了我們的表示學習框架在相關時間序列預測和將預測模型轉移到有限數據的新實例。在學習到的表示之上訓練的線性回歸模型表明,我們的模型在大多數情況下表現最好。特別是與表示學習模型相比,我們在PeMS-BAY數據集上將RMSE、MAE和MAPE分別減少了37%、49%和48%。此外,在真實世界的地鐵客流數據中,我們的框架展示了傳輸以推斷新的冷啟動實例的未來信息的能力,收益分別為15%、19%和18%。
1 背景
近年來,許多關于時間序列自監督學習方法的研究仍存在幾個顯著的缺點:
最近的研究[13, 14]只學實例級表示,不適合點級任務,如預測和異常檢測。盡管它們在許多時間序列下游任務(如分類和聚類)上成功。
當前研究忽視不同實例間的相關性,學習相關時間序列的集成表示,難以轉移到現實世界的下游任務,例如子實例預測。
所有基于對比的方法(如TS2Vec)都對數據分布或實例相關性做出假設,可能失去多樣性,并可能出現假陰性樣本。
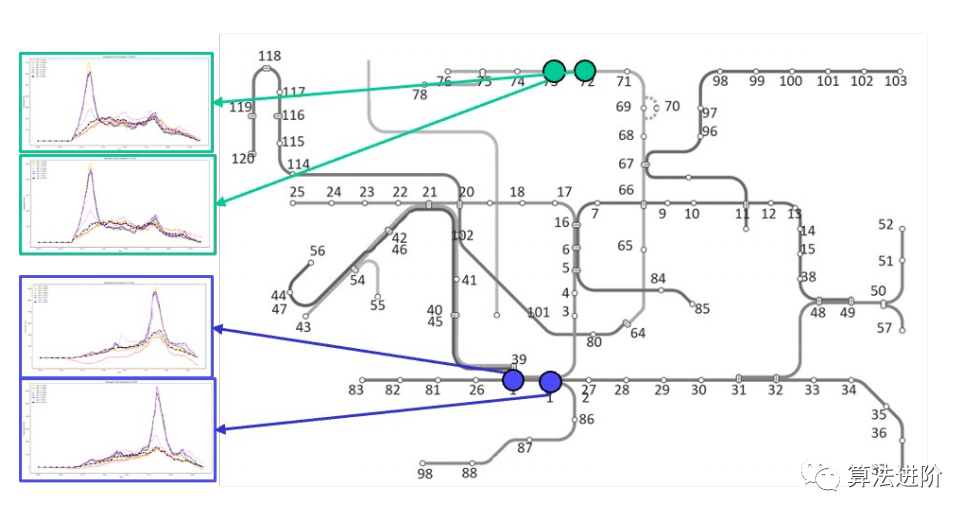
(a)空間相關性:一個車站的客流通常受到其圖形鄰居的影響。
(b)每周周期模式的時間相關性與缺失數據問題
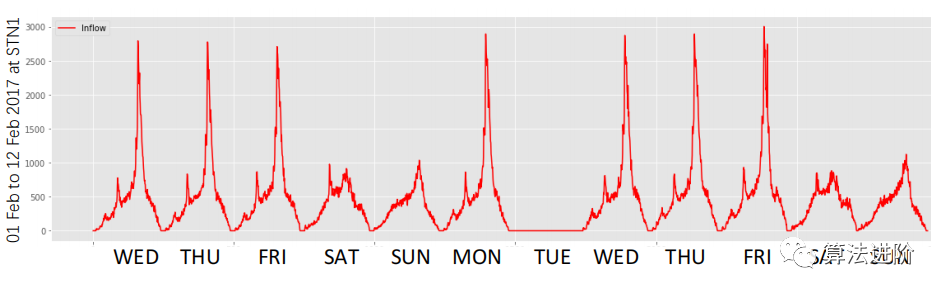
圖1:相關時間序列的時空相關性的一個例子:[1]、[2]地鐵站的乘客流入。(a)空間相關性:相鄰車站的客流通常都很相似。(b)時間相關性:一個車站的客流通常具有歷史時期的模式。此外,還觀察到缺失的數據。
為了解決這些挑戰,我們提出了一個通過時空引導的相關時間序列表示學習框架。本文的主要貢獻總結如下:
我們構建了一個學習框架,用于學習任意實例在任何時間步長內的點級表示。這具有靈活性,所學習到的表示法可以被微調用于1) 相關的時間序列預測,以及2) 用于新實例的轉移任務,而無需重新訓練預測模型。為了捕捉空間和時間上的相關性,我們在自監督學習框架中利用了來自預定義相鄰矩陣的歷史數據和相鄰信息。
為了避免在時間序列數據的對比學習范式中經常出現的假陰性,我們在模型中加入了一個沒有負樣本的自監督學習框架。我們定義了空間和時間目標,并使用蒙版視圖來預測目標的表示,以學習相關性。
我們根據實際數據不同下游任務的結果和分析,展示了表示學習框架的有效性和靈活性。我們對預測任務的評估顯示了具有可比性能的端到端解決方案,但我們的方法更靈活,可以轉移到進入數據集的新實例,而無需重新訓練模型。
2 相關工作
2.1預文本任務時間序列學習
通過設計各種預文本任務來提取有用的信息,以幫助模型在下游任務中表現良好。這些預文本任務包括遮蓋序列的重構、相對定位、時間洗牌和對比預測編碼任務等。這些任務的目的是學習時間序列的有效表示,以便在下游任務中獲得更好的性能。此外,還有其他的預文本任務,如引導空間時間表示預測等。
2.2基于對比的時間序列學習
基于對比的時間序列學習是一種時間序列表示學習的方法,其中大多數方法都采用對比學習框架。這些方法通過構建正負樣本對來進行自監督學習,其中對比損失試圖最大化正樣本對之間的相似性,同時最小化負樣本對之間的相似性。先前的研究提出了許多方法來選擇正負樣本對,以提高所學習表示的質量。這些方法包括使用三元組損失隨機選擇時間段、使用對比預測編碼(CPC)等。這些方法的目的是學習時間序列的有效表示,以便在下游任務中獲得更好的性能。
3 方法
這邊主要介紹提出的模型框架。該模型的編碼器由三個組件組成:輸入投影層、擴張卷積神經網絡模塊和MLP預測器。對于每個輸入w,輸入投影層是一個全連接層,將時間戳t的觀測值xi,t映射到高維潛在向量z。然后,應用具有十個殘差塊的擴張卷積神經網絡模塊來提取每個時間戳的上下文表示。每個擴張卷積塊包含兩個1-D卷積層,具有擴張參數(對于第l個塊為2的l次方)。擴張卷積使不同領域具有大的感受野。在BYOL的思想下,通過預測視圖的不同目標而不是對比來學習表示。在視圖和目標通過全連接層f映射到高維潛在向量之后,使用兩個擴張卷積神經網絡預測器來預測從遮蓋視圖嵌入的潛在向量中的時空表示。
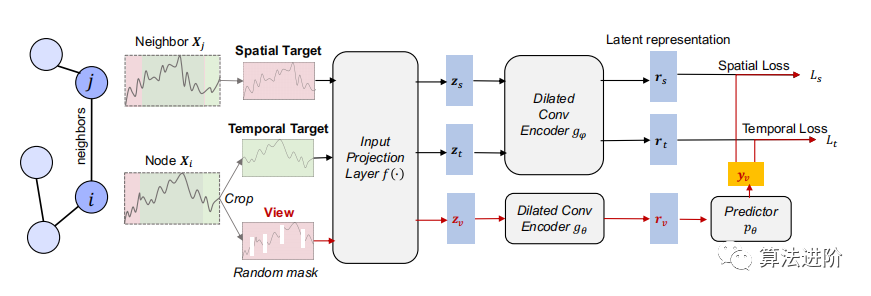
圖2:提出的一種相關時間序列的表示學習框架:主干由一個投影到高維空間的線性層,兩個具有不同參數的擴張卷積編碼器和一個用于根據蒙版視圖嵌入的潛在向量來預測時空表示的預測器組成。
4實驗結果
4.1相關的時間序列預測
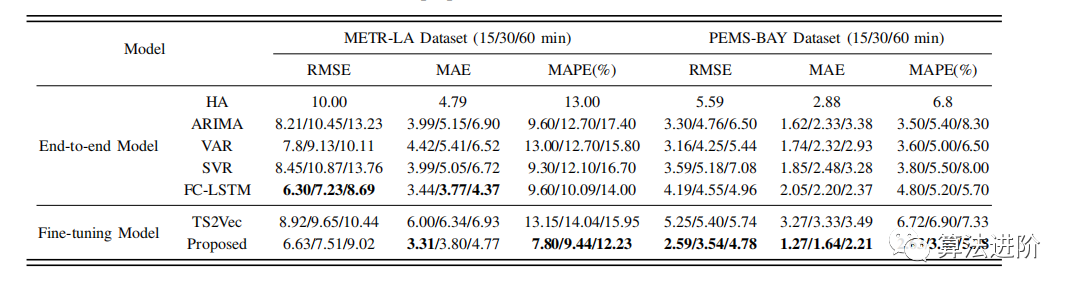
下圖為本文提出的表示學習方法在時空預測數據集上的預測效果,可以看到相比TS2Vec,我們的方法有比較明顯的效果提升。這足以說明我們提出的引入空間信息的對比學習,對于時空預測類型的問題效果更好。
表1:所提方法和基線MAE、MAPE和RMSE(最好的加粗表示,下同)
我們在PEMS-BAY數據集上的性能優于基于時空圖的神經網絡對PEMS-BAY數據集的短期預測。我們可以看到,與TS2Vec相比,我們的模型有更好的預測趨勢。
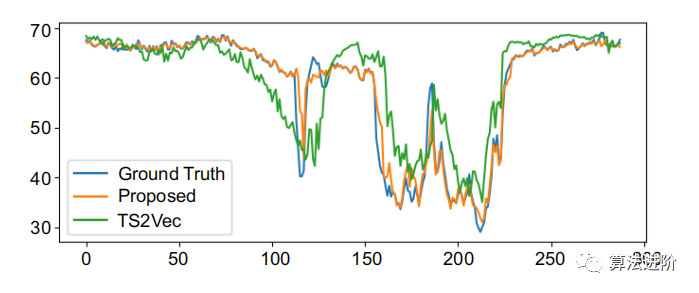
圖3.我們的模型和TS2Vec的一個典型預測切片可視化。
4.2 冷啟動——將模型轉移到數據有限的新實例
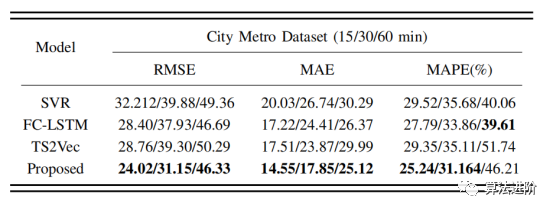
如圖4所示,由于新的地鐵站的建設,地鐵網絡圖結構會發生變化,同時這些新的地鐵站通常只有很少的歷史數據可用,因此預測它們的未來客流量會變得更加困難,這就是時間序列預測的"cold-start"問題。我們提出的方法在大多數情況下都取得了最好的預測性能(表2)。
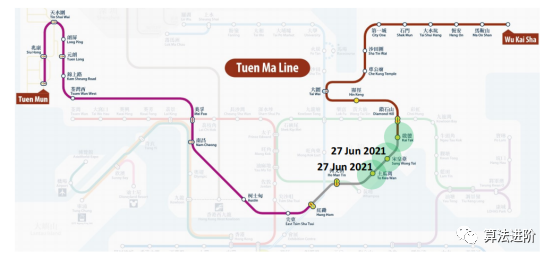
圖4新建地鐵站數據有限,也改變地鐵網絡圖(綠色突出顯示) 表2:新車站的城市地鐵:擬建方法的MAE、MAPE、RMSE及基線。
4.3 消融研究
為了驗證我們的模型中時間和空間成分的有效性,我們比較了在METRLA數據集上不同超參數α值的模型性能。我們將α的值從0→1,時間間隔為0.25,其中α = 1意味著我們只使用歷史信息,而α = 0意味著我們只考慮空間依賴性。
表3:METR-LA對α不同值的消融結果
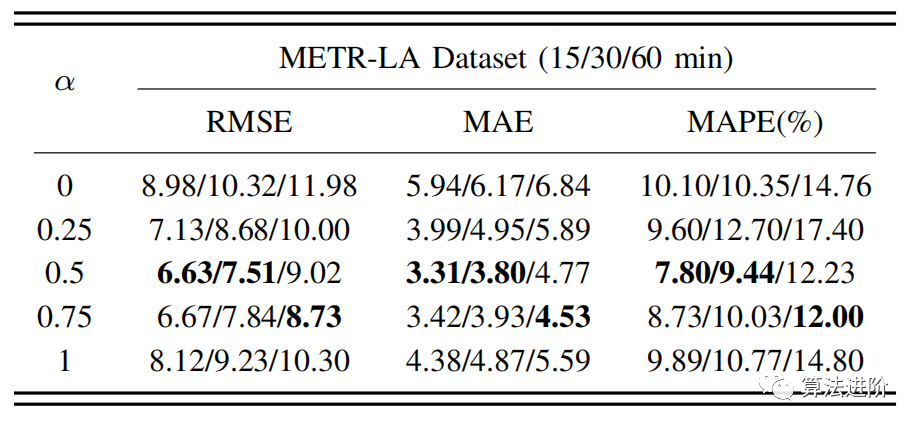
表3顯示,當α=為0.5時,我們的模型在短期預測中表現最好。當時間目標的貢獻大于空間目標時,或當α=值為0.75時,該模型的長期預測效果更好。
4.4 對丟失的數據具有魯棒性
我們以METR-LA數據集為例,以三個缺失率、20%、40%和60%的隨機缺失數據來評估預測性能。圖5顯示,在缺失率小于60%的情況下,我們的空間和時間目標都是非常穩健的。請注意,對于較小的α,如α = 0.25,預測性能比α = 0.75穩定。這表明空間目標的設計可以提高表示學習框架的魯棒性。
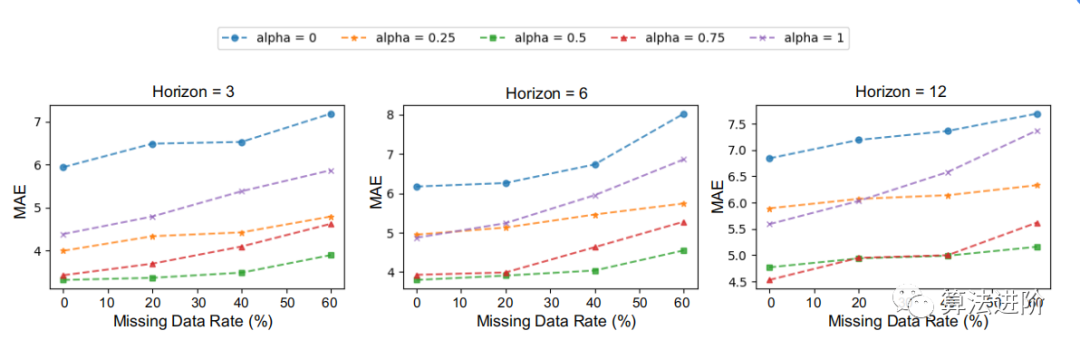
圖5:METR-LA數據集對不同缺失數據率和α的MAE
-
編碼器
+關注
關注
45文章
3601瀏覽量
134201 -
數據
+關注
關注
8文章
6909瀏覽量
88849 -
時間序列
+關注
關注
0文章
31瀏覽量
10420
原文標題:基于時空引導的時間序列自監督學習
文章出處:【微信號:可靠性雜壇,微信公眾號:可靠性雜壇】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
適用于任意數據模態的自監督學習數據增強技術

基于transformer和自監督學習的路面異常檢測方法分享

基于半監督學習框架的識別算法
機器學習算法中有監督和無監督學習的區別
自監督學習與Transformer相關論文
最基礎的半監督學習
半監督學習最基礎的3個概念
為什么半監督學習是機器學習的未來?
半監督學習:比監督學習做的更好
華裔女博士提出:Facebook提出用于超參數調整的自我監督學習框架
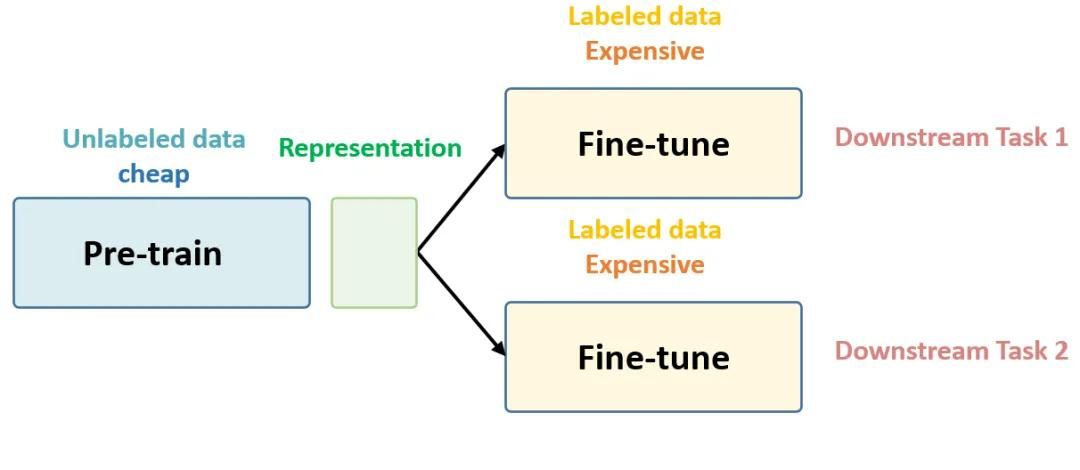

設計時空自監督學習框架來學習3D點云表示
一個通用的時空預測學習框架






 工商網監
工商網監
評論