 聚類分析的簡單案例
聚類分析的簡單案例
基本概念
聚類就是一種尋找數據之間一種內在結構的技術。聚類把全體數據實例組織成一些相似組,而這些相似組被稱作聚類。處于相同聚類中的數據實例彼此相同,處于不同聚類中的實例彼此不同。聚類技術通常又被稱為無監督學習,因為與監督學習不同,在聚類中那些表示數據類別的分類或者分組信息是沒有的。
通過上述表述,我們可以把聚類定義為將數據集中在某些方面具有相似性的數據成員進行分類組織的過程。因此,聚類就是一些數據實例的集合,這個集合中的元素彼此相似,但是它們都與其他聚類中的元素不同。在聚類的相關文獻中,一個數據實例有時又被稱為對象,因為現實世界中的一個對象可以用數據實例來描述。同時,它有時也被稱作數據點(Data Point),因為我們可以用r 維空間的一個點來表示數據實例,其中r 表示數據的屬性個數。下圖顯示了一個二維數據集聚類過程,從該圖中可以清楚地看到數據聚類過程。雖然通過目測可以十分清晰地發現隱藏在二維或者三維的數據集中的聚類,但是隨著數據集維數的不斷增加,就很難通過目測來觀察甚至是不可能。
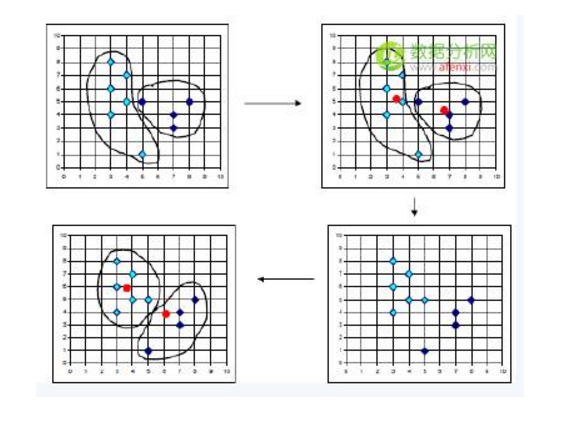
SAS聚類分析案例
1 問題背景
考慮下面案例,一個棒球管理員希望根據隊員們的興趣相似性將他們進行分組。顯然,在該例子中,沒有響應變量。管理者希望能夠方便地識別出隊員的分組情況。同時,他也希望了解不同組之間隊員之間的差異性。
該案例的數據集是在SAMPSIO庫中的DMABASE數據集。下面是數據集中的主要的變量的描述信息:
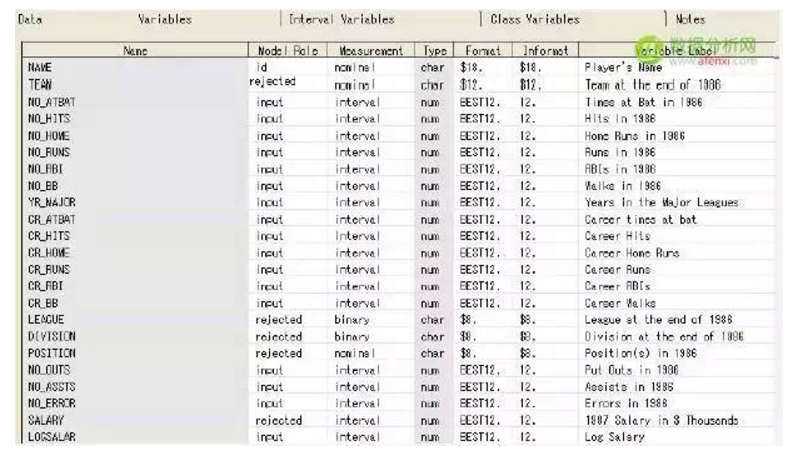
在這個案例中,設置TEAM,POSITION,LEAGUE,DIVISION和SALARY變量的模型角色為rejected,設置SALARY變量的模型角色為rejected是由于它的信息已經存儲在LOGSALAR中。在聚類分析和自組織映射圖中是不需要目標變量的。如果需要在一個目標變量上識別分組,可以考慮預測建模技術或者定義一個分類目標。
2 聚類方法概述
聚類分析經常和有監督分類相混淆,有監督分類是為定義的分類響應變量預測分組或者類別關系。而聚類分析,從另一方面考慮,它是一種無監督分類技術。它能夠在所有輸入變量的基礎上識別出數據集中的分組和類別信息。這些組、簇,賦予不同的數字。然而,聚類數目不能用來評價類別之間的近似關系。自組織映射圖嘗試創建聚類,并且在一個圖上用圖形化的方式繪制出聚類信息,在此處我們并沒有考慮。
1) 建立初始數據流
2) 設置輸入數據源結點
打開輸入數據源結點
從SAMPSIO庫中選擇DMABASE數據集
設置NAME變量的模型角色為id,TEAM,POSIOTION,LEAGUE,DIVISION和SALARY變量的模型角色為rejected
探索變量的分布和描述性統計信息
選擇區間變量選項卡,可以觀察到只有LOGSALAR和SALARY變量有缺失值。選擇類別變量選項卡,可以觀察到沒有缺失值。在本例中,沒有涉及到任何類別變量。
關閉輸入數據源結點,并保存信息。
3) 設置替代結點
雖然并不是總是要處理缺失值,但是有時候缺失值的數量會影響聚類結點產生的聚類解決方案。為了產生初始聚類,聚類結點往往需要一些完整的觀測值。當缺失值太多的時候,需要用替代結點來處理。雖然這并不是必須的,但是在本例中使用到了。
4) 設置聚類結點
打開聚類結點,激活變量選項卡。K-means聚類對輸入數據是敏感的。一般情況下,考慮對數據集進行標準化處理。
在變量選項卡,選擇標準偏差單選框
選擇聚類選項卡
觀察到默認選擇聚類數目的方法是自動的
關閉聚類結點
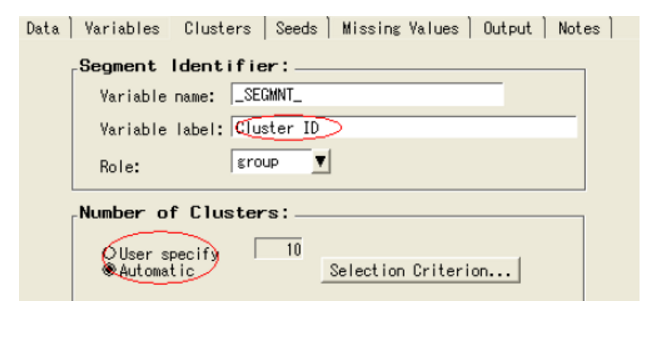
5) 聚類結果
在聚類結點處運行流程圖,查看聚類結果。
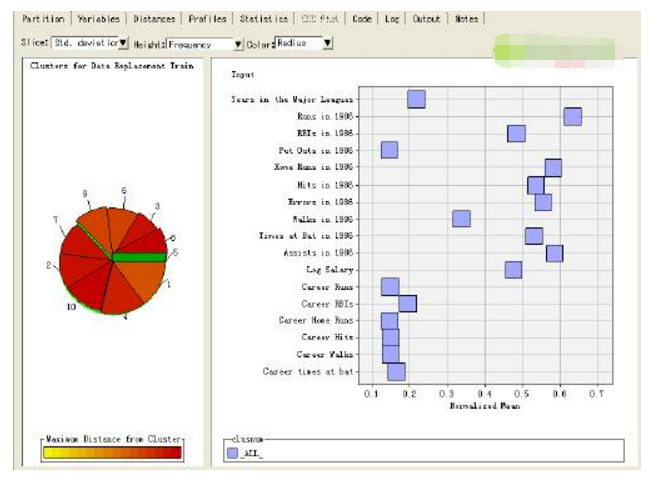
6) 限定聚類數目
打開聚類結點
選擇聚類選項卡
在聚類數目選擇部分,點擊選擇標準按鈕
輸入最大聚類數目為10
點擊ok,關閉聚類結點
7)結果解釋
我們可以定義每個類別的信息,結合背景識別每個類型的特征。選擇箭頭按鈕,
選擇三維聚類圖的某一類別,
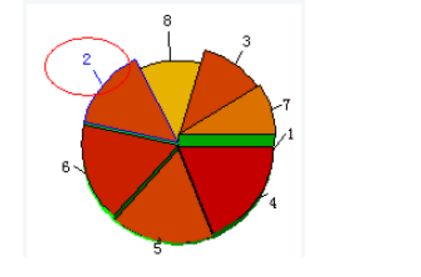
在工具欄選擇刷新輸入均值圖圖標,
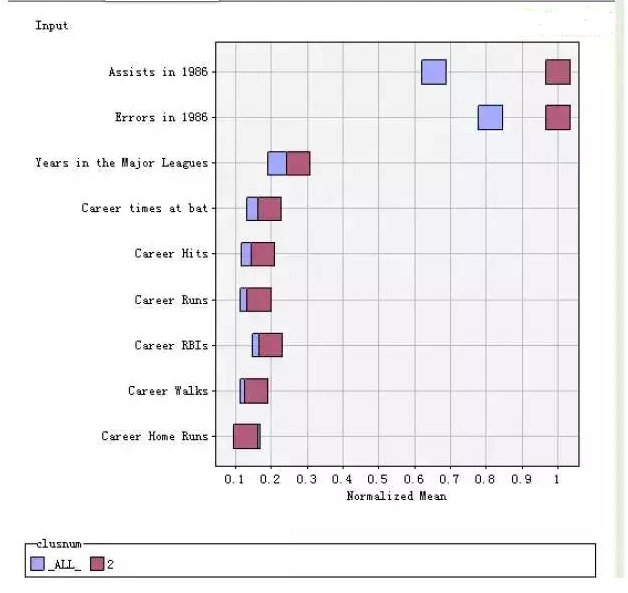
點擊該圖標,可以查看該類別的規范化均值圖
同理,可以根據該方法對其他類別進行解釋。
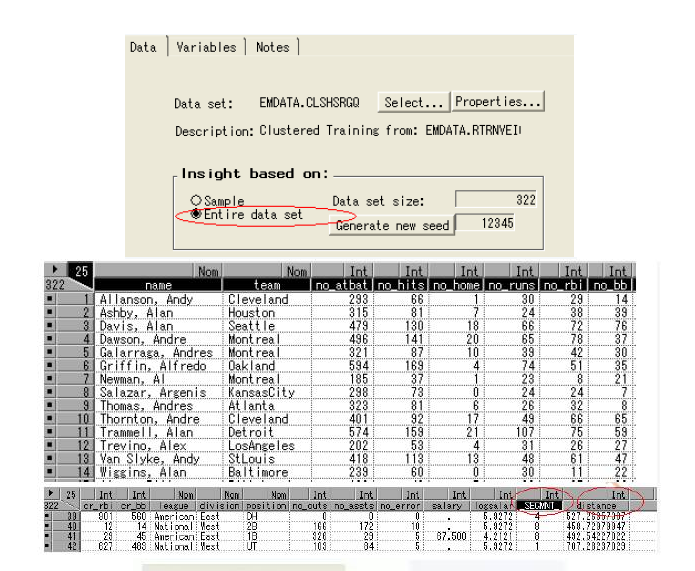
8)運用Insight結點
Insight結點可以用來比較不同屬性之間的異常。打開insight結點,選擇整個數據集,關閉結點。
從insight結點處運行。
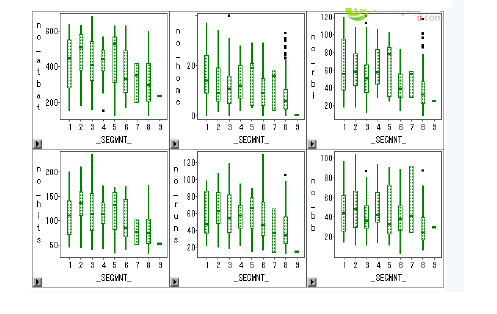
變量_SEGMNT_標識類別,distance標識觀測值到所在類別中心的距離。運用insight窗口的analyze工具評估和比較聚類結果。
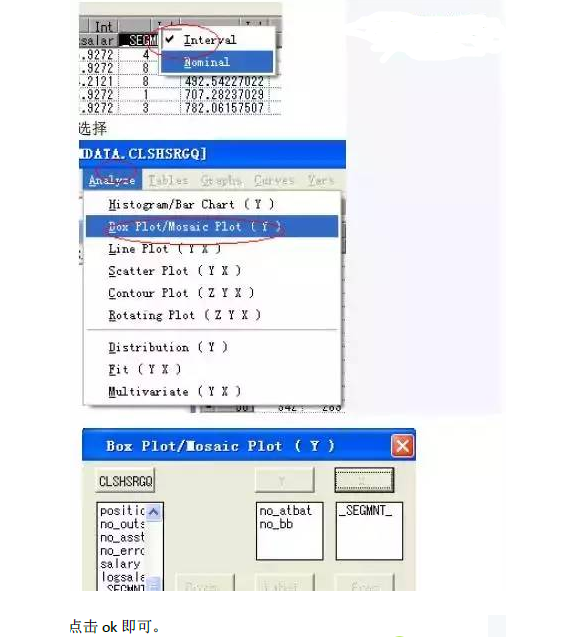
首先把_SEGMNT_的度量方式從interval轉換成nominal。
聚類應用
在商業上,聚類分析被用來發現不同的客戶群,并且通過購買模式刻畫不同的客戶群的特征。聚類分析是細分市場的有效工具,同時也可用于研究消費者行為,尋找新的潛在市場、選擇實驗的市場,并作為多元分析的預處理。在生物上,聚類分析被用來動植物分類和對基因進行分類,獲取對種群固有結構的認識。在地理上,聚類能夠幫助在地球中被觀察的數據庫商趨于的相似性。在保險行業上,聚類分析通過一個高的平均消費來鑒定汽車保險單持有者的分組,同時根據住宅類型,價值,地理位置來鑒定一個城市的房產分組。在因特網應用上,聚類分析被用來在網上進行文檔歸類來修復信息。在電子商務上,聚類分析在電子商務中網站建設數據挖掘中也是很重要的一個方面,通過分組聚類出具有相似瀏覽行為的客戶,并分析客戶的共同特征,可以更好的幫助電子商務的用戶了解自己的客戶,向客戶提供更合適的服務。
聚類分析應用——市場細分
聚類是將數據分類到不同的類或者簇這樣的一個過程,所以同一個簇中的對象有很大的相似性,而不同簇間的對象有很大的相異性。
從統計學的觀點看,聚類分析是通過數據建模簡化數據的一種方法。傳統的統計聚類分析方法包括系統聚類法、分解法、加入法、動態聚類法、有序樣品聚類、有重疊聚類和模糊聚類等。
從機器學習的角度講,簇相當于隱藏模式。聚類是搜索簇的無監督學習過程。與分類不同,無監督學習不依賴預先定義的類或帶類標記的訓練實例,需要由聚類學習算法自動確定標記,而分類學習的實例或數據對象有類別標記。聚類是觀察式學習,而不是示例式的學習。
從實際應用的角度看,聚類分析是數據挖掘的主要任務之一。而且聚類能夠作為一個獨立的工具獲得數據的分布狀況,觀察每一簇數據的特征,集中對特定的聚簇集合作進一步地分析。聚類分析還可以作為其他算法(如分類和定性歸納算法)的預處理步驟。
聚類分析的核心思想就是物以類聚,人以群分。在市場細分領域,消費同一種類的商品或服務時,不同的客戶有不同的消費特點,通過研究這些特點,企業可以制定出不同的營銷組合,從而獲取最大的消費者剩余,這就是客戶細分的主要目的。在銷售片區劃分中,只有合理地將企業所擁有的子市場歸成幾個大的片區,才能有效地制定符合片區特點的市場營銷戰略和策略。金融領域,對基金或者股票進行分類,以選擇分類投資風險。
下面以一個汽車銷售的案例來介紹聚類分析在市場細分中的應用。
商業目標
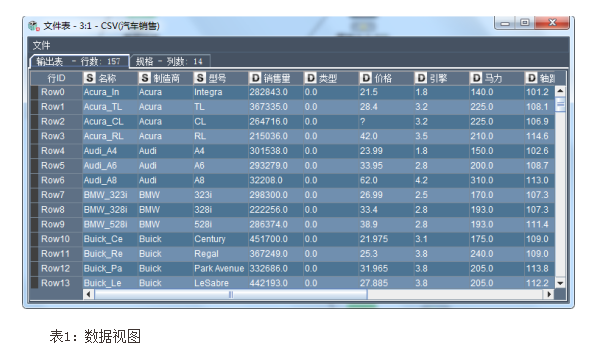
業務理解:數據名稱《汽車銷售.csv》。該案例所用的數據是一份關于汽車的數據,該數據文件包含銷售值、訂價以及各種品牌和型號的車輛的物理規格。訂價和物理規格可以從 edmunds.com 和制造商處獲得。定價為美國本土售價。如下:
業務目標:對市場進行準確定位,為汽車的設計和市場份額預測提供參考。
數據挖掘目標:通過聚類的方式對現有的車型進行分類。
數據準備
通過數據探索對數據的質量和字段的分布進行了解,并排除有問題的行或者列優化數據質量。
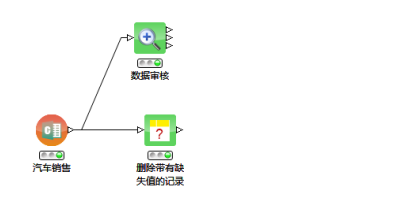
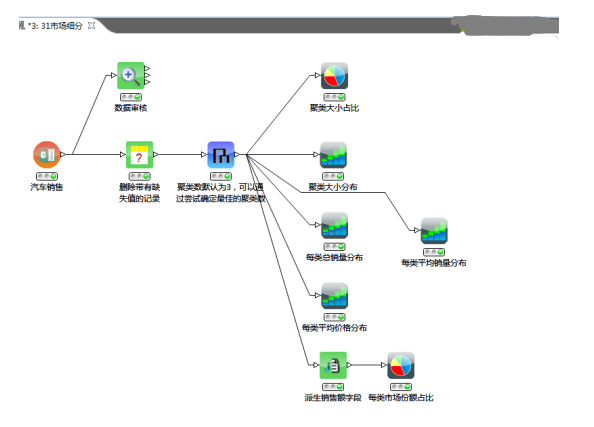
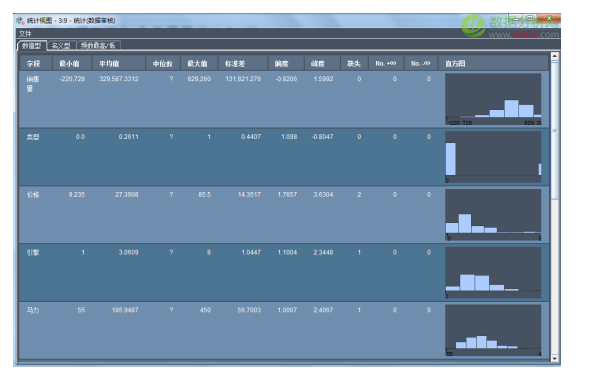
第一步,我們使用統計節點審核數據的質量,從審核結果中我們發現存在缺失的數據,如下圖所示:
第二步,對缺失的數據進行處理,我們選擇使用缺失填充節點刪除這些記錄。配置如下:
建模
我們選擇層次聚類進行分析,嘗試根據各種汽車的銷售量、價格、引擎、馬力、軸距、車寬、車長、制動、排量、油耗等指標對其分類。
因為層次聚類不能自動確定分類數量,因此需要我們以自定義的方式規定最后聚類的類別數。層次聚類節點配置如下(默認配置):
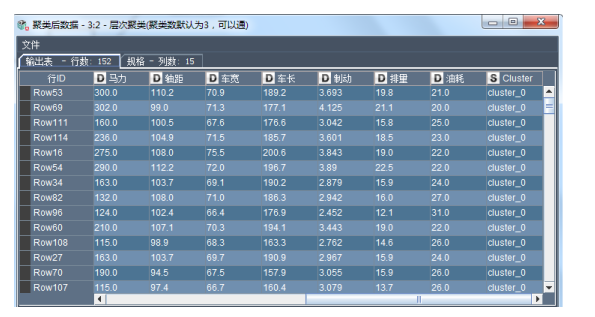
可以使用交互表或者右擊層次聚類節點查看聚類的結果,如下圖所示:
再使用餅圖查看每個類的大小,結果如下:
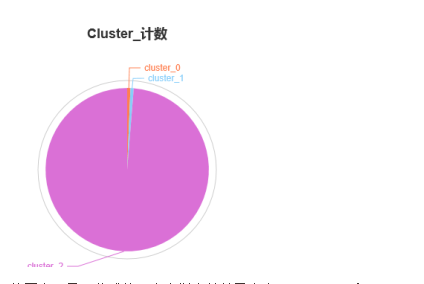
從圖中可見,分成的三個類樣本數差異太大,cluster_0和cluster_1包含的樣本數都只有1,這樣的分類是沒有意義的,因此需要重新分類。我們嘗試在層次聚類節點的配置中指定新的聚類方法:完全。新的聚類樣本數分布如下:
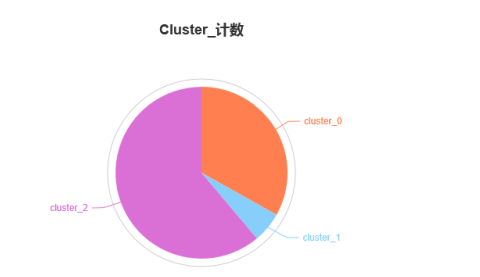
cluster_0、 cluster_1、cluster_2的樣本數分別為:50、9、93。
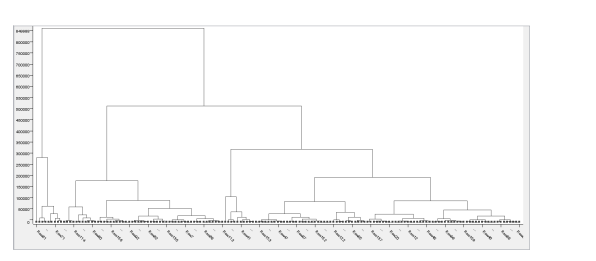
執行后輸出樹狀/冰柱圖,可以從上往下看,一開始是一大類,往下走就分成了兩類,越往下分的類越多,最后細分到每一個記錄是一類,如下所示:
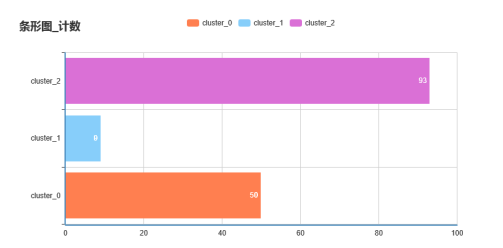
我們可以再使用條形圖查看每類的銷售量、平均價格,如下圖所示:
每類總銷量分布圖
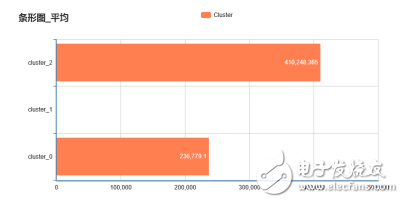
每類平均銷量分布圖
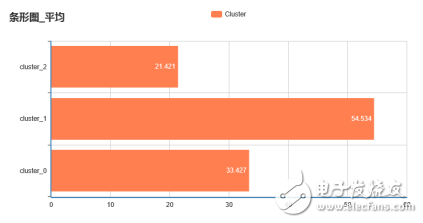
每類平均價格分布圖
我們再看一下每類的銷售額分布情況。首先,我們需要使用Java代碼段節點或者派生節點生成銷售額字段,配置如下:
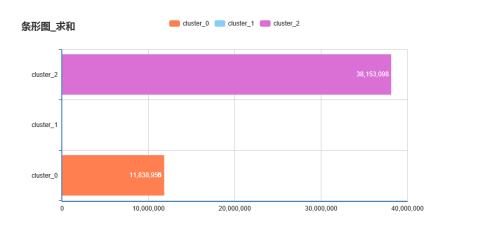
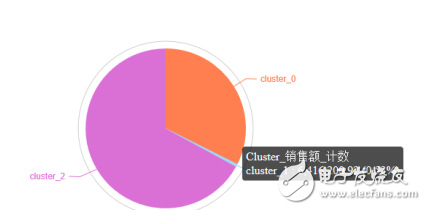
再使用餅圖查看銷售額分布情況,cluster_0、 cluster_1、cluster_2的市場份額分別為:32.39%、0.53%和67.08%,如下圖所示:
案例小結
通過這個案例,大家可以發現聚類分析確實很簡單。進行聚類計算后,主要通過圖形化探索的方式評估聚類合理性,以及在確定聚類后,分析每類的特征。
-
聚類分析
+關注
關注
0文章
16瀏覽量
7407
發布評論請先 登錄
相關推薦
電動機的安裝形式有哪些?簡單分析
發電機的主要工作原理是什么?簡單分析
變頻電機的主要構造原理是什么?簡單分析
汽車發電機的工作原理是什么?簡單分析
單相電機正反轉原理是什么?簡單分析
Keysight 頻譜分析儀(信號分析儀)

QT串口通信的簡單使用
利用拉曼光譜對用于制藥的帶狀薄膜進行實時定量分析

數字前端電路:簡單的邊沿檢測電路分析
CanEasy多場景應用,讓汽車總線測試更簡單
使用Raspberry Pi Pico實現簡單的邏輯分析儀

利用拉曼光譜對制藥應用的條狀薄膜進行實時定量分析






 工商網監
工商網監
評論