 浪潮信息發布“源”Yuan-EB助力RAG檢索精度新高
浪潮信息發布“源”Yuan-EB助力RAG檢索精度新高
近日,浪潮信息發布 “源”Yuan-EB(Yuan-embedding-1.0,嵌入模型),在C-MTEB榜單中斬獲檢索任務第一名,以78.41的平均精度刷新大模型RAG檢索最高成績,將基于元腦企智EPAI為構建企業知識庫提供更高效、精準的知識向量化能力支撐,助力用戶使用領先的RAG技術加速企業知識資產的價值釋放。
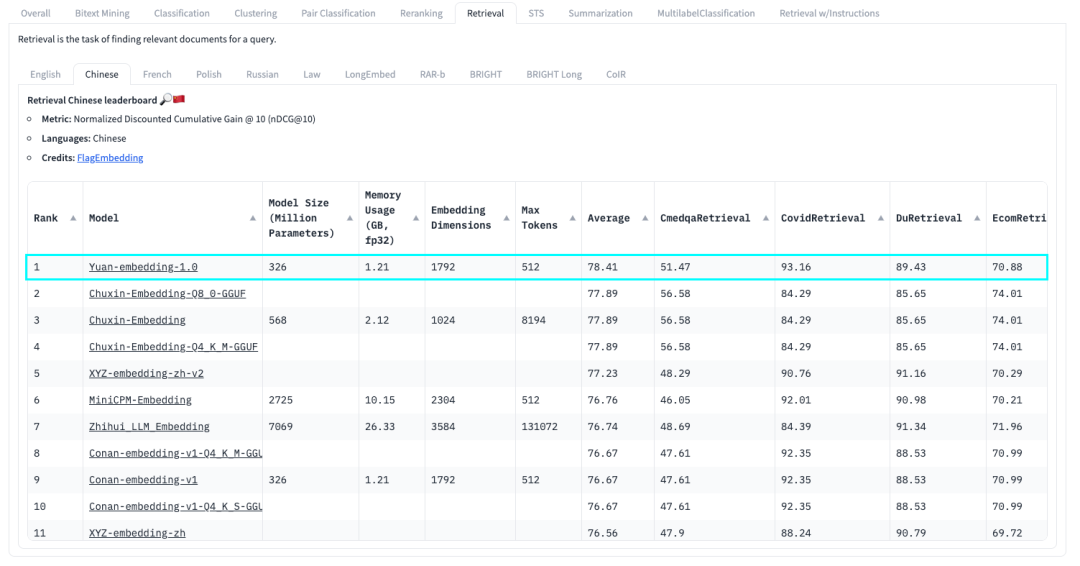
“源”Yuan-EB 在HuggingFace的C-MTEB榜單中排名第一
Yuan-EB(版本號Yuan-embedding-1.0) 是專為增強中文文本檢索能力而設計的嵌入模型(也稱Embedding模型),在 “源2.0” 大模型的工作基礎上,創新性地采用了“源2.0-M32”大模型進行數據重寫與合成,并通過索引技術、樣本排序等系列方法完成高質量微調數據集構建,能夠有效提升RAG系統的檢索精度。
C-MTEB是目前業內最權威的嵌入模型測試榜單。其中,檢索任務(Retrieval)是檢索增強生成(RAG)場景下最為重要、應用最廣泛的任務能力,考察的是Embedding模型從大量的數據集中找到并返回與給定查詢最相關或最匹配的信息的過程。“源”Yuan-EB基于該任務提供的醫療、新聞、電商、娛樂等8個中文文本數據集,實現了業界領先的海量文本檢索精度。
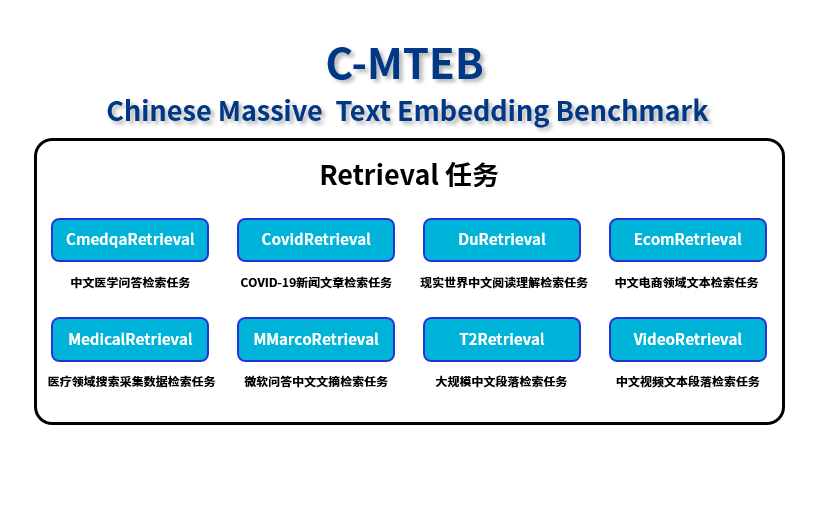
C-MTEB榜單Retrieval任務提供8個測試數據集
“源” Yuan-EB 助力RAG檢索精度新高
嵌入模型在RAG流程中扮演著關鍵角色,它能夠將復雜的高維數據(例如文本、圖像或音頻)轉換為機器可理解的向量形式,直接決定了RAG檢索的精準性和效率。
“源”Yuan-EB通過數據準備與模型微調兩個方面的技術創新,實現了模型精度的大幅提升:
■ 在數據方面,基于“源2.0”微調階段的問答數據進行清洗與篩選,構建問題(query)與文本(corpus)數據集;使用“源2.0-M32”對C-MTEB 訓練數據進行重寫與合成,通過索引技術與排序模型進行高效的難負樣本提取,完成大規模難負例樣本挖掘,形成高質量微調數據集;
■ 在微調方面,通過兩個階段的領先微調方法實現模型能力提升。第一階段,使用各個領域(醫療、新聞、長文本、娛樂等方向)的大規模數據進行對比學習訓練;第二階段,采用“源2.0-M32”生成的合成數據進一步微調,并使用MRL方法完成“源”Yuan-EB訓練;
“源”Yuan-EB為用戶提供了大模型企業知識庫應用開發的最優模型選擇,能夠在 RAG流程的多個方面起到顯著的精度提升,包括信息檢索的準確性、處理大規模數據的效率、消除語義歧義、降低計算成本、增強對長文檔的處理能力以及模型魯棒性等,最大化提升RAG流程的整體性能和應用效果。
元腦企智EPAI集成“源”Yuan-EB,加速知識庫構建與性能提升
目前,“源”Yuan-EB已經在開源社區和企業大模型開發平臺元腦企智EPAI中全面開放下載。用戶可以在元腦企智EPAI平臺中快速使用“源”Yuan-EB,并結合EPAI自研的多階段RAG技術,零代碼、低成本地基于企業數據構建大模型知識庫應用。
企業大模型開發平臺“元腦企智”EPAI(Enterprise Platform of AI),是浪潮信息為企業AI大模型落地應用打造的高效、易用、安全的端到端開發平臺,提供數據準備、模型訓練、知識檢索、應用框架等系列工具,支持調度多元算力和多模算法,幫助企業高效開發部署生成式AI應用、打造智能生產力。
元腦企智EPAI已經支持超過13種類型文檔的信息識別與提取,結合創新的多級混合檢索策略,有效提升元腦企智EPAI在管理、解析、檢索知識庫與生成內容方面的最終效果,幫助企業用戶實現基于私有數據、行業數據下的精準檢索、精準問答,確保專業場景下大模型生成內容的準確性和可靠性,加速大模型創新力釋放。
-
浪潮
+關注
關注
1文章
454瀏覽量
23820 -
開源
+關注
關注
3文章
3254瀏覽量
42408 -
大模型
+關注
關注
2文章
2333瀏覽量
2489
原文標題:浪潮信息發布“源”Yuan-EB,刷新大模型RAG檢索精度紀錄!
文章出處:【微信號:浪潮AIHPC,微信公眾號:浪潮AIHPC】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
浪潮信息源2.0大模型與百度PaddleNLP全面適配
浪潮信息:元腦企智EPAI助力金融大模型快速落地

浪潮信息推出AIGC存儲解決方案
浪潮信息重磅發布“源2.0-M32”開源大模型
浪潮信息與北京伙伴共筑AI新生態
浪潮信息發布源2.0-M32開源大模型,模算效率大幅提升
浪潮信息發布“源2.0-M32”開源大模型
浪潮信息發布AS13000G7-N系列分布式全閃存儲
【中心動態】 走進浪潮信息

浪潮信息發布為大模型專門優化的分布式全閃存儲AS13000G7-N系列

浪潮信息發布企業大模型開發平臺“元腦企智”EPAI

浪潮信息與英特爾合作推出一種大模型效率工具“YuanChat”

智邦國際與KeyarchOS完成浪潮信息澎湃技術認證

儀電云云操作系統獲得浪潮信息澎湃技術認證
浪潮信息發布源2.0基礎大模型,千億參數全面開源





 工商網監
工商網監
評論