 SQL與大數據處理的關系 如何使用SQL進行ETL過程
SQL與大數據處理的關系 如何使用SQL進行ETL過程
SQL與大數據處理的關系
SQL(Structured Query Language,結構化查詢語言)在大數據處理中扮演著至關重要的角色。隨著大數據技術的快速發展,SQL作為一種標準的數據庫查詢語言,依舊在數據處理中占據著不可或缺的地位。無論是傳統的關系型數據庫還是如今流行的分布式大數據處理框架(如Hive、Presto等),SQL的運用都十分廣泛。
在大數據場景下,SQL能夠通過分布式計算和并行處理來加快數據處理速度和提高效率。大數據平臺通常會支持SQL-on-Hadoop等技術,讓用戶能夠使用SQL語言來查詢和分析存儲在Hadoop集群中的數據,這種方式降低了學習成本,使得更多用戶能夠通過熟悉的SQL語言來操作大數據。
如何使用SQL進行ETL過程
ETL(Extract, Transform, Load,即提取、轉換、加載)是數據處理中的重要環節,而SQL在ETL過程中發揮著關鍵作用。以下是如何使用SQL進行ETL過程的詳細步驟:
1. 數據提取(Extract)
- 確定數據源 :首先,需要確定要提取數據的數據源,這可以是一個或多個數據庫表。
- 編寫查詢語句 :使用SQL的
SELECT語句從數據源中提取數據。可以根據需要添加WHERE子句來過濾數據,只提取滿足特定條件的記錄。 - 使用連接 :如果數據分散在多個表中,可以使用SQL的
JOIN操作來合并這些表的數據。
2. 數據轉換(Transform)
- 數據清洗 :在數據轉換階段,首先需要進行數據清洗。這包括處理缺失值(如使用
COALESCE函數填充缺失值)、去除重復數據(如使用DISTINCT關鍵字或窗口函數ROW_NUMBER())以及數據格式轉換(如使用CAST或CONVERT函數)。 - 數據計算 :根據業務需求,可能需要計算新的字段或指標。這可以通過SQL的算術運算、字符串函數或日期函數來實現。
- 數據聚合 :使用SQL的
GROUP BY子句和聚合函數(如SUM、COUNT、AVG等)來對數據進行匯總和分組。
3. 數據加載(Load)
- 選擇目標表 :確定要將轉換后的數據加載到哪個目標表中。
- 編寫插入語句 :使用SQL的
INSERT INTO語句將轉換后的數據插入到目標表中。如果目標表已經存在數據,并且需要追加新數據,可以使用INSERT INTO ... SELECT語句來從源表中選擇數據并插入到目標表中。 - 驗證數據 :在數據加載完成后,需要對加載的數據進行驗證,以確保數據的準確性和完整性。這可以通過編寫查詢語句來檢查目標表中的數據是否滿足預期。
注意事項
- 性能優化 :在處理大數據時,SQL查詢的性能可能成為一個問題。因此,需要采取一些優化措施來提高查詢性能,如使用索引、優化查詢語句等。
- 數據安全性 :在ETL過程中,需要確保數據的安全性。這包括保護數據源和目標表的訪問權限、防止數據泄露等。
- 數據一致性 :在ETL過程中,需要確保數據的一致性。這包括在數據提取、轉換和加載過程中保持數據的完整性、準確性和一致性。
綜上所述,SQL在大數據處理和ETL過程中發揮著重要作用。通過掌握SQL語法和高級特性,可以更加高效地進行數據的查詢、分析和處理。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
存儲
+關注
關注
13文章
4261瀏覽量
85666 -
SQL
+關注
關注
1文章
759瀏覽量
44069 -
函數
+關注
關注
3文章
4304瀏覽量
62427 -
數據處理
+關注
關注
0文章
581瀏覽量
28527
發布評論請先 登錄
相關推薦
常用SQL函數及其用法
SQL(Structured Query Language)是一種用于管理和操作關系數據庫的編程語言。SQL 提供了豐富的函數庫,用于數據檢索、數據
大數據從業者必知必會的Hive SQL調優技巧
大數據從業者必知必會的Hive SQL調優技巧 摘要 :在大數據領域中,Hive SQL被廣泛應用于數據倉庫的
什么是 Flink SQL 解決不了的問題?
簡介 在實時數據開發過程中,大家經常會用 Flink SQL 或者 Flink DataStream API 來做數據加工。通常情況下選用2者都能加工出想要的
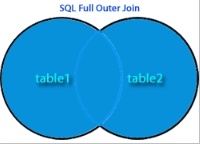
SQL全外連接剖析
SQL中的全外連接是什么? 在SQL中,FULLOUTERJOIN組合左外連接和右外連接的結果,并返回連接子句兩側表中的所有(匹配或不匹配)行。接下面sojson給大家詳細講解。 ? 圖解:SQL全
為什么需要監控SQL服務器?
服務器是存儲、處理和管理數據的關系數據庫管理系統 (RDBMS) 工具或軟件,例如Microsoft的MSSQL、Oracle DB和PostgreSQL。此外,服務器執行SQL查詢和
如何用Rust過程宏魔法簡化SQL函數呢?
這是 RisingWave 中一個 SQL 函數的實現。只需短短幾行代碼,通過在 Rust 函數上加一行過程宏,我們就把它包裝成了一個 SQL 函數。
SQL核心知識點總結
SQL:Structure Query Language。(結構化查詢語言),通過sql操作數據庫(操作數據庫,操作表,操作數據)
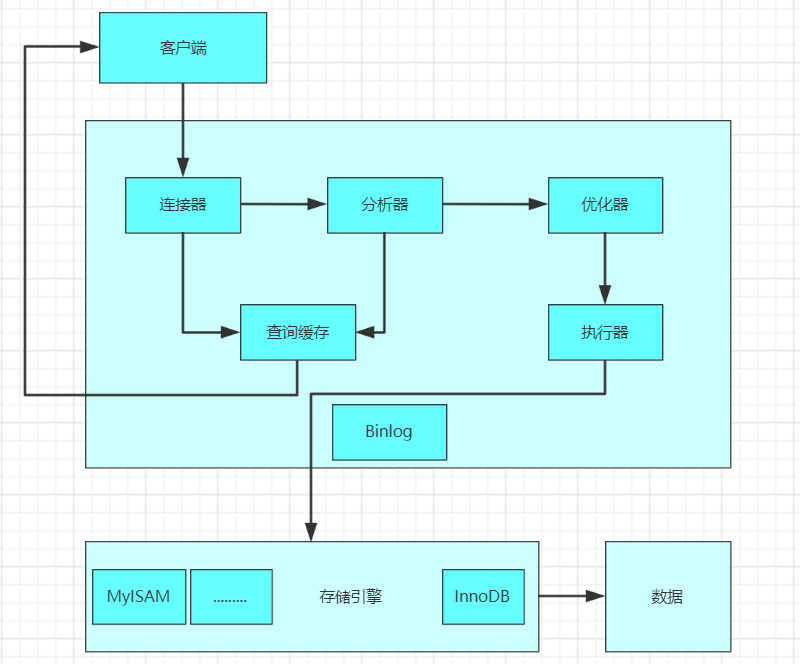
MySQL執行過程:如何進行sql 優化
(1)客戶端發送一條查詢語句到服務器; (2)服務器先查詢緩存,如果命中緩存,則立即返回存儲在緩存中的數據; (3)未命中緩存后,MySQL 通過關鍵字將 SQL 語句進行解析,并生成一顆對應的解析樹,MySQL 解析器將使用
Oracle如何執行sql腳本文件
Oracle是一種關系型數據庫管理系統,可用于存儲、查詢和管理大量的數據。在Oracle中,可以通過執行SQL腳本文件來一次性地執行多個SQL
oracle執行sql查詢語句的步驟是什么
Oracle數據庫是一種常用的關系型數據庫管理系統,具有強大的SQL查詢功能。Oracle執行SQL查詢語句的步驟包括編寫
oracle sql 定義變量并賦值
在Oracle SQL中,變量是用來存儲數據值的標識符。通過定義和使用變量,我們可以在SQL語句中使用它們來存儲和處理數據,從而實現更靈活和
oracle用的是sql語句嗎
是的,Oracle使用的是SQL語言。SQL(Structured Query Language)是一種用于管理和操作關系型數據庫的標準編程語言,被廣泛應用于企業級





 工商網監
工商網監
評論