 Python自動化運維之協程函數賦值過程
Python自動化運維之協程函數賦值過程
一、協程
1.1 協程的概念
協程,又稱微線程,纖程。英文名Coroutine。一句話說明什么是線程:協程是一種用戶態的輕量級線程。(其實并沒有說明白~)那么這么來理解協程比較容易:
線程是系統級別的,它們是由操作系統調度;協程是程序級別的,由程序員根據需要自己調度。我們把一個線程中的一個個函數叫做子程序,那么子程序在執行過程中可以中斷去執行別的子程序;別的子程序也可以中斷回來繼續執行之前的子程序,這就是協程。也就是說同一線程下的一段代碼執行著執行著就可以中斷,然后跳去執行另一段代碼,當再次回來執行代碼塊的時候,接著從之前中斷的地方開始執行。
比較專業的理解是:協程擁有自己的寄存器上下文和棧。協程調度切換時,將寄存器上下文和棧保存到其他地方,在切回來的時候,恢復先前保存的寄存器上下文和棧。因此:協程能保留上一次調用時的狀態(即所有局部狀態的一個特定組合),每次過程重入時,就相當于進入上一次調用的狀態,換種說法:進入上一次離開時所處邏輯流的位置。
1.2 協程的優缺點
協程的優點:(1)無需線程上下文切換的開銷,協程避免了無意義的調度,由此可以提高性能(但也因此,程序員必須自己承擔調度的責任,同時,協程也失去了標準線程使用多CPU的能力)(2)無需原子操作鎖定及同步的開銷(3)方便切換控制流,簡化編程模型(4)高并發+高擴展性+低成本:一個CPU支持上萬的協程都不是問題。所以很適合用于高并發處理。
協程的缺點:(1)無法利用多核資源:協程的本質是個單線程,它不能同時將 單個CPU 的多個核用上,協程需要和進程配合才能運行在多CPU上.當然我們日常所編寫的絕大部分應用都沒有這個必要,除非是cpu密集型應用。(2)進行阻塞(Blocking)操作(如IO時)會阻塞掉整個程序
二、Python中如何實現協程
2.1 yield實現協程
前文所述“子程序(函數)在執行過程中可以中斷去執行別的子程序;別的子程序也可以中斷回來繼續執行之前的子程序”,那么很容易想到Python的yield,顯然yield是可以實現這種切換的。
def eater(name): print("%s eat food" %name) while True: food = yield print("done")g = eater("gangdan")print(g)
執行結果:
由執行結果可以證明g現在就是生成器函數
2.2 協程函數賦值過程
用的是yield的表達式形式,要先運行next(),讓函數初始化并停在yield,然后再send() ,send會在觸發下一次代碼的執行時,給yield賦值
next()和send() 都是讓函數在上次暫停的位置繼續運行:
def creater(name): print('%s start to eat food' %name) food_list = [] while True: food = yield food_list print('%s get %s ,to start eat' %(name,food)) food_list.append(food)# 獲取生成器builder = creater('tom')# 現在是運行函數,讓函數初始化next(builder)print(builder.send('包子'))print(builder.send('骨頭'))print(builder.send('菜湯'))
運行結果:
tom start to eat foodtom get 包子 ,to start eat['包子']tom get 骨頭 ,to start eat['包子', '骨頭']tom get 菜湯 ,to start eat['包子', '骨頭', '菜湯']
需要注意的是每次都需要先運行next()函數,讓程序停留在yield位置。
如果有多個這樣的函數都需要執行next()函數,讓程序停留在yield位置。為了防止忘記初始化next操作,需要用到裝飾器來解決此問題。
def init(func): def wrapper(*args,**kwargs): builder = func(*args,**kwargs) next(builder) # 這個地方是關鍵可以使用builder.send("None"),第一次必須傳入None。 return builder return wrapper@initdef creater(name): print('%s start to eat food' %name) food_list = [] while True: food = yield food_list print('%s get %s ,to start eat' %(name,food)) food_list.append(food)# 獲取生成器builder = creater("tom")# 現在是直接運行函數,無須再函數初始化print(builder.send('包子'))print(builder.send('骨頭'))print(builder.send('菜湯'))
執行結果:
tom start to eat foodtom get 包子 ,to start eat['包子']tom get 骨頭 ,to start eat['包子', '骨頭']tom get 菜湯 ,to start eat['包子', '骨頭', '菜湯']
2.3 協程函數簡單應用
請給Tom投喂食物:
def init(func): def wrapper(*args,**kwargs): builder = func(*args,**kwargs) next(builder) return builder return wrapper@initdef creater(name): print('%s start to eat food' %name) food_list = [] while True: food = yield food_list print('%s get %s ,to start eat' %(name,food)) food_list.append(food)def food(): builder = creater("Tom") while True: food = input("請給Tom投喂食物:").strip() if food == "q": print("投喂結束") return 0 else: builder.send(food)if __name__ == '__main__': food()
執行結果:
Tom start to eat food請給Tom投喂食物:骨頭Tom get 骨頭 ,to start eat請給Tom投喂食物:菜湯Tom get 菜湯 ,to start eat請給Tom投喂食物:q投喂結束
2.4 協程函數的應用
實現linux中"grep -rl error <目錄>"命令,過濾一個文件下的子文件、字文件夾的內容中的相應的內容的功能程序。
首先了解一個OS模塊中的walk方法,能夠把參數中的路徑下的文件夾打開并返回一個元組。
>>> import os # 導入模塊>>> os.walk(r"E:Pythonscript") #使用r 是讓字符串中的符號沒有特殊意義,針對的是轉義
返回的是一個元組,第一個元素是文件的路徑,第二個是文件夾,第三個是該路徑下的文件。
這里需要用到一個寫程序的思想:面向過程編程。
三、面向過程編程
面向過程:核心是過程二字,過程及即解決問題的步驟,基于面向過程設計程序就是一條工業流水線,是一種機械式的思維方式。流水線式的編程思想,在設計程序時,需要把整個流程設計出來。
優點:1:體系結構更加清晰2:簡化程序的復雜度
缺點:可擴展性極其的差,所以說面向過程的應用場景是:不需要經常變化的軟件,如:linux內核,httpd,git等軟件下面就根據面向過程的思想完成協程函數應用中的功能。
目錄結構:
test├── aa│ ├── bb1│ │ └── file2.txt│ └── bb2│ └── file3.txt└─ file1.txt文件內容:file1.txt:error123file2.txt:123file3.txt:123error
程序流程:第一階段:找到所有文件的絕對路徑第二階段:打開文件第三階段:循環讀取每一行第四階段:過濾“error”第五階段:打印該行屬于的文件名第一階段:找到所有文件的絕對路徑
g是一個生成器,就能夠用next()執行,每次next就是運行一次,這里的運行結果是依次打開文件的路徑:
>>> import os>>> g = os.walk(r"E:Pythonscript函數 est")>>> next(g)('E:\Python\script\函數\test', ['aa'], [])>>> next(g)('E:\Python\script\函數\test\aa', ['bb1', 'bb2'], ['file1.txt'])>>> next(g)('E:\Python\script\函數\test\aa\bb1', [], ['file2.txt'])>>> next(g)('E:\Python\script\函數\test\aa\bb2', [], ['file3.txt'])>>> next(g)Traceback (most recent call last): File "", line 1, in
我們在打開文件的時候需要找到文件的絕對路徑,現在可以通過字符串拼接的方法把第一部分和第三部分進行拼接。
用循環打開:
import osdir_g = os.walk(r"E:Pythonscript函數 est")for dir_path in dir_g: print(dir_path)
結果:
('E:\Python\script\函數\test', ['aa'], [])('E:\Python\script\函數\test\aa', ['bb1', 'bb2'], ['file1.txt'])('E:\Python\script\函數\test\aa\bb1', [], ['file2.txt'])('E:\Python\script\函數\test\aa\bb2', [], ['file3.txt'])
將查詢出來的文件和路徑進行拼接,拼接成絕對路徑
import osdir_g = os.walk(r"E:Pythonscript函數 est")for dir_path in dir_g: for file in dir_path[2]: file = "%s\%s" %(dir_path[0],file) print(file)
執行結果:
E:Pythonscript函數testaaile1.txtE:Pythonscript函數testaab1ile2.txtE:Pythonscript函數testaab2ile3.txt
用函數實現:
import osdef search(): while True: dir_name = yield dir_g = os.walk(dir_name) for dir_path in dir_g: for file in dir_path[2]: file = "%s\%s" %(dir_path[0],file) print(file)g = search()next(g)g.send(r"E:Pythonscript函數 est")
為了把結果返回給下一流程
@init # 初始化生成器def search(target): while True: dir_name = yield dir_g = os.walk(dir_name) for pardir,_,files in dir_g: for file in files: abspath = r"%s%s" %(pardir,file) target.send(abspath)
第二階段:打開文件
@initdef opener(target): while True: abspath=yield with open(abspath,'rb') as f: target.send((abspath,f))
第三階段:循環讀出每一行內容
@initdef cat(target): while True: abspath,f=yield #(abspath,f) for line in f: res=target.send((abspath,line)) if res:break
第四階段:過濾
@initdef grep(pattern,target): tag=False while True: abspath,line=yield tag tag=False if pattern in line: target.send(abspath) tag=True
第五階段:打印該行屬于的文件名
@initdef printer(): while True: abspath=yield print(abspath)g = search(opener(cat(grep('error'.encode('utf-8'), printer()))))g.send(r'E:Pythonscript函數 est')
執行結果:
E:Pythonscript函數testaaile1.txtE:Pythonscript函數testaab2ile3.txt
-
自動化
+關注
關注
29文章
5512瀏覽量
79106 -
函數
+關注
關注
3文章
4306瀏覽量
62430 -
python
+關注
關注
56文章
4782瀏覽量
84453
原文標題:Python自動化運維之高級函數
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
配電自動化實用化運維指標研究
厲害了!山東電力運維自動化平臺正式投運
Ansible企業級自動化運維探索的詳細資料說明
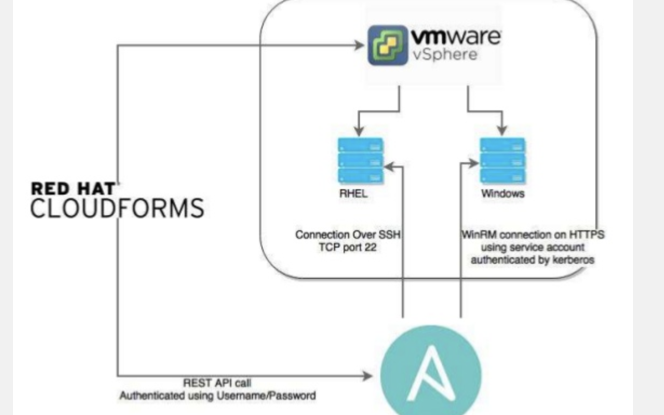
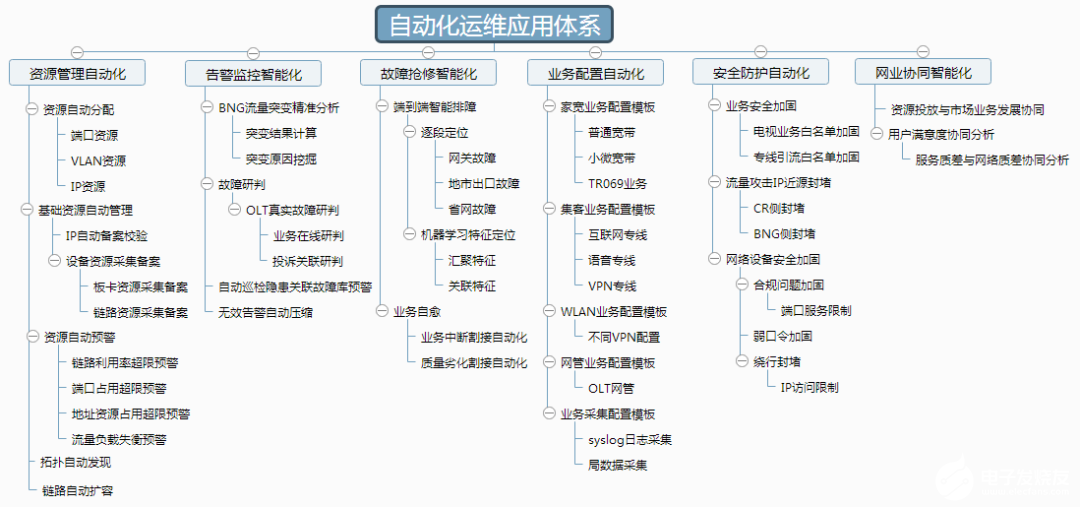
城域網是什么,其生命周期和自動化運維應用有哪些特點
Python后端項目的協程是什么
Python協程與JavaScript協程的對比及經驗技巧
協程的概念及協程的掛起函數介紹

網絡設備自動化運維工具—ansible入門筆記介紹





 工商網監
工商網監
評論