 AI時代核心存力HBM(上)
AI時代核心存力HBM(上)
一、HBM 是什么?
1、HBM 是 AI 時代的必需品作為行業主流存儲產品的動態隨機存取存儲器 DRAM 針對不同的應用領域定義了不同的產 品,幾個主要大類包括 LPDDR、DDR、GDDR 和 HBM 等,他們雖然均使用相同的 DRAM 存儲單 元(DRAM Die),但其組成架構功能不同,導致對應的性能不同。手機、汽車、消費類等 對低功耗要求高主要使用 LPDDR,服務器和 PC 端等有高傳輸、高密度要求則使用 DDR,圖 形處理及高算力領域對高吞吐量、高帶寬、低功耗等綜合性要求極高則使用 GDDR 和 HBM。 HBM(High Bandwidth Memory),意為高帶寬存儲器,是一種面向需要極高吞吐量的數據密集型應用程序的 DRAM,常被用于高性能計算、網絡交換及轉發設備等需要高存儲器帶寬的領域。那么 HBM 到底優勢在哪呢?通過 TSV 技術,堆疊方案解決內存墻的問題。基于馮·諾依曼理論的傳統計算機系統架構一直存在“內存墻”的問題。
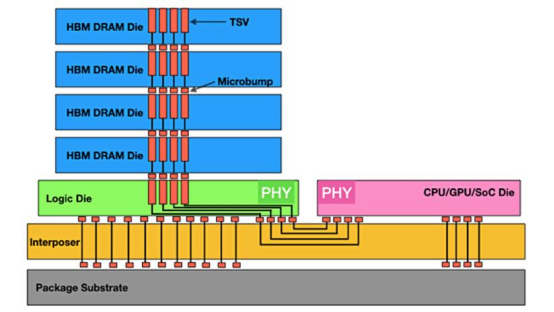
HBM 通過硅中介層和 TSV 來運行
主要歸因于:第一存儲與計算單元分離,存儲與處理器之間通過總線傳輸數據,這容易導致存儲的帶寬計算單元的帶寬,從而導致 AI 算力升級較慢;
第二,是高功耗,在處理器和存儲之間頻繁傳輸數據,會產生較多的能耗,也會使傳輸速率下降。相較于傳統 GDDR,HBM 具有更高速,更低耗,更輕薄等諸多優點。HBM 憑借獨特的 TSV 信號縱向連接技術,其內部將數個 DRAM 芯片在緩沖芯片上進行立體 堆疊,其內部堆疊的 DDR 層數可達 4 層、8 層以至 12 層,從而形成大容量、高位寬的 DDR 組合陣列。
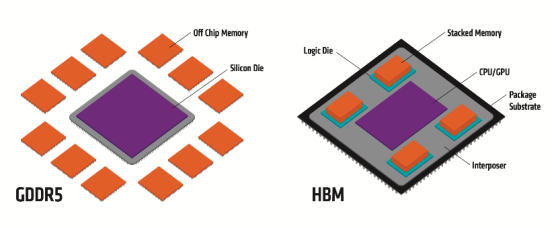
GDDR 與 HBM 結構分布
TSV 是在 DRAM 芯片上搭上數千個細微孔并通過垂直貫通的電極連接上下芯片的技術。該技術在緩沖芯片上將數個 DRAM 芯片堆疊起來,并通過貫通所有芯片層的柱狀 通道傳輸信號、指令、電流。相較傳統封裝方式,該技術能夠縮減 30%體積,并降低 50% 能耗。
憑借 TSV 方式,HBM 大幅提高了容量和位寬(I/O 數量)。與傳統內存技術相比,HBM 具有更高帶寬、更多 I/O 數量、更低功耗、更小尺寸等特征。
具體來看:(1)存儲帶寬問題:由于存儲的制成與封裝工藝與 CPU 的制成封裝工藝不同,CPU 使用的是 SRAM 寄存器,速度快,雙穩態電路,而存儲器使用的是 DRAM 寄存器,速度慢,單穩態電路。這樣的工藝不同拉大了兩者間的差距,在過去 20 年內,CPU 的峰值計算能力增加了 90000 倍,內存/硬件互存寬帶卻只是提高了 30 倍。存儲的帶寬通過總線一直限制著計算單位的帶寬,最新型的 GDDR6 單顆帶寬上限在 96GB/s,而最新型的單棧HBM3E 帶寬上限近 1.2TB/s,在 AI 應用中,每個 SoC 的帶寬需求都會超過幾 TB/s,上百倍的數據傳輸差距使得傳統 DRAM 遠不能滿足 AI 訓練所需的算力缺口。(2)傳輸效能問題:由于分離距離問題,數據存算間(I/O)會有很大的延誤,一步數據計算過后的大部分時間都在讀取內存,查詢所用的大量時間與吞吐量影響用戶體驗,數據傳輸能量消耗占總數據存算的 60-90%,嚴重浪費效能。(3)占用空間問題:傳統 GDDR 由于是 2D 平面分布,占用空間大,無法滿足目前消費電子輕量化與便攜化的需求。
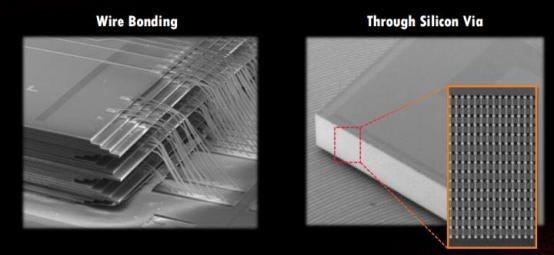
傳統打線與 TSV 穿孔區別
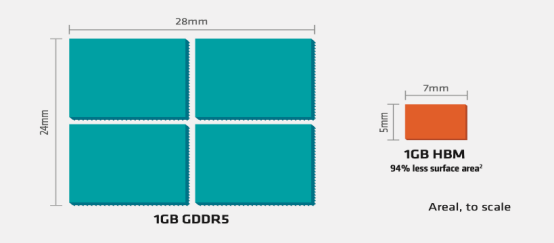
GDDR 與 HBM 占用空間對比
HBM 包括多層 DRAM 芯片和一層基本邏輯芯片,不同 DRAM 以及邏輯芯片之間用 TSV 與微凸 塊技術實現通道連接,每個 HBM 芯片可與多達 8 條通道與外部連接,每個通道可單獨訪問 1 組 DRAM 陣列,通道間訪存相互獨立。邏輯芯片可以控制 DRAM 芯片,并提供與處理器芯 片連接的接口,主要包括測試邏輯模塊與物理層(PHY)接口模塊,其中 PHY 接口通過中 間介質層與處理器直接連通,直接存取(DA)端口提供 HBM 中多層 DRAM 芯片的測試通道。
中間介質層通過微凸塊連接到封裝基板,從而形成 SiP 系統。
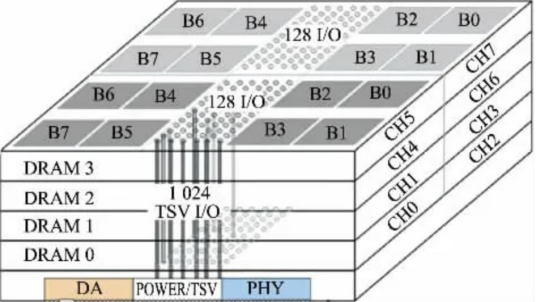
HBM 架構詳解
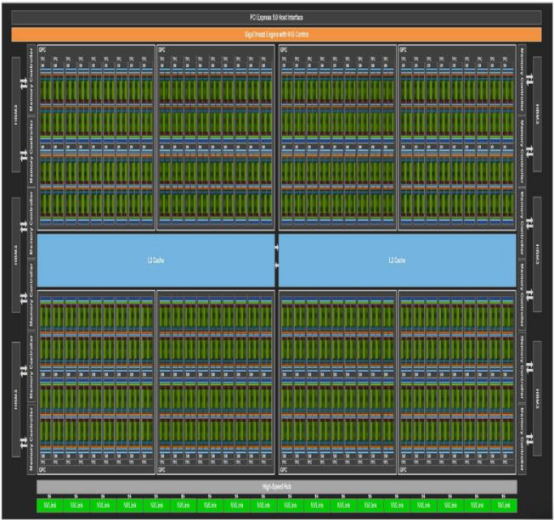
HBM3 在 NVIDIA Hopper 架構的應用AI 時代存力的首選自 ChatGPT 爆火之后,國內外大廠爭相競逐 AI 大模型。而 AI 大模型的基礎,就是靠海量 數據和強大算力來支撐訓練和推理過程。其中一些模型有 1000 億字節的數據,參數量越 大,AI 模型越智能,以 GPT-4 模型為例有近 1.76 萬億參數量。
對于每次重新訓練的迭代, 都必須從數據中心背板的磁盤上取出 1000 億字節的數據并進入計算盒,在為期兩個月的訓練中,必須來回調取數百萬次如此龐大的數據。如果能縮短數據存取,就會大大簡化訓 練過程。但在過去 20 年中,存儲和計算并沒有同步發展,硬件的峰值計算能力增加了 90000 倍,而內存/硬件互連帶寬卻只是提高了 30 倍。
當存儲的性能跟不上處理器,對指令和數 據的搬運(寫入和讀出)的時間將是處理器運算所消耗時間的幾十倍乃至幾百倍,這就要 打破“內存墻”。此時,高帶寬內存 HBM 應運而生,被認為是 AI 計算的首選內存。
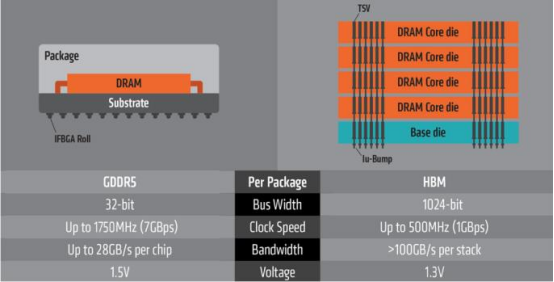
GDDR 與 HBM 性能對比
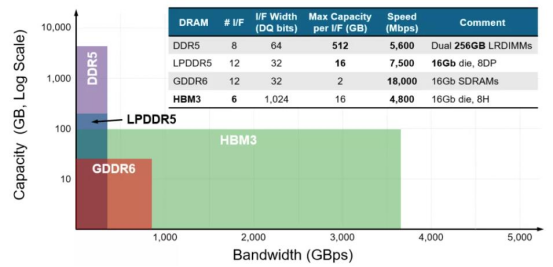
不同內存類型之間 DRAM 容量和帶寬的差異 HBM 解決了傳統 GDDR 遇到的“內存墻”問題,采用了存算一體的近存計算架構,不通過外部連線的方式與 GPU/CPU/Soc 連接,而是通過中間介質層緊湊快速地連接信號處理器芯片,極大的節省了數據傳輸所使用的時間與耗能。 而在空間占用上,HBM 采用的堆 棧技術會使得在空間占用要比同比傳統 GDDR 節省 94%。在應對目前云端 AI 的多用戶, 高吞吐,低延遲,高密度部署需求所帶來的計算單位需求,I/O 數量也需要不斷突破滿足 計算單位的需求。使用 GDDR 所適配的 PCB 技術并不能突破 I/O 數量瓶頸,而 HBM 的 TSV 技術帶來的存儲器集成度極大提升,使得帶寬不再受制于芯片引腳的互聯數量,在一定程度上解決了 I/O 瓶頸,成為高算力芯片的首選。

HBM 在 GPU 中搭配

HBM 與 GPU 集成在一起2 NVIDIA 和 AMD 依靠 HBM 持續提升 GPU 性能HBM 新型存儲器較傳統 GDDR 具有更高的帶寬,更低的延遲和更好的等效比。隨著 AI 對算 力的高要求,高帶寬內存顯然是高性能 GPU 的最佳搭配,AMD 和 NVIDIA 兩家尖端的 GPU 都陸續配備了 HBM。
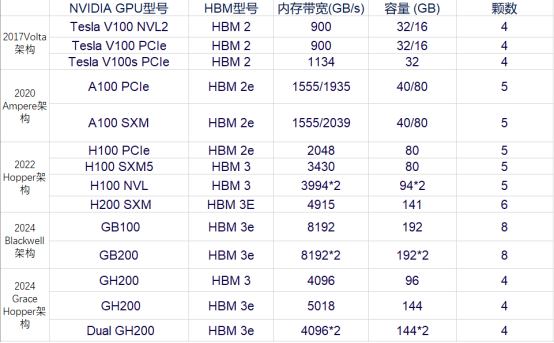
NVIDIA 不同 GPU 型號搭載 HBM 情況
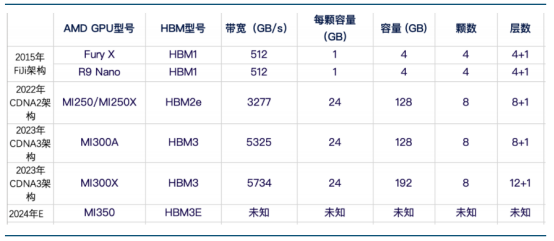
AMD 不同 GPU 型號搭載 HBM 情況 NVIDIA 已在搭載 HBM 的 GPU 型號上迭代 5 次,性能也在不斷跟進以適配 AI 模型與訓練的 需求。在 7 年時間內,從 V100 架構時代搭載的 HBM2 已經演化到了 GB200 的 HBM3E,而內 存寬帶與容量則是在這幾年內翻了數倍。
以同一 Hopper 架構下的 H100 SXM 和 H200 SXM 為例,在其他硬件條件與接口協議相同的情況下,搭載了 HBM3E 的 H200 SXM 要比搭載了 HBM3 的 H100 SXM 在帶寬速率上提升了 43%,在容量上也是擴增了 76%。而對比落后了一 整代,搭載了 HBM 2E 的 A100 SXM,帶寬速率更是提高了 141%,所有的這一切提升都是 HBM 性能迭代帶來的優勢。
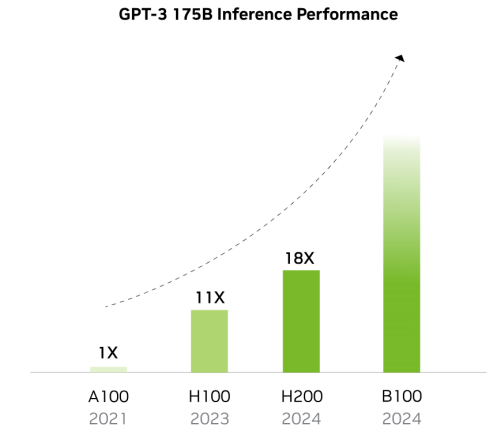
隨著搭載 HBM 容量提升 GPU 效能倍數提升
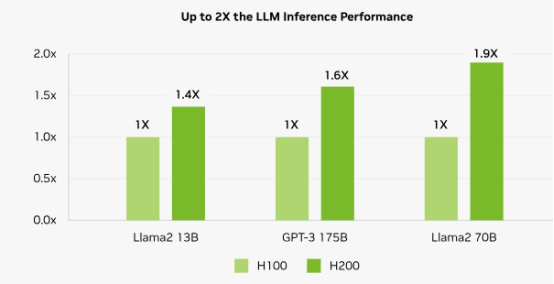
H200 較 H100 在大模型領域性能提升情況 歸因于 AI 大模型的逐步迭代,GPU 迭代速度加快。核心供應商 NVIDIA 和 AMD 新品性能競 爭,預計 2025 年加速 HBM 規格需求大幅轉向 HBM3e,且將會有更多 12hi 的產品出現,帶 動單芯片搭載 HBM 的容量提升。根據 TrendForce 集邦咨詢預估,2024 年的 HBM 需求位元 年成長率近 200%,2025 年可望將再翻倍。
-
DRAM
+關注
關注
40文章
2303瀏覽量
183304 -
存儲
+關注
關注
13文章
4261瀏覽量
85666 -
HBM
+關注
關注
0文章
373瀏覽量
14704
原文標題:AI時代核心存力 HBM(上)
文章出處:【微信號:閃德半導體,微信公眾號:閃德半導體】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI算力需求的暴增,HBM和GDDR SDRAM成為AI芯片新的內存方案
HBM搶單大戰,才剛剛拉開帷幕

被稱為“小號HBM”,華邦電子CUBE進階邊緣AI存儲
大模型時代的算力需求
【AD新聞】AI時代,一美元能夠買到多強的算力?
AI的核心是什么?
嵌入式系統的核心競爭力是什么
英偉達全球首發HBM3e 專為生成式AI時代打造
全面分析服務器/AI計算的算力框架

算力需求催生存力風口,HBM競爭從先進封裝開始
大算力芯片里的HBM,你了解多少?
大模型時代必備存儲之HBM進入汽車領域

中國AI芯片和HBM市場的未來
億鑄科技熊大鵬探討AI大算力芯片的挑戰與解決策略
AI時代核心存力HBM(中)





 工商網監
工商網監
評論