 一文梳理:如何構建并優化GPU云算力中心?
一文梳理:如何構建并優化GPU云算力中心?
?【更多詳細內容,請訪問星融元官網https://asterfusion.com/】
目前最常見的AI算力中心部署的GPU集群大小為 2048、1024、512 和 256,且部署成本隨 GPU 數量線性增長。本文將以相對折中的1024 GPU卡(H100)的規模為例展開分析。
01 計算節點的選型
計算節點是AI算力中心的建設報價中最昂貴的部分,一開始拿到的 HGX H100 默認物料清單(BoM)往往使用的是頂級配置。不同于 DGX 是 NVIDIA 的系統品牌,HGX 作為 NVIDIA 授權平臺允許合作伙伴構建定制的GPU系統。那么,根據業務實際所需,我們可從以下幾個方面嘗試優化成本。
| 默認 HGX H100 機箱 物料報價清單 | |
| 組件和服務 | 數量 |
| 接近頂級性能的英特爾 Emerald Rapids 處理器 | 2 |
| 8 H100 +4 NVSwitch HGX Baseboard + 8 SXM5 Heatsinks | 1 |
| CPU RAM (per Gbyte) | 2048 |
| Storage (per TByte) | 30 |
| 后端 ConnectX-7 NIC | 80 |
| Bluefield-3 DPU | 2 |
| 主板 | 1 |
| 機箱(機箱、布線等) | 1 |
| 冷卻(CPU 散熱器 + 風扇) | 1 |
| 電源 | 8 |
| 組裝&測試 | 1 |
| OEM 增值/附加費用 | 1 |
| 合計($):270000+ | |
1、選擇中端CPU
LLM 訓練是一項 GPU 高度密集型工作負載,對 CPU 工作負載要求低。CPU 運行是一些簡單任務,例如 PyTorch ,控制 GPU 的其他進程、初始化網絡和存儲調用,或者運行虛擬機管理程序等。Intel CPU 相對更容易實現正確的 NCCL 性能和虛擬化,而且整體錯誤更少。如果是采用AMD CPU ,則要用 NCCL_IB_PCI_RELAXED_ORDERING 并嘗試不同的 NUMA NPS 設置來調優。
2、 RAM 降級到 1 TB
RAM 同樣是計算節點中相對昂貴的部分。許多標準產品都具有 2TB 的 CPU DDR 5 RAM,但常規的AI工作負載根本不受 CPU RAM 限制,可以考慮減配。
3、刪除 Bluefield-3 或選擇平替
Bluefield-3 DPU最初是為傳統 CPU 云開發的,賣點在于卸載CPU負載,讓CPU用于業務出租,而不是運行網絡虛擬化。結合實際,奔著GPU算力而來的客戶無論如何都不會需要太多 CPU 算力,使用部分 CPU 核心進行網絡虛擬化是可以接受的。此外Bluefield-3 DPU 相當昂貴,使用標準 ConnectX 作為前端或采用平替的DPU智能網卡完全可滿足所需。
綜合考慮前述幾項成本優化,我們已經可為單個服務器降低約5%的成本。在擁有 128 個計算節點的 1024 H100 集群中,這個比率背后的金額已經相當可觀。
4、減少單節點網卡數量(謹慎選擇)
標準物料清單中,每臺 H100 計算服務器配備八個 400G CX-7() NIC,單服務器的總帶寬達到 3,200Gb/s。如果只使用四塊網卡,后端計算網的帶寬將會減少 50%。 這種調整顯而易見可以節約資金,但多少會也對部分AI工作負載性能造成不利影響。
02 集群網絡的選型
集群網絡是繼計算節點之后的第二大成本來源。本文舉例的 NVIDIA H100 集群有三種不同的網絡:
后端網絡(計算網,InfiniBand 或 RoCEv2) 用于將 GPU 之間的通信從數十個機架擴展到數千個機架。該網絡可以使 InfiniBand() 或 Spectrum-X 以太網,也可以使用其他供應商的以太網。
前端網絡(業務管理和存儲網絡) 用于連接互聯網、SLURM/Kubernetes() 和網絡存儲以加載訓練數據和Checkpoint。該網絡通常以每 GPU 25-50Gb/s 的速度運行,滿配八卡的情況每臺GPU服務器的帶寬將達到 200-400Gb/s。
帶外管理網絡 用于重新映像操作系統、監控節點健康狀況(如風扇速度、溫度、功耗等)。服務器上的BMC、機柜電源、交換機、液冷裝置等通常連接到此網絡以監控和控制服務器和各種其他 IT 設備。
| 默認 HGX H100 集群網絡 物料報價清單 | |
| 組件和服務 | 數量 |
| InfiniBand 計算網 | |
| Quantum-2 IB 交換機(MQM9700) | 48 |
| Nvidia LinkX IB 400G 單端口 SR4 收發器 (MMA4Z00-NS4400) | 1024 |
| Nvidia LinkX 800G 雙端口 SR8 收發器 (MMA4Z00-NS) | 1536 |
| Nvidia LinkX 400G 多模光纖 | 3072 |
| 前端光纖架構成本 | |
| Spectrum Ethernet Switch (SN4600) | 6 |
| Nvidia LinkX 200G QSFP56 AOC 收發器 | 384 |
| Nvidia LinkX 200G 收發器 | 256 |
| Nvidia LinkX 100G 多模光纖 | 512 |
| 帶外管理網 | |
| 1GbE Spectrum Ethernet Switch (SN2201) | 4 |
| RJ45 Cables | 232 |
| 合計($):490000+ | |
1、計算網絡:RoCEv2替代IB
與量大管飽的以太網解決方案相比,NVIDIA 提供的InfiniBand無疑更昂貴,但一些客戶依舊篤定認為以太網性能要低得多,這主要是因為以太網需要進行必要的無損網絡參數配置并且針對性調優才能發揮集合通信庫的性能。
不過從對業務性能的影響角度看,目前技術背景下使用IB或是RoCEv2作為后端計算網沒有并太多差異。畢竟 RoCE 實際上只是將成熟的IB傳輸層和RDMA移植到了同樣成熟的以太網和IP網絡上,這一點我們將在往后的另一篇文章來分析闡述。
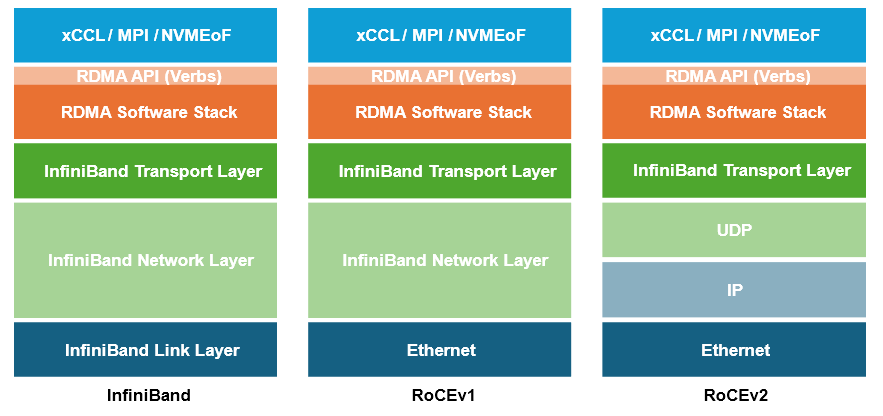
大規模算力場景中用以太網替代IB組成高性能無損網絡已形成業內共識,行業熱點早已轉向了如何更好地薅“以太網羊毛”:例如從以太網標準入手,推出下一代面向AI場景的新協議,以及一些廠商立足于現有協議標準在簡化RoCE網絡配置和提高可視化能力上做的創新嘗試。
參閱: Easy RoCE:在SONiC交換機上一鍵啟用無損以太網
無論是在AI訓推的測試場景,還是頭部云廠商已有的工程實踐里,AI以太網都有了大量案例可供參考。
據統計,在全球 TOP500 的超級計算機中,RoCE和IB的占比相當。以計算機數量計算,IB 占比為 47.8%, RoCE 占比為 39%; 而以端口帶寬總量計算,IB占比為 39.2%,RoCE 為 48.5%。與IB相比,我們相信有著開放生態的以太網將會得到加速發展。
目前市場上提供適用于AI場景的高性能以太網交換芯片平臺主要有Broadcom Tomahawk、Marvell Teralynx和Cisco Silicon One 等,NVIDIA Spectrum 芯片僅用于Spectrum-X平臺,不單獨銷售。以上平臺都推出了51.2T,800GbE/s的尖端型號,綜合來看部署數量上 Tomahawk 明顯占優,轉發時延性能表現 Teralynx 更勝一籌。
2、前端網絡:合理降低帶寬速率
NVIDIA 和一些OEM/系統集成商通常會在服務器提供 2x200GbE 前端網絡連接,并使用 Spectrum Ethernet SN4600 交換機部署網絡。
我們知道,這張網絡僅用于進行存儲和互聯網調用以及傳輸基于 SLURM,Kubernetes 等管理調度平臺的帶內管理流量,并不會用于時延敏感和帶寬密集型的梯度同步。每臺服務器 400G 的網絡連接在常規情況下將遠超實際所需,其中存在一些成本壓縮空間。
3、帶外管理網絡:選用通用的以太網交換機
NVIDIA 默認物料清單一般包括 Spectrum 1GbE 交換機,價格昂貴。帶外管理網絡用到的技術比較通用,選擇市場上成本更優的 1G 以太網交換機完全夠用。
03 計算網絡的架構優化
GPU集群計算網將承載并行計算過程中產生的各類集合通信(all-reduce,all-gather 等),流量規模和性能要求與傳統云網絡完全不同。
參閱:揭秘AI智算中心網絡流量 - 大模型訓練篇
NVIDIA 推薦的網絡拓撲是一個具有無阻塞連接的兩層胖樹網絡,理論上任意節點對都應該能同時進行線速通信。但由于存在鏈路擁塞、不完善的自適應路由和額外跳數的帶來的通信延遲,真實場景中無法達到理論最優狀態,需要對其進行性能優化。
軌道優化(Rail-optimized)架構
軌道優化架構下,4臺服務器的32張 GPU 卡不再是連接到 TOR 交換機,而是來自32臺服務器的同卡號 GPU 連接各自的軌道交換機——即32臺服務器的所有 GPU#0 都連接到 Leaf 交換機#0,所有 GPU#1 都連接到 Leaf 交換機#1,依此類推。
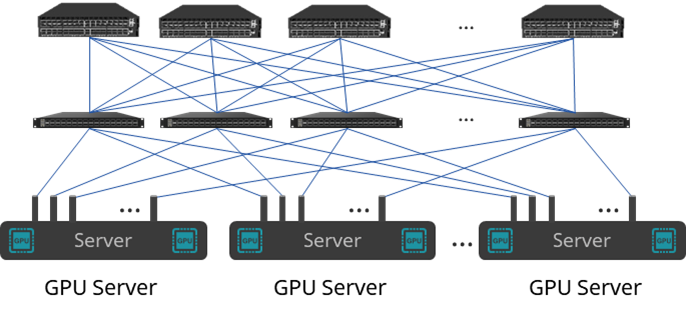
軌道優化網絡的主要優勢是減少網絡擁塞。因為用于 AI 訓練的 GPU 會定期并行底發送數據,通過集合通信來在不同GPU之間交換梯度并更新參數。如果來自同一服務器的所有 GPU 都連接到同一個 ToR 交換機,當它們將并行流量發送到網絡,使用相同鏈路造成擁塞的可能性會非常高。
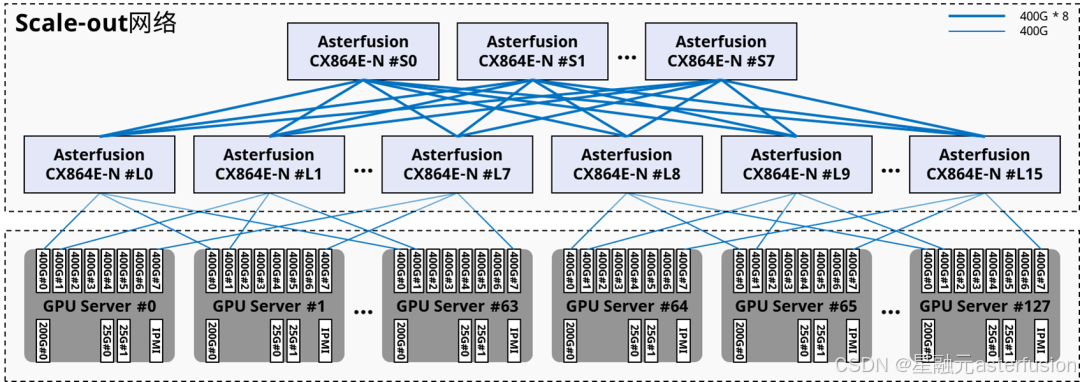
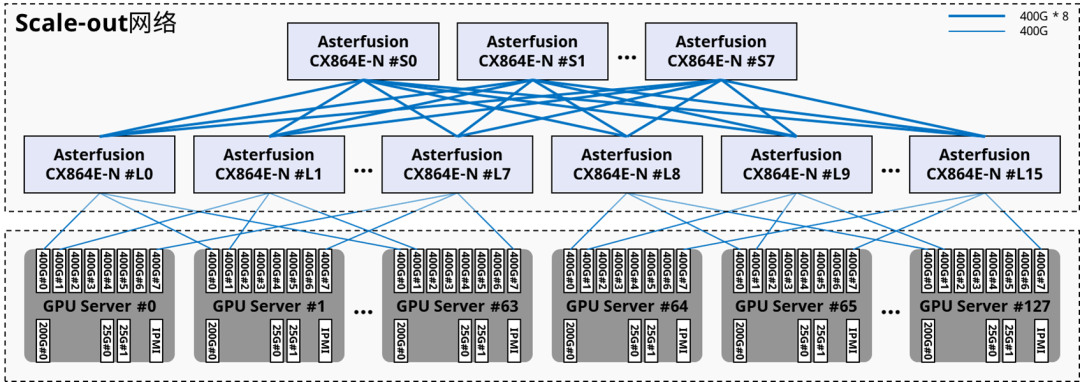
星融元(Asterfusion)給出的1024卡,128計算節點 Scale-out 網絡方案正是基于軌道優化后的架構,其中采用了24臺 CX864E-N(51.2T的單芯片盒式交換機,8臺作為Spine,16臺作為Leaf),產生跨節點通信的同卡號GPU之間只會相距一跳。
參閱:星融元發布 51.2T 800G 以太網交換機,賦能AI開放生態

?編輯
來源:星融元(Asterfusion)CX864E-N交換機
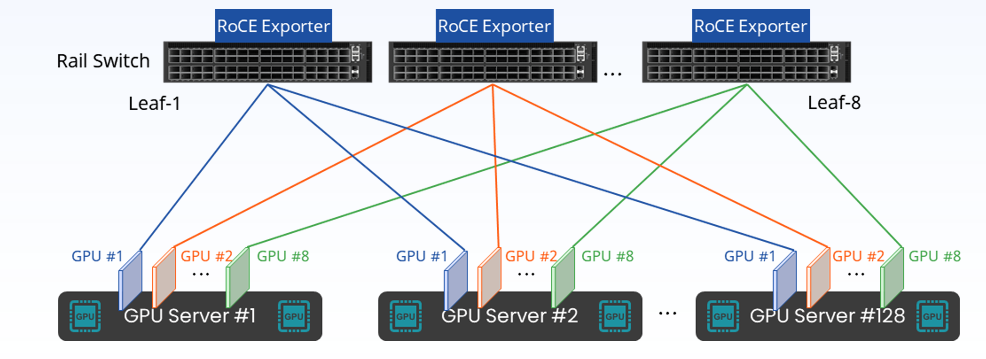
來源:星融元(Asterfusion)星智AI網絡解決方案
如果追求極致的成本優化,對于一個32到128個節點的計算集群甚至可以設計只有單層軌道交換機的Rail-only網絡,理論上建網成本可以節約高達75%。
確定合適的超額訂閱率
軌道優化拓撲的另一個好處可以超額訂閱(Oversubscription)。在網絡架構設計的語境下,超額訂閱指的是提供更多的下行容量;超額訂閱率即下行容量(到服務器/存儲)和上行帶寬(到上層Spine交換機)的比值,在 Meta 的 24k H100 集群里這個比率甚至已經來到夸張的7:1。
通過設計超額訂閱,我們可以通過突破無阻塞網絡的限制進一步優化成本。這點之所以可行是因為 8 軌的軌道優化拓撲里,大多數流量傳輸發生在 pod 內部,跨 pod 流量的帶寬要求相對較低。結合足夠好的自適應路由能力和具備較大緩沖空間的交換機,我們可以規劃一個合適的超額訂閱率以減少上層Spine交換機的數量。
但值得注意的是,無論是IB還是RoCEv2,當前還沒有一個完美的方案規避擁塞風險,兩者應對大規模集合通信流量時均有所不足,故超額訂閱不宜過于激進。(而且最好給Leaf交換機留有足夠端口,以便未來 pod 間流量較大時增加spine交換機)
現階段如果是選用基于以太網的AI網絡方案我們仍推薦1:1的無阻塞網絡設計。
04 NVMe 存儲
物理服務器數量
為了實現高可用性,大多數存儲廠商都會建議部署至少 8 臺存儲服務器。8 臺存儲服務器每臺可提供 250GB/s 到 400GB/s 的存儲帶寬,足以滿足在 1024 臺 H100 上運行的 AI 工作負載。我們可以從最小可用數量開始,但需要注意在存儲系統上留出足夠的端口、NVMe 驅動器托架、電源和機架空間,以便后續按需擴展。
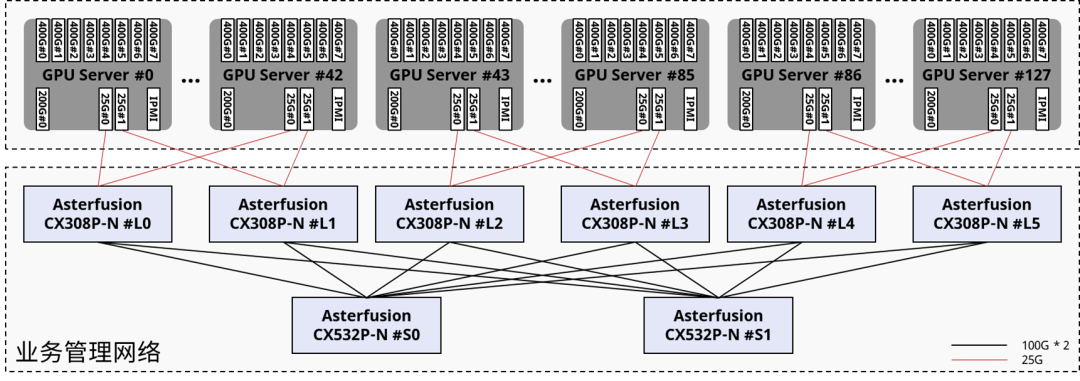
存儲網絡
常見的方案是構建專門的200G無損以太網作為存儲網絡以確保性能,存儲前后端網絡在物理上合一。

來源:星融元(Asterfusion)
存儲服務器也可以在后端計算網上運行——通常是將IB網卡綁定到 GPU 0來充當存儲網卡。雖然存儲基準測試的延遲和帶寬表現很好,但在實際AI工作負載中將影響 GPU 0 的性能(IB網卡同時作為存儲網卡會有流量沖突)。當存儲集群中的磁盤發生故障將觸發重建,會在計算網上造成大量的流量,形成更嚴重的擁塞。
05 帶內管理
為了運行高可用的 UFM 和 CPU 管理節點,我們建議部署至少兩個通用 x86 服務器,使用25GE/10GE以太網鏈路連接所有計算節點和管理節點,并接入外部網絡。
來源:星融元(Asterfusion)
默認的NVIDIA Superpod 架構中包含了“NVIDIA AI Enterprise”或“Base Command Manager (BCM)”,其建議零售價為4,500 美元/GPU。BCM 是一個提供 AI 工作流和集群管理的軟件包,這一部分軟件費用可以考慮剔除后選擇其他平替方案,或交由用戶自定義。
此外帶內管理系統還涉及到其他 IT 設備,例如防火墻、機架、PDU 等,這部分價格不會顯著增加集群建設支出。
06 帶外管理
帶外管理系統主要是通過智慧平臺管理接口(IPMI)去監視、控制和自動回報大量服務器的運作狀況。IPMI可獨立于操作系統外自行運作,并允許管理者在受監控的系統未開機但有接電源的情況下進行遠程管理,但這種監控功能主要集中在硬件級別。
不同于帶內管理,帶外管理構建了單獨的網絡承載物理設備管理流量,不會承載業務流量。我們一般是每GPU計算節點和存儲節點配置1條1 GE 鏈路連接IPMI和后端管理平臺。
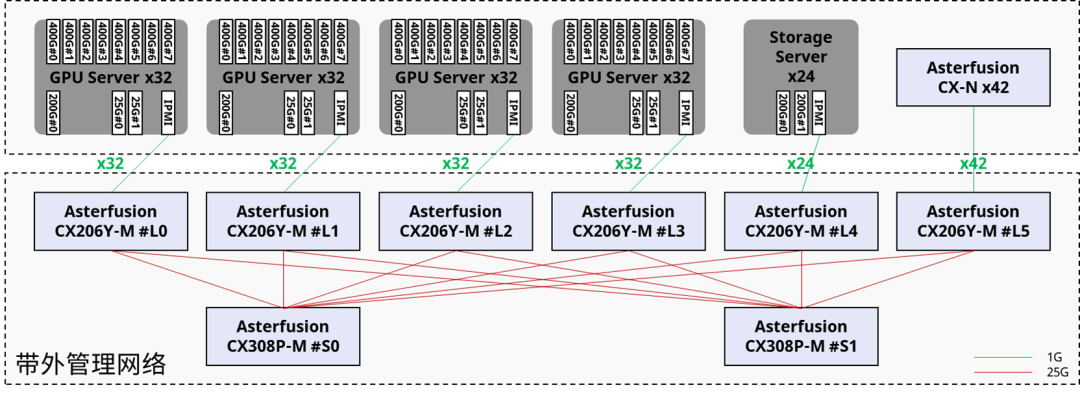
07 驅動和業務調度程序
GPU驅動程序
必要的 GPU 驅動程序有 cuda-drivers-5xx 和 fabricmanager-5xx 以及 cuda-toolkit-12-x。
Cuda-drivers-5xx 是 ubuntu/Linux 與 GPU 交互所需的內核空間驅動程序
fabricmanager-5xx 是一個負責配置節點內 NV 鏈路結構
Cuda-toolkit-12-x 包含所有用戶空間工具和 API
網絡驅動程序
MLNX_OFED
每個 GPU 服務器上都需要安裝 Mellanox OpenFabrics Enterprise Distribution (MLNX_OFED) 驅動程序。此軟件包是 ConnectX-7 InfiniBand NIC 的驅動程序,用于執行 RDMA(遠程直接內存訪問)和 OS 內核旁路。
GPU Direct RDMA
這是一個包含在 cuda-drivers-5xx 中的附加內核驅動程序,默認情況下未啟用。如果沒有此驅動程序,GPU 將需要先在 CPU RAM 中緩沖消息后才能發送到 NIC。
啟用 GPUDirect RDMA 的命令是 sudo modprobe nvidia-peermem。
NVIDIA HPC-X
主要用于進一步優化 GPU 與 NIC 的通信。
如果沒有上述軟件包,GPU 只能以 80Gbit/s 的速度收發流量,啟用這些軟件包后點對點收發速率應可達到 391Gb/s左右。
業務調度和啟動程序
絕大部分的最終用戶會希望擁有一個開箱即用的調度程序,可以基于SLURM 、K8s 或者其他供應商的軟件平臺。從0到1手動安裝并調試以上平臺,對于不是專精于此的工程師至少需要花費1-2天時間,因此閑置的 GPU 資源對于客戶都是實打實的支出。
08 多租戶隔離
參考傳統CPU云的經驗,除非客戶長期租用整個GPU集群,否則每個物理集群可能都會有多個并發用戶,所以GPU云算力中心同樣需要隔離前端以太網和計算網絡,并在客戶之間隔離存儲。
基于以太網實現的多租戶隔離和借助云管平臺的自動化部署已經有大量成熟的方案。如采用InfiniBand方案,多租戶網絡隔離是使用分區密鑰 (pKeys) 實現的:客戶通過 pKeys 來獲得獨立的網絡,相同 pKeys 的節點才能相互通信。
09 GPU的虛擬化
與傳統CPU云不同的是,AI用途的GPU云租戶通常會將每個 GPU 計算節點作為一個整體來租用,深入到節點內部的更細粒度的虛擬化并無絕對必要。但為了進一步提高GPU資源利用率,很多人還是會選擇GPU虛擬化,目前,GPU虛擬化技術一般分為三種:軟件模擬、直通獨占(pGPU)、直通共享(如vGPU、MIG)。
AI算力租賃場景的虛擬化程度一般是到單卡層次,即直通獨占(pGPU)——利用 PCIe 直通技?
術,將物理主機上的整塊GPU顯卡直通掛載到虛擬機上使用,原理與網卡直通類似,但這種方式需要主機支持IOMMU()。(一種內存管理單元,它將具有直接存儲器訪問能力的I/O總線連接至主內存。如傳統的MMU一樣,IOMMU將設備可見的虛擬地址映射到物理地址)
pGPU直通方式相當于虛擬機獨享GPU,硬件驅動無需修改。因為沒有對可支持的GPU數量做限制,也沒有閹割GPU功能性,大多數功能可以在該直通模式下無修改支持。
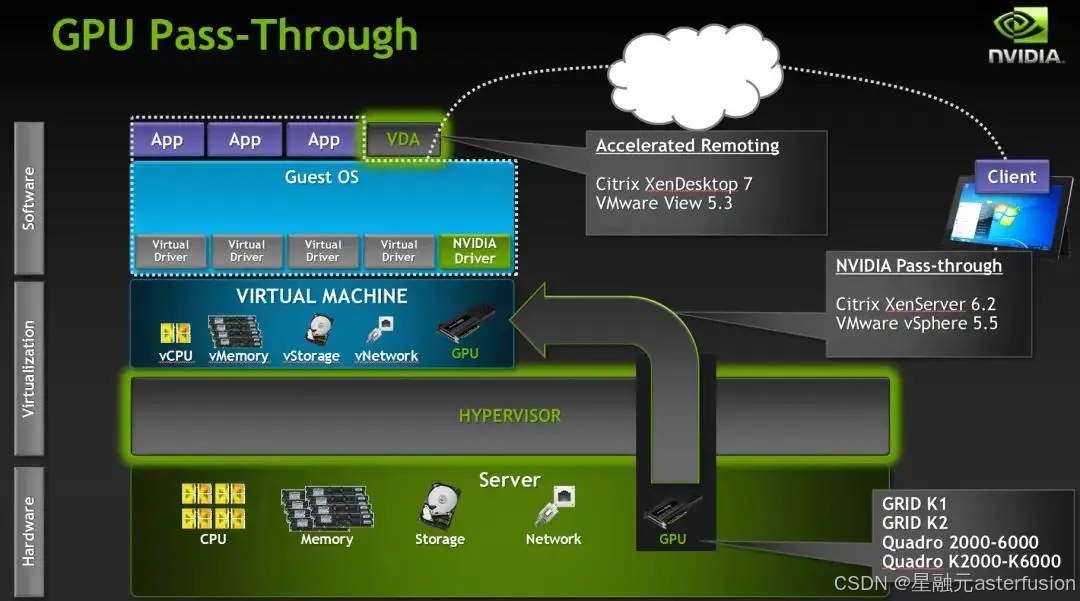
?編輯
值得一提的是,NCCL 和 NVIDIA 驅動程序在 GPU 虛擬機內運行時無法自動檢測 NUMA 區域和 PCIe 拓撲,需要通過 NCCL_TOPO_FILE 變量手動傳遞 /etc/nccl.conf中的 NUMA 區域和 PCIe 拓撲文件,否則 NCCL 性能將僅以應有帶寬的 50% 運行。
10 監控方案
監控面板
在監控方面,我們至少建議通過 Prometheus + Grafana 構建一個集中的監控面板,以便用戶跟蹤 GPU 溫度、電源使用情況等BMC指標,XID錯誤,甚至將業務和網絡統一監測。
計算節點的監控包括在每個 GPU 節點上安裝一個 IPMI 和 DCGM Exporter,然后在管理節點上部署 Prometheus 與 GPU 上的 Exporter 通信,并將數據存儲在數據庫中。Grafana 連接到 Prometheus 對收集來的數據進行可視化呈現。
網絡側的監控類似,在這種場景下采用SONiC交換機的優勢明顯,因其軟件環境本身就是開放的容器化架構,我們能以 docker 形式在交換機運行 exporter 取得所需設備狀態數據,還可借助RESTful API調用網絡能力集成進上層管理平臺。
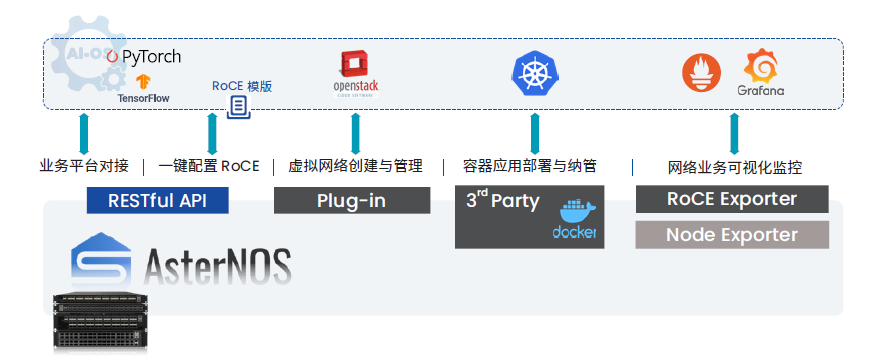
另外,結合帶內網絡遙測(INT)能力還可對RoCE網絡實現亞秒級的精細監控,用以輔助網絡擁塞控制。
來源:星融元提供的Prometheus + Grafana 毫秒級 RoCE 監控方案
常見錯誤
診斷消息(dmesg)兩個常見 dmesg 消息是電纜被拔出以及 NIC 或者光收發器過熱。
靜默數據損壞 (SDC)沒有收到診斷消息等錯誤報告,但卻輸出錯誤的矩陣乘法結果。這些錯誤稱為靜默數據損壞 (SDC)。確定 GPU 上是否有該問題的最簡單方法是使用 Nvidia DCGMI 診斷級別 4 工具 sudo dcgmi diag -r 4。該工具將捕獲 95% 的最常見靜默數據損壞問題。
NCCL故障 常見NCCL故障包括死鎖和停滯,可能會導致訓練作業暫停 30-35 分鐘, 而后 PyTorch 的 NCCL watchdog 會終止整個訓練作業。對此可以考慮添加電力消耗監控來檢查AI作業是否正常運行。更多NCCL排障請參考:https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/troubleshooting.html
Infiniband UFM 的錯誤代碼 常見如 110(符號錯誤)、112(鏈接中斷)、329(鏈接中斷)、702(端口被視為不健康)和 918(符號位錯誤警告)。遇到上述任何錯誤代碼,應立即聯系網絡技術工程師進一步調查。
11 部署驗收和日常維護
集群規模的驗收測試應持續至少 3-4 周,盡可能排除早期失效期出現的節點組件故障。AI訓練非常依賴網絡、HBM() 和 BF16/FP16/FP8 張量核心,而目前常用的高性能計算測試工具,例如LINPACK(國際上使用最廣泛的測試浮點性能的基準測試)不會大量使用網絡,也不會占用太多 GPU 的 HBM 內存,而是僅使用和測試 GPU 的 FP64 核心。穩妥起見,我們建議驗收測試盡量以模擬真實業務的方式展開。
NCCL-TEST
nccl-test 工具是 NVIDIA 開源的一項用于測試 NCCL 集合通信的工具,我們建議在正式運行業務之前先使用nccl-test來檢測集合通信是否正常、壓測集合通信速率等,看看否存在任何性能不足或下降。關于nccl-test日志的分析我們將在接下來的主題中展開。
日常維護
集群中最常見的問題包括收發器抖動、GPU掉線、GPU HBM 錯誤和 SDC等。大多數情況下,這些問題只需簡單地啟動物理服務器的硬重啟,或者斷電后重啟即可解決。重新插拔收發器或清除光纖電纜上的灰塵也可以解決一些意外故障。更復雜的情況請交給廠商技術服務團隊處理。
?
?審核編輯 黃宇
-
gpu
+關注
關注
28文章
4700瀏覽量
128695 -
AI
+關注
關注
87文章
30106瀏覽量
268398 -
AI算力
+關注
關注
0文章
72瀏覽量
8563 -
算力
+關注
關注
1文章
925瀏覽量
14738
發布評論請先 登錄
相關推薦
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
【一文看懂】大白話解釋“GPU與GPU算力”

一文讀懂算力中心四大類型,深度解讀應用與趨勢
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
【「大模型時代的基礎架構」閱讀體驗】+ 未知領域的感受
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
名單公布!【書籍評測活動NO.41】大模型時代的基礎架構:大模型算力中心建設指南
算力服務器為什么選擇GPU





 工商網監
工商網監
評論