 探討移動設備中的緩存文件管理
探討移動設備中的緩存文件管理
本文發表于FAST 2022。探討緩存文件管理方法。本文通過一個輕量級的基于機器學習的分類引擎來篩選和個性化管理緩存文件,實驗在華為P9和Mate30兩部手機上進行,驗證I/O性能和存儲壽命。結果表明其具有很好的實用價值。
背景
由于應用程序的動態特性和整體系統優化,大部分移動應用程序都需要從網絡中下載文件或數據。即使現代通信網絡具有更高的帶寬,許多應用程序仍然嚴重依賴移動設備上緩存的數據,以避免通過網絡重新下載數據,并滿足其執行延遲需求。當前的移動設備首先將緩存文件存儲在主存中,然后將它們寫回閃存。這些應用程序的緩存數據通常作為緩存文件進行管理,并且可以快速地重新訪問。
問題
1. 緩存文件請求的空間越來越大。
即使部分移動系統和用戶會對部分緩存文件進行刪除,但是由于緩存文件的保存而造成的額外閃存寫已經發生,對閃存性能和壽命的損害也無法避免;同時,實驗顯示現實緩存文件寫入移動設備存儲中的數據量占總寫入量的64%,頻繁的緩存文件的寫入和刪除都會引起閃存的IO爭用用降低系統效率,影響閃存壽命。
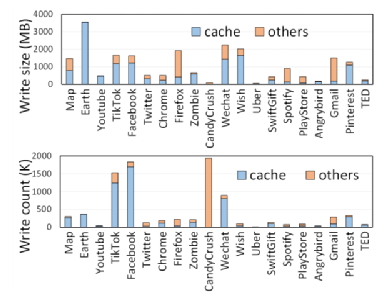
圖1 不同應用緩存寫次數和寫量占比
2. 當前的安卓系統沒有考慮緩存文件之間的差異性。
緩存文件根據其訪問模式和生命周期可以分為三類:閱后即焚文件,下載后不會被再次訪問,因此可以在訪問之后直接刪除;瞬態文件,下載后短時間內會頻繁訪問,但過一段時間舊不會被再次訪問;長壽文件,下載后的很長一段時間后還會被再次訪問。實驗結果顯示由93%的緩存文件都是閱后即焚文件和瞬態文件,不需要存儲到閃存中去,但是當前的系統對所有的緩存文件都采取持久化到閃存的策略,實際上造成了存儲空間的極大浪費,嚴重影響閃存壽命和性能。
CacheSifter設計與實現
1. 設計原則(1)用戶應用透明,不影響應用的正常運行;
(2)在線分類,對于閱后即焚文件和瞬態文件避免存儲到閃存中;
(3)自適應內存管理,根據內存的使用情況自動調整不同應用的緩存對于內存的占用;
(4)適應用戶行為的改變,當用戶訪問模式改變時可以重新分類已經做過分類的文件;
(5)確保系統安全性,刪除緩存文件不會導致應用程序崩潰或用戶數據丟失。
2. 基本框架
用一個輕量級的機器學習模型進行緩存文件的在線分類,并根據不同的文件類型采取不同的存儲策略:對于閱后即焚文件,在分類之后立即刪除;對于瞬態文件,分類之后由內存中的鏈表進行管理,超出活動時長則進行刪除操作;對于長壽文件,利用安卓的基本LRU驅逐機制,自動寫回后端閃存,并會在應用程序將該文件失效之后從閃存中刪除。對于一些重要的緩存文件或者刪除會影響系統安全的文件維護一個安全鏈表,避免誤刪的操作。
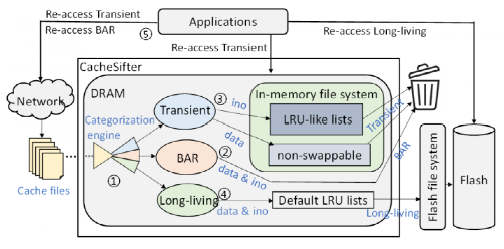
圖2 系統框架
CacheSifter優勢
1. 避免在閃存中存儲閱后即焚文件和瞬態緩存文件,可以減少對閃存空間的不必要的數據寫,大大改善閃存性能和壽命;2. 直接從DRAM訪問瞬態文件,提高這部分文件的訪問速度和性能;3. 利用輕量級的機器學習模型來優化緩存文件的管理,引入的代價極小,可以實現用戶透明的目標。
評估
評估實驗在華為P9和Mate30兩部手機上進行,由于CacheSifter的平臺獨立性,結果顯示在兩部手機上的實驗數據差異不大。
由于內存使用和分類時間的限制,本文在一個模型中只能關注一個優化指標,因此使用了兩個模型來進行訓練以分別保證訓練的高準確率或高召回率:高召回率模型旨在減少緩存文件的回寫,并將重新下載的開銷最小到最低;而高精度模型則旨在以最小的錯誤分類來減少緩存文件的回寫。
為了評估Cache Sifter的有效性,我們設計實驗來驗證本文的方法在緩存回寫數據量的減少、閃存壽命的改善、密集IO下讀寫性能的提高等指標上的結果。
1. 緩存文件寫回數據量顯著減小
該實驗主要對緩存寫的減少和總IO的減少進行評估。
在P9上,高召回模型和高精度模型將緩存文件的寫平均減少了62%和59.5%。兩種模型也顯著減少了總i/o的數量,即平均分別為29.7%和31.2%;在Mate30上,兩種模型也都大大減少了緩存文件的回寫,即平均分別為88.3%和85.5%。兩種模型的I/Os數量也減少得更多,即平均分別為47.7%和46.6%。而之所以在兩部手機上具有不同的優化效果,主要還是因為用戶行為和系統默認管理機制的不同。
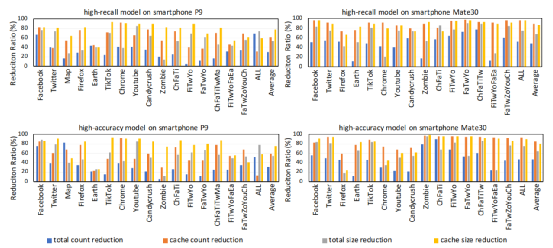
圖3 緩存寫回數據量減少的實驗結果
2. 閃存壽命顯著改善
通過代入寫放大系數、預留空間因子、以及PE循環次數可以大致估算出閃存的壽命。以P9為例,通過計算可以得出兩種模型的平均I/O量可分別減少53.2%和54.7%。因此,使用壽命可以平均分別提高113.7%和120.8%。可以看出本文的方法可以有效提升閃存壽命。
3. 密集IO下讀寫性能提升
通過制造IO密集內存條件,測試了不同實驗組(不做緩存管理的基本組,高召回率實驗組,高準確率實驗組,不生成緩存文件的實驗組)在讀寫一個512MB文件時的讀寫延遲。實驗結果如圖4:
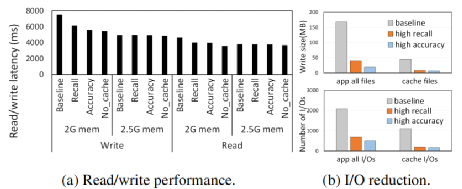
圖4 讀寫性能的提升(a)和IO數據量的減少(b)
可以看到在IO密集情況下(2G內存),與基本組相比,高召回率模型的讀寫延遲平均分別降低了13.9%和18.4%,而使用高精度模型的讀寫延遲分別降低了14.4%和25.5%。這是因為CacheSifter會使得由應用程序生成的緩存文件回寫顯著減小,從而改善了內存不足或IO密集情況下的IO爭用。因此當內存充足(至少2.5G)時,這種改善會由于IO爭用的不明顯而無法體現。
總結
文章提出了一種緩存文件管理方案CacheSifter,通過一個輕量級的基于機器學習的分類引擎來篩選和個性化管理緩存文件,實驗結果可以證明該方法對I/O性能和存儲壽命都提供了顯著的好處,但開銷很小,具有很好的實用價值。
The End
致 謝
感謝本次論文解讀者,來自華東師范大學的準研究生張祎,主要研究方向為閃存緩存管理技術研究。
原文標題:移動設備中的緩存文件管理
文章出處:【微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
原文標題:移動設備中的緩存文件管理
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
緩存之美——如何選擇合適的本地緩存?
EasyControl賦能華為HarmonyOS系統的企業級移動設備管理方案

嵌入式設備中的4G/5G模塊管理
鴻蒙開發文件管理:【@ohos.fileManager (公共文件訪問與管理)】

鴻蒙原生應用元服務開發WEB-緩存與存儲管理
LOTO示波器軟件PC緩存(波形錄制與回放)功能
設備倉儲管理系統在設備管理中的應用
鴻蒙開發實戰:【文件管理】






 工商網監
工商網監
評論