 RAPIDS cuDF將pandas提速近150倍
RAPIDS cuDF將pandas提速近150倍
在 NVIDIA GTC 2024 上,NVIDIA 宣布,RAPIDS cuDF 當前已能夠為 950 萬 pandas 用戶帶來 GPU 加速,且無需修改代碼。
目前,NVIDIA 再次對這一應用進行了更新:現在無需在 Google Colab 中修改代碼,即可直接使用 RAPIDS cuDF 為 pandas 提供加速。現在即可嘗試在 Colab notebook 中使用這一教程。
pandas 是一個靈活且強大的 Python 數據分析和處理程序庫,因其是易于使用的 API,已成為數據科學家的首選。但隨著數據集規模的擴大,其在僅使用 CPU 的系統中的處理速度和效率方面遇到了挑戰。
RAPIDS 是一套開源的 GPU 加速 Python 程序庫,旨在改進數據科學和分析工作流。RAPIDS cuDF 是一個 GPU DataFrame 程序庫,其提供了一個類似 pandas 的 API,用于加載、過濾和操作數據。cuDF 的早期版本只適用于 GPU 開發工作流程。
去年秋季,RAPIDS 發布了 cuDF 版本。該版本通過開放測試版中統一的 CPU/GPU 用戶體驗,在不修改代碼的情況下將加速計算引入到 pandas 工作流中。在 GTC 2024 上,NVIDIA 宣布在新發布的 RAPIDS v24.02 中正式推出 cuDF 加速 pandas 功能。NVIDIA AI Enterprise 5.0 將在晚些時候支持這一功能。
兩個相同的 pandas 工作流在 Jupyter notebook 中并列運行。其中一個使用了僅搭載 CPU 的 pandas,另一個則加載了 cudf.pandas 擴展,以便可以使用 RAPIDS cuDF 加速 pandas。
將統一的 CPU/GPU 體驗
引入 pandas 工作流
cuDF 一直使用類似于 pandas 的 API 為用戶提供卓越的 DataFrame 程序庫性能。但使用 cuDF 有時需要采取變通方法:
對 cuDF 中尚未實現或支持的任何 pandas 功能采取變通方法。
在必須在異構硬件上運行的代碼庫中,為執行 CPU 和 GPU 設計單獨的代碼路徑。
在與其他 PyData 程序庫或專為 pandas 設計的、特定于組織的工具進行交互時,需要手動切換 cuDF 和 pandas。
在 24.02 版本中,除了提供現有的僅 GPU 使用體驗外,cuDF 還能在無需更改代碼的情況下加速 pandas,以應對這些挑戰。
該功能專為數據科學家而設計,旨在即使數據規模增長到千兆字節、性能降低時仍然可以繼續使用 pandas。當 cuDF 加速 pandas 時,在可能的情況下操作將在 GPU 上運行,否則將在(使用 pandas 的)CPU 上運行。這實現了統一的 CPU/GPU 體驗,為用戶自己的 pandas 工作流帶來了領先的性能。
隨著 GA 版本的發布,cuDF 可提供以下功能:
無需更改代碼的加速:只需加載 cuDF Jupyter Notebook 擴展或使用cuDF Python 模塊選項。
兼容第三方程序庫:pandas 加速器模式與大多數在 pandas 對象上運行的第三方程序庫兼容,甚至可以加速這些庫中的 pandas 操作。
統一的 CPU/GPU 工作流:使用單一代碼路徑進行開發、測試和生產運行,不受硬件限制。
如要將 GPU 加速功能引入 Jupyter notebook 中的 pandas 工作流,請加載 cudf.pandas 擴展:
%load_ext cudf.pandas import pandas as pd
如要在運行 Python 腳本時訪問,請使用 cudf.pandas 模塊選項:
python -m cudf.pandas script.py
為 pandas 工作流帶來頂尖的性能
當數據規模達到千兆字節時,pandas 往往會因為性能較慢而變得在使用過程中面臨較多挑戰,導致一些數據科學家不得不放棄他們喜愛的 pandas API。有了新的 RAPIDS cuDF,就可以繼續將 pandas 作為主要工具使用并獲得頂尖的性能。
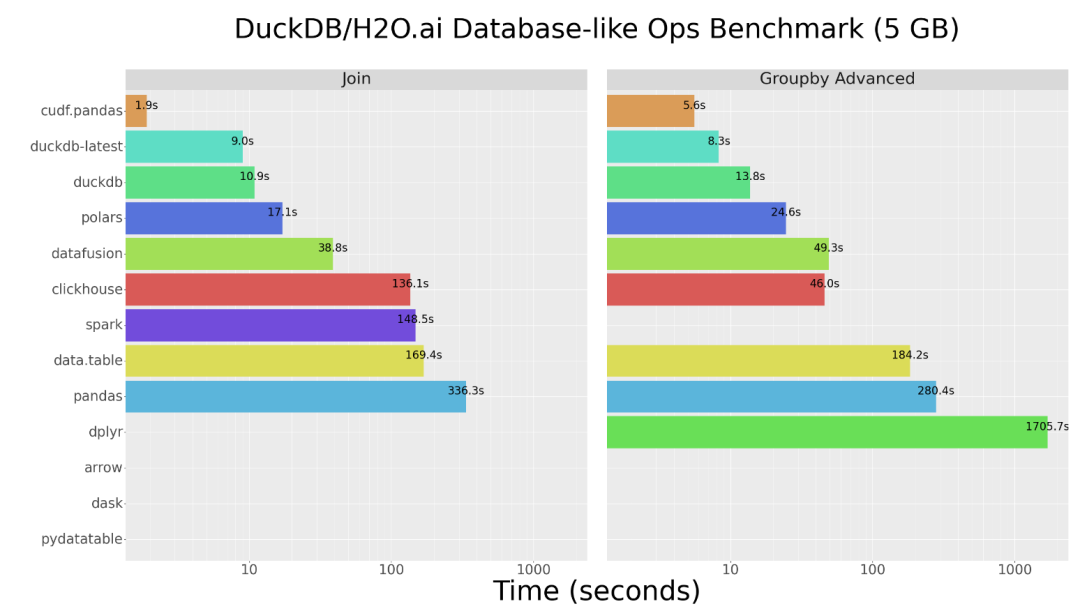
用戶可以通過運行流行的 DuckDB Database-like Ops Benchmark 中的 pandas 部分來了解這一點,該基準測試最初由 H2o.ai 開發。DuckDB 的基準測試方式是將一系列常見分析任務,例如將數據連接在一起或計算每組的統計量作為基準,來比較基于 CPU 的流行 DataFrame 和 SQL 引擎的性能。
在數據量為 5 GB 的情況下,pandas 的性能大幅下降,變得非常慢,僅僅執行一系列連接和高級分組操作就需要數分鐘時間。
以往使用 cuDF 代替 pandas 運行此基準測試時,需要更改代碼并解決功能缺失的問題。現在,借助 cuDF 的全新 pandas 加速模式,這個問題迎刃而解。用戶可以在不改變pandas基準代碼的情況下運行該基準測試,而且速度將大幅提升。其中的大部分操作由 GPU 執行,小部分操作由 CPU 執行,保證了工作流的順利操作。
這樣操作所取得的結果非常出色。cuDF 的統一 CPU/GPU 體驗無需更改代碼,即可將處理時間從原本幾分鐘縮短至 1 到 2 秒(圖 1)。

圖 1.cuDF.pandas 與傳統 pandas v2.2 在標準 DuckDB 數據基準測試(5 GB)中的性能比較
硬件:NVIDIA Grace Hopper;CPU:英特爾 Xeon Platinum 8480C|軟件:pandas v2.2、RAPIDS cuDF 23.10
結語
pandas 是 Python 生態系統中最流行的 DataFrame 程序庫,但它的速度會隨著 CPU 上數據量的增加而變慢。
現在只需一條命令,用戶就可以在無需更改代碼的情況下,使用 cuDF 將加速計算引入到其 pandas 工作流中。根據數據集大小為 5 GB 的分析基準測試結果,處理時間縮短到原來的 150 分之一。
您可參考詳細的教程在 Google Colab 上的免費 GPU 環境中試用 cuDF 的 pandas 加速功能。
-
cpu
+關注
關注
68文章
10829瀏覽量
211182 -
NVIDIA
+關注
關注
14文章
4949瀏覽量
102825 -
代碼
+關注
關注
30文章
4753瀏覽量
68368
原文標題:無需更改代碼,RAPIDS cuDF 將 pandas 提速近 150 倍
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Python利用pandas讀寫Excel文件

pandas是什么?
pandas是什么
pandas使用步驟
pandas是什么?
pandas是什么?
pandas怎么使用
如何使用RAPIDS和CuPy時加速Gauss 秩變換

NVIDIA深度學習加速數據科學教材套滿足教學需求
如何加速apply函數600倍的技巧
如何用基于NVIDIA GPU的RAPIDS cuML實現取代KRR?
超強圖解Pandas,建議收藏

將NVIDIA加速計算引入Polars






 工商網監
工商網監
評論