 一種改進的前饋序列記憶神經網絡結構
一種改進的前饋序列記憶神經網絡結構
在語音頂會ICASSP,阿里巴巴語音交互智能團隊的poster論文提出一種改進的前饋序列記憶神經網絡結構,稱之為深層前饋序列記憶神經網絡(DFSMN)。研究人員進一步將深層前饋序列記憶神經網絡和低幀率(LFR)技術相結合,構建LFR-DFSMN語音識別聲學模型。
該模型在大詞匯量的英文識別和中文識別任務上都可以取得相比于目前最流行的基于長短時記憶單元的雙向循環神經網絡(BLSTM)的識別系統顯著的性能提升。而且LFR-DFSMN在訓練速度,模型參數量,解碼速度,而且模型的延時上相比于BLSTM都具有明顯的優勢。
研究背景
近年來, 深度神經網絡成為了大詞匯量連續語音識別系統中的主流聲學模型。由于語音信號具有很強的長時相關性,因而目前普遍流行的是使用具有長時相關建模的能力的循環神經網絡(RNN),例如LSTM以及其變形結構。循環神經網絡雖然具有很強的建模能力,但是其訓練通常采用BPTT算法,存在訓練速度緩慢和梯度消失問題。我們之前的工作,提出了一種新穎的非遞歸的網絡結構,稱之為前饋序列記憶神經網絡(feedforward sequential memory networks, FSMN),可以有效的對信號中的長時相關性進行建模。相比于循環神經網絡,FSMN訓練更加高效,而且可以獲得更好的性能。
本論文,我們在之前FSMN的相關工作的基礎上進一步提出了一種改進的FSMN結構,稱之為深層的前饋序列記憶神經網絡(Deep-FSMN, DFSMN)。我們通過在FSMN相鄰的記憶模塊之間添加跳轉連接(skip connections),保證網絡高層梯度可以很好的傳遞給低層,從而使得訓練很深的網絡不會面臨梯度消失的問題。進一步的,考慮到將DFSMN應用于實際的語音識別建模任務不僅需要考慮模型的性能,而且需要考慮到模型的計算量以及實時性。針對這個問題,我們提出將DFSMN和低幀率(lower frame rate,LFR)相結合用于加速模型的訓練和測試。同時我們設計了DFSMN的結構,通過調整DFSMN的記憶模塊的階數實現時延的控制,使得基于LFR-DFSMN的聲學模型可以被應用到實時的語音識別系統中。
我們在多個大詞匯量連續語音識別任務包括英文和中文上驗證了DFSMN的性能。在目前流行的2千小時英文FSH任務上,我們的DFSMN相比于目前主流的BLSTM可以獲得絕對1.5%而且模型參數量更少。在2萬小時的中文數據庫上,LFR-DFSMN相比于LFR-LCBLSTM可以獲得超過20%的相對性能提升。而且LFR-DFSMN可以靈活的控制時延,我們發現將時延控制到5幀語音依舊可以獲得相比于40幀時延的LFR-LCBLSTM更好的性能。
FSMN回顧
最早提出的FSMN的模型結構如圖1(a)所示,其本質上是一個前饋全連接神經網絡,通過在隱層旁添加一些記憶模塊(memory block)來對周邊的上下文信息進行建模,從而使得模型可以對時序信號的長時相關性進行建模。FSMN的提出是受到數字信號處理中濾波器設計理論的啟發:任何無限響應沖擊(Infinite Impulse Response, IIR)濾波器可以采用高階的有限沖擊響應(Finite Impulse Response, FIR)濾波器進行近似。從濾波器的角度出發,如圖1(c)所示的RNN模型的循環層就可以看作如圖1(d)的一階IIR濾波器。而FSMN采用的采用如圖1(b)所示的記憶模塊可以看作是一個高階的FIR濾波器。從而FSMN也可以像RNN一樣有效的對信號的長時相關性進行建模,同時由于FIR濾波器相比于IIR濾波器更加穩定,因而FSMN相比于RNN訓練上會更加簡單和穩定。
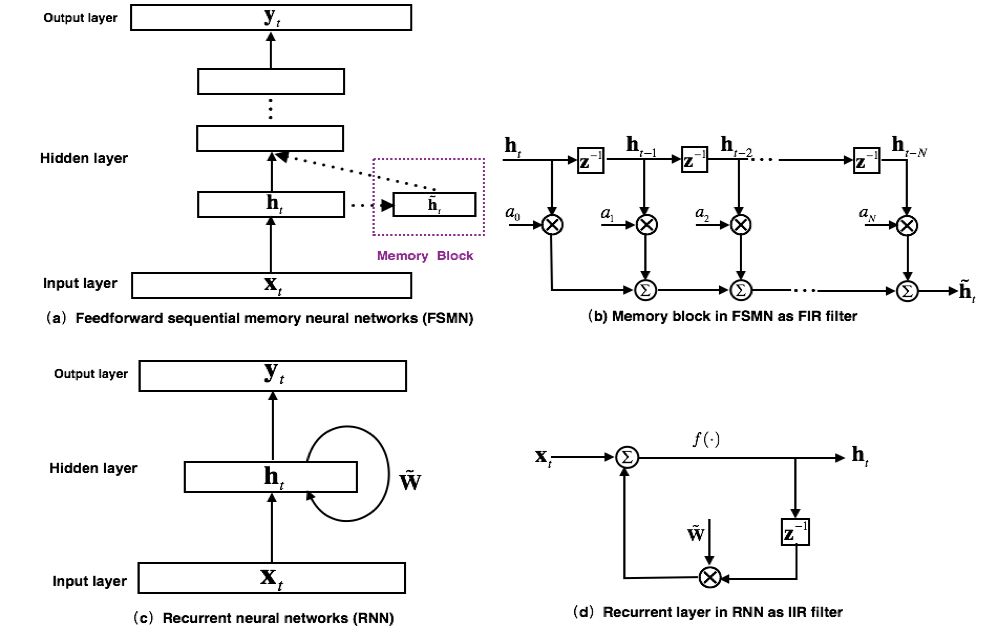
圖 1. FSMN模型結構以及和RNN的對比
根據記憶模塊編碼系數的選擇,可以分為:1)標量FSMN(sFSMN);2)矢量FSMN(vFSMN)。sFSMN 和 vFSMN 顧名思義就是分別使用標量和矢量作為記憶模塊的編碼系數。sFSMN和vFSMN記憶模塊的表達分別如下公式:
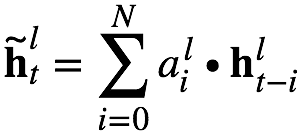
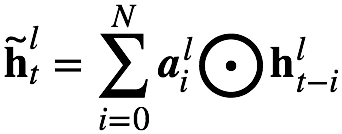
以上的FSMN只考慮了歷史信息對當前時刻的影響,我們可以稱之為單向的FSMN。當我們同時考慮歷史信息以及未來信息對當前時刻的影響時,我們可以將單向的FSMN進行擴展得到雙向的FSMN。雙向的sFSMN和vFSMN記憶模塊的編碼公式如下:
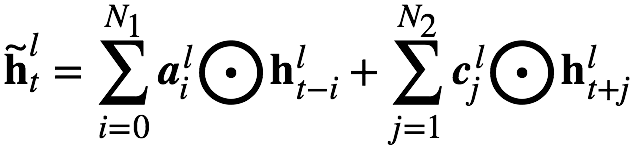
這里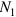 和?
和?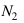 分別代表回看(look-back)的階數和向前看(look-ahead)的階數。我們可以通過增大階數,也可以通過在多個隱層添加記憶模塊來增強FSMN對長時相關性的建模能力。
分別代表回看(look-back)的階數和向前看(look-ahead)的階數。我們可以通過增大階數,也可以通過在多個隱層添加記憶模塊來增強FSMN對長時相關性的建模能力。
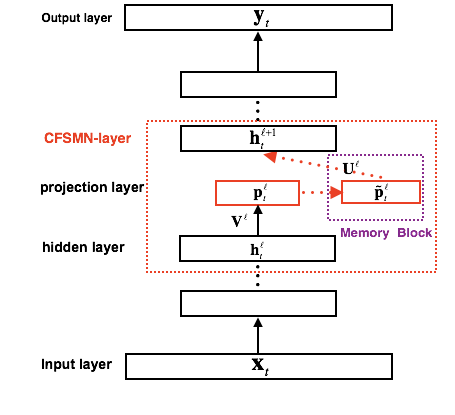
圖 2. cFSMN結構框圖
FSMN相比于FNN,需要將記憶模塊的輸出作為下一個隱層的額外輸入,這樣就會引入額外的模型參數。隱層包含的節點越多,則引入的參數越多。我們通過結合矩陣低秩分解(Low-rank matrix factorization)的思路,提出了一種改進的FSMN結構,稱之為簡潔的FSMN(Compact FSMN,cFSMN)。如圖2是一個第l個隱層包含記憶模塊的cFSMN的結構框圖。
對于cFSMN,通過在網絡的隱層后添加一個低維度的線性投影層,并且將記憶模塊添加在這些線性投影層上。進一步的,cFSMN對記憶模塊的編碼公式進行了一些改變,通過將當前時刻的輸出顯式的添加到記憶模塊的表達中,從而只需要將記憶模塊的表達作為下一層的輸入。這樣可以有效的減少模型的參數量,加快網絡的訓練。具體的,單向和雙向的cFSMN記憶模塊的公式表達分別如下:
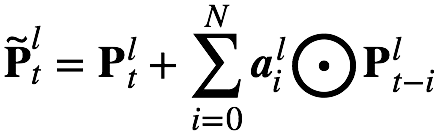
DFSMN介紹
圖 3. Deep-FSMN (DFSMN)模型結構框圖
如圖3是我們進一步提出的Deep-FSMN(DFSMN)的網絡結構框圖,其中左邊第一個方框代表輸入層,右邊最后一個方框代表輸出層。我們通過在cFSMN的記憶模塊(紅色框框表示)之間添加跳轉連接(skip connection),從而使得低層記憶模塊的輸出會被直接累加到高層記憶模塊里。這樣在訓練過程中,高層記憶模塊的梯度會直接賦值給低層的記憶模塊,從而可以克服由于網絡的深度造成的梯度消失問題,使得可以穩定的訓練深層的網絡。我們對記憶模塊的表達也進行了一些修改,通過借鑒擴張(dilation)卷積[3]的思路,在記憶模塊中引入一些步幅(stride)因子,具體的計算公式如下:
其中 表示第
表示第 ?層記憶模塊第t個時刻的輸出。
?層記憶模塊第t個時刻的輸出。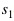 和
和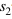 分別表示歷史和未來時刻的編碼步幅因子,例如 則表示對歷史信息進行編碼時每隔一個時刻取一個值作為輸入。這樣在相同的階數的情況下可以看到更遠的歷史,從而可以更加有效的對長時相關性進行建模。對于實時的語音識別系統我們可以通過靈活的設置未來階數來控制模型的時延,在極端情況下,當我們將每個記憶模塊的未來階數都設置為0,則我們可以實現無時延的一個聲學模型。對于一些任務,我們可以忍受一定的時延,我們可以設置小一些的未來階數。
分別表示歷史和未來時刻的編碼步幅因子,例如 則表示對歷史信息進行編碼時每隔一個時刻取一個值作為輸入。這樣在相同的階數的情況下可以看到更遠的歷史,從而可以更加有效的對長時相關性進行建模。對于實時的語音識別系統我們可以通過靈活的設置未來階數來控制模型的時延,在極端情況下,當我們將每個記憶模塊的未來階數都設置為0,則我們可以實現無時延的一個聲學模型。對于一些任務,我們可以忍受一定的時延,我們可以設置小一些的未來階數。
LFR-DFSMN聲學模型
目前的聲學模型,輸入的是每幀語音信號提取的聲學特征,每幀語音的時長通常為10ms,對于每個輸入的語音幀信號會有相對應的一個輸出目標。最近有研究提出一種低幀率(Low Frame Rate,LFR)建模方案:通過將相鄰時刻的語音幀進行綁定作為輸入,去預測這些語音幀的目標輸出得到的一個平均輸出目標。具體實驗中可以實現三幀(或更多幀)拼接而不損失模型的性能。從而可以將輸入和輸出減少到原來的三分之一甚至更多,可以極大的提升語音識別系統服務時聲學得分的計算以及解碼的效率。我們結合LFR和以上提出的DFSMN,構建了如圖4的基于LFR-DFSMN的語音識別聲學模型,經過多組實驗我們最終確定了采用一個包含10層DFSMN層+2層DNN的DFSMN作為聲學模型,輸入輸出則采用LFR,將幀率降低到原來的三分之一。
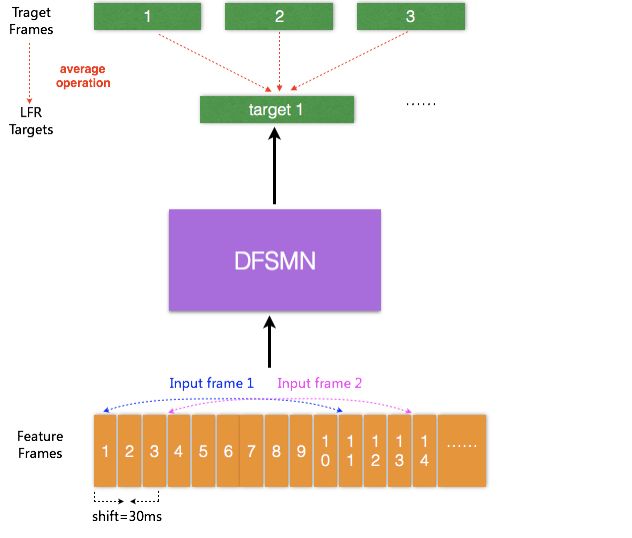
圖 4. LFR-DFSMN聲學模型結構框圖
實驗結果
英文識別
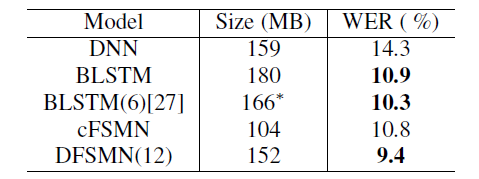
我們在2千小時的英文FSH任務上驗證所提出的DFSMN模型。我們首先驗證了DFSMN的網絡深度對性能的影響,我們分別驗證了DFSMN包含6,8,10,12個DFSMN層的情況。最終模型的識別性能如下表。通過增加網絡的深度我們可以獲得一個明顯的性能提升。
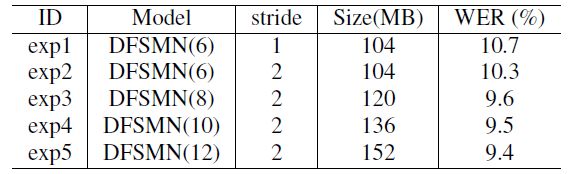
我們也和一些主流的聲學模型進行了對比,結果如下表。從結果看DFSMN相比于目前最流行的BLSTM不僅參數量更少,而且性能上可以獲得1.5%的絕對性能提升。
2. 中文識別
關于中文識別任務,我們首先在5000小時任務上進行實驗。我們分別驗證了采用綁定的音素狀態(CD-State)和綁定的音素(CD-Phone)作為輸出層建模單元。關于聲學模型我們對比了時延可控的BLSTM(LCBLSTM),cFSMN以及DFSMN。對于LFR模型,我們采用CD-Phone作為建模單元。詳細的實驗結果如下表:
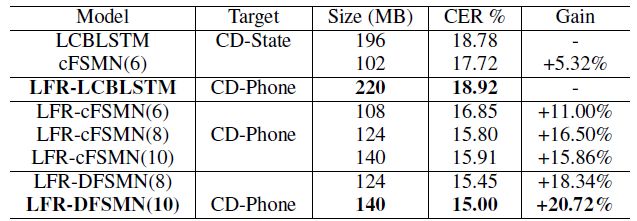
對于基線LCBSLTM,采用LFR相比于傳統的單幀預測在性能上相近,優點在效率可以提升3倍。而采用LFR的cFSMN,相比于傳統的單幀預測不僅在效率上可以獲得相應提升,而且可以獲得更好的性能。這主要是LFR一定程度上破壞了輸入信號的時序性,而BLSTM的記憶機制對時序性更加的敏感。進一步的我們探索了網絡深度對性能的影響,對于之前的cFSMN網絡,當把網絡深度加深到10層,會出現一定的性能下降。而對于我們最新提出來的DFSMN,10層的網絡相比于8層依舊可以獲得性能提升。最終相比于基線的LFR-LCBLSTM模型,我們可以獲得超過20%的相對性能提升。
下表我們對比了LFR-DFSMN和LFR-LCBLSTM的訓練時間,以及解碼的實時因子(RTF)。從結果上看我們可以將訓練速度提升3倍,同時可以將實時因子降低到原來的接近三分之一。

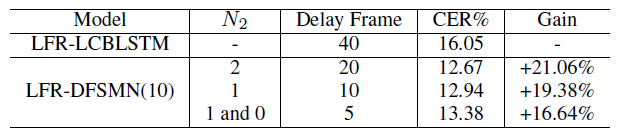
對于語音識別系統,另外一個需要考慮的因素是模型的延遲問題。原始的BLSTM需要等接收整句話后才能得到輸出用于解碼。LCBLSTM是目前的一種改進結構,可以將解碼的時延進行控制,目前采用的LFR-LCBLSTM的時延幀數是40幀。對于DFSMN,時延的幀數可以功過設計記憶模塊的濾波器階數進行靈活控制。最終當只有5幀延時時,LFR-DFSMN相比于LFR-LCBLSTM依然可以獲得更好的性能。
-
神經網絡
+關注
關注
42文章
4764瀏覽量
100542 -
語音識別
+關注
關注
38文章
1724瀏覽量
112548
原文標題:顯著超越流行長短時記憶網絡,阿里提出DFSMN語音識別聲學模型
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
神經網絡結構搜索有什么優勢?
一種新型神經網絡結構:膠囊網絡
一種神經網絡結構改進方法「ReZero」






 工商網監
工商網監
評論