") 手機識別模型案例
手機識別模型案例
導讀
2023年以ChatGPT為代表的大語言模型橫空出世,它的出現(xiàn)標志著自然語言處理領域取得了重大突破。它在文本生成、對話系統(tǒng)和語言理解等方面展現(xiàn)出了強大的能力,為人工智能技術的發(fā)展開辟了新的可能性。同時,人工智能技術正在進入各種應用領域,在智慧城市、智能制造、智慧醫(yī)療、智慧農(nóng)業(yè)等領域發(fā)揮著重要作用。
本期介紹:模型案例:|手機識別模型!
RT-DETR
RT-DETR是基于DETR架構的端到端對象檢測器,完全消除了對NMS的需求。通過這樣做,RT-DETR顯著減少了之前基于卷積神經(jīng)網(wǎng)絡(CNN)的對象檢測器(如YOLO系列)的延遲。它結合了強大的主干、混合編碼器和獨特的查詢選擇器,可以快速準確地處理特征。
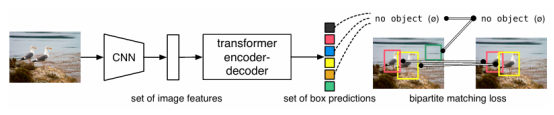
RT-DETR架構的關鍵組件
Backbone網(wǎng)絡:通常采用高效的卷積神經(jīng)網(wǎng)絡(CNN)作為特征提取的基礎,例如ResNet或EfficientNet,以獲取圖像的多尺度特征。從主干,RT-DETR提取三個級別的特征- S3,S4和S5,這些多尺度特征有助于模型理解圖像的高級和細粒度細節(jié)。
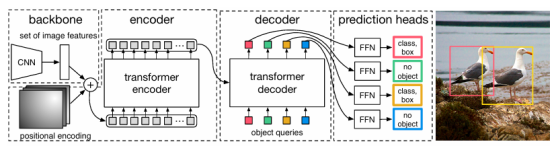
Transformer編碼器-解碼器:RT-DETR中使用了Transformer的編碼器-解碼器結構,該混合編碼器包括兩個主要部分:基于注意力的尺度內(nèi)特征交互(AIFI)和跨尺度特征融合(CCFF)。
基于注意力的尺度內(nèi)特征交互(AIFI)
這個組件的核心思想是利用自注意力機制在同一尺度內(nèi)進行特征交互。AIFI能夠讓模型有效地捕捉同一尺度特征圖中各個位置之間的關系。
具體而言,AIFI通過計算特征的注意力權重,使得模型能夠關注到重要的區(qū)域,并抑制冗余信息,從而增強對目標的定位和表征能力。
這種尺度內(nèi)的交互有助于在相似尺寸的物體之間建立聯(lián)系,提高對密集目標的檢測能力。
跨尺度特征融合(CCFF)
CCFF負責整合來自不同尺度的特征,以便于模型能夠從多層次的信息中獲得更全面的上下文。這一過程通常涉及將來自不同尺度的特征圖進行融合,通過卷積操作、上采樣或下采樣等方式,將這些特征進行對齊并結合在一起。
CCFF不僅允許模型綜合不同尺度特征的優(yōu)勢,還能提高對各種大小目標的檢測能力。
多尺度特征金字塔:RT-DETR通常會借助特征金字塔網(wǎng)絡(FPN)來融合來自不同層次的特征,以加強對不同大小目標的檢測能力。
目標查詢(Object Queries):解碼器使用的目標查詢是關鍵組件,它們用于引導模型對目標的檢測,允許模型在生成檢測結果時關注不同的潛在目標。
類別和邊界框回歸:在解碼器中,RT-DETR通過類別預測和邊界框回歸來輸出目標的類別和位置。
高效的訓練策略:RT-DETR往往結合了一些改進的訓練策略,如動態(tài)圖損失(Dynamic Loss)和圖像增強技術,以提高模型的收斂速度和檢測精度。
后處理:如NMS(非極大值抑制)處理步驟,以去除冗余的檢測框和優(yōu)化最終的檢測結果。
手機識別模型
該 AI 模型由 Swift yolo 算法生成,專為 Seeed Studio Grove Vision AI (V2) 設備設計,能夠高效識別和檢測到手機。
應用場景
該模型適用于多種應用場景,包括零售、安全、公共空間監(jiān)控和個人監(jiān)督。
在零售業(yè),該模型可以實時監(jiān)控手機庫存,幫助員工及時補貨;
在安全方面,它可以幫助識別和跟蹤丟失或被盜的手機;
在個人監(jiān)督,很多學生上課玩手機,可以通過此模型進行監(jiān)控。
SenseCraft Al平臺
SenseCraft Al平臺,是柴火母公司矽遞科技旗下的AI平臺,支持Grove-Vision AI V2、XIAO ESP32S3 Sense和NVIDlA Jetson設備的模型部署、模型訓練和數(shù)據(jù)輸出。
SenseCraft Al平臺為使用者提供海量模型,簡化模型訓練過程并提供專業(yè)的AI視覺工作空間。
在Grove - Vision AI V2模塊上部署模型
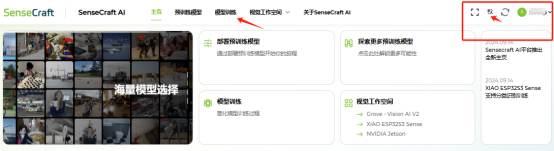
1、打開SenseCraft AI平臺,如果第一次使用請先注冊一個會員賬號,還可以設置語言為中文。
平臺地址:
https://sensecraft.seeed.cc/ai/#/model
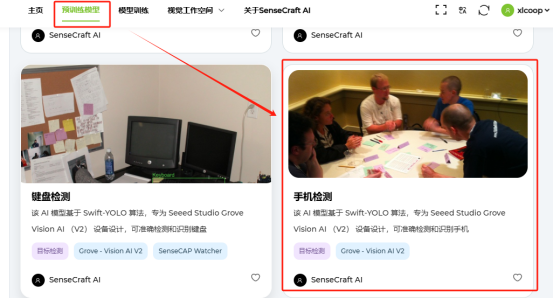
2、在頂部單擊【預訓練模型】菜單,在公共AI模型列表中找到【手機檢測】模型,單擊此模型圖片,如下圖所示。
3、進入【手機檢測】模型介紹頁面,單擊右側的“部署模型”按鈕,如下圖所示。

4、進入部署手機檢測模型頁面,按提示步驟先連接攝像頭,再連接設備到電腦USB接口上,最后單擊【連接設備】按鈕,如下圖所示。

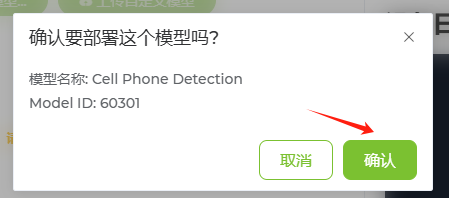
5、彈出部署模型窗口,單擊“確定”按鈕,如下圖所示。
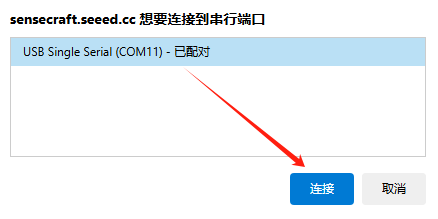
6、彈出連接到串行端口窗口,選擇端口號后單擊“連接”按鈕,如下圖所示。
7、開始進行模型部署、固件下載、設備重啟等過程,完成后在預覽中即可看到當前攝像頭視頻內(nèi)容,將攝像頭對準手機圖片查看預測效果,如下圖所示。

原型設計
利用此手機識別模型,設計一個桌面手機監(jiān)控裝置,此裝置在檢測到有人用手機時會點亮led模塊,也可改為蜂鳴器模塊進行報警,這樣就有了一個防沉迷手機檢測裝置。

模型推理演示,請看如下視頻
Grove Al視覺模塊 V2套裝介紹

Grove Al視覺模塊 V2

OV5647-62攝像頭
Grove - Vision Al Module V2是一款拇指大小的人工智能視覺模塊, 配備Himax WiseEye2 HX6538處理器和Arm Ethos-U55嵌入式神經(jīng)網(wǎng)絡加速單元(NPU), 該處理器采用 ArmCortex-M55雙核架構。
Arm Ethos-U55 嵌入式神經(jīng)網(wǎng)絡處理器(NPU)
嵌入式神經(jīng)網(wǎng)絡處理器(NPU)是一種特別設計用于執(zhí)行神經(jīng)網(wǎng)絡計算的高效率處理器。它主要基于數(shù)據(jù)驅動并行計算架構,特別擅長處理視頻、圖像等大量的多媒體數(shù)據(jù)。NPU模仿了生物神經(jīng)網(wǎng)絡的架構,與CPU、GPU相比,它能夠通過更少的指令(一條或幾條)完成神經(jīng)元的處理,因此在深度學習的處理效率方面具有明顯優(yōu)勢。
它具有標準的CSI接口, 并與樹莓派相機兼容。它有一個內(nèi)置的數(shù)字麥克風和SD卡插槽。它非常適用于各種嵌入式視覺項目。
有了SenseCraft Al算法平臺, 經(jīng)過訓練的ML模型可以部署到傳感器, 而不需要編碼。它兼容XIAO系列和Arduino生態(tài)系統(tǒng), 是各種物體檢測應用的理想選擇。
主要硬件配置
- 板卡基于WiseEye2 HX6538處理器, 采用雙核ARM Cortex-M55架構
- 配備集成Arm Ethos-U55嵌入式神經(jīng)網(wǎng)絡處理器(NPU), 兼容的樹莓派相機
- 板載PDM麥克風, SD卡插槽, Type-C, Grove接口, 豐富的外設支持樣機開發(fā)
- Seeed Studio XIAO的可擴展性, SenseCraft Al的現(xiàn)成AI模型用于無代碼部署。
- 支持各種有效的模型, 包括MobilenetV1、MobilenetV2、 Eficientnet-Lite、Yolov5和Yolov8.
寫在最后
SenseCraft-AI平臺的模型倉數(shù)量還很少,但是好消息是它支持自定義模型上傳并輸出推理結果,平臺會逐漸增加模型倉的數(shù)量和分享有愛好者設計的模型倉原型,敬請關注!
-
手機
+關注
關注
35文章
6850瀏覽量
157407 -
模型
+關注
關注
1文章
3171瀏覽量
48711
原文標題:模型案例:| 手機識別模型!
文章出處:【微信號:ChaiHuoMakerSpace,微信公眾號:柴火創(chuàng)客空間】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
AI大模型在圖像識別中的優(yōu)勢
手機識別不了GATT_SERVER例程中的屬性怎么辦?
人臉識別模型訓練流程
人臉識別模型訓練失敗原因有哪些
人臉識別模型訓練是什么意思
Transformer模型在語音識別和語音生成中的應用優(yōu)勢
開發(fā)者手機 AI - 目標識別 demo
蘋果ReALM模型在實體識別測試中超越OpenAI GPT-4.0
谷歌模型怎么用手機打開
谷歌模型怎么用手機打開網(wǎng)頁
谷歌模型怎么用手機打開文件

2024國內(nèi)各手機品牌大語言模型進展

重塑翻譯與識別技術:開源語音識別模型Whisper的編譯優(yōu)化與部署






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論