 Apple Keynote推出iPhone X和FaceID
Apple Keynote推出iPhone X和FaceID
最近大家談論最多的關于新款iPhone X的功能之一就是新的解鎖技術,即TouchID的后續技術:FaceID。
創建了無邊框手機后,蘋果不得不找出新方法簡單快捷地解鎖手機。雖然一些競爭對手繼續使用放在不同位置的指紋傳感器,但蘋果決定對解鎖手機的方式進行創新和變革:只需看一眼,FaceID就能安全地解鎖iPhone X。借助一款先進(而且非常小巧)的前置深度相機,iPhone X可以建立用戶臉部的3D模型。此外,iPhone X通過紅外攝像頭識別人臉,可以避免環境光和顏色對人臉識別的影響。通過深度學習,手機可以捕捉到用戶臉部的很多細節,因此在用戶拿著手機的時候,手機可以識別出它的主人。比較令人驚訝的是,蘋果表示這種方法比TouchID更安全,出錯率為百萬分之一。
我對蘋果的FaceID的實現技術非常感興趣,特別是它完全運行在設備上,而且只需利用用戶的面部進行一點點訓練,就可以在每次拿起手機的時候順利地進行識別。我研究了如何使用深度學習來實現此過程,以及如何優化每個步驟。在這篇文章中,我將展示如何使用Keras實現一個類似FaceID的算法。我會介紹采用的各種架構,并展示一些在Kinect(一種非常流行的RGB-D相機,擁有與iPhone X前置攝像頭非常相似的輸出,但設備本身更大)上的最終實驗。倒杯咖啡,讓我們開始逆向工程蘋果的新技術。
對FaceID的初步了解
“……賦予FaceID力量的神經網絡不是簡單的分類。”
FaceID注冊的過程
第一步我們來仔細分析FaceID在iPhone X上的工作原理。我們可以通過蘋果的白皮書理解FaceID的基本機制。使用TouchID的時候,用戶必須多次按傳感器來注冊自己的指紋。大約需要15-20次不同的觸摸,iPhone才能完成注冊,并準備好TouchID。同樣地,FaceID也需要用戶進行臉部注冊。過程非常簡單:用戶只需像往常一樣看著手機,然后慢慢地轉動頭部一圈,從不同的角度注冊臉部。如此,注冊過程就完成了,手機已經準備好解鎖了。這個超快的注冊過程可以告訴我們很多關于底層學習算法的信息。比如,FaceID背后的神經網絡并不是簡單的分類。我會在后面進行詳細的解釋。
Apple Keynote推出iPhone X和FaceID
對于神經網絡來說,分類的意思是學習如何預測看到的臉是不是用戶的臉。所以,它需要一些訓練數據來預測“是”或“否”,但與很多其他深度學習的應用場景不同,所以這種方式在這里并不適用。首先,神經網絡需要使用從用戶臉上捕捉到的數據重新進行訓練。而這需要消耗大量的時間和電量,還需要大量的不同面孔作為訓練數據以獲得負面的樣本,這也是不現實的。即使是試圖遷移并微調已經訓練好的神經網絡,這些條件也幾乎不會變化。而且,蘋果也不可能在實驗室等地方“線下”訓練復雜的神經網絡,然后再將訓練好的神經網絡搭載在手機中。相反,我認為FaceID是由孿生卷積神經網絡實現的(siamese-like convolutional neural network),該網絡由蘋果公司進行“線下”培訓,將臉部映射到一個低維潛在空間(latent space),并通過對比損失函數(contrastive loss)最大化不同人臉之間的距離。通過本文,你可以了解Keynote中提到的體系結構。我知道,很多讀者對上述名詞很陌生,但是沒關系,我會逐步的進行詳細的解釋。
FaceID看起來會是TouchID之后的新標準。蘋果是否會把它帶到所有的新設備上?
從人臉到神經網絡的數字


Hadsell,Chopra和LeCun發表的論文“Dimensionality Reduction by Learning an Invariant Mapping”。請注意此架構是如何學習數字之間的相似性,并自動將它們分組在二維中。類似的技術也可以應用于面部識別。

FaceID可以適應外觀的變化
接下來,讓我們看看如何利用Python和Keras實現。
使用Keras實現FaceID
就像所有的機器學習項目一樣,我們首先需要的是數據。創建自己的數據集需要花費大量時間和許多人的配合,這項工作本身可能非常具有挑戰性。因此,我搜索了網絡上RGB-D的人臉數據集,找到了一個非常合適的數據集(http://www.vap.aau.dk/rgb-d-face-database/)。這個數據集是根據人臉面向不同的方向以及不同的表情制作出的RGB-D圖像集,正好類似于iPhone X的情況。
最終的實現可以參考我的GitHub代碼庫(https://github.com/normandipalo/faceID_beta),里面有個Jupyter Notebook。我還進一步嘗試了使用Colab Notebook,你也可以試試看。
我創建了一個基于SqueezeNet架構的卷積網絡。這個神經網絡以兩組RGBD的面部圖像(即4通道圖像)作為輸入,并輸出兩組數據之間的距離。該網絡用對比損失函數(constrastive loss)訓練,可以最大程度地減少同一人的照片之間的距離,同時最大程度地提高不同人的照片之間的距離。
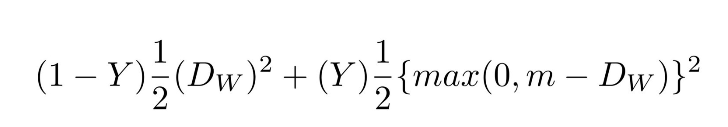
對比損失函數

使用t-SNE創建嵌入空間中的人臉的簇,每種顏色代表不同的面孔(但顏色被重復使用)
使用PCA創建嵌入空間中的人臉的簇,每種顏色都是不同的面孔(但顏色被重復使用)
實驗!
現在我們可以試試個模型,模擬一個常見的FaceID的流程:首先,注冊用戶的面部;然后在解鎖階段,需要驗證兩個方面——主人可以解鎖,而其他人不可以。 如前所述,區別在于神經網絡會計算解鎖手機時和注冊時的臉部的距離,然后判斷是否在某個閾值以下。
下面我們來注冊:我從數據集中采集了同一人的一系列照片,并模擬了注冊階段。現在該設備將計算每個姿勢的嵌入,并保存在本地。
新用戶注冊階段,模仿FaceID的過程
在深度相機中觀察到的注冊階段
嵌入空間中同一個用戶的面部距離
嵌入空間中不同用戶的面部距離
因此,我們可以將閾值設置為大約0.4,就可以阻止陌生人解鎖設備了。
結論
在這篇文章中,我展示了如何利用面部嵌入和孿生卷積神經網絡,實現FaceID解鎖機制的原型。希望對你能有所幫助。如果你有任何問題都可以和我聯系。你可以從以下鏈接找到所有相關的Python代碼:
-
iPhone
+關注
關注
28文章
13446瀏覽量
201464 -
神經網絡
+關注
關注
42文章
4765瀏覽量
100566 -
faceid
+關注
關注
2文章
89瀏覽量
11898
發布評論請先 登錄
相關推薦
Apple Intelligence未達預期,iPhone 16銷量受挫,AI全球化挑戰浮現
史上最大屏幕Apple Watch亮相 屏幕面積增加了30%
蘋果秋季發布會臨近,iPhone 16與Apple Watch系列新品蓄勢待發
Apple設備為什么無法連接到AP?
iPhone16出貨量或達9000萬部 押注“Apple Intelligence”AI
Anthropic推出iPhone應用程序和業務層
Meta與雷朋聯手推出智能眼鏡Ray-Ban,深度整合Apple Music
蘋果今年將“Apple ID”更名為“Apple Account”
貝寶宣布小企業可采用支持Apple Tap to Pay的iPhone接受美金付款
蘋果iPhone 16系列或搭載差異化基帶芯片
Apple Find My認證芯片-ST17H6x芯片
倫茨科技ST17H6x芯片,國產首款支持Apple Find My認證芯片
國產Apple Find My「查找」認證芯片-倫茨科技ST17H6x芯片

倫茨科技宣布ST17H6x芯片已通過Apple MFi / Find My「查找」認證






 工商網監
工商網監
評論