 機器學習開發課程,使用Pandas探索數據分析
機器學習開發課程,使用Pandas探索數據分析
編者按:Mail.Ru數據科學家Yury Kashnitsky和Segmento數據科學家Katya Demidova合作開設了機器學習開發課程。第一課介紹了如何使用Pandas進行數據分析。
這一篇文章意味著,我們OpenDataScience的開放機器學習課程開始了。這一課程的目標并不是開發另一個全面的機器學習或數據分析的引導課程(所以這并不能代替基礎性的教育,在線和線下課程,培訓,以及書籍)。本系列文章的目的是幫你快速溫習知識,同時幫你找到進一步學習的主題。我們的角度和Deep Learning book的作者們類似,從回顧數學和機器學習基礎開始——簡短扼要,包含很多指向其他資源的鏈接。
這一課程的設計考慮到了理論和實踐的平衡;因此,每個主題附帶了作業。你可以參加Kaggle上相應的競賽。
我們在OpenDataScience的Slack小組中討論這一課程。請填寫這個表單申請加入。
概覽
關于本課程
作業說明
主要Pandas方法
預測電信運營商的客戶離網率
作業一
參考資源
1. 關于本課程
大綱
使用Pandas探索數據分析
使用Python可視化數據
分類、決策樹、K近鄰
線性分類、線性回歸
Bagging、隨機森林
特征工程、特征選取
無監督學習:主成分分析、聚類
Vowpal Wabbit:學習GB級數據
使用Python進行時序分析
梯度提升
社區
我們的課程的最突出的優勢之一就是活躍的社區。如果你加入OpenDataScience的Slack小組,你會發現文章和作業的作者們在#eng_mlcourse_open頻道熱心答疑。對初學者而言,這非常有用。請填寫這個表單申請加入。表單會詢問一些關于你的背景和技能的問題,包括幾道簡單的數學題。
我們的聊天比較隨意,喜歡開玩笑,經常使用表情。不是所有的MOOC敢夸口說自己有這樣一個活躍的社區。另外,Reddit上也有這一課程的subreddit。
預備知識
預備知識:
微積分的基本概念
線性代數
概率論和統計
Python編程技能
如果你需要補習一下,可以參考“Deep Learning”一書的第一部分,以及眾多數學和Python的線上課程(例如,CodeAcademy的Python課程)。以后我們的wiki頁面將補充更多信息。
軟件
目前而言,你只需要Anaconda(基于Python 3.6),就可以重現當前課程中的代碼。在之后的課程中,你需要安裝其他庫,例如Xgboost和Vowpal Wabbit。
你也可以使用這個Docker容器,其中已經預裝了所有需要用到的軟件。更多信息請看相應的wiki頁面。
2. 作業
每篇文章以Jupyter notebook的形式給出作業。作業包括補全代碼片段,以及通過Google表單回答一些問題。
每個作業必須在一周之內完成。
請在OpenDataScience的Slack小組#eng_mlcourse_open頻道或直接評論留言討論課程內容。
作業的答案會發給提交了相應的Google表單的用戶。
Pandas的主要方法
好吧……其實已經有很多關于Pandas和可視化數據分析的教程了。如果你很熟悉這些主題,請等待本系列的第3篇文章,正式開始機器學習的內容。
下面的材料以Jupyter notebook的形式查看效果最佳。如果你克隆了本教程的代碼倉庫,你也可以在本地運行。
Pandas是一個Python庫,提供了大量數據分析的方法。數據科學家經常和表格形式的數據(比如.csv、.tsv、.xlsx)打交道。Pandas可以使用類似SQL的方式非常方便地加載、處理、分析這些表格形式的數據。搭配Matplotlib和Seaborn效果更好。
Pandas的主要數據結構是Series和DataFrame類。前者是一個包含某種固定類型數據的一維數組,后者是一個二維數據結構——一張表格——其中每列包含相同類型的數據。你可以把它看成Series實例構成的字典。DataFrame很適合表示真實數據:行代表實例(對象、觀測,等等),列代表每個實例的相應特征。
我們將通過分析電信運營商的客戶離網率數據集來展示Pandas的主要方法。我們首先通過read_csv讀取數據,然后使用head方法查看前5行數據:
import pandas as pd
import numpy as np
df = pd.read_csv('../../data/telecom_churn.csv')
df.head()

每行對應一位客戶,我們的研究對象,列則是對象的特征。
讓我們查看一下數據的維度、特征名稱和特征類型。
print(df.shape)
結果:
(3333, 20)
所以我們的表格包含3333行和20列。下面我們嘗試打印列名:
print(df.columns)
結果:
Index(['State', 'Account length', 'Area code', 'International plan',
'Voice mail plan', 'Number vmail messages', 'Total day minutes',
'Total day calls', 'Total day charge', 'Total eve minutes',
'Total eve calls', 'Total eve charge', 'Total night minutes',
'Total night calls', 'Total night charge', 'Total intl minutes',
'Total intl calls', 'Total intl charge', 'Customer service calls',
'Churn'],
dtype='object')
我們可以使用info()方法輸出dataframe的一些總體信息:
print(df.info())
RangeIndex: 3333 entries, 0 to 3332
Data columns (total 20 columns):
State 3333 non-null object
Account length 3333 non-null int64
Area code 3333 non-null int64
International plan 3333 non-null object
Voice mail plan 3333 non-null object
Number vmail messages 3333 non-null int64
Total day minutes 3333 non-null float64
Total day calls 3333 non-null int64
Total day charge 3333 non-null float64
Total eve minutes 3333 non-null float64
Total eve calls 3333 non-null int64
Total eve charge 3333 non-null float64
Total night minutes 3333 non-null float64
Total night calls 3333 non-null int64
Total night charge 3333 non-null float64
Total intl minutes 3333 non-null float64
Total intl calls 3333 non-null int64
Total intl charge 3333 non-null float64
Customer service calls 3333 non-null int64
Churn 3333 non-null bool
dtypes: bool(1), float64(8), int64(8), object(3)
memory usage: 498.1+ KB
None
bool、int64、float64和object是我們特征的數據類型。這一方法同時也會顯示是否有缺失的值。在上面的例子中答案是沒有缺失,因為每列都包含3333個觀測,和我們之前使用shape方法得到的數字是一致的。
我們可以通過astype方法更改列的類型。讓我們將這一方法應用到Churn特征以將其修改為int64:
df['Churn'] = df['Churn'].astype('int64')
describe方法可以顯示數值特征(int64和float64)的基本統計學特性:未缺失值的數值、均值、標準差、范圍、四分位數。
df.describe()
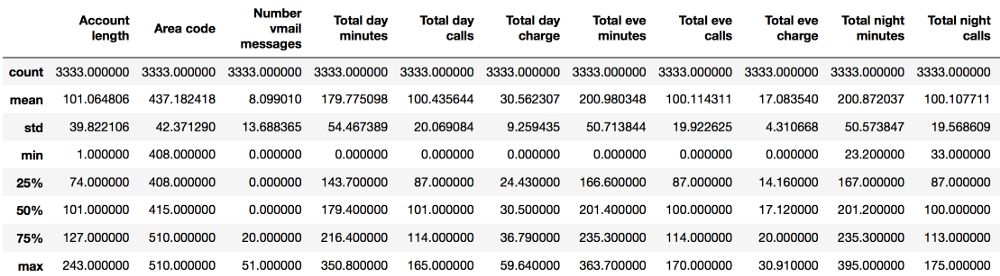
查看非數值特征的統計數據時,需要通過include參數顯式指定包含的數據類型:
df.describe(include=['object', 'bool'])
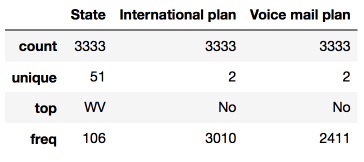
類別(類型為object)和布爾值(類型為bool)特征可以應用value_counts方法。讓我們看下Churn的分布:
df['Churn'].value_counts()
結果:
0 2850
1 483
Name: Churn, dtype: int64
3333位客戶中,2850位是忠實客戶;他們的Churn值為0。調用value_counts函數時,帶上normalize=True參數可以顯示比例:
df['Churn'].value_counts(normalize=True)
結果:
0 0.855086
1 0.144914
Name: Churn, dtype: float64
排序
DataFrame可以根據某個變量的值(也就是列)排序。比如,根據每日消費額排序(ascending=False倒序):
df.sort_values(by='Total day charge', ascending=False).head()

此外,還可以根據多個列的數值排序:
df.sort_values(by=['Churn', 'Total day charge'], ascending=[True, False]).head()

索引和獲取數據
DataFrame可以以不同的方式索引。
使用DataFrame['Name']可以得到一個單獨的列。比如:離網率有多高?
df['Churn'].mean()
結果:
0.14491449144914492
對一家公司而言,14.5%的離網率是一個很糟糕的數據;這么高的離網率可能導致公司破產。
布爾值索引同樣很方便。語法是df[P(df['Name'])],P是檢查Name列每個元素的邏輯條件。這一索引的結果是DataFrame的Name列中滿足P條件的行。
讓我們使用布爾值索引來回答這樣一個問題:
離網用戶的數值變量的均值是多少?
df[df['Churn'] == 1].mean()
結果:
Account length 102.664596
Area code 437.817805
Number vmail messages 5.115942
Total day minutes 206.914079
Total day calls 101.335404
Total day charge 35.175921
Total eve minutes 212.410145
Total eve calls 100.561077
Total eve charge 18.054969
Total night minutes 205.231677
Total night calls 100.399586
Total night charge 9.235528
Total intl minutes 10.700000
Total intl calls 4.163561
Total intl charge 2.889545
Customer service calls 2.229814
Churn 1.000000
dtype: float64
離網用戶在白天打電話的總時長的均值是多少?
df[df['Churn'] == 1]['Total day minutes'].mean()
結果:
206.91407867494814
未使用國際套餐的忠實用戶(Churn == 0)所打的最長的國際長途是多久?
df[(df['Churn'] == 0) & (df['International plan'] == 'No')]['Total intl minutes'].max()
結果:
18.899999999999999
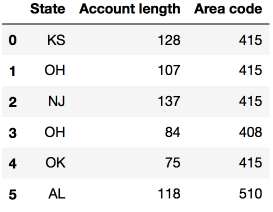
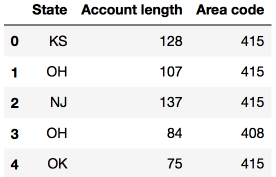
DataFrame可以通過列名、行名、行號進行索引。loc方法為通過名稱索引,iloc方法為通過數字索引。
loc的例子:給我們0至5行(含)、State(州)至Area code(區號)(含)的數據;iloc的例子:給我們前5行、前3列的數據(和典型的Python切片一樣,不含最大值)。
df.loc[0:5, 'State':'Area code']
df.iloc[0:5, 0:3]
df[:1]和df[-1:]可以得到DataFrame的首行和末行。(譯者注:個人更喜歡用df.head(1)和df.tail(1)。)
應用函數到單元格、列、行
使用apply()方法應用函數至每一列:
df.apply(np.max)
結果:
State WY
Account length 243
Area code 510
International plan Yes
Voice mail plan Yes
Number vmail messages 51
Total day minutes 350.8
Total day calls 165
Total day charge 59.64
Total eve minutes 363.7
Total eve calls 170
Total eve charge 30.91
Total night minutes 395
Total night calls 175
Total night charge 17.77
Total intl minutes 20
Total intl calls 20
Total intl charge 5.4
Customer service calls 9
Churn 1
dtype: object
apply方法也可以應用函數至每一行,指定axis=1即可。lambda函數在這一場景下十分方便。比如,選中所有以W開頭的州:
df[df['State'].apply(lambda state: state[0] == 'W')].head()

map方法可以替換某一列中的值:
d = {'No' : False, 'Yes' : True}
df['International plan'] = df['International plan'].map(d)
df.head()

其實也可以直接使用replace方法:
df = df.replace({'Voice mail plan': d})
df.head()

組
Pandas下分組數據的一般形式為:
df.groupby(by=grouping_columns)[columns_to_show].function()
groupby方法根據grouping_columns的值進行分組。
接著,選中感興趣的列(columns_to_show)。如果不包括這一項,那么會包括所有非groupby列。
最后,應用一個或多個函數。
在下面的例子中,我們根據Churn變量的值分組數據,顯示每組的統計數據:
columns_to_show = ['Total day minutes', 'Total eve minutes',
'Total night minutes']
df.groupby(['Churn'])[columns_to_show].describe(percentiles=[])

和上面的例子類似,只不過這次將一些函數傳給agg():
columns_to_show = ['Total day minutes', 'Total eve minutes',
'Total night minutes']
df.groupby(['Churn'])[columns_to_show].agg([np.mean, np.std,
np.min, np.max])

匯總表
假設我們想知道樣本的Churn(離網)和International plan(國際套餐)的分布,我們可以使用crosstab方法構建一個列聯表(contingency table):
pd.crosstab(df['Churn'], df['International plan'])

Churn(離網)和Voice mail plan(語音郵件套餐)的分布:
pd.crosstab(df['Churn'], df['Voice mail plan'], normalize=True)
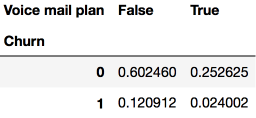
我們可以看到,大部分用戶是忠實的,同時并不使用額外的服務(國際套餐、語音郵件)。
對熟悉Excel的而言,這很像Excel中的透視表(pivot table)。當然,Pandas實現了透視表:pivot_table方法接受以下參數:
values需要計算統計數據的變量列表
index分組數據的變量列表
aggfunc需要計算哪些統計數據,例如,總和、均值、最大值、最小值,等等。
讓我們看下不同區號下白天、夜晚、深夜的電話量的均值:
df.pivot_table(['Total day calls', 'Total eve calls', 'Total night calls'], ['Area code'], aggfunc='mean')
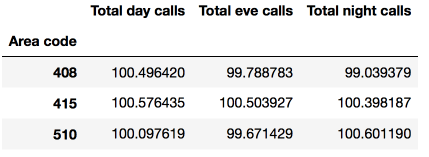
轉換DataFrame
和其他很多Pandas任務一樣,在DataFrame中新增列有很多方法。
比如,為所有用戶計算總的電話量:
total_calls = df['Total day calls'] + df['Total eve calls'] +
df['Total night calls'] + df['Total intl calls']
df.insert(loc=len(df.columns), column='Total calls', value=total_calls)
df.head()

上面的代碼創建了一個中間Series實例,其實可以直接添加:
df['Total charge'] = df['Total day charge'] + df['Total eve charge'] +
df['Total night charge'] + df['Total intl charge']
df.head()

使用drop方法刪除列和行,將相應的索引和axis參數(1表示刪除列,0表示刪除行,默認值為0)傳給drop方法。inplace參數表示是否修改原始DataFrame(False表示不修改現有DataFrame,返回一個新DataFrame,True表示修改當前DataFrame)。
# 移除先前創建的列
df.drop(['Total charge', 'Total calls'], axis=1, inplace=True)
# 如何刪除行
df.drop([1, 2]).head()

4. 預測離網率的首次嘗試
讓我們看下International plan(國際套餐)變量和離網率的相關性。我們將通過crosstab列聯表來查看這一關系,我們也將使用Seaborn進行可視化分析(不過,可視化分析的更多內容將在本系列的下一篇文章介紹):
pd.crosstab(df['Churn'], df['International plan'], margins=True)
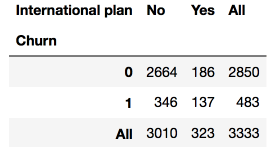
# 加載模塊,配置繪圖
%matplotlib inline
import matplotlib.pyplot as plt
# pip install seaborn
import seaborn as sns
plt.rcParams['figure.figsize'] = (8, 6)
sns.countplot(x='International plan', hue='Churn', data=df);
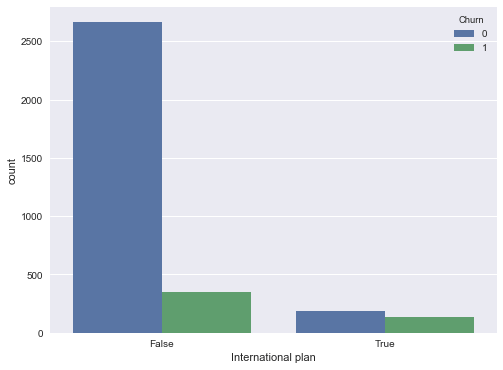
我們看到,開通了國際套餐的用戶的離網率要高很多,這是一個很有趣的觀測結果。也許,國際電話高昂、難以控制的話費很容易引起爭端,讓電信運營商的客戶很不滿意。
接下來,讓我們查看下另一個重要特征——客服呼叫。我們同樣編制一張匯總表,并繪制一幅圖像。
pd.crosstab(df['Churn'], df['Customer service calls'], margins=True)

sns.countplot(x='Customer service calls', hue='Churn', data=df);
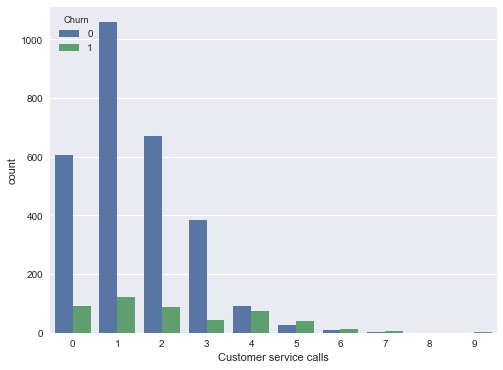
也許匯總表不是很明顯,但圖形很明顯地顯示了,從4次客戶呼叫開始,離網率顯著提升了。
讓我們給DataFrame添加一個二元屬性——客戶呼叫超過3次。同樣讓我們看下它與離網率的相關性:
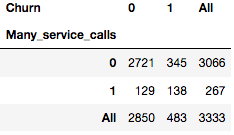
df['Many_service_calls'] = (df['Customer service calls'] > 3).astype('int')
pd.crosstab(df['Many_service_calls'], df['Churn'], margins=True)
sns.countplot(x='Many_service_calls', hue='Churn', data=df);
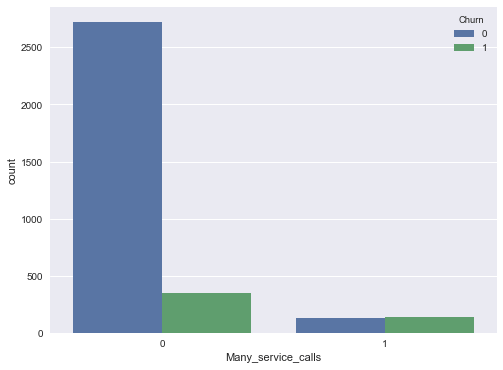
讓我們創建另一張列聯表,將Churn(離網)與International plan(國際套餐)及新創建的Many_service_calls(多次客服呼叫)關聯起來:
pd.crosstab(df['Many_service_calls'] & df['International plan'] , df['Churn'])

因此,預測客戶呼叫客服超過3次,且已開通國際套餐的情況下會離網(Churn=1),我們可以期望的精確度為85.8%的精確度(我們只有464+9次弄錯了)。我們基于非常簡單的推理得到的數字85.8%,可以作為一個良好的開端(我們即將創建的更多機器學習模型的基線)。
復習一下我們介紹的內容:
樣本中忠實客戶的份額為85.5%。這意味著最幼稚總是預測“忠實客戶”的模型有85.5%的概率猜對。也就是說,后續模型的正確答案的比例(精確度)不應該比這個數字少,并且很有希望顯著高于這個數字;
基于一個簡單的預測“(客服呼叫次數 > 3) & (國際套餐 = True) => Churn = 1, else Churn = 0”,我們可以期望85.8%的精確度,剛剛超過85.5%。以后我們將討論決策樹,看看如何僅僅基于輸入數據自動找出這樣的規則;
我們沒有應用機器學習就得到這兩條基線,它們將作為后續模型的開端。如果經過大量的努力,我們將正確答案的份額提高了0.5%,那么也許我們搞錯了什么,限制使用一個包含兩個條件的簡單模型已經足夠了;
在訓練復雜模型之間,建議擺弄下數據,繪制一些圖表,檢查一下簡單的假設。此外,在業務上應用機器學習時,通常從簡單的方案開始,接著嘗試更復雜的方案。
5. 作業一
第一次作業將分析包含美國居民的人口信息的UCI成人數據。我們建議你在Jupyter notebook中完成這些任務,然后通過Google表單回答10個問題。提交表單之后,同樣可以編輯你的回答。
截止日期:February 11, 23:59 CE
6. 相關資源
首先,當然是Pandas官方文檔
10 minutes to pandas(十分鐘入門pandas)
Pandas cheatsheet PDF
GitHub倉庫:Pandas exercises(Pandas練習)和Effective Pandas
scipy-lectures.org pandas、numpy、matplotlib、scikit-learn教程
-
機器學習
+關注
關注
66文章
8382瀏覽量
132441 -
數據分析
+關注
關注
2文章
1429瀏覽量
34025
原文標題:機器學習開放課程(一):使用Pandas探索數據分析
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論