 使用ReMEmbR實現機器人推理與行動能力
使用ReMEmbR實現機器人推理與行動能力
視覺語言模型(VLM)通過將文本和圖像投射到同一個嵌入空間,將基礎大語言模型(LLM)強大的語言理解能力與視覺 transformer(ViT)的視覺能力相結合。VLM 可以處理非結構化的多模態數據、對其進行推理并以結構化的格式返回輸出結果。由于經過大量預訓練,只需要為這些模型提供新的提示或進行參數高效微調,它們就能輕松適應不同的視覺相關的任務。
這些模型還可以與實時數據源和工具集成,從而在不知道答案時請求獲得更多信息或在知道答案時采取行動。LLM 和 VLM 可以作為智能體對數據進行推理,幫助機器人執行可能難以定義的有意義的任務。
在此前一篇的文章利用 NVIDIA Jetson 實現生成式 AI中,我們展示了可以在NVIDIA Jetson Orin設備上運行 LLM 和 VLM,從而在邊緣設備上實現零樣本物體檢測、視頻字幕、文本生成等多種新功能。
但如何將這些先進技術應用于機器人的感知和自主運行?將這些模型部署到現場時又會面臨哪些挑戰?
本文將討論 ReMEmbR。該項目結合了 LLM、VLM 和檢索增強生成(RAG),使機器人能夠在數小時至數天的長時程部署期間,對所看到的事物進行推理并采取行動。
ReMEmbR 在記憶構建階段使用 VLM 和矢量數據庫來高效構建長時程語義記憶,之后在查詢階段使用 LLM 智能體對該記憶進行推理。它完全開源,并且可在設備端運行。
ReMEmbR 解決了在機器人應用中使用 LLM 和 VLM 時所面臨的諸多挑戰:
如何處理大型上下文。
如何對空間記憶進行推理。
如何構建一個基于提示的智能體來查詢更多數據,直到用戶的問題得到解答。
我們還進一步構建了一個在真實機器人上使用 ReMEmbR 的示例。我們在這項工作中使用了 Nova Carter 和NVIDIA Isaac ROS,并分享了我們所使用的代碼和步驟。如需了解更多信息,請參見以下資源:
適用于長時程時空記憶、
推理與行動的 ReMEmbR
人們越來越期待機器人能夠長時間感知環境并與之互動。機器人每次部署的時間長達數小時乃至數天,它們會偶然感知到不同的物體、事件和位置。
為了讓機器人在長時間部署的場景中能夠理解和回答那些需要復雜多步驟推理的問題,我們開發了 ReMEmbR 這一用于具身機器人的檢索增強記憶。
ReMEmbR 為機器人構建了可擴展的長時程記憶和推理系統,提高了機器人的感知問題回答和語義行動能力。ReMEmbR 包含記憶構建和查詢兩個階段。
在記憶構建階段,我們借助 VLM,使用矢量數據庫構建了結構化記憶。在查詢階段,我們建立了一個 LLM 智能體,它可以循環調用不同的檢索函數,最終回答用戶提出的問題。
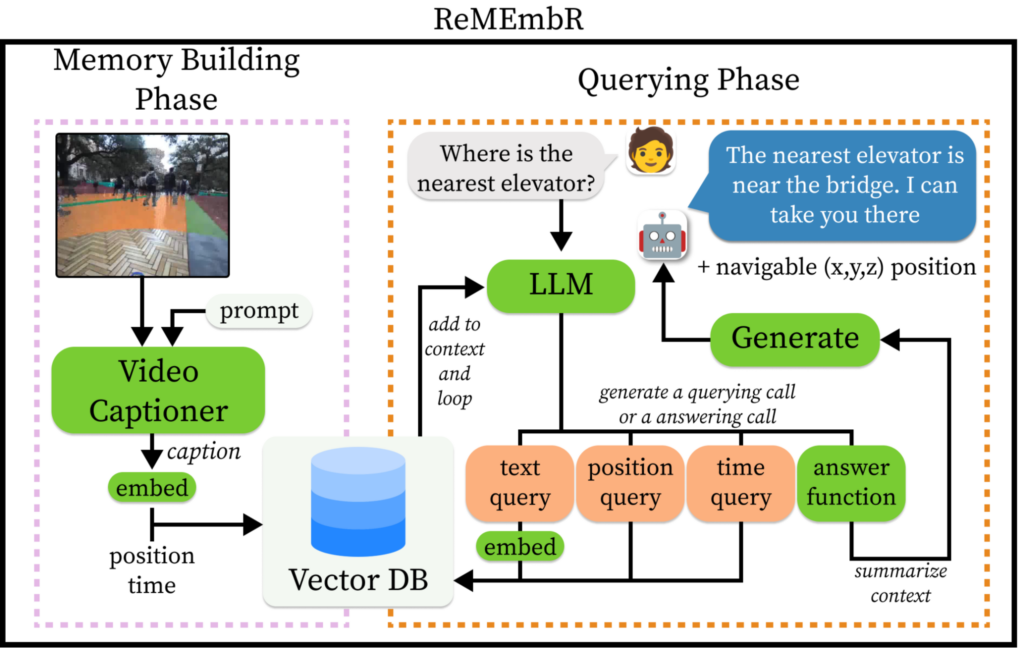
圖 1. 完整的 ReMEmbR 系統
構建更加智能的記憶
ReMEmbR 的記憶構建階段就是讓機器人的記憶工作。當機器人已被部署了數小時或數天時,就需要一種高效的方式存儲這些信息。視頻雖然易于存儲,但卻難以查詢和理解。
在記憶構建過程中,我們會截取視頻的短片段,使用NVIDIA VILA字幕生成 VLM 為其添加字幕,然后將它們嵌入到 MilvusDB 矢量數據庫。我們還在該矢量數據庫中存儲時間戳和坐標信息。
該設置使我們能夠高效地存儲和查詢機器人記憶中的各種信息。通過使用 VILA 捕捉視頻片段,并將其嵌入到 MilvusDB 矢量數據庫,該系統可以記住 VILA 能夠捕捉到的任何內容,包括從四處走動的人等動態事件和特定的小物體,到更加普遍的內容類別。
使用矢量數據庫可以輕松添加供 ReMEmbR 考慮的新信息。
ReMEmbR 智能體
鑒于數據庫中存儲的記憶如此之長,標準 LLM 很難對長上下文進行快速推理。
ReMEmbR 智能體的 LLM 后端可以是NVIDIA NIM微服務、本地設備上的 LLM 或其他 LLM API。當用戶提出問題時,LLM 生成對數據庫的查詢并反復檢索相關信息。LLM 可以根據用戶提出的問題來查詢文本信息、時間信息或位置信息。這個過程不斷重復,直到問題得到解答。
我們為 LLM 智能體使用了這些不同的工具,使機器人不僅能夠回答如何前往特定地點的問題,還能夠進行空間和時間推理。圖 2 展示了這一推理階段的情況。

圖 2. ReMEmbR 查詢和推理流程示例
在真實機器人上部署 ReMEmbR
為了演示如何將 ReMEmbR 集成到真實機器人中,我們使用 ReMEmbR 與NVIDIA Isaac ROS和 Nova Carter 構建了一個演示。Isaac ROS 是一個基于開源 ROS 2 軟件框架構建而成的加速計算軟件包和 AI 模型集,它將 NVIDIA 加速技術帶給了全球各地的 ROS 開發者。
在演示中,機器人回答問題并引導人們參觀辦公室環境。為了讓大家了解如何構建該應用,以下是我們所采取的步驟:
構建占用柵格地圖
運行記憶構建器
運行 ReMEmbR 智能體
添加語音識別
構建占用柵格地圖
第一步是創建環境地圖。為了建立矢量數據庫,ReMEmbR 需要訪問單目攝像頭圖像和全局位置(姿勢)信息。
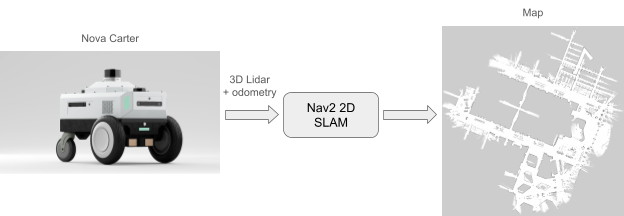
圖 3. 使用 Nova Carter 繪制占用柵格地圖
根據環境或平臺的不同,獲取全局姿勢信息可能會具有一定的難度。幸運的是,在使用 Nova Carter 時,這項工作就會變得簡單。由 Nova Orin 參考架構驅動的 Nova Carter 是一個完整的機器人開發平臺,能夠加速下一代自主移動機器人(AMR)的開發和部署。該平臺在配備 3D 激光雷達后,可以生成精準且全局一致的度量地圖。
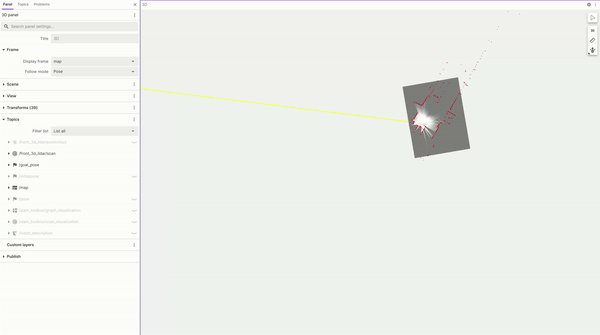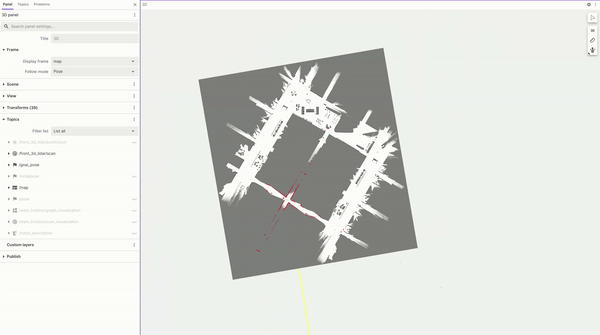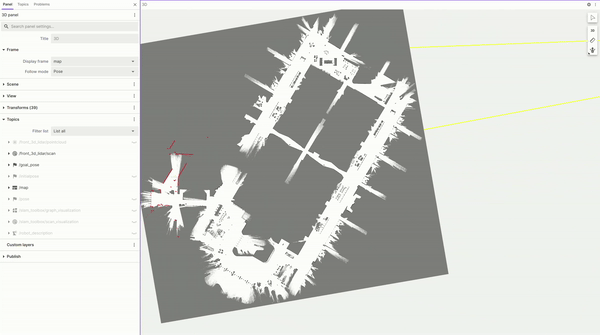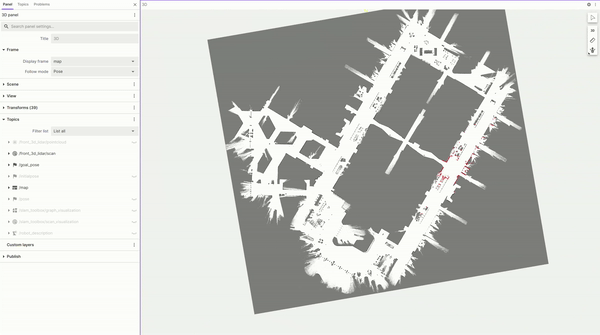
圖 4. 使用 Nova Carter 構建的
占用柵格地圖的 FoxGlove 可視化圖
按照 Isaac ROS 文檔,我們通過遙控機器人,快速繪制出占用柵格地圖。該地圖之后在建立 ReMEmbR 數據庫時被用于定位,并在最終部署機器人時被用于路徑規劃和導航。
運行記憶構建器
在創建環境地圖后,第二步是填充 ReMEmbR 使用的矢量數據庫。為此,我們在遙控機器人的同時,運行 AMCL 進行全局定位。有關如何使用 Nova Carter 實現這一操作的更多信息,請參見教程:使用 Isaac Perceptor 和 Nav2 進行自主導航:
https://nvidia-isaac-ros.github.io/reference_workflows/isaac_perceptor/tutorials_on_carter/demo_navigation.html
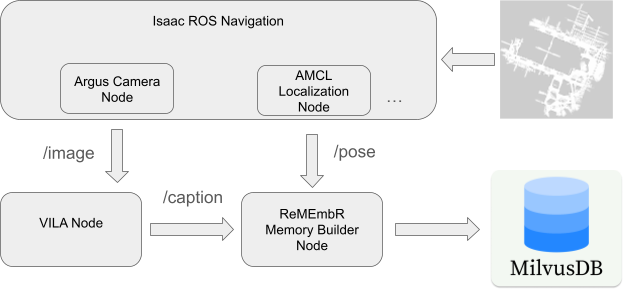
圖 5. 運行 ReMEmBr 記憶構建器
在后臺運行定位后,我們又啟動了兩個專門用于記憶構建階段的 ROS 節點。
第 1 個 ROS 節點運行 VILA 模型,為機器人攝像頭圖像生成字幕。該節點在設備上運行,因此即便網絡時斷時續,我們也能建立一個可靠的數據庫。
由于使用了 NanoLLM 進行量化和推理,在 Jetson 上運行該節點變得更加容易。Jetson AI Lab中就有這個庫和許多其他庫。最近甚至還發布了一個 ROS 軟件包(ros2_nanollm),用于將 NanoLLM 模型與 ROS 應用輕松集成。
第二個 ROS 節點獲取 VILA 生成的標題以及 AMCL 節點估計的全局姿態。它為字幕建立文本嵌入,并將姿勢、文本、嵌入和時間戳存儲到矢量數據庫中。
運行 ReMEmbR 智能體
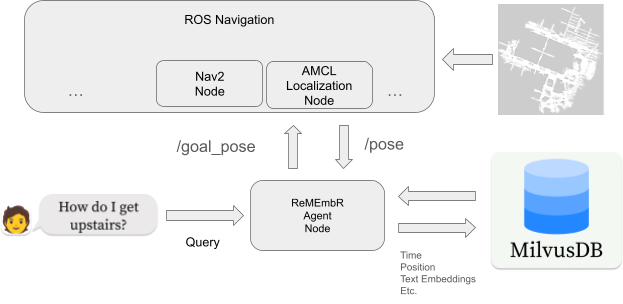
圖 6. 運行 ReMEmbR 智能體
以回答用戶查詢并導航至目標姿勢
在填充了矢量數據庫后,就滿足了 ReMEmbR 智能體回答用戶查詢和生成有意義動作所需的一切條件。
第三步是運行現場演示。為了使機器人的記憶保持靜態,我們禁用了圖像字幕生成和記憶構建節點,并啟用了 ReMEmbR 智能體節點。如前所述,ReMEmbR 智能體負責接收用戶查詢、查詢矢量數據庫,并確定機器人應采取的適當行動。在本例中,該行動是與用戶查詢相對應的目的地目標姿勢。
然后,我們通過手動輸入用戶查詢,對系統進行了端到端測試:
“帶我去最近的電梯”
“帶我去一個可以吃零食的地方”
ReMEmbR 智能體確定最佳目標姿勢并將其發布到/goal_pose主題中。然后,路徑規劃器會生成一條全局路徑,將機器人導航至該目標。
添加語音識別
在實際應用中,用戶很可能無法使用終端來輸入查詢,因此需要一種直觀的方式與機器人進行交互。為此,我們進一步開發了該應用,集成了語音識別功能來為該智能體生成查詢。
在 Jetson Orin 平臺上集成語音識別功能十分簡單。為此,我們編寫了一個 ROS 節點,該節點封裝了最近發布的 WhisperTRT 項目。WhisperTRT 利用NVIDIA TensorRT優化了 OpenAI 的 whisper 模型,從而在Jetson AGX Orin和NVIDIA Jetson Orin Nano上實現了低延遲推理。
WhisperTRT ROS 節點使用 PyAudio 直接訪問麥克風,并在語音主題上發布識別出的語音。

圖 7. 通過將語音識別與 WhisperTRT 集成,實現自然的用戶交互全部整合
-
機器人
+關注
關注
210文章
28191瀏覽量
206505 -
NVIDIA
+關注
關注
14文章
4935瀏覽量
102806 -
LLM
+關注
關注
0文章
272瀏覽量
305 -
生成式AI
+關注
關注
0文章
487瀏覽量
459
原文標題:借助 ReMEmbR 利用生成式 AI 賦予機器人推理與行動能力
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論