 深度學習模型介紹,Attention機制和其它改進
深度學習模型介紹,Attention機制和其它改進
深度學習模型介紹
DeepDive系統在數據處理階段很大程度上依賴于NLP工具,如果NLP的過程中存在錯誤,這些錯誤將會在后續的標注和學習步驟中被不斷傳播放大,影響最終的關系抽取效果。為了避免這種傳播和影響,近年來深度學習技術開始越來越多地在關系抽取任務中得到重視和應用。本章主要介紹一種遠程監督標注與基于卷積神經網絡的模型相結合的關系抽取方法以及該方法的一些改進技術。
Piecewise Convolutional Neural Networks(PCNNs)模型
PCNNs模型由Zeng et al.于2015提出,主要針對兩個問題提出解決方案:
針對遠程監督的wrong label problem,該模型提出采用多示例學習的方式從訓練集中抽取取置信度高的訓練樣例訓練模型。
針對傳統統計模型特征抽取過程中出現的錯誤和后續的錯誤傳播問題,該模型提出用 piecewise 的卷積神經網絡自動學習特征,從而避免了復雜的NLP過程。
下圖是PCNNs的模型示意圖:
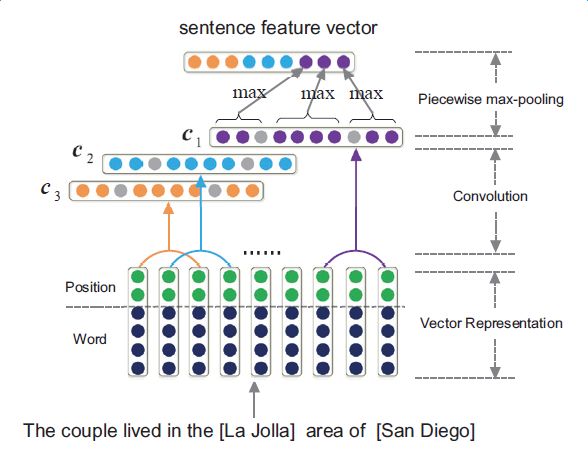
PCNNs模型主要包括以下幾個步驟:




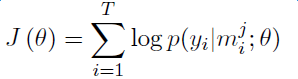
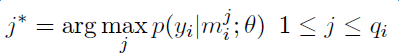
實驗證明,PCNNs + 多實例學習的方法 Top N 上平均值比單純使用多示例學習的方法高了 5 個百分點。
Attention機制和其它改進
上述模型對于每個實體對只選用一個句子進行學習和預測,損失了大量的來自其它正確標注句子的信息。為了在濾除wrong label case的同時,能更有效地利用盡量多的正確標注的句子,Lin et al. 于2016年提出了PCNNs+Attention(APCNNs)算法。相比之前的PCNNs模型,該算法在池化層之后,softmax層之前加入了一種基于句子級別的attention機制,算法的示意圖如下:
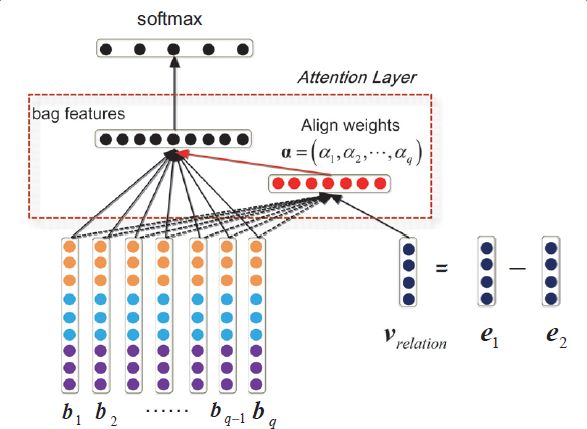

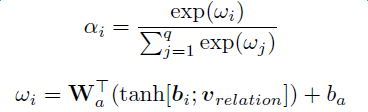

除了Attention機制外,還有一些其它的輔助信息也被加入多示例學習模型來改關系抽取的質量,例如在計算實體向量的時候加入實體的描述信息(Ji et al.,2017);利用外部神經網絡獲取數據的可靠性和采樣的置信度等信息對模型的訓練進行指導(Tang et al.,2017)。
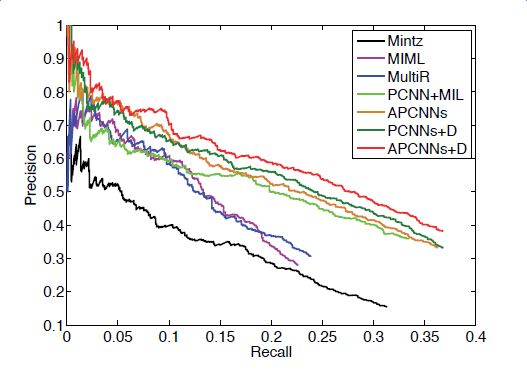
下圖顯示了各模型和改進算法的準確率和召回率的對比,其中Mintz不對遠程監督的wrong label problem做處理,直接用所有標注樣例進行訓練;MultiR和MIML是采用概率圖模型進行示例篩選的兩種多示例學習模型;PCNN+MIL是本章第一小節介紹的模型;APCNNs 在PCNN+MIL基礎上添加了attention機制;PCNNs+D在PCNN+MIL基礎上添加了對描述信息的使用;APCNNs+D在APCNNs基礎上添加了對描述信息的使用。實驗采用的是該領域評測中使用較廣泛的New York Times(NYT)數據集(Riedel et al.,2010)。
深度學習方法在圖譜構建中的應用進展
深度學習模型在神馬知識圖譜數據構建中的應用目前還處于探索階段,本章將介紹當前的工作進展和業務落地過程中遇到的一些問題。
語料準備和實體向量化
深度學習模型較大程度依賴于token向量化的準確性。與基于DeepDive方法的語料準備相同,這里的token切分由以詞為單位,改為以實體為單位,以NER環節識別的實體粒度為準。Word2vec生成的向量表征token的能力與語料的全面性和語料的規模都很相關,因此我們選擇百科全量語料作為word2vec的訓練語料,各統計數據和模型參數設置如下表所示:

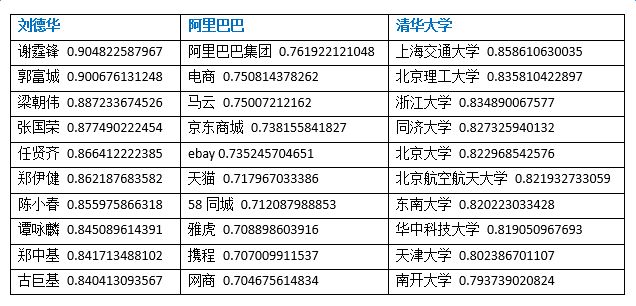
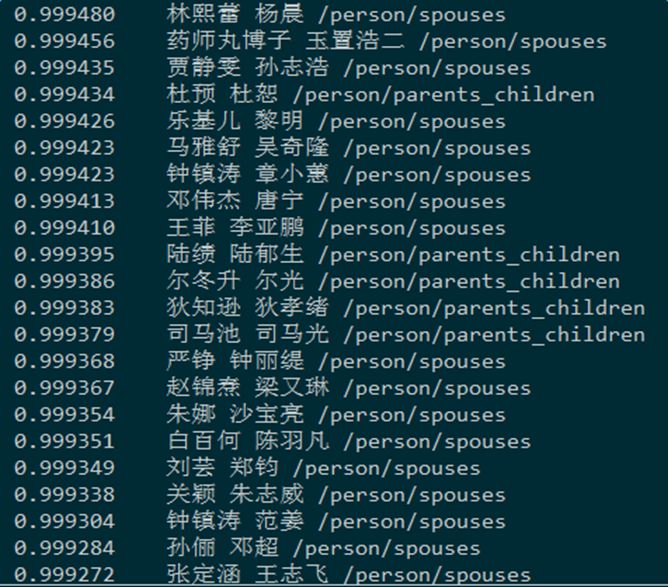
為了驗證詞向量訓練的效果,我們對word2vec的結果做了多種測試,這里給出部分實驗數據。下圖所示的是給定一個實體,查找最相關實體的實驗:
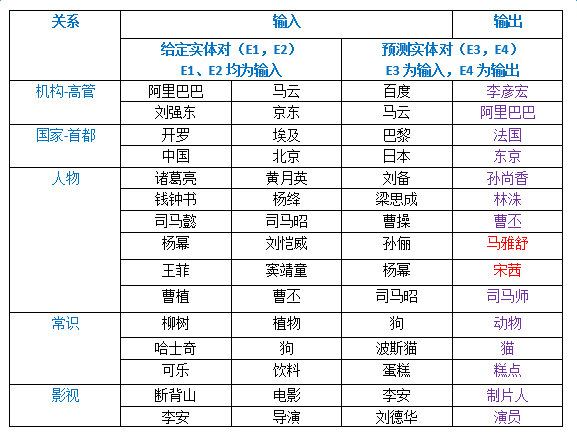
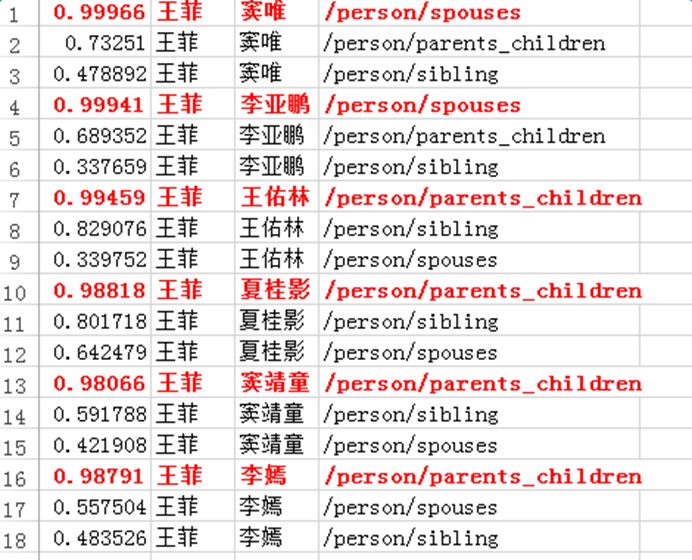
以下是給定一個實體對和預測實體對的其中一個實體,計算預測實體對中另一個實體的實驗。隨機選取了五種預測關系,構造了15組給定實體對和預測實體對,預測結果如下圖所示,除了飄紅的兩個例子,其余預測均正確:
模型選取與訓練數據準備
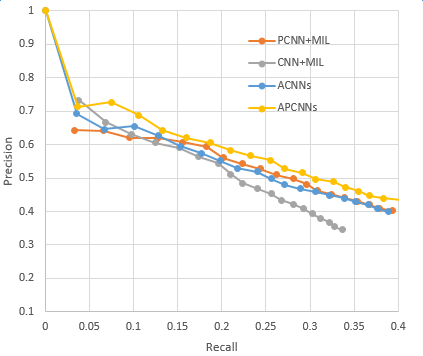
具體應用中我們選擇采用APCNNs模型。我們在NYT標準數據集上復現了上一章提到的幾種關鍵模型,包括CNN+MIL,PCNN+MIL,CNNs(基于Attention機制的CNN模型)和APCNNs。復現結果與論文中給出的baseline基本一致,APCNNs模型的表現明顯優于其它模型。下圖是幾種模型的準召結果對比:
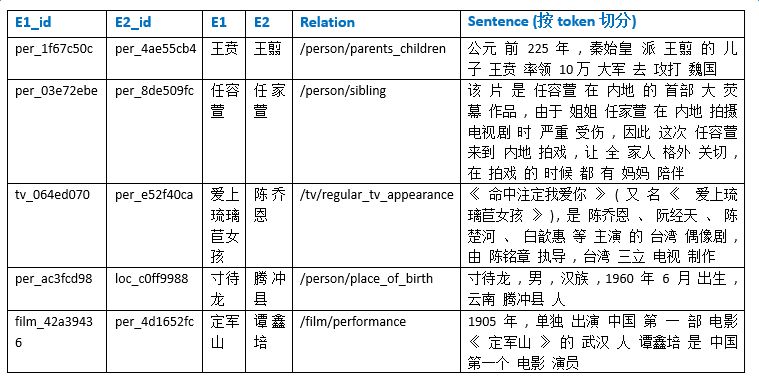
為了得到豐富的訓練數據,我們取知識圖譜中建設相對完善的人物、地理位置、組織機構、電影、電視、圖書等領域下的15個核心關系,如電影演員、圖書作者、公司高管、人物出生地等,對照百科全量語料,產出relation值為15個關系之一的標注正例,合計數目在千萬量級,產出無relation值標注(relation值為NA)的示例超過1億。
應用嘗試和問題分析


APCNNs模型在輔助知識圖譜數據構建中目前還處于嘗試階段。就運算能力而言,APCNNs模型相比DeepDive系統更有優勢,能在大規模語料上同時針對多個關系進行計算,且迭代更新過程無需人工校驗交互。但在業務落地過程中,我們也遇到了一些問題,總結如下:
大規模實驗耗時過長,給參數的調整和每一次算法策略上的迭代增加了難度
目前學術界通用的測試語料是英文的NYT數據集,相同的模型應用于中文語料時,存在準召率對標困難的問題
深度學習的過程人工難以干預。假設我們要預測(楊冪,劉愷威)的婚姻關系,但從最初的基于大規模語料的詞向量生成開始,如果該語料中(楊冪,劉愷威)共現時的主導關系就不是婚姻關系,而是影視劇中的合作關系(如“該片講述楊冪飾演的夏晚晴在遭遇好友算計、男友婚變的窘境下,被劉愷威飾演的花花公子喬津帆解救,但卻由此陷入更大圈套的故事。”),或基于某些活動的共同出席關系(如“楊冪與劉愷威共同擔任了新浪廈門愛心圖書館的公益大使”),則在attention步驟中得到的關系向量就會偏向合作關系,這將導致計算包中每個句子的權值時,表達婚姻關系的句子難以獲得高分,從而導致后續學習中的偏差。
深度學習模型的結果較難進行人工評測,尤其對于知識圖譜中沒有出現的實體對,需要在大規模的中間過程矩陣中進行匹配和提取,將權重矩陣可視化為包中每個句子的得分,對計算資源和人工都有不小的消耗。
總結與展望
基于DeepDive的方法和基于深度學習的方法各有優勢和缺陷,以下從4個方面對這兩種方法進行總結和對比:
1、 語料的選取和范圍
Deepdive可適用于較小型、比較專門的語料,例如歷史人物的關系挖掘;可以針對語料和抽取關系的特點進行調整規則,如婚姻關系的一對一或一對多,如偏文言文的語料的用語習慣等。
APCNNs模型適用于大規模語料,因為attention機制能正常運行的前提是word2vec學習到的實體向量比較豐富全面。
2、 關系抽取
Deepdive僅適用于單一關系的判斷,分類結果為實體對間某一關系成立的期望值。針對不同的關系,可以運營不同的規則,通過基于規則的標注能較好地提升訓練集的標注準確率。
APCNNs模型適用于多分類問題,分類結果為relation集合中的關系得分排序。無需針對relation集合中特定的某個關系做規則運營。
3、 長尾數據
Deepdive更適用于長尾數據的關系挖掘,只要是NER能識別出的實體對,即使出現頻率很低,也能根據該實體對的上下文特征做出判斷。
APCNNs模型需要保證實體在語料中出現的次數高于一定的閾值,如min_count>=5,才能保證該實體有word2vec的向量表示。bag中有一定數量的sentence,便于選取相似度高的用于訓練
4、 結果生成與檢測
Deepdive對輸出結果正誤的判斷僅針對單個句子,同樣的實體對出現在不同的句子中可能給出完全不同的預測結果。測試需要結合原句判斷結果是否準確,好處是有原句作為依據,方便進行人工驗證。
APCNNs模型針對特定的實體對做判斷,對于給定的實體對,系統給出一致的輸出結果。對于新數據的結果正確性判斷,需要結合中間結果,對包中被選取的句子集合進行提取和驗證,增加了人工檢驗有的難度。
在未來的工作中,對于基于DeepDive的方法,我們在擴大抓取關系數目的同時,考慮將業務實踐中沉淀的改進算法流程化、平臺化,同時構建輔助的信息增補工具,幫助減輕DeepDive生成結果寫入知識圖譜過程中的人工檢驗工作,例如,對于婚姻關系的實體對,我們可以從圖譜獲取人物的性別、出生年月等信息,來輔助關系的正誤判斷。
對于基于深度學習的方法,我們將投入更多的時間和精力,嘗試從以下幾方面促進業務的落地和模型的改進:
將已被DeepDive證明有效的某些改進算法應用到深度學習方法中,例如根據關系相關的關鍵詞進行過濾,縮小數據規模,提高運行效率。
將計算中間結果可視化,分析attention過程中關系向量與sentence選取的關聯,嘗試建立選取結果好壞的評判機制,嘗試利用更豐富的信息獲得更準確的關系向量。
考慮如何突破預先設定的關系集合的限制,面向開放領域進行關系抽取,自動發現新的關系和知識。
探索除了文本以外其它形式數據的關系抽取,如表格、音頻、圖像等。
-
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
深度學習
+關注
關注
73文章
5493瀏覽量
121000
原文標題:首次公開:深度學習在阿里知識圖譜構建中的應用
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何才能高效地進行深度學習模型訓練?
深度學習模型是如何創建的?
什么是深度學習?使用FPGA進行深度學習的好處?
Attention的具體原理詳解
為什么要有attention機制,Attention原理






 工商網監
工商網監
評論