") 三位大神Hinton、Yann LeCun和Bengio分析入門深度學(xué)習(xí)
三位大神Hinton、Yann LeCun和Bengio分析入門深度學(xué)習(xí)
深度學(xué)習(xí)三巨頭Geoffrey Hinton、Yann LeCun和Yoshua Bengio對(duì)AI領(lǐng)域的貢獻(xiàn)無人不知、無人不曉。本文是《Nature》雜志為紀(jì)念人工智能60周年而專門推出的深度學(xué)習(xí)綜述,也是Hinton、LeCun和Bengio三位大神首次合寫同一篇文章。該綜述在深度學(xué)習(xí)領(lǐng)域的重要性不言而喻,可以說是所有人入門深度學(xué)習(xí)的必讀作品。
本文上半部分深入淺出介紹深度學(xué)習(xí)的基本原理和核心優(yōu)勢(shì),下半部分則詳解CNN、分布式特征表示、RNN及其不同的應(yīng)用,并對(duì)深度學(xué)習(xí)技術(shù)的未來發(fā)展進(jìn)行展望。
論文摘要
深度學(xué)習(xí)可以讓那些擁有多個(gè)處理層的計(jì)算模型來學(xué)習(xí)具有多層次抽象的數(shù)據(jù)的表示。這些方法在許多方面都帶來了顯著的改善,包括最先進(jìn)的語音識(shí)別、視覺對(duì)象識(shí)別、對(duì)象檢測(cè)和許多其它領(lǐng)域,例如藥物發(fā)現(xiàn)和基因組學(xué)等。深度學(xué)習(xí)能夠發(fā)現(xiàn)大數(shù)據(jù)中的復(fù)雜結(jié)構(gòu)。它是利用BP算法來完成這個(gè)發(fā)現(xiàn)過程的。BP算法能夠指導(dǎo)機(jī)器如何從前一層獲取誤差而改變本層的內(nèi)部參數(shù),這些內(nèi)部參數(shù)可以用于計(jì)算表示。深度卷積網(wǎng)絡(luò)在處理圖像、視頻、語音和音頻方面帶來了突破,而遞歸網(wǎng)絡(luò)在處理序列數(shù)據(jù),比如文本和演講方面表現(xiàn)出了閃亮的一面。
機(jī)器學(xué)習(xí)技術(shù)在現(xiàn)代社會(huì)的各個(gè)方面表現(xiàn)出了強(qiáng)大的功能:從Web搜索到社會(huì)網(wǎng)絡(luò)內(nèi)容過濾,再到電子商務(wù)網(wǎng)站上的商品推薦都有涉足。并且它越來越多地出現(xiàn)在消費(fèi)品中,比如相機(jī)和智能手機(jī)。
機(jī)器學(xué)習(xí)系統(tǒng)被用來識(shí)別圖片中的目標(biāo),將語音轉(zhuǎn)換成文本,匹配新聞元素,根據(jù)用戶興趣提供職位或產(chǎn)品,選擇相關(guān)的搜索結(jié)果。逐漸地,這些應(yīng)用使用一種叫深度學(xué)習(xí)的技術(shù)。傳統(tǒng)的機(jī)器學(xué)習(xí)技術(shù)在處理未加工過的數(shù)據(jù)時(shí),體現(xiàn)出來的能力是有限的。
幾十年來,想要構(gòu)建一個(gè)模式識(shí)別系統(tǒng)或者機(jī)器學(xué)習(xí)系統(tǒng),需要一個(gè)精致的引擎和相當(dāng)專業(yè)的知識(shí)來設(shè)計(jì)一個(gè)特征提取器,把原始數(shù)據(jù)(如圖像的像素值)轉(zhuǎn)換成一個(gè)適當(dāng)?shù)膬?nèi)部特征表示或特征向量,子學(xué)習(xí)系統(tǒng),通常是一個(gè)分類器,對(duì)輸入的樣本進(jìn)行檢測(cè)或分類。特征表示學(xué)習(xí)是一套給機(jī)器灌入原始數(shù)據(jù),然后能自動(dòng)發(fā)現(xiàn)需要進(jìn)行檢測(cè)和分類的表達(dá)的方法。
深度學(xué)習(xí)就是一種特征學(xué)習(xí)方法,把原始數(shù)據(jù)通過一些簡(jiǎn)單的但是非線性的模型轉(zhuǎn)變成為更高層次的,更加抽象的表達(dá)。通過足夠多的轉(zhuǎn)換的組合,非常復(fù)雜的函數(shù)也可以被學(xué)習(xí)。
對(duì)于分類任務(wù),高層次的表達(dá)能夠強(qiáng)化輸入數(shù)據(jù)的區(qū)分能力方面,同時(shí)削弱不相關(guān)因素。比如,一副圖像的原始格式是一個(gè)像素?cái)?shù)組,那么在第一層上的學(xué)習(xí)特征表達(dá)通常指的是在圖像的特定位置和方向上有沒有邊的存在。第二層通常會(huì)根據(jù)那些邊的某些排放而來檢測(cè)圖案,這時(shí)候會(huì)忽略掉一些邊上的一些小的干擾。第三層或許會(huì)把那些圖案進(jìn)行組合,從而使其對(duì)應(yīng)于熟悉目標(biāo)的某部分。隨后的一些層會(huì)將這些部分再組合,從而構(gòu)成待檢測(cè)目標(biāo)。
深度學(xué)習(xí)的核心方面是,上述各層的特征都不是利用人工工程來設(shè)計(jì)的,而是使用一種通用的學(xué)習(xí)過程從數(shù)據(jù)中學(xué)到的。
深度學(xué)習(xí)正在取得重大進(jìn)展,解決了人工智能界的盡最大努力很多年仍沒有進(jìn)展的問題。它已經(jīng)被證明,它能夠擅長發(fā)現(xiàn)高維數(shù)據(jù)中的復(fù)雜結(jié)構(gòu),因此它能夠被應(yīng)用于科學(xué)、商業(yè)和政府等領(lǐng)域。除了在圖像識(shí)別、語音識(shí)別等領(lǐng)域打破了紀(jì)錄,它還在另外的領(lǐng)域擊敗了其他機(jī)器學(xué)習(xí)技術(shù),包括預(yù)測(cè)潛在的藥物分子的活性、分析粒子加速器數(shù)據(jù)、重建大腦回路、預(yù)測(cè)在非編碼DNA突變對(duì)基因表達(dá)和疾病的影響。
也許更令人驚訝的是,深度學(xué)習(xí)在自然語言理解的各項(xiàng)任務(wù)中產(chǎn)生了非常可喜的成果,特別是主題分類、情感分析、自動(dòng)問答和語言翻譯。我們認(rèn)為,在不久的將來,深度學(xué)習(xí)將會(huì)取得更多的成功,因?yàn)樗枰苌俚氖止すこ蹋梢院苋菀资芤嬗诳捎糜?jì)算能力和數(shù)據(jù)量的增加。目前正在為深度神經(jīng)網(wǎng)絡(luò)開發(fā)的新的學(xué)習(xí)算法和架構(gòu)只會(huì)加速這一進(jìn)程。
監(jiān)督學(xué)習(xí)
機(jī)器學(xué)習(xí)中,不論是否是深層,最常見的形式是監(jiān)督學(xué)習(xí)。
試想一下,我們要建立一個(gè)系統(tǒng),它能夠?qū)σ粋€(gè)包含了一座房子、一輛汽車、一個(gè)人或一個(gè)寵物的圖像進(jìn)行分類。我們先收集大量的房子,汽車,人與寵物的圖像的數(shù)據(jù)集,并對(duì)每個(gè)對(duì)象標(biāo)上它的類別。在訓(xùn)練期間,機(jī)器會(huì)獲取一副圖片,然后產(chǎn)生一個(gè)輸出,這個(gè)輸出以向量形式的分?jǐn)?shù)來表示,每個(gè)類別都有一個(gè)這樣的向量。我們希望所需的類別在所有的類別中具有最高的得分,但是這在訓(xùn)練之前是不太可能發(fā)生的。通過計(jì)算一個(gè)目標(biāo)函數(shù)可以獲得輸出分?jǐn)?shù)和期望模式分?jǐn)?shù)之間的誤差(或距離)。然后機(jī)器會(huì)修改其內(nèi)部可調(diào)參數(shù),以減少這種誤差。這些可調(diào)節(jié)的參數(shù),通常被稱為權(quán)值,它們是一些實(shí)數(shù),可以被看作是一些“旋鈕”,定義了機(jī)器的輸入輸出功能。
在典型的深學(xué)習(xí)系統(tǒng)中,有可能有數(shù)以百萬計(jì)的樣本和權(quán)值,和帶有標(biāo)簽的樣本,用來訓(xùn)練機(jī)器。為了正確地調(diào)整權(quán)值向量,該學(xué)習(xí)算法計(jì)算每個(gè)權(quán)值的梯度向量,表示了如果權(quán)值增加了一個(gè)很小的量,那么誤差會(huì)增加或減少的量。權(quán)值向量然后在梯度矢量的相反方向上進(jìn)行調(diào)整。我們的目標(biāo)函數(shù),所有訓(xùn)練樣本的平均,可以被看作是一種在權(quán)值的高維空間上的多變地形。負(fù)的梯度矢量表示在該地形中下降方向最快,使其更接近于最小值,也就是平均輸出誤差低最低的地方。
在實(shí)際應(yīng)用中,大部分從業(yè)者都使用一種稱作隨機(jī)梯度下降的算法(SGD)。它包含了提供一些輸入向量樣本,計(jì)算輸出和誤差,計(jì)算這些樣本的平均梯度,然后相應(yīng)的調(diào)整權(quán)值。通過提供小的樣本集合來重復(fù)這個(gè)過程用以訓(xùn)練網(wǎng)絡(luò),直到目標(biāo)函數(shù)停止增長。它被稱為隨機(jī)的是因?yàn)樾〉臉颖炯瘜?duì)于全體樣本的平均梯度來說會(huì)有噪聲估計(jì)。這個(gè)簡(jiǎn)單過程通常會(huì)找到一組不錯(cuò)的權(quán)值,同其他精心設(shè)計(jì)的優(yōu)化技術(shù)相比,它的速度讓人驚奇。訓(xùn)練結(jié)束之后,系統(tǒng)會(huì)通過不同的數(shù)據(jù)樣本——測(cè)試集來顯示系統(tǒng)的性能。這用于測(cè)試機(jī)器的泛化能力——對(duì)于未訓(xùn)練過的新樣本的識(shí)別能力。
當(dāng)前應(yīng)用中的許多機(jī)器學(xué)習(xí)技術(shù)使用的是線性分類器來對(duì)人工提取的特征進(jìn)行分類。一個(gè)2類線性分類器會(huì)計(jì)算特征向量的加權(quán)和。當(dāng)加權(quán)和超過一個(gè)閾值之后,輸入樣本就會(huì)被分配到一個(gè)特定的類別中。從20世紀(jì)60年代開始,我們就知道了線性分類器只能夠把樣本分成非常簡(jiǎn)單的區(qū)域,也就是說通過一個(gè)超平面把空間分成兩部分。
但像圖像和語音識(shí)別等問題,它們需要的輸入-輸出函數(shù)要對(duì)輸入樣本中不相關(guān)因素的變化不要過于的敏感,如位置的變化,目標(biāo)的方向或光照,或者語音中音調(diào)或語調(diào)的變化等,但是需要對(duì)于一些特定的微小變化非常敏感(例如,一只白色的狼和跟狼類似的白色狗——薩莫耶德犬之間的差異)。在像素這一級(jí)別上,兩條薩莫耶德犬在不同的姿勢(shì)和在不同的環(huán)境下的圖像可以說差異是非常大的,然而,一只薩摩耶德犬和一只狼在相同的位置并在相似背景下的兩個(gè)圖像可能就非常類似。
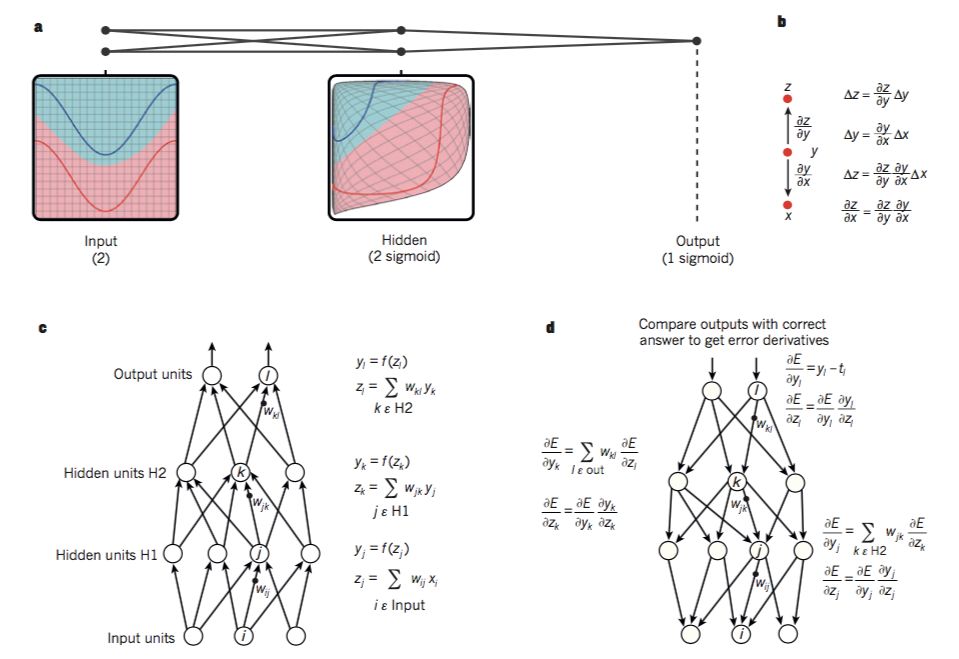
圖1 多層神經(jīng)網(wǎng)絡(luò)和BP算法
多層神經(jīng)網(wǎng)絡(luò)(用連接點(diǎn)表示)可以對(duì)輸入空間進(jìn)行整合,使得數(shù)據(jù)(紅色和藍(lán)色線表示的樣本)線性可分。注意輸入空間中的規(guī)則網(wǎng)格(左側(cè))是如何被隱藏層轉(zhuǎn)換的(轉(zhuǎn)換后的在右側(cè))。這個(gè)例子中只用了兩個(gè)輸入節(jié)點(diǎn),兩個(gè)隱藏節(jié)點(diǎn)和一個(gè)輸出節(jié)點(diǎn),但是用于目標(biāo)識(shí)別或自然語言處理的網(wǎng)絡(luò)通常包含數(shù)十個(gè)或者數(shù)百個(gè)這樣的節(jié)點(diǎn)。獲得C.Olah(http://colah.github.io/)的許可后重新構(gòu)建的這個(gè)圖。
鏈?zhǔn)椒▌t告訴我們兩個(gè)小的變化(x和y的微小變化,以及y和z的微小變化)是怎樣組織到一起的。x的微小變化量Δx首先會(huì)通過乘以?y/?x(偏導(dǎo)數(shù))轉(zhuǎn)變成y的變化量Δy。類似的,Δy會(huì)給z帶來改變?chǔ)。通過鏈?zhǔn)椒▌t可以將一個(gè)方程轉(zhuǎn)化到另外的一個(gè)——也就是Δx通過乘以?y/?x和?z/?x得到Δz的過程。當(dāng)x,y,z是向量的時(shí)候,可以同樣處理(使用雅克比矩陣)。
具有兩個(gè)隱層一個(gè)輸出層的神經(jīng)網(wǎng)絡(luò)中計(jì)算前向傳播的公式。每個(gè)都有一個(gè)模塊構(gòu)成,用于反向傳播梯度。在每一層上,我們首先計(jì)算每個(gè)節(jié)點(diǎn)的總輸入z,z是前一層輸出的加權(quán)和。然后利用一個(gè)非線性函數(shù)f(.)來計(jì)算節(jié)點(diǎn)的輸出。簡(jiǎn)單期間,我們忽略掉了閾值項(xiàng)。神經(jīng)網(wǎng)絡(luò)中常用的非線性函數(shù)包括了最近幾年常用的校正線性單元(ReLU)f(z) = max(0,z),和傳統(tǒng)的sigmoids,比如f(z) = (exp(z) ? exp(?z))/(exp(z) + exp(?z)) 和f(z) = 1/(1 + exp(?z))。
計(jì)算反向傳播的公式。在隱層,我們計(jì)算每個(gè)輸出單元產(chǎn)生的誤差,這是由上一層產(chǎn)生的誤差的加權(quán)和。然后我們將輸出層的誤差通過乘以梯度f(z)轉(zhuǎn)換到輸入層。在輸出層上,每個(gè)節(jié)點(diǎn)的誤差會(huì)用成本函數(shù)的微分來計(jì)算。如果節(jié)點(diǎn)l的成本函數(shù)是0.5*(yl-tl)^2, 那么節(jié)點(diǎn)的誤差就是yl-tl,其中tl是期望值。一旦知道了?E/?zk的值,節(jié)點(diǎn)j的內(nèi)星權(quán)向量wjk就可以通過yj ?E/?zk來進(jìn)行調(diào)整。
一個(gè)線性分類器或者其他操作在原始像素上的淺層分類器不能夠區(qū)分后兩者,雖然能夠?qū)⑶罢邭w為同一類。這就是為什么淺分類要求有良好的特征提取器用于解決選擇性不變性困境——提取器會(huì)挑選出圖像中能夠區(qū)分目標(biāo)的那些重要因素,但是這些因素對(duì)于分辨動(dòng)物的位置就無能為力了。為了加強(qiáng)分類能力,可以使用泛化的非線性特性,如核方法,但這些泛化特征,比如通過高斯核得到的,并不能夠使得學(xué)習(xí)器從學(xué)習(xí)樣本中產(chǎn)生較好的泛化效果。
傳統(tǒng)的方法是手工設(shè)計(jì)良好的特征提取器,這需要大量的工程技術(shù)和專業(yè)領(lǐng)域知識(shí)。但是如果通過使用通用學(xué)習(xí)過程而得到良好的特征,那么這些都是可以避免的了。這就是深度學(xué)習(xí)的關(guān)鍵優(yōu)勢(shì)。
深度學(xué)習(xí)的體系結(jié)構(gòu)是簡(jiǎn)單模塊的多層棧,所有(或大部分)模塊的目標(biāo)是學(xué)習(xí),還有許多計(jì)算非線性輸入輸出的映射。棧中的每個(gè)模塊將其輸入進(jìn)行轉(zhuǎn)換,以增加表達(dá)的可選擇性和不變性。比如說,具有一個(gè)5到20層的非線性多層系統(tǒng)能夠?qū)崿F(xiàn)非常復(fù)雜的功能,比如輸入數(shù)據(jù)對(duì)細(xì)節(jié)非常敏感——能夠區(qū)分白狼和薩莫耶德犬,同時(shí)又具有強(qiáng)大的抗干擾能力,比如可以忽略掉不同的背景、姿勢(shì)、光照和周圍的物體等。
用反向傳播訓(xùn)練多層神經(jīng)網(wǎng)絡(luò)
在最早期的模式識(shí)別任務(wù)中,研究者的目標(biāo)一直是使用可以訓(xùn)練的多層網(wǎng)絡(luò)來替代經(jīng)過人工選擇的特征,雖然使用多層神經(jīng)網(wǎng)絡(luò)很簡(jiǎn)單,但是得出來的解很糟糕。直到20世紀(jì)80年代,使用簡(jiǎn)單的隨機(jī)梯度下降來訓(xùn)練多層神經(jīng)網(wǎng)絡(luò),這種糟糕的情況才有所改變。只要網(wǎng)絡(luò)的輸入和內(nèi)部權(quán)值之間的函數(shù)相對(duì)平滑,使用梯度下降就湊效,梯度下降方法是在70年代到80年代期間由不同的研究團(tuán)隊(duì)獨(dú)立發(fā)明的。
用來求解目標(biāo)函數(shù)關(guān)于多層神經(jīng)網(wǎng)絡(luò)權(quán)值梯度的反向傳播算法(BP)只是一個(gè)用來求導(dǎo)的鏈?zhǔn)椒▌t的具體應(yīng)用而已。反向傳播算法的核心思想是:目標(biāo)函數(shù)對(duì)于某層輸入的導(dǎo)數(shù)(或者梯度)可以通過向后傳播對(duì)該層輸出(或者下一層輸入)的導(dǎo)數(shù)求得(如圖1)。反向傳播算法可以被重復(fù)的用于傳播梯度通過多層神經(jīng)網(wǎng)絡(luò)的每一層:從該多層神經(jīng)網(wǎng)絡(luò)的最頂層的輸出(也就是改網(wǎng)絡(luò)產(chǎn)生預(yù)測(cè)的那一層)一直到該多層神經(jīng)網(wǎng)絡(luò)的最底層(也就是被接受外部輸入的那一層),一旦這些關(guān)于(目標(biāo)函數(shù)對(duì))每層輸入的導(dǎo)數(shù)求解完,我們就可以求解每一層上面的(目標(biāo)函數(shù)對(duì))權(quán)值的梯度了。
很多深度學(xué)習(xí)的應(yīng)用都是使用前饋式神經(jīng)網(wǎng)絡(luò)(如圖1),該神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)一個(gè)從固定大小輸入(比如輸入是一張圖)到固定大小輸出(例如,到不同類別的概率)的映射。從第一層到下一層,計(jì)算前一層神經(jīng)元輸入數(shù)據(jù)的權(quán)值的和,然后把這個(gè)和傳給一個(gè)非線性激活函數(shù)。當(dāng)前最流行的非線性激活函數(shù)是rectified linear unit(ReLU),函數(shù)形式:f(z)=max(z,0)。過去的幾十年中,神經(jīng)網(wǎng)絡(luò)使用一些更加平滑的非線性函數(shù),比如tanh(z)和1/(1+exp(-z)),但是ReLU通常會(huì)讓一個(gè)多層神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)的更快,也可以讓一個(gè)深度網(wǎng)絡(luò)直接有監(jiān)督的訓(xùn)練(不需要無監(jiān)督的pre-train)。
達(dá)到之前那種有pre-train的效果。通常情況下,輸入層和輸出層以外的神經(jīng)單元被稱為隱藏單元。隱藏層的作用可以看成是使用一個(gè)非線性的方式打亂輸入數(shù)據(jù),來讓輸入數(shù)據(jù)對(duì)應(yīng)的類別在最后一層變得線性可分。
在20世紀(jì)90年代晚期,神經(jīng)網(wǎng)絡(luò)和反向傳播算法被大多數(shù)機(jī)器學(xué)習(xí)團(tuán)隊(duì)拋棄,同時(shí)也不受計(jì)算機(jī)視覺和語音識(shí)別團(tuán)隊(duì)的重視。人們普遍認(rèn)為,學(xué)習(xí)有用的、多級(jí)層次結(jié)構(gòu)的、使用較少先驗(yàn)知識(shí)進(jìn)行特征提取的這些方法都不靠譜。確切的說是因?yàn)楹?jiǎn)單的梯度下降會(huì)讓整個(gè)優(yōu)化陷入到不好的局部最小解。
實(shí)踐中,如果在大的網(wǎng)絡(luò)中,不管使用什么樣的初始化條件,局部最小解并不算什么大問題,系統(tǒng)總是得到效果差不多的解。最近的理論和實(shí)驗(yàn)表明,局部最小解還真不是啥大問題。相反,解空間中充滿了大量的鞍點(diǎn)(梯度為0的點(diǎn)),同時(shí)鞍點(diǎn)周圍大部分曲面都是往上的。所以這些算法就算是陷入了這些局部最小值,關(guān)系也不太大。
2006年前后,CIFAR(加拿大高級(jí)研究院)把一些研究者聚集在一起,人們對(duì)深度前饋式神經(jīng)網(wǎng)絡(luò)重新燃起了興趣。研究者們提出了一種非監(jiān)督的學(xué)習(xí)方法,這種方法可以創(chuàng)建一些網(wǎng)絡(luò)層來檢測(cè)特征而不使用帶標(biāo)簽的數(shù)據(jù),這些網(wǎng)絡(luò)層可以用來重構(gòu)或者對(duì)特征檢測(cè)器的活動(dòng)進(jìn)行建模。通過預(yù)訓(xùn)練過程,深度網(wǎng)絡(luò)的權(quán)值可以被初始化為有意思的值。然后一個(gè)輸出層被添加到該網(wǎng)絡(luò)的頂部,并且使用標(biāo)準(zhǔn)的反向傳播算法進(jìn)行微調(diào)。這個(gè)工作對(duì)手寫體數(shù)字的識(shí)別以及行人預(yù)測(cè)任務(wù)產(chǎn)生了顯著的效果,尤其是帶標(biāo)簽的數(shù)據(jù)非常少的時(shí)候。
使用這種與訓(xùn)練方法做出來的第一個(gè)比較大的應(yīng)用是關(guān)于語音識(shí)別的,并且是在GPU上做的,這樣做是因?yàn)閷懘a很方便,并且在訓(xùn)練的時(shí)候可以得到10倍或者20倍的加速。2009年,這種方法被用來映射短時(shí)間的系數(shù)窗口,該系統(tǒng)窗口是提取自聲波并被轉(zhuǎn)換成一組概率數(shù)字。它在一組使用很少詞匯的標(biāo)準(zhǔn)的語音識(shí)別基準(zhǔn)測(cè)試程序上達(dá)到了驚人的效果,然后又迅速被發(fā)展到另外一個(gè)更大的數(shù)據(jù)集上,同時(shí)也取得驚人的效果。從2009年到到2012年底,較大的語音團(tuán)隊(duì)開發(fā)了這種深度網(wǎng)絡(luò)的多個(gè)版本并且已經(jīng)被用到了安卓手機(jī)上。對(duì)于小的數(shù)據(jù)集來說,無監(jiān)督的預(yù)訓(xùn)練可以防止過擬合,同時(shí)可以帶來更好的泛化性能當(dāng)有標(biāo)簽的樣本很小的時(shí)候。一旦深度學(xué)習(xí)技術(shù)重新恢復(fù),這種預(yù)訓(xùn)練只有在數(shù)據(jù)集合較少的時(shí)候才需要。
然后,還有一種深度前饋式神經(jīng)網(wǎng)絡(luò),這種網(wǎng)絡(luò)更易于訓(xùn)練并且比那種全連接的神經(jīng)網(wǎng)絡(luò)的泛化性能更好。這就是卷積神經(jīng)網(wǎng)絡(luò)(CNN)。當(dāng)人們對(duì)神經(jīng)網(wǎng)絡(luò)不感興趣的時(shí)候,卷積神經(jīng)網(wǎng)絡(luò)在實(shí)踐中卻取得了很多成功,如今它被計(jì)算機(jī)視覺團(tuán)隊(duì)廣泛使用。
卷積神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)被設(shè)計(jì)用來處理到多維數(shù)組數(shù)據(jù)的,比如一個(gè)有3個(gè)包含了像素值2-D圖像組合成的一個(gè)具有3個(gè)顏色通道的彩色圖像。很多數(shù)據(jù)形態(tài)都是這種多維數(shù)組的:1D用來表示信號(hào)和序列包括語言,2D用來表示圖像或者聲音,3D用來表示視頻或者有聲音的圖像。卷積神經(jīng)網(wǎng)絡(luò)使用4個(gè)關(guān)鍵的想法來利用自然信號(hào)的屬性:局部連接、權(quán)值共享、池化以及多網(wǎng)絡(luò)層的使用。
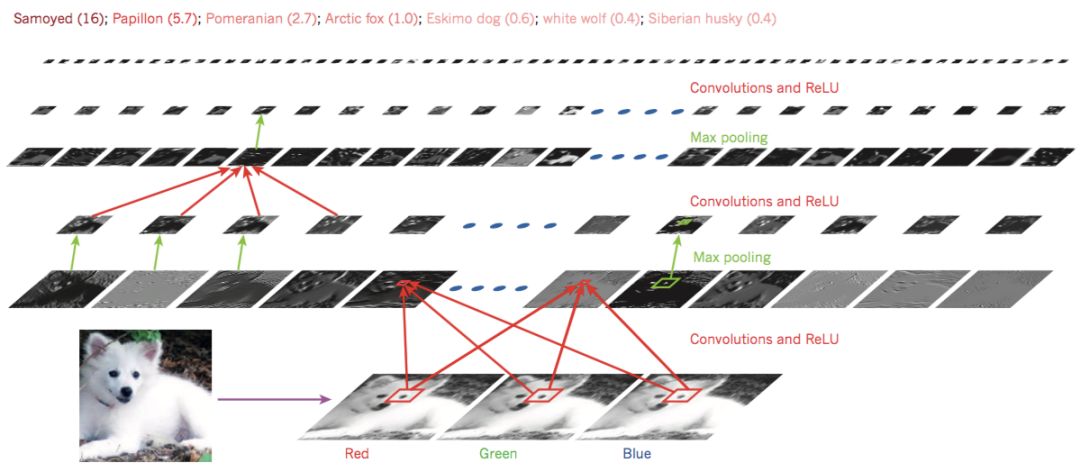
圖2 卷積神經(jīng)網(wǎng)絡(luò)內(nèi)部
一個(gè)典型的卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)(如圖2)是由一系列的過程組成的。最初的幾個(gè)階段是由卷積層和池化層組成,卷積層的單元被組織在特征圖中,在特征圖中,每一個(gè)單元通過一組叫做濾波器的權(quán)值被連接到上一層的特征圖的一個(gè)局部塊,然后這個(gè)局部加權(quán)和被傳給一個(gè)非線性函數(shù),比如ReLU。在一個(gè)特征圖中的全部單元享用相同的過濾器,不同層的特征圖使用不同的過濾器。使用這種結(jié)構(gòu)處于兩方面的原因。
首先,在數(shù)組數(shù)據(jù)中,比如圖像數(shù)據(jù),一個(gè)值的附近的值經(jīng)常是高度相關(guān)的,可以形成比較容易被探測(cè)到的有區(qū)分性的局部特征。其次,不同位置局部統(tǒng)計(jì)特征不太相關(guān)的,也就是說,在一個(gè)地方出現(xiàn)的某個(gè)特征,也可能出現(xiàn)在別的地方,所以不同位置的單元可以共享權(quán)值以及可以探測(cè)相同的樣本。在數(shù)學(xué)上,這種由一個(gè)特征圖執(zhí)行的過濾操作是一個(gè)離線的卷積,卷積神經(jīng)網(wǎng)絡(luò)也是這么得名來的。
卷積層的作用是探測(cè)上一層特征的局部連接,然而池化層的作用是在語義上把相似的特征合并起來,這是因?yàn)樾纬梢粋€(gè)主題的特征的相對(duì)位置不太一樣。一般地,池化單元計(jì)算特征圖中的一個(gè)局部塊的最大值,相鄰的池化單元通過移動(dòng)一行或者一列來從小塊上讀取數(shù)據(jù),因?yàn)檫@樣做就減少的表達(dá)的維度以及對(duì)數(shù)據(jù)的平移不變性。兩三個(gè)這種的卷積、非線性變換以及池化被串起來,后面再加上一個(gè)更多卷積和全連接層。在卷積神經(jīng)網(wǎng)絡(luò)上進(jìn)行反向傳播算法和在一般的深度網(wǎng)絡(luò)上是一樣的,可以讓所有的在過濾器中的權(quán)值得到訓(xùn)練。
深度神經(jīng)網(wǎng)絡(luò)利用的很多自然信號(hào)是層級(jí)組成的屬性,在這種屬性中高級(jí)的特征是通過對(duì)低級(jí)特征的組合來實(shí)現(xiàn)的。在圖像中,局部邊緣的組合形成基本圖案,這些圖案形成物體的局部,然后再形成物體。這種層級(jí)結(jié)構(gòu)也存在于語音數(shù)據(jù)以及文本數(shù)據(jù)中,如電話中的聲音,因素,音節(jié),文檔中的單詞和句子。當(dāng)輸入數(shù)據(jù)在前一層中的位置有變化的時(shí)候,池化操作讓這些特征表示對(duì)這些變化具有魯棒性。
卷積神經(jīng)網(wǎng)絡(luò)中的卷積和池化層靈感直接來源于視覺神經(jīng)科學(xué)中的簡(jiǎn)單細(xì)胞和復(fù)雜細(xì)胞。這種細(xì)胞的是以LNG-V1-V2-V4-IT這種層級(jí)結(jié)構(gòu)形成視覺回路的。當(dāng)給一個(gè)卷積神經(jīng)網(wǎng)絡(luò)和猴子一副相同的圖片的時(shí)候,卷積神經(jīng)網(wǎng)絡(luò)展示了猴子下顳葉皮質(zhì)中隨機(jī)160個(gè)神經(jīng)元的變化。卷積神經(jīng)網(wǎng)絡(luò)有神經(jīng)認(rèn)知的根源,他們的架構(gòu)有點(diǎn)相似,但是在神經(jīng)認(rèn)知中是沒有類似反向傳播算法這種端到端的監(jiān)督學(xué)習(xí)算法的。一個(gè)比較原始的1D卷積神經(jīng)網(wǎng)絡(luò)被稱為時(shí)延神經(jīng)網(wǎng)絡(luò),可以被用來識(shí)別語音以及簡(jiǎn)單的單詞。
20世紀(jì)90年代以來,基于卷積神經(jīng)網(wǎng)絡(luò)出現(xiàn)了大量的應(yīng)用。最開始是用時(shí)延神經(jīng)網(wǎng)絡(luò)來做語音識(shí)別以及文檔閱讀。這個(gè)文檔閱讀系統(tǒng)使用一個(gè)被訓(xùn)練好的卷積神經(jīng)網(wǎng)絡(luò)和一個(gè)概率模型,這個(gè)概率模型實(shí)現(xiàn)了語言方面的一些約束。20世紀(jì)90年代末,這個(gè)系統(tǒng)被用來美國超過10%的支票閱讀上。后來,微軟開發(fā)了基于卷積神經(jīng)網(wǎng)絡(luò)的字符識(shí)別系統(tǒng)以及手寫體識(shí)別系統(tǒng)。20世紀(jì)90年代早期,卷積神經(jīng)網(wǎng)絡(luò)也被用來自然圖形中的物體識(shí)別,比如臉、手以及人臉識(shí)別(face recognition)。
使用深度卷積網(wǎng)絡(luò)進(jìn)行圖像理解
21世紀(jì)開始,卷積神經(jīng)網(wǎng)絡(luò)就被成功的大量用于檢測(cè)、分割、物體識(shí)別以及圖像的各個(gè)領(lǐng)域。這些應(yīng)用都是使用了大量的有標(biāo)簽的數(shù)據(jù),比如交通信號(hào)識(shí)別,生物信息分割,面部探測(cè),文本、行人以及自然圖形中的人的身體部分的探測(cè)。近年來,卷積神經(jīng)網(wǎng)絡(luò)的一個(gè)重大成功應(yīng)用是人臉識(shí)別。
值得一提的是,圖像可以在像素級(jí)別進(jìn)行打標(biāo)簽,這樣就可以應(yīng)用在比如自動(dòng)電話接聽機(jī)器人、自動(dòng)駕駛汽車等技術(shù)中。像Mobileye以及NVIDIA公司正在把基于卷積神經(jīng)網(wǎng)絡(luò)的方法用于汽車中的視覺系統(tǒng)中。其它的應(yīng)用涉及到自然語言的理解以及語音識(shí)別中。
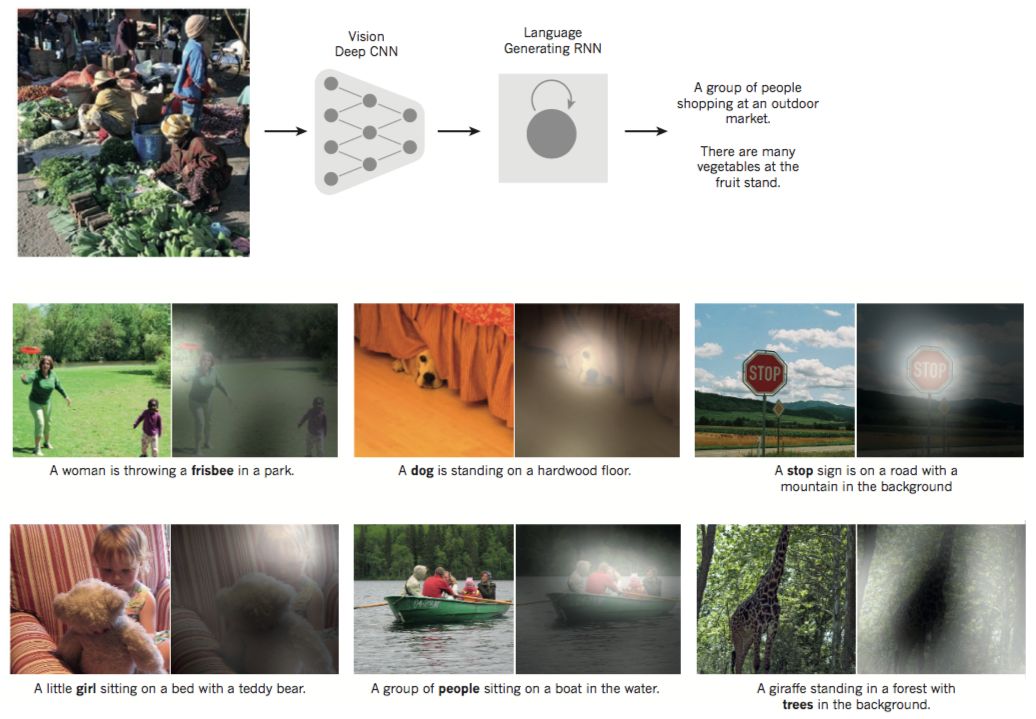
圖3 從圖像到文字
盡管卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用的很成功,但是它被計(jì)算機(jī)視覺以及機(jī)器學(xué)習(xí)團(tuán)隊(duì)開始重視是在2012年的ImageNet競(jìng)賽。在該競(jìng)賽中,深度卷積神經(jīng)網(wǎng)絡(luò)被用在上百萬張網(wǎng)絡(luò)圖片數(shù)據(jù)集,這個(gè)數(shù)據(jù)集包含了1000個(gè)不同的類。該結(jié)果達(dá)到了前所未有的好,幾乎比當(dāng)時(shí)最好的方法降低了一半的錯(cuò)誤率。這個(gè)成功來自有效地利用了GPU、ReLU、一個(gè)新的被稱為dropout的正則技術(shù),以及通過分解現(xiàn)有樣本產(chǎn)生更多訓(xùn)練樣本的技術(shù)。這個(gè)成功給計(jì)算機(jī)視覺帶來一個(gè)革命。如今,卷積神經(jīng)網(wǎng)絡(luò)用于幾乎全部的識(shí)別和探測(cè)任務(wù)中。最近一個(gè)更好的成果是,利用卷積神經(jīng)網(wǎng)絡(luò)結(jié)合回饋神經(jīng)網(wǎng)絡(luò)用來產(chǎn)生圖像標(biāo)題。
如今的卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)有10-20層采用ReLU激活函數(shù)、上百萬個(gè)權(quán)值以及幾十億個(gè)連接。然而訓(xùn)練如此大的網(wǎng)絡(luò)兩年前就只需要幾周了,現(xiàn)在硬件、軟件以及算法并行的進(jìn)步,又把訓(xùn)練時(shí)間壓縮到了幾小時(shí)。
基于卷積神經(jīng)網(wǎng)絡(luò)的視覺系統(tǒng)的性能已經(jīng)引起了大型技術(shù)公司的注意,比如Google、Facebook、Microsoft、IBM,yahoo!、Twitter和Adobe等,一些快速增長的創(chuàng)業(yè)公司也同樣如是。
卷積神經(jīng)網(wǎng)絡(luò)很容易在芯片或者現(xiàn)場(chǎng)可編程門陣列(FPGA)中高效實(shí)現(xiàn),許多公司比如NVIDIA、Mobileye、Intel、Qualcomm以及Samsung,正在開發(fā)卷積神經(jīng)網(wǎng)絡(luò)芯片,以使智能機(jī)、相機(jī)、機(jī)器人以及自動(dòng)駕駛汽車中的實(shí)時(shí)視覺系統(tǒng)成為可能。
分布式特征表示與語言處理
與不使用分布式特征表示(distributed representations)的經(jīng)典學(xué)習(xí)算法相比,深度學(xué)習(xí)理論表明深度網(wǎng)絡(luò)具有兩個(gè)不同的巨大的優(yōu)勢(shì)。這些優(yōu)勢(shì)來源于網(wǎng)絡(luò)中各節(jié)點(diǎn)的權(quán)值,并取決于具有合理結(jié)構(gòu)的底層生成數(shù)據(jù)的分布。首先,學(xué)習(xí)分布式特征表示能夠泛化適應(yīng)新學(xué)習(xí)到的特征值的組合(比如,n元特征就有2n種可能的組合)。其次,深度網(wǎng)絡(luò)中組合表示層帶來了另一個(gè)指數(shù)級(jí)的優(yōu)勢(shì)潛能(指數(shù)級(jí)的深度)。
多層神經(jīng)網(wǎng)絡(luò)中的隱層利用網(wǎng)絡(luò)中輸入的數(shù)據(jù)進(jìn)行特征學(xué)習(xí),使之更加容易預(yù)測(cè)目標(biāo)輸出。下面是一個(gè)很好的示范例子,比如將本地文本的內(nèi)容作為輸入,訓(xùn)練多層神經(jīng)網(wǎng)絡(luò)來預(yù)測(cè)句子中下一個(gè)單詞。內(nèi)容中的每個(gè)單詞表示為網(wǎng)絡(luò)中的N分之一的向量,也就是說,每個(gè)組成部分中有一個(gè)值為1其余的全為0。在第一層中,每個(gè)單詞創(chuàng)建不同的激活狀態(tài),或單詞向量(如圖4)。在語言模型中,網(wǎng)絡(luò)中其余層學(xué)習(xí)并轉(zhuǎn)化輸入的單詞向量為輸出單詞向量來預(yù)測(cè)句子中下一個(gè)單詞,可以通過預(yù)測(cè)詞匯表中的單詞作為文本句子中下一個(gè)單詞出現(xiàn)的概率。網(wǎng)絡(luò)學(xué)習(xí)了包含許多激活節(jié)點(diǎn)的、并且可以解釋為詞的獨(dú)立特征的單詞向量,正如第一次示范的文本學(xué)習(xí)分層表征文字符號(hào)的例子。這些語義特征在輸入中并沒有明確的表征。而是在利用“微規(guī)則”(‘micro-rules’,本文中直譯為:微規(guī)則)學(xué)習(xí)過程中被發(fā)掘,并作為一個(gè)分解輸入與輸出符號(hào)之間關(guān)系結(jié)構(gòu)的好的方式。當(dāng)句子是來自大量的真實(shí)文本并且個(gè)別的微規(guī)則不可靠的情況下,學(xué)習(xí)單詞向量也一樣能表現(xiàn)得很好。利用訓(xùn)練好的模型預(yù)測(cè)新的事例時(shí),一些概念比較相似的詞容易混淆,比如星期二(Tuesday)和星期三(Wednesday),瑞典(Sweden)和挪威(Norway)。這樣的表示方式被稱為分布式特征表示,因?yàn)樗麄兊脑刂g并不互相排斥,并且他們的構(gòu)造信息對(duì)應(yīng)于觀測(cè)到的數(shù)據(jù)的變化。這些單詞向量是通過學(xué)習(xí)得到的特征構(gòu)造的,這些特征不是由專家決定的,而是由神經(jīng)網(wǎng)絡(luò)自動(dòng)發(fā)掘的。從文本中學(xué)習(xí)得單詞向量表示現(xiàn)在廣泛應(yīng)用于自然語言中。
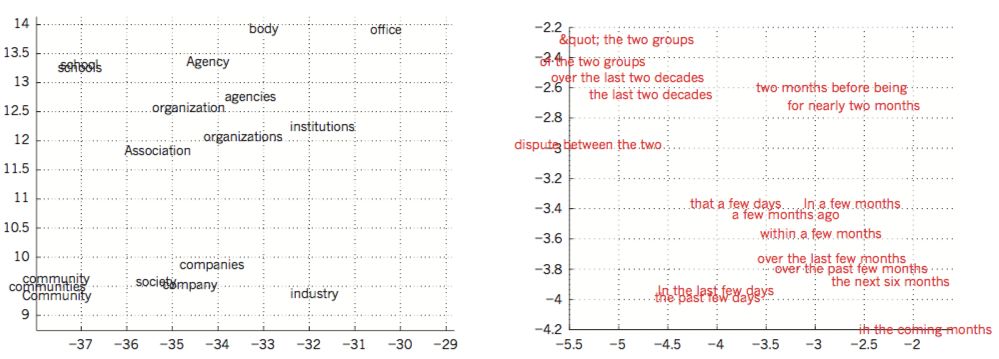
圖4 詞向量學(xué)習(xí)可視化
特征表示問題爭(zhēng)論的中心介于對(duì)基于邏輯啟發(fā)和基于神經(jīng)網(wǎng)絡(luò)的認(rèn)識(shí)。在邏輯啟發(fā)的范式中,一個(gè)符號(hào)實(shí)體表示某一事物,因?yàn)槠湮ㄒ坏膶傩耘c其他符號(hào)實(shí)體相同或者不同。該符號(hào)實(shí)例沒有內(nèi)部結(jié)構(gòu),并且結(jié)構(gòu)與使用是相關(guān)的,至于理解符號(hào)的語義,就必須與變化的推理規(guī)則合理對(duì)應(yīng)。相反地,神經(jīng)網(wǎng)絡(luò)利用了大量活動(dòng)載體、權(quán)值矩陣和標(biāo)量非線性化,來實(shí)現(xiàn)能夠支撐簡(jiǎn)單容易的、具有常識(shí)推理的快速“直覺”功能。
在介紹神經(jīng)語言模型前,簡(jiǎn)述下標(biāo)準(zhǔn)方法,其是基于統(tǒng)計(jì)的語言模型,該模型沒有使用分布式特征表示。而是基于統(tǒng)計(jì)簡(jiǎn)短符號(hào)序列出現(xiàn)的頻率增長到N(N-grams,N元文法)。可能的N-grams的數(shù)字接近于VN,其中V是詞匯表的大小,考慮到文本內(nèi)容包含成千上萬個(gè)單詞,所以需要一個(gè)非常大的語料庫。N-grams將每個(gè)單詞看成一個(gè)原子單元,因此不能在語義相關(guān)的單詞序列中一概而論,然而神經(jīng)網(wǎng)絡(luò)語言模型可以,是因?yàn)樗麄冴P(guān)聯(lián)每個(gè)詞與真是特征值的向量,并且在向量空間中語義相關(guān)的詞彼此靠近(圖4)。
遞歸神經(jīng)網(wǎng)絡(luò)
首次引入反向傳播算法時(shí),最令人興奮的便是使用遞歸神經(jīng)網(wǎng)絡(luò)(recurrent neural networks,下文簡(jiǎn)稱RNNs)訓(xùn)練。對(duì)于涉及到序列輸入的任務(wù),比如語音和語言,利用RNNs能獲得更好的效果。RNNs一次處理一個(gè)輸入序列元素,同時(shí)維護(hù)網(wǎng)絡(luò)中隱式單元中隱式的包含過去時(shí)刻序列元素的歷史信息的“狀態(tài)向量”。如果是深度多層網(wǎng)絡(luò)不同神經(jīng)元的輸出,我們就會(huì)考慮這種在不同離散時(shí)間步長的隱式單元的輸出,這將會(huì)使我們更加清晰怎么利用反向傳播來訓(xùn)練RNNs(如圖5,右)。
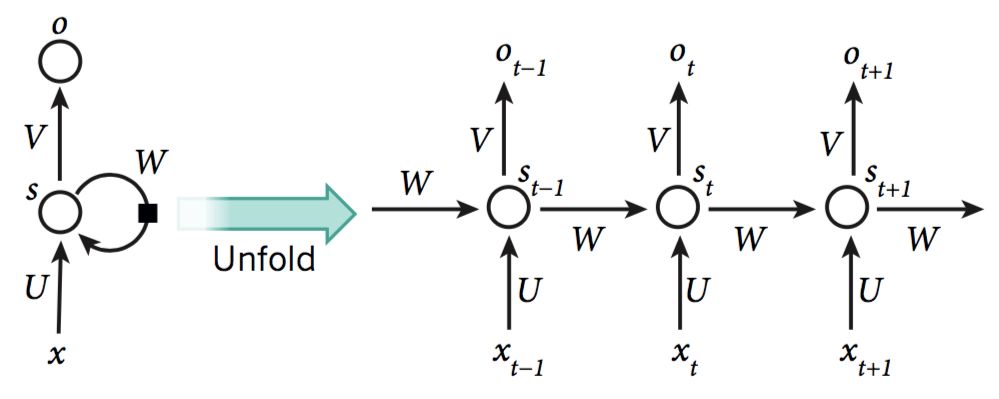
圖5 遞歸神經(jīng)網(wǎng)絡(luò)
RNNs是非常強(qiáng)大的動(dòng)態(tài)系統(tǒng),但是訓(xùn)練它們被證實(shí)存在問題的,因?yàn)榉聪騻鞑サ奶荻仍诿總€(gè)時(shí)間間隔內(nèi)是增長或下降的,所以經(jīng)過一段時(shí)間后將導(dǎo)致結(jié)果的激增或者降為零。
由于先進(jìn)的架構(gòu)和訓(xùn)練方式,RNNs被發(fā)現(xiàn)可以很好的預(yù)測(cè)文本中下一個(gè)字符或者句子中下一個(gè)單詞,并且可以應(yīng)用于更加復(fù)雜的任務(wù)。例如在某時(shí)刻閱讀英語句子中的單詞后,將會(huì)訓(xùn)練一個(gè)英語的“編碼器”網(wǎng)絡(luò),使得隱式單元的最終狀態(tài)向量能夠很好地表征句子所要表達(dá)的意思或思想。這種“思想向量”(thought vector)可以作為聯(lián)合訓(xùn)練一個(gè)法語“編碼器”網(wǎng)絡(luò)的初始化隱式狀態(tài)(或者額外的輸入),其輸出為法語翻譯首單詞的概率分布。如果從分布中選擇一個(gè)特殊的首單詞作為編碼網(wǎng)絡(luò)的輸入,將會(huì)輸出翻譯的句子中第二個(gè)單詞的概率分布,并直到停止選擇為止。總體而言,這一過程是根據(jù)英語句子的概率分布而產(chǎn)生的法語詞匯序列。這種簡(jiǎn)單的機(jī)器翻譯方法的表現(xiàn)甚至可以和最先進(jìn)的(state-of-the-art)的方法相媲美,同時(shí)也引起了人們對(duì)于理解句子是否需要像使用推理規(guī)則操作內(nèi)部符號(hào)表示質(zhì)疑。這與日常推理中同時(shí)涉及到根據(jù)合理結(jié)論類推的觀點(diǎn)是匹配的。
類比于將法語句子的意思翻譯成英語句子,同樣可以學(xué)習(xí)將圖片內(nèi)容“翻譯”為英語句子(如圖3)。這種編碼器是可以在最后的隱層將像素轉(zhuǎn)換為活動(dòng)向量的深度卷積網(wǎng)絡(luò)(ConvNet)。解碼器與RNNs用于機(jī)器翻譯和神經(jīng)網(wǎng)絡(luò)語言模型的類似。近來,已經(jīng)掀起了一股深度學(xué)習(xí)的巨大興趣熱潮(參見文獻(xiàn)[86]提到的例子)。
RNNs一旦展開(如圖5),可以將之視為一個(gè)所有層共享同樣權(quán)值的深度前饋神經(jīng)網(wǎng)絡(luò)。雖然它們的目的是學(xué)習(xí)長期的依賴性,但理論的和經(jīng)驗(yàn)的證據(jù)表明很難學(xué)習(xí)并長期保存信息。
為了解決這個(gè)問題,一個(gè)增大網(wǎng)絡(luò)存儲(chǔ)的想法隨之產(chǎn)生。采用了特殊隱式單元的LSTM(long short-termmemory networks)被首先提出,其自然行為便是長期的保存輸入。一種稱作記憶細(xì)胞的特殊單元類似累加器和門控神經(jīng)元:它在下一個(gè)時(shí)間步長將擁有一個(gè)權(quán)值并聯(lián)接到自身,拷貝自身狀態(tài)的真實(shí)值和累積的外部信號(hào),但這種自聯(lián)接是由另一個(gè)單元學(xué)習(xí)并決定何時(shí)清除記憶內(nèi)容的乘法門控制的。
LSTM網(wǎng)絡(luò)隨后被證明比傳統(tǒng)的RNNs更加有效,尤其當(dāng)每一個(gè)時(shí)間步長內(nèi)有若干層時(shí),整個(gè)語音識(shí)別系統(tǒng)能夠完全一致的將聲學(xué)轉(zhuǎn)錄為字符序列。目前LSTM網(wǎng)絡(luò)或者相關(guān)的門控單元同樣用于編碼和解碼網(wǎng)絡(luò),并且在機(jī)器翻譯中表現(xiàn)良好。
過去幾年中,幾位學(xué)者提出了不同的提案用于增強(qiáng)RNNs的記憶模塊。提案中包括神經(jīng)圖靈機(jī),其中通過加入RNNs可讀可寫的“類似磁帶”的存儲(chǔ)來增強(qiáng)網(wǎng)絡(luò),而記憶網(wǎng)絡(luò)中的常規(guī)網(wǎng)絡(luò)通過聯(lián)想記憶來增強(qiáng)。記憶網(wǎng)絡(luò)在標(biāo)準(zhǔn)的問答基準(zhǔn)測(cè)試中表現(xiàn)良好,記憶是用來記住稍后要求回答問題的事例。
除了簡(jiǎn)單的記憶化,神經(jīng)圖靈機(jī)和記憶網(wǎng)絡(luò)正在被用于那些通常需要推理和符號(hào)操作的任務(wù),還可以教神經(jīng)圖靈機(jī)“算法”。除此以外,他們可以從未排序的輸入符號(hào)序列(其中每個(gè)符號(hào)都有與其在列表中對(duì)應(yīng)的表明優(yōu)先級(jí)的真實(shí)值)中,學(xué)習(xí)輸出一個(gè)排序的符號(hào)序列。可以訓(xùn)練記憶網(wǎng)絡(luò)用來追蹤一個(gè)設(shè)定與文字冒險(xiǎn)游戲和故事的世界的狀態(tài),回答一些需要復(fù)雜推理的問題。在一個(gè)測(cè)試?yán)又校W(wǎng)絡(luò)能夠正確回答15句版的《指環(huán)王》中諸如“Frodo現(xiàn)在在哪?”的問題。
深度學(xué)習(xí)的未來展望
無監(jiān)督學(xué)習(xí)對(duì)于重新點(diǎn)燃深度學(xué)習(xí)的熱潮起到了促進(jìn)的作用,但是純粹的有監(jiān)督學(xué)習(xí)的成功蓋過了無監(jiān)督學(xué)習(xí)。在本篇綜述中雖然這不是我們的重點(diǎn),我們還是期望無監(jiān)督學(xué)習(xí)在長期內(nèi)越來越重要。無監(jiān)督學(xué)習(xí)在人類和動(dòng)物的學(xué)習(xí)中占據(jù)主導(dǎo)地位:我們通過觀察能夠發(fā)現(xiàn)世界的內(nèi)在結(jié)構(gòu),而不是被告知每一個(gè)客觀事物的名稱。
人類視覺是一個(gè)智能的、基于特定方式的利用小或大分辨率的視網(wǎng)膜中央窩與周圍環(huán)繞區(qū)域?qū)饩€采集成像的活躍的過程。我們期望未來在機(jī)器視覺方面會(huì)有更多的進(jìn)步,這些進(jìn)步來自那些端對(duì)端的訓(xùn)練系統(tǒng),并結(jié)合ConvNets和RNNs,采用增強(qiáng)學(xué)習(xí)來決定走向。結(jié)合了深度學(xué)習(xí)和增強(qiáng)學(xué)習(xí)的系統(tǒng)正處在初期,但已經(jīng)在分類任務(wù)中超過了被動(dòng)視頻系統(tǒng),并在學(xué)習(xí)操作視頻游戲中產(chǎn)生了令人印象深刻的效果。
在未來幾年,自然語言理解將是深度學(xué)習(xí)做出巨大影響的另一個(gè)領(lǐng)域。我們預(yù)測(cè)那些利用了RNNs的系統(tǒng)將會(huì)更好地理解句子或者整個(gè)文檔,當(dāng)它們選擇性地學(xué)習(xí)了某時(shí)刻部分加入的策略。
最終,在人工智能方面取得的重大進(jìn)步將來自那些結(jié)合了復(fù)雜推理表示學(xué)習(xí)(representation learning )的系統(tǒng)。盡管深度學(xué)習(xí)和簡(jiǎn)單推理已經(jīng)應(yīng)用于語音和手寫字識(shí)別很長一段時(shí)間了,我們?nèi)孕枰ㄟ^操作大量向量的新范式來代替基于規(guī)則的字符表達(dá)式操作。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4762瀏覽量
100535 -
AI
+關(guān)注
關(guān)注
87文章
30106瀏覽量
268399 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120975
原文標(biāo)題:深度學(xué)習(xí)綜述:Hinton、Yann LeCun和Bengio經(jīng)典重讀
文章出處:【微信號(hào):AItists,微信公眾號(hào):人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論