") 比谷歌快46倍!GPU助力IBM Snap ML,40億樣本訓(xùn)練模型僅需91.5秒
比谷歌快46倍!GPU助力IBM Snap ML,40億樣本訓(xùn)練模型僅需91.5秒
近日,IBM 宣布他們使用一組由 Criteo Labs發(fā)布的廣告數(shù)據(jù)集來(lái)訓(xùn)練邏輯回歸分類(lèi)器,在POWER9服務(wù)器和GPU上運(yùn)行自身機(jī)器學(xué)習(xí)庫(kù)Snap ML,結(jié)果比此前來(lái)自谷歌的最佳成績(jī)快了46倍。
英偉達(dá)CEO黃仁勛和IBM 高級(jí)副總裁John Kelly在Think大會(huì)上
最近,在拉斯維加斯的IBM THINK大會(huì)上,IBM宣布,他們利用優(yōu)化的硬件上的新軟件和算法,取得了AI性能的大突破,包括采用 POWER9 和NVIDIA?V100?GPU 的組合。
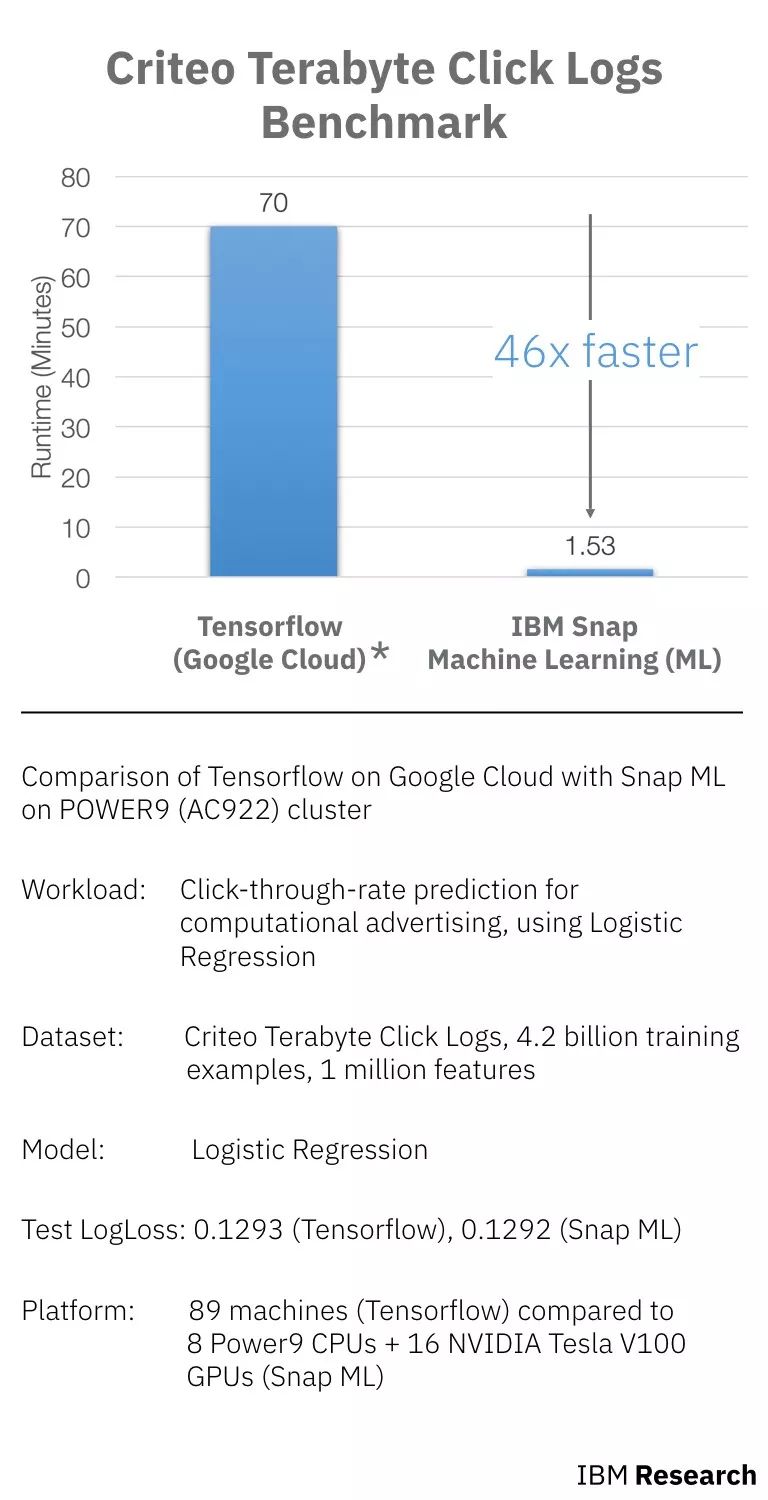
谷歌云上TensorFlow和POWER9 (AC922)cluster上IBM Snap的對(duì)比(runtime包含數(shù)據(jù)加載的時(shí)間和訓(xùn)練的時(shí)間)
如上圖所示,workload、數(shù)據(jù)集和模型都是相同的,對(duì)比的是在Google Cloud上使用TensorFlow進(jìn)行訓(xùn)練和在Power9上使用Snap ML訓(xùn)練的時(shí)間。其中,TensorFlow使用了89臺(tái)機(jī)器(60臺(tái)工作機(jī)和29臺(tái)參數(shù)機(jī)),Snap ML使用了9個(gè) Power9 CPU和16個(gè)NVIDIA Tesla V100 GPU。
相比 TensorFlow,Snap ML 獲得相同的損失,但速度快了 46 倍。
怎么實(shí)現(xiàn)的?
Snap ML:居然比TensorFlow快46倍
早在去年二月份,谷歌軟件工程師Andreas Sterbenz寫(xiě)了一篇關(guān)于使用谷歌Cloud ML和TensorFlow進(jìn)行大規(guī)模預(yù)測(cè)廣告和推薦場(chǎng)景的點(diǎn)擊次數(shù)的博客。
Sterbenz訓(xùn)練了一個(gè)模型,以預(yù)測(cè)在Criteo Labs中顯示的廣告點(diǎn)擊量,這些日志大小超過(guò)1TB,并包含來(lái)自數(shù)百萬(wàn)展示廣告的特征值和點(diǎn)擊反饋。
數(shù)據(jù)預(yù)處理(60分鐘)之后是實(shí)際學(xué)習(xí),使用60臺(tái)工作機(jī)和29臺(tái)參數(shù)機(jī)進(jìn)行培訓(xùn)。該模型花了70分鐘訓(xùn)練,評(píng)估損失為0.1293。
雖然Sterbenz隨后使用不同的模型來(lái)獲得更好的結(jié)果,減少了評(píng)估損失,但這些都花費(fèi)更長(zhǎng)的時(shí)間,最終使用具有三次epochs(度量所有訓(xùn)練矢量一次用來(lái)更新權(quán)重的次數(shù))的深度神經(jīng)網(wǎng)絡(luò),耗時(shí)78小時(shí)。
但是IBM在POWER9服務(wù)器和GPU上運(yùn)行的自身訓(xùn)練庫(kù)后,可以在基本的初始訓(xùn)練上勝過(guò)谷歌Cloud Platform上的89臺(tái)機(jī)器。
他們展示了一張顯示Snap ML、Google TensorFlow和其他三個(gè)對(duì)比結(jié)果的圖表:
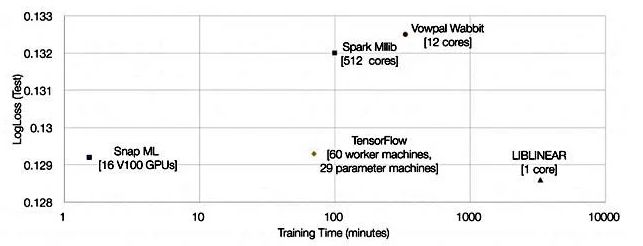
比TensorFlow快46倍,是怎么做到的?
研究人員表示,Snap ML具有多層次的并行性,可以在集群中的不同節(jié)點(diǎn)間分配工作負(fù)載,利用加速器單元,并利用各個(gè)計(jì)算單元的多核并行性。
1. 首先,數(shù)據(jù)分布在集群中的各個(gè)工作節(jié)點(diǎn)上。
2. 在節(jié)點(diǎn)上,數(shù)據(jù)在CPU和GPU并行運(yùn)行的主CPU和加速GPU之間分離
3. 數(shù)據(jù)被發(fā)送到GPU中的多個(gè)核心,并且CPU工作負(fù)載是多線程的
Snap ML具有嵌套的分層算法(nested hierarchical algorithmic)功能,可以利用這三個(gè)級(jí)別的并行性。
簡(jiǎn)而言之,Snap ML的三個(gè)核心特點(diǎn)是:
分布式訓(xùn)練:Snap ML是一個(gè)數(shù)據(jù)并行的框架,能夠在大型數(shù)據(jù)集上進(jìn)行擴(kuò)展和訓(xùn)練,這些數(shù)據(jù)集可以超出單臺(tái)機(jī)器的內(nèi)存容量,這對(duì)大型應(yīng)用程序至關(guān)重要。
GPU加速:實(shí)現(xiàn)了專(zhuān)門(mén)的求解器,旨在利用GPU的大規(guī)模并行架構(gòu),同時(shí)保持GPU內(nèi)存中的數(shù)據(jù)位置,以減少數(shù)據(jù)傳輸開(kāi)銷(xiāo)。為了使這種方法具有可擴(kuò)展性,利用最近異構(gòu)學(xué)習(xí)的一些進(jìn)步,即使可以存儲(chǔ)在加速器內(nèi)存中的數(shù)據(jù)只有一小部分,也可以實(shí)現(xiàn)GPU加速。
稀疏數(shù)據(jù)結(jié)構(gòu):大部分機(jī)器學(xué)習(xí)數(shù)據(jù)集都是稀疏的,因此在應(yīng)用于稀疏數(shù)據(jù)結(jié)構(gòu),對(duì)系統(tǒng)中使用的算法進(jìn)行了一些新的優(yōu)化。
技術(shù)過(guò)程:在91.5秒內(nèi)實(shí)現(xiàn)了0.1292的測(cè)試損失
先對(duì)Tera-Scale Benchmark設(shè)置。
Terabyte Click Logs是由Criteo Labs發(fā)布的一個(gè)大型在線廣告數(shù)據(jù)集,用于分布式機(jī)器學(xué)習(xí)領(lǐng)域的研究。它由40億個(gè)訓(xùn)練樣本組成。
其中,每個(gè)樣本都有一個(gè)“標(biāo)簽”,即用戶是否點(diǎn)擊在線廣告,以及相應(yīng)的一組匿名特征。基于這些數(shù)據(jù)訓(xùn)練機(jī)器學(xué)習(xí)模型,其目標(biāo)是預(yù)測(cè)新用戶是否會(huì)點(diǎn)擊廣告。
這個(gè)數(shù)據(jù)集是目前最大的公開(kāi)數(shù)據(jù)集之一,數(shù)據(jù)在24天內(nèi)收集,平均每天收集1.6億個(gè)訓(xùn)練樣本。
為了訓(xùn)練完整的Terabyte Click Logs數(shù)據(jù)集,研究人員在4臺(tái)IBM Power System AC922服務(wù)器上部署Snap ML。每臺(tái)服務(wù)器都有4個(gè)NVIDIA Tesla V100 GPU和2個(gè)Power9 CPU,可通過(guò)NVIDIA NVLink接口與主機(jī)進(jìn)行通信。服務(wù)器通過(guò)Infiniband網(wǎng)絡(luò)相互通信。當(dāng)在這樣的基礎(chǔ)設(shè)施上訓(xùn)練邏輯回歸分類(lèi)器時(shí),研究人員在91.5秒內(nèi)實(shí)現(xiàn)了0.1292的測(cè)試損失。
再來(lái)看一遍前文中的圖:
在為這樣的大規(guī)模應(yīng)用部署GPU加速時(shí),出現(xiàn)了一個(gè)主要的技術(shù)挑戰(zhàn):訓(xùn)練數(shù)據(jù)太大而無(wú)法存儲(chǔ)在GPU上可用的存儲(chǔ)器中。因此,在訓(xùn)練期間,需要有選擇地處理數(shù)據(jù)并反復(fù)移入和移出GPU內(nèi)存。為了解釋?xiě)?yīng)用程序的運(yùn)行時(shí)間,研究人員分析了在GPU內(nèi)核中花費(fèi)的時(shí)間與在GPU上復(fù)制數(shù)據(jù)所花費(fèi)的時(shí)間。
在這項(xiàng)研究中,使用Terabyte Clicks Logs的一小部分?jǐn)?shù)據(jù),包括初始的2億個(gè)訓(xùn)練樣本,并比較了兩種硬件配置:
基于Intel x86的機(jī)器(Xeon Gold 6150 CPU @ 2.70GHz),帶有1個(gè)使用PCI Gen 3接口連接的NVIDIA Tesla V100 GPU。
使用NVLink接口連接4個(gè)Tesla V100 GPU的IBM POWER AC922服務(wù)器(在比較中,僅使用其中1個(gè)GPU)。
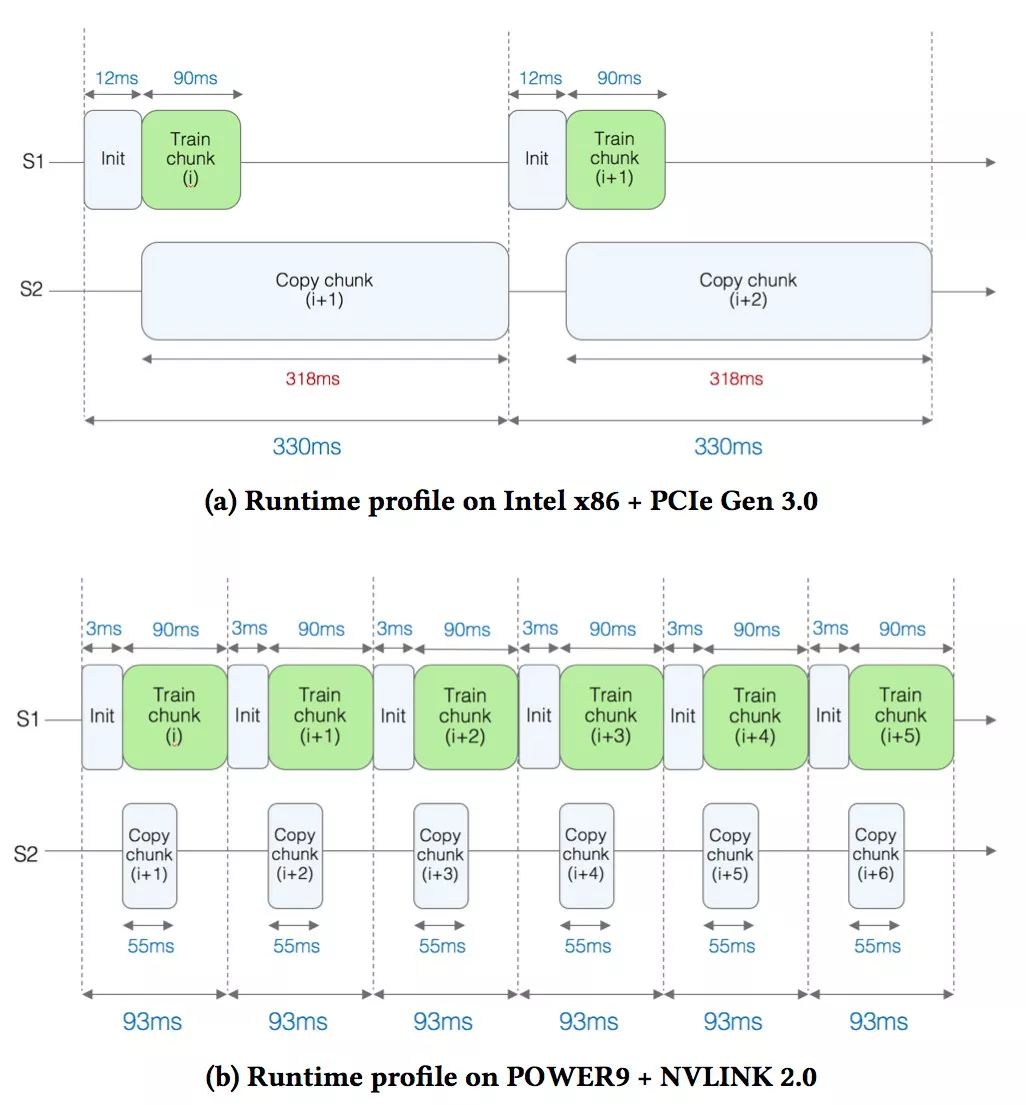
圖a顯示了基于x86的設(shè)置的性能分析結(jié)果。可以看到S1和S2這兩條線。在S1線上,實(shí)際的訓(xùn)練即將完成時(shí)(即,調(diào)用邏輯回歸內(nèi)核)。訓(xùn)練每個(gè)數(shù)據(jù)塊的時(shí)間大約為90毫秒(ms)。
當(dāng)訓(xùn)練正在進(jìn)行時(shí),在S2線上,研究人員將下一個(gè)數(shù)據(jù)塊復(fù)制到GPU上。觀察到復(fù)制數(shù)據(jù)需要318毫秒,這意味著GPU閑置了相當(dāng)長(zhǎng)的一段時(shí)間,復(fù)制數(shù)據(jù)的時(shí)間顯然是一個(gè)瓶頸。
在圖b中,對(duì)于基于POWER的設(shè)置,由于NVIDIA NVLink提供了更快的帶寬,因此下一個(gè)數(shù)據(jù)塊復(fù)制到GPU的時(shí)間顯著減少到55 ms(幾乎減少了6倍)。這種加速是由于將數(shù)據(jù)復(fù)制時(shí)間隱藏在內(nèi)核執(zhí)行后面,有效地消除了關(guān)鍵路徑上的復(fù)制時(shí)間,并實(shí)現(xiàn)了3.5倍的加速。
IBM的這個(gè)機(jī)器學(xué)習(xí)庫(kù)提供非常快的訓(xùn)練速度,可以在現(xiàn)代CPU / GPU計(jì)算系統(tǒng)上訓(xùn)練流主流的機(jī)器學(xué)習(xí)模型,也可用于培訓(xùn)模型以發(fā)現(xiàn)新的有趣模式,或者在有新數(shù)據(jù)可用時(shí)重新訓(xùn)練現(xiàn)有模型,以保持速度在線速水平(即網(wǎng)絡(luò)所能支持的最快速度)。這意味著更低的用戶計(jì)算成本,更少的能源消耗,更敏捷的開(kāi)發(fā)和更快的完成時(shí)間。
不過(guò),IBM研究人員并沒(méi)有聲稱(chēng)TensorFlow沒(méi)有利用并行性,并且也不提供Snap ML和TensorFlow之間的任何比較。
但他們的確說(shuō):“我們實(shí)施專(zhuān)門(mén)的解決方案,來(lái)利用GPU的大規(guī)模并行架構(gòu),同時(shí)尊重GPU內(nèi)存中的數(shù)據(jù)區(qū)域,以避免大量數(shù)據(jù)傳輸開(kāi)銷(xiāo)。”
文章稱(chēng),采用NVLink 2.0接口的AC922服務(wù)器,比采用其Tesla GPU的PCIe接口的Xeon服務(wù)器(Xeon Gold 6150 CPU @ 2.70GHz)要更快,PCIe接口是特斯拉GPU的接口。“對(duì)于基于PCIe的設(shè)置,我們測(cè)量的有效帶寬為11.8GB /秒,對(duì)于基于NVLink的設(shè)置,我們測(cè)量的有效帶寬為68.1GB /秒。”
訓(xùn)練數(shù)據(jù)被發(fā)送到GPU,并在那里被處理。NVLink系統(tǒng)以比PCIe系統(tǒng)快得多的速度向GPU發(fā)送數(shù)據(jù)塊,時(shí)間為55ms,而不是318ms。
IBM團(tuán)隊(duì)還表示:“當(dāng)應(yīng)用于稀疏數(shù)據(jù)結(jié)構(gòu)時(shí),我們對(duì)系統(tǒng)中使用的算法進(jìn)行了一些新的優(yōu)化。”
總的來(lái)說(shuō),似乎Snap ML可以更多地利用Nvidia GPU,在NVLink上傳輸數(shù)據(jù)比在x86服務(wù)器的PCIe link上更快。但不知道POWER9 CPU與Xeons的速度相比如何,IBM尚未公開(kāi)發(fā)布任何直接POWER9與Xeon SP的比較。
因此也不能說(shuō),在相同的硬件配置上運(yùn)行兩個(gè)suckers之前,Snap ML比TensorFlow好得多。
無(wú)論是什么原因,46倍的降幅都令人印象深刻,并且給了IBM很大的空間來(lái)推動(dòng)其POWER9服務(wù)器作為插入Nvidia GPU,運(yùn)行Snap ML庫(kù)以及進(jìn)行機(jī)器學(xué)習(xí)的場(chǎng)所。
-
谷歌
+關(guān)注
關(guān)注
27文章
6142瀏覽量
105115 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4765瀏覽量
100566 -
gpu
+關(guān)注
關(guān)注
28文章
4703瀏覽量
128725
原文標(biāo)題:比谷歌快46倍!GPU助力IBM Snap ML,40億樣本訓(xùn)練模型僅需91.5 秒
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
FPGA比CPU和GPU快的原理是什么

挑戰(zhàn)GPU,Habana推出四倍處理能力的AI訓(xùn)練芯片
matlab自學(xué)一本通(新版軟件+基礎(chǔ)教程+案例源碼)
在Ubuntu上使用Nvidia GPU訓(xùn)練模型
GPU如何訓(xùn)練大批量模型?方法在這里
阿里云圖像識(shí)別速度創(chuàng)紀(jì)錄,比AWS快2.36倍,比谷歌快5.28倍
YOLO的另一選擇,手機(jī)端97FPS的Anchor-Free目標(biāo)檢測(cè)模型NanoDet
一個(gè)GPU訓(xùn)練一個(gè)130億參數(shù)的模型
樣本量極少可以訓(xùn)練機(jī)器學(xué)習(xí)模型嗎?
NVIDIA GPU助力提升模型訓(xùn)練和推理性價(jià)比
形狀感知零樣本語(yǔ)義分割





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論