") 從FPN到Mask R-CNN,Facebook的計(jì)算機(jī)視覺有多強(qiáng)
從FPN到Mask R-CNN,Facebook的計(jì)算機(jī)視覺有多強(qiáng)
▌Feature Pyramid Networks( 特征金字塔網(wǎng)絡(luò))
首先,我們要介紹的是著名的特征金字塔網(wǎng)絡(luò)(這是發(fā)表在 CVPR 2017 上的一篇論文,以下簡(jiǎn)稱FPN)。
如果你在過去兩年有一直跟進(jìn)計(jì)算機(jī)視覺領(lǐng)域的最新進(jìn)展的話,那你一定聽說過這個(gè)網(wǎng)絡(luò)的大名,并和其他人一樣等待著作者開源這個(gè)項(xiàng)目。FPN 這篇論文提出的一種非常棒的思路。我們都知道,構(gòu)建一個(gè)多任務(wù)、多子主題、多應(yīng)用領(lǐng)域的基線模型是很困難的。
FPN 可以視為是一種擴(kuò)展的通用特征提取網(wǎng)絡(luò)(如 ResNet、DenseNet),你可以從深度學(xué)習(xí)模型庫中選擇你想要的預(yù)訓(xùn)練的 FPN 模型并直接使用它!
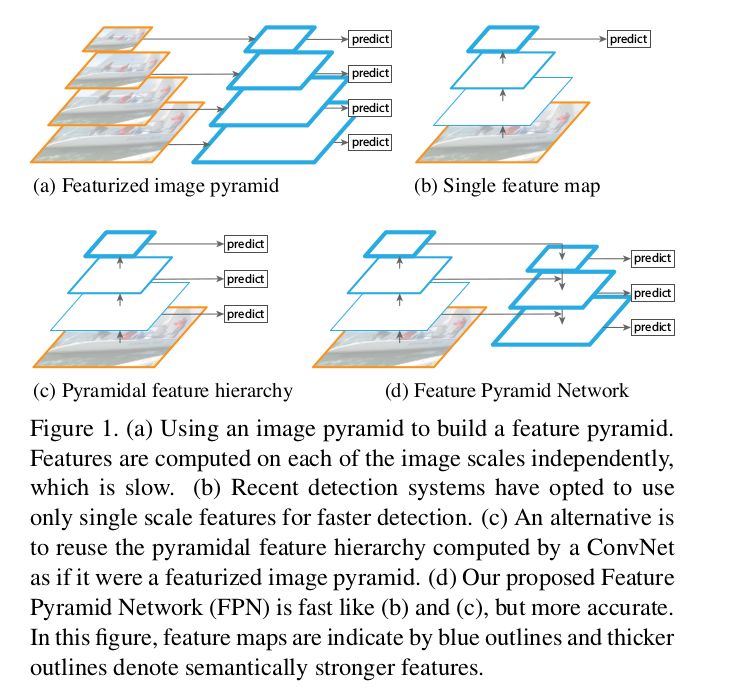
通常,圖像目標(biāo)有多個(gè)不同尺度和尺寸大小。一般的數(shù)據(jù)集無法捕捉所有的圖像屬性,因此人們使用圖像金字塔的方式,對(duì)圖像按多種分辨率進(jìn)行降級(jí),提取圖像特征,以方便 CNN 處理。但是,這種方法最大弊端是網(wǎng)絡(luò)處理的速度很慢,因此我們更喜歡使用單個(gè)圖像尺度進(jìn)行預(yù)測(cè),也就導(dǎo)致大量圖像特征的流失,如一部分研究者可能從特征空間的中間層獲取預(yù)測(cè)結(jié)果。
換句話說,以 ResNet 為例,對(duì)于分類任務(wù)而言,在幾個(gè) ResNet 模塊后放置一個(gè)反卷積層,在有輔助信息和輔助損失的情況下獲取分割輸出(可能是 1x1 卷積和 GlobalPool),這就是大部分現(xiàn)有模型架構(gòu)的工作流程。
回到我們的主題,F(xiàn)PN 作者提出一種新穎的思想,能夠有效改善現(xiàn)有的處理方式。他們不單單使用側(cè)向連接,還使用自上而下的路徑,并通過一個(gè)簡(jiǎn)單的 MergeLayer(mode=『addition』)將二者結(jié)合起來,這種方式對(duì)于特征的處理是非常有效!由于初始卷積層提取到的底層特征圖(初始卷積層)的語義信息不夠強(qiáng),無法直接用于分類任務(wù),而深層特征圖的語義信息更強(qiáng),F(xiàn)PN 正是利用了這一關(guān)鍵點(diǎn)從深層特征圖中捕獲到更強(qiáng)的語義信息。
此外,F(xiàn)PN 通過自上而下的連接路徑獲得圖像的 Fmaps(特征圖),從而能夠到達(dá)網(wǎng)絡(luò)的最深層。可以說,F(xiàn)PN 巧妙地將二者結(jié)合了起來,這種網(wǎng)絡(luò)結(jié)構(gòu)能夠提取圖像更深層的特征語義信息,從而避免了現(xiàn)有處理過程信息的流失。
其他一些實(shí)現(xiàn)細(xì)節(jié)
-
圖像金字塔:認(rèn)為同樣大小的所有特征圖屬于同一個(gè)階段。最后一層的輸出是金字塔的 reference FMaps。如 ResNet 中的第 2、3、4、5 個(gè)模塊的輸出。你可以根據(jù)內(nèi)存和特定使用情況來改變金字塔。
-
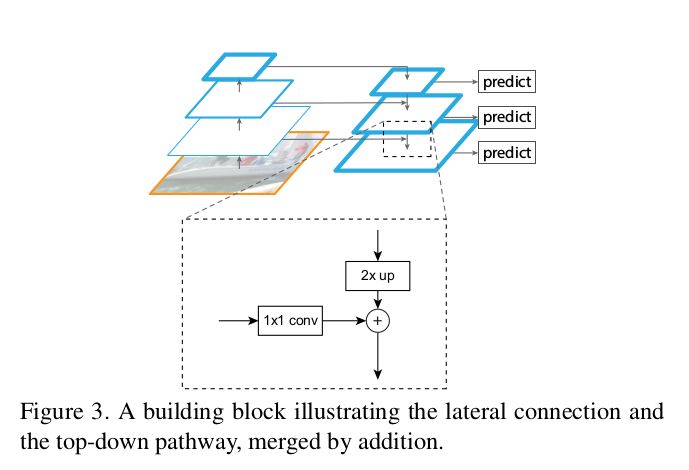
側(cè)向連接:1x1 卷積和自上而下的路徑都經(jīng)過 2× 的上采樣過程。上層的特征以自上而下的方式生成粗粒度的圖像特征,而側(cè)向連接則通過自下而上的路徑來添加更多細(xì)粒度的特征信息。在此我引用了論文中的一些圖片來幫助你進(jìn)一步理解這一過程。
-
在 FPN 的論文中,作者還介紹了一個(gè)簡(jiǎn)單的 demo 來可視化這個(gè)想法的設(shè)計(jì)思路。
如前所述,F(xiàn)PN 是一個(gè)能夠在多任務(wù)情景中使用的基線模型,適用于如目標(biāo)檢測(cè)、分割、姿態(tài)估計(jì)、人臉檢測(cè)及其他計(jì)算機(jī)視覺應(yīng)用領(lǐng)域。這篇論文的題目是 FPNs for Object Detection,自 2017 年發(fā)表以來引用量已超過 100 次!
此外,論文作者在隨后的 RPN(區(qū)域建議網(wǎng)絡(luò))和 Faster-RCNN 網(wǎng)絡(luò)研究中,仍使用 FPN 作為網(wǎng)絡(luò)的基線模型,可見 FPN的強(qiáng)大之處。以下我將列出一些關(guān)鍵的實(shí)驗(yàn)細(xì)節(jié),這些在論文中也都可以找到。
?
實(shí)驗(yàn)要點(diǎn)
-
RPN:這篇論文中,作者用 FPN 來代替單個(gè)尺度 Fmap,并在每一級(jí)使用單尺度 anchor (由于使用了 FPN,因此沒必要使用多尺度的 anchor)。此外,作者還展示了所有層級(jí)的特征金字塔共享類似的語義信息。
-
Faster RCNN:這篇論文中,作者使用類似圖像金字塔的輸出方式處理這個(gè)特征金字塔,并使用以下公式將感興趣域(RoI)分配到特定的層級(jí)中。
-
?
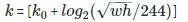 ?,其中 w、h 分別表示寬度和高度,k 表示 RoI 所分配到的層級(jí),k0 代表的是 w=224,h=224 時(shí)所映射到的層級(jí)。
?,其中 w、h 分別表示寬度和高度,k 表示 RoI 所分配到的層級(jí),k0 代表的是 w=224,h=224 時(shí)所映射到的層級(jí)。 -
Faster RCNN 在 COCO 數(shù)據(jù)集上取得當(dāng)前最先進(jìn)的實(shí)驗(yàn)結(jié)果,沒有任何冗余的結(jié)構(gòu)。
-
論文的作者對(duì)每個(gè)模塊的功能進(jìn)行了消融(ablation)研究,并論證了本文提出的想法。
-
此外,還基于 DeepMask 和 SharpMask 論文,作者進(jìn)一步展示了如何使用 FPN 生成分割的建議區(qū)域(segmentation proposal generation)。
對(duì)于其他的實(shí)現(xiàn)細(xì)節(jié)、實(shí)驗(yàn)設(shè)置等內(nèi)容,感興趣的同學(xué)可以認(rèn)真閱讀下這篇論文。
實(shí)現(xiàn)代碼
-
官方的Caffe2版本:
https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
-
Caffe版本:https://github.com/unsky/FPN
-
PyTorch版本:https://github.com/kuangliu/pytorch-fpn (just the network)
-
MXNet版本:https://github.com/unsky/FPN-mxnet
-
Tensorflow版本:https://github.com/yangxue0827/FPN_Tensorflow
▌RetinaNet:Focal Loss 損失函數(shù)用于密集目標(biāo)檢測(cè)任務(wù)
這個(gè)架構(gòu)是由同一個(gè)團(tuán)隊(duì)所開發(fā),這篇論文[2]發(fā)表在 ICCV 2017 上,論文的一作也是 FPN 論文的一作。該論文中提出有兩個(gè)關(guān)鍵想法:通用損失函數(shù)Focal Loss(FL)和單階段的目標(biāo)檢測(cè)器RetinaNet。兩者組合成的RetinaNet在COCO的目標(biāo)檢測(cè)任務(wù)中表現(xiàn)得非常好,并超過了先前FPN所保持的結(jié)果。
Focal Loss
Focal Loss損失函數(shù)的提出來源于一個(gè)聰明又簡(jiǎn)單的想法。如果你熟悉加權(quán)函數(shù)的話,那么你應(yīng)該對(duì)Focal Loss并不陌生。該損失函數(shù)其實(shí)就是巧妙地使用了加權(quán)的損失函數(shù),讓模型訓(xùn)練過程更聚焦于分類難度高的樣本。其數(shù)學(xué)公式如下所示:

其中,γ 是一個(gè)可改變的超參數(shù),pt 表示分類器輸出的樣本概率。將 γ 設(shè)置為大于 0,將會(huì)減小分類結(jié)果較好的樣本權(quán)重。α_t 表示標(biāo)準(zhǔn)加權(quán)損失函數(shù)中的類別權(quán)重,在論文中將其稱為 α-balanced 損失。值得注意的是,這個(gè)是分類損失,RetinaNet 將其與 smooth L1 損失結(jié)合,用于目標(biāo)檢測(cè)任務(wù)。
RetinaNet
YOLO2 和 SSD 是當(dāng)前處理目標(biāo)場(chǎng)景最優(yōu)的單階段(one-stage)算法。相繼的,F(xiàn)AIR 也開發(fā)了自己的單階段檢測(cè)器。作者指出,YOLO2 和 SSD 模型都無法接近當(dāng)前最佳的結(jié)果,而RetinaNet 可以輕松地實(shí)現(xiàn)單階段的最佳的檢測(cè)結(jié)果,而且速度較快,他們將這歸功于新型損失函數(shù)(Focal Loss)的應(yīng)用,而不是簡(jiǎn)單的網(wǎng)絡(luò)結(jié)構(gòu)(其結(jié)構(gòu)仍以 FPN 為基礎(chǔ)網(wǎng)絡(luò))。
作者認(rèn)為,單階段檢測(cè)器將面臨很多背景和正負(fù)類別樣本數(shù)量不平衡的問題(而不僅僅的簡(jiǎn)單的正類別樣本的不均衡問題),一般的加權(quán)損失函數(shù)僅僅是為了解決樣本數(shù)量不均衡問題,而Focal Loss 函數(shù)主要是針對(duì)分類難度大/小的樣本,而這正好能與 RetinaNet 很好地契合。
注意點(diǎn):
-
兩階段(two-stage)目標(biāo)檢測(cè)器無需擔(dān)心正、負(fù)樣本的不均衡問題,因?yàn)樵诘谝浑A段就將絕大部分不均衡的樣本都移除了。
-
RetinaNet 由兩部分組成:主干網(wǎng)絡(luò)(即卷積特征提取器,如 FPN)和兩個(gè)特定任務(wù)的子網(wǎng)絡(luò)(分類器和邊界框回歸器)。
-
采用不同的設(shè)計(jì)參數(shù)時(shí),網(wǎng)絡(luò)的性能不會(huì)發(fā)生太大的變化。
-
Anchor 或 AnchorBoxes 是與 RPN 中相同的 Anchor[5]。Anchor 的坐標(biāo)是滑動(dòng)窗口的中心位置,其大小、橫縱比(aspect ratio)與滑動(dòng)窗口的長(zhǎng)寬比有關(guān),大小從 322 到 512 ,橫縱比取值為{1:2, 1:1, 2:1}。
-
用 FPN 來提取圖像特征,在每一階段都有 cls+bbox 子網(wǎng)絡(luò),用于給出 Anchor 中所有位置的對(duì)應(yīng)輸出。
實(shí)現(xiàn)代碼
-
官方的Caffe2版本:
https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
-
PyTorch版本:https://github.com/kuangliu/pytorch-retinanet
-
Keras版本:https://github.com/fizyr/keras-retinanet
-
MXNet版本:https://github.com/unsky/RetinaNet
▌Mask R-CNN
正如上面所述,Mask R-CNN [3]也幾乎是同一個(gè)團(tuán)隊(duì)開發(fā)的,并發(fā)表在 ICCV 2017 上,用于圖像的實(shí)例分割任務(wù)。簡(jiǎn)單來說,圖像的實(shí)例分割不過就是不使用邊界框的目標(biāo)檢測(cè)任務(wù),目的是給出檢測(cè)目標(biāo)準(zhǔn)確的分割掩碼。這項(xiàng)任務(wù)想法簡(jiǎn)單,實(shí)現(xiàn)起來也并不困難,但是要使模型正常運(yùn)行并達(dá)到當(dāng)前最佳的水準(zhǔn),或者使用預(yù)訓(xùn)練好的模型來加快分割任務(wù)的實(shí)現(xiàn)等,想要做到這些可并不容易。
TL;DR:如果你了解 Faster R-CNN 的工作原理,那么 Mask R-CNN 模型對(duì)你來說是很簡(jiǎn)單的,只需要在 Faster R-CNN 的基礎(chǔ)上添加一個(gè)用于分割的網(wǎng)絡(luò)分支,其網(wǎng)絡(luò)主體有 3 個(gè)分支,分別對(duì)應(yīng)于 3 個(gè)不同的任務(wù):分類、邊界框回歸和實(shí)例分割。
值得注意的是,Mask R-CNN 的最大貢獻(xiàn)在于,僅僅使用簡(jiǎn)單、基礎(chǔ)的網(wǎng)絡(luò)設(shè)計(jì),不需要多么復(fù)雜的訓(xùn)練優(yōu)化過程及參數(shù)設(shè)置,就能夠?qū)崿F(xiàn)當(dāng)前最佳的實(shí)例分割效果,并有很高的運(yùn)行效率。
我很喜歡這篇論文,因?yàn)樗乃枷牒芎?jiǎn)單。但是,那些看似簡(jiǎn)單的東西卻伴有大量的解釋。例如,多項(xiàng)式掩碼與獨(dú)立掩碼的使用(softmax vs sigmoid)。
此外,Mask R-CNN 并未假設(shè)大量先驗(yàn)知識(shí),因此在論文中也沒有需要論證的內(nèi)容。如果你有興趣,可以仔細(xì)查看這篇論文,你可能會(huì)發(fā)現(xiàn)一些有趣的細(xì)節(jié)。基于你對(duì) Faster RCNN已有了基礎(chǔ)了解,我總結(jié)了以下一些細(xì)節(jié)幫助你進(jìn)一步理解 Mask R-CNN:
-
首先,Mask R-CNN 與 Faster RCNN 類似,都是兩階段網(wǎng)絡(luò)。第一階段都是 RPN 網(wǎng)絡(luò)。
-
Mask R-CNN 添加一個(gè)并行分割分支,用于預(yù)測(cè)分割的掩碼,稱之為 FCN。
-
Mask R-CNN 的損失函數(shù)由 L_cls、L_box、L_maskLcls、L_box、L_mask 四部分構(gòu)成。
-
Mask R-CNN 中用 ROIAlign 層代替 ROIPool。這不像 ROIPool 中那樣能將你的計(jì)算結(jié)果的分?jǐn)?shù)部分(x/spatial_scale)四舍五入成整數(shù),而是通過雙線性內(nèi)插值法來找出特定浮點(diǎn)值對(duì)應(yīng)的像素。
-
例如:假定 ROI 高度和寬度分別是 54、167。空間尺度,也稱為 stride 是圖像大小 size/Fmap 的值(H/h),其值通常為 224/14=16 (H=224,h=14)。此外,還要注意的是:
-
ROIPool: 54/16, 167/16 = 3,10
-
ROIAlign: 54/16, 167/16 = 3.375, 10.4375
-
現(xiàn)在,我們使用雙線性內(nèi)插值法對(duì)其進(jìn)行上采樣。
-
根據(jù) ROIAlign 輸出的形狀(如7x7),我們可以用類似的操作將對(duì)應(yīng)的區(qū)域分割成合適大小的子區(qū)域。
-
使用 Chainer folks 檢查 ROIPooling 的 Python 實(shí)現(xiàn),并嘗試自己實(shí)現(xiàn) ROIAlign。
-
ROIAlign 的實(shí)現(xiàn)代碼可在不同的庫中獲得,具體可查看下面給出的代碼鏈接。
-
-
Mask R-CNN 的主干網(wǎng)絡(luò)是 ResNet-FPN。
此外,我還曾專門寫過一篇文章介紹過Mask-RCNN的原理,博客地址是:https://coming.soon/。
實(shí)現(xiàn)代碼
-
官方的Caffe2版本:
https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
-
Keras版本:https://github.com/matterport/Mask_RCNN/
-
PyTorch版本:https://github.com/soeaver/Pytorch_Mask_RCNN/
-
MXNet版本:https://github.com/TuSimple/mx-maskrcnn
▌Learning to Segment Everything
正如題目 Learning to Segment Everything 那樣,這篇論文是關(guān)于目標(biāo)分割任務(wù),具體來說是解決實(shí)例分割問題。計(jì)算機(jī)視覺領(lǐng)域中標(biāo)準(zhǔn)的分割數(shù)據(jù)集對(duì)于現(xiàn)實(shí)的應(yīng)用而言,數(shù)據(jù)集的數(shù)量都太有限了,即使是當(dāng)前最流行、最豐富的 COCO 數(shù)據(jù)集[7],也僅有 80 種目標(biāo)類別,這還遠(yuǎn)遠(yuǎn)無法達(dá)到實(shí)用的需求。
相比之下,目標(biāo)識(shí)別及檢測(cè)的數(shù)據(jù)集,如 OpenImages[8]就有將近 6000 個(gè)分類類別和 545 個(gè)檢測(cè)類別。此外,斯坦福大學(xué)的另一個(gè)數(shù)據(jù)集 Visual Genome 也擁有近 3000 個(gè)目標(biāo)類別。但由于這個(gè)數(shù)據(jù)集中每個(gè)類別所包含的目標(biāo)數(shù)量太少了,即使它的類別在實(shí)際應(yīng)用中更加豐富、有用,深度神經(jīng)網(wǎng)絡(luò)也無法在這樣的數(shù)據(jù)集上取得足夠好的性能,因此研究者通常不喜歡選用這些數(shù)據(jù)集進(jìn)行目標(biāo)分類、檢測(cè)問題的研究。值得注意的是,這個(gè)數(shù)據(jù)集僅有 3000 個(gè)目標(biāo)檢測(cè)(邊界框)的標(biāo)簽類別,而沒有包含任何目標(biāo)分割的標(biāo)注,即無法直接用于目標(biāo)分割的研究。
下面來介紹我們要講的這篇論文[4]。
就數(shù)據(jù)集而言,實(shí)際上邊界框與分割標(biāo)注之間并不存在太大的區(qū)別,區(qū)別僅在于后者比前者的標(biāo)注信息更加精確。因此,本文的作者正是利用 Visual Genome[9]數(shù)據(jù)集中有 3000 個(gè)類別的目標(biāo)邊界框標(biāo)簽來解決目標(biāo)分割任務(wù)。我們稱這種方法為弱監(jiān)督學(xué)習(xí),即不需要相關(guān)任務(wù)的完整監(jiān)督信息。如果他們使用的是 COCO + Visual Genome 的數(shù)據(jù)集,即同時(shí)使用分割標(biāo)簽和邊界框標(biāo)簽,那么這同樣可稱為是半監(jiān)督學(xué)習(xí)。
讓我們回到主題,這篇論文提出了一種非常棒的思想,其網(wǎng)絡(luò)架構(gòu)主要如下:
-
網(wǎng)絡(luò)結(jié)構(gòu)建立在 Mask-RCNN 基礎(chǔ)上。
-
同時(shí)使用有掩碼和無掩碼的輸入對(duì)模型進(jìn)行訓(xùn)練。
-
在分割掩碼和邊界框掩碼之間添加了一個(gè)權(quán)重遷移函數(shù)。
-
當(dāng)使用一個(gè)無掩碼的輸入時(shí),將
-
如下圖所示:A 表示 COCO 數(shù)據(jù)集,B 表示 Visual Genome 數(shù)據(jù)集,對(duì)網(wǎng)絡(luò)的不同輸入使用不同的訓(xùn)練路徑。
-
將兩個(gè)損失同時(shí)進(jìn)行反向傳播將導(dǎo)致
-
Fix:當(dāng)反向傳播掩碼損失時(shí),要計(jì)算預(yù)測(cè)掩碼的權(quán)重 τ 關(guān)于權(quán)重遷移函數(shù)參數(shù) θ 的梯度值,而對(duì)邊界框的權(quán)重
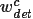
-
 ,其中 τ 表示預(yù)測(cè)掩碼的權(quán)重值。?
,其中 τ 表示預(yù)測(cè)掩碼的權(quán)重值。?
-
由于 Visual Genome 數(shù)據(jù)集沒有分割標(biāo)注,模型無法給出在該數(shù)據(jù)集上目標(biāo)分割的準(zhǔn)確率,因此作者在其他的數(shù)據(jù)集上展示模型的驗(yàn)證結(jié)果。PASCAL-VOC 數(shù)據(jù)集有 20 個(gè)目標(biāo)類別,這些類別全部包含在 COCO 數(shù)據(jù)集中。因此,對(duì)于這 20 種類別,他們使用 PASCAL-VOC 數(shù)據(jù)集的分割標(biāo)注及 COCO 數(shù)據(jù)集中相應(yīng)類別的邊界框標(biāo)簽對(duì)模型進(jìn)行訓(xùn)練。
論文展示了在 COCO 數(shù)據(jù)集中這 20 個(gè)類別上,模型實(shí)例分割的結(jié)果。此外由于兩個(gè)數(shù)據(jù)集包含兩種不同的真實(shí)標(biāo)簽,他們還對(duì)相反的情況進(jìn)行了訓(xùn)練,實(shí)驗(yàn)結(jié)果如下圖所示。
?

-
Facebook
+關(guān)注
關(guān)注
3文章
1429瀏覽量
54648 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1696瀏覽量
45927
原文標(biāo)題:從FPN到Mask R-CNN,一文告訴你Facebook的計(jì)算機(jī)視覺有多強(qiáng)
文章出處:【微信號(hào):AI_Thinker,微信公眾號(hào):人工智能頭條】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
手把手教你使用LabVIEW實(shí)現(xiàn)Mask R-CNN圖像實(shí)例分割(含源碼)
機(jī)器視覺與計(jì)算機(jī)視覺的關(guān)系簡(jiǎn)述
計(jì)算機(jī)視覺領(lǐng)域的關(guān)鍵技術(shù)/典型算法模型/通信工程領(lǐng)域的應(yīng)用方案
深度學(xué)習(xí)與傳統(tǒng)計(jì)算機(jī)視覺簡(jiǎn)介
Mask R-CNN:自動(dòng)從視頻中制作目標(biāo)物體的GIF動(dòng)圖
什么是Mask R-CNN?Mask R-CNN的工作原理
引入Mask R-CNN思想通過語義分割進(jìn)行任意形狀文本檢測(cè)與識(shí)別
計(jì)算機(jī)視覺與機(jī)器視覺區(qū)別
手把手教你操作Faster R-CNN和Mask R-CNN
Facebook AI使用單一神經(jīng)網(wǎng)絡(luò)架構(gòu)來同時(shí)完成實(shí)例分割和語義分割

計(jì)算機(jī)視覺入門指南
基于Mask R-CNN的遙感圖像處理技術(shù)綜述
用于實(shí)例分割的Mask R-CNN框架
PyTorch教程14.8之基于區(qū)域的CNN(R-CNN)

PyTorch教程-14.8。基于區(qū)域的 CNN (R-CNN)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論