 【干貨】計算機視覺必讀:目標跟蹤、網絡壓縮、圖像分類、人臉識別等
【干貨】計算機視覺必讀:目標跟蹤、網絡壓縮、圖像分類、人臉識別等
深度學習目前已成為發展最快、最令人興奮的機器學習領域之一。本文以計算機視覺的重要概念為線索,介紹深度學習在計算機視覺任務中的應用,包括網絡壓縮、細粒度圖像分類、看圖說話、視覺問答、圖像理解、紋理生成和風格遷移、人臉識別、圖像檢索、目標跟蹤等。
網絡壓縮(network compression)
盡管深度神經網絡取得了優異的性能,但巨大的計算和存儲開銷成為其部署在實際應用中的挑戰。有研究表明,神經網絡中的參數存在大量的冗余。因此,有許多工作致力于在保證準確率的同時降低網路復雜度。
低秩近似用低秩矩陣近似原有權重矩陣。例如,可以用SVD得到原矩陣的最優低秩近似,或用Toeplitz矩陣配合Krylov分解近似原矩陣。
剪枝(pruning)在訓練結束后,可以將一些不重要的神經元連接(可用權重數值大小衡量配合損失函數中的稀疏約束)或整個濾波器去除,之后進行若干輪微調。實際運行中,神經元連接級別的剪枝會使結果變得稀疏,不利于緩存優化和內存訪問,有的需要專門設計配套的運行庫。相比之下,濾波器級別的剪枝可直接運行在現有的運行庫下,而濾波器級別的剪枝的關鍵是如何衡量濾波器的重要程度。例如,可用卷積結果的稀疏程度、該濾波器對損失函數的影響、或卷積結果對下一層結果的影響來衡量。
量化(quantization)對權重數值進行聚類,用聚類中心數值代替原權重數值,配合Huffman編碼,具體可包括標量量化或乘積量化。但如果只考慮權重自身,容易造成量化誤差很低,但分類誤差很高的情況。因此,Quantized CNN優化目標是重構誤差最小化。此外,可以利用哈希進行編碼,即被映射到同一個哈希桶中的權重共享同一個參數值。
降低數據數值范圍默認情況下數據是單精度浮點數,占32位。有研究發現,改用半精度浮點數(16位)幾乎不會影響性能。谷歌TPU使用8位整型來表示數據。極端情況是數值范圍為二值或三值(0/1或-1/0/1),這樣僅用位運算即可快速完成所有計算,但如何對二值或三值網絡進行訓練是一個關鍵。通常做法是網絡前饋過程為二值或三值,梯度更新過程為實數值。此外,有研究認為,二值運算的表示能力有限,因此其使用一個額外的浮點數縮放二值卷積后的結果,以提升網絡表示能力。
精簡結構設計有研究工作直接設計精簡的網絡結構。例如,(1).瓶頸(bottleneck)結構及1×1卷積。這種設計理念已經被廣泛用于Inception和ResNet系列網絡設計中。(2).分組卷積。(3).擴張卷積。使用擴張卷積可以保持參數量不變的情況下擴大感受野。
知識蒸餾(knowledge distillation)訓練小網絡以逼近大網絡,但應該如何去逼近大網絡仍沒有定論。
軟硬件協同設計常用的硬件包括兩大類:(1). 通用硬件,包括CPU(低延遲,擅長串行、復雜運算)和GPU(高吞吐率,擅長并行、簡單運算)。(2). 專用硬件,包括ASIC(固定邏輯器件,例如谷歌TPU)和FPGA(可編程邏輯器件,靈活,但效率不如ASIC)。
細粒度圖像分類(fine-grained image classification)
相比(通用)圖像分類,細粒度圖像分類需要判斷的圖像類別更加精細。比如,我們需要判斷該目標具體是哪一種鳥、哪一款的車、或哪一個型號的飛機。通常,這些子類之間的差異十分微小。比如,波音737-300和波音737-400的外觀可見的區別只是窗戶的個數不同。因此,細粒度圖像分類是比(通用)圖像分類更具有挑戰性的任務。
細粒度圖像分類的經典做法是先定位出目標的不同部位,例如鳥的頭、腳、翅膀等,之后分別對這些部位提取特征,最后融合這些特征進行分類。這類方法的準確率較高,但這需要對數據集人工標注部位信息。目前細粒度分類的一大研究趨勢是不借助額外監督信息,只利用圖像標記進行學習,其以基于雙線性CNN的方法為代表。
雙線性CNN (bilinear CNN)其通過計算卷積描述向量(descriptor)的外積來考察不同維度之間的交互關系。由于描述向量的不同維度對應卷積特征的不同通道,而不同通道提取了不同的語義特征,因此,通過雙線性操作,可以同時捕獲輸入圖像的不同語義特征之間的關系。
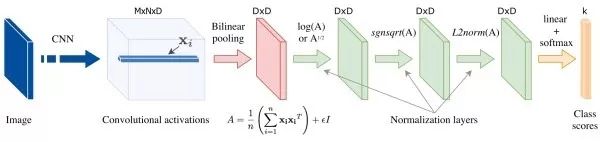
精簡雙線性匯合雙線性匯合的結果十分高維,這會占用大量的計算和存儲資源,同時使后續的全連接層的參數量大大增加。許多后續研究工作旨在設計更精簡的雙線性匯合策略,大致包括以下三大類:(1).PCA降維。在雙線性匯合前,對深度描述向量進行PCA投影降維,但這會使各維不再相關,進而影響性能。一個折中的方案是只對一支進行PCA降維。(2).近似核估計。可以證明,在雙線性匯合結果后使用線性SVM分類等價于在描述向量間使用了多項式核。由于兩個向量外積的映射等于兩個向量分別映射之后再卷積,有研究工作使用隨機矩陣近似向量的映射。此外,通過近似核估計,我們可以捕獲超過二階的信息(如下圖)。(3).低秩近似。對后續用于分類的全連接層的參數矩陣進行低秩近似,進而使我們不用顯式計算雙線性匯合結果。
“看圖說話”(image captioning)
“看圖說話”旨在對一張圖像產生對其內容一兩句話的文字描述。這是視覺和自然語言處理兩個領域的交叉任務。
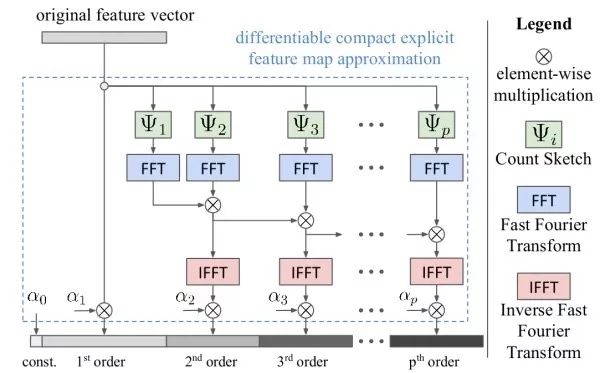
編碼-解碼網絡(encoder-decoder networks)看圖說話網絡設計的基本思想,其借鑒于自然語言處理中的機器翻譯思路。將機器翻譯中的源語言編碼網絡替換為圖像的CNN編碼網絡以提取圖像的特征,之后用目標語言解碼網絡生成文字描述。
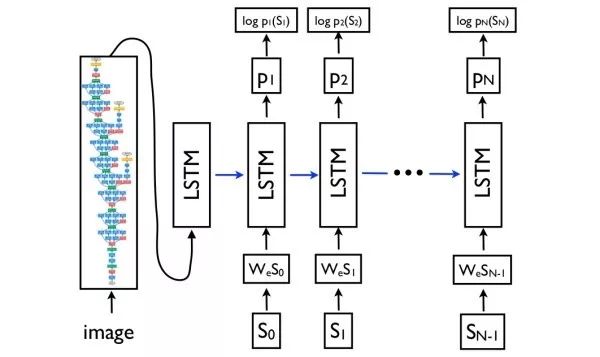
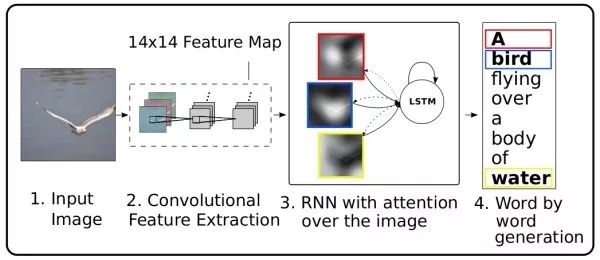
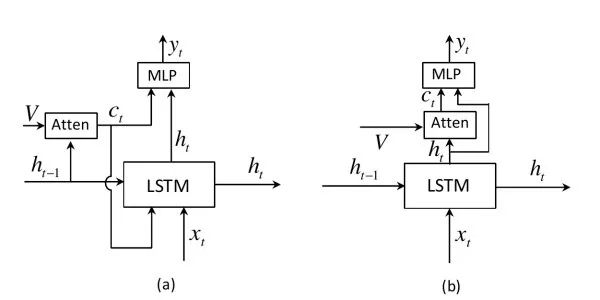
Show, attend, and tell注意力(attention)機制是機器翻譯中用于捕獲長距離依賴的常用技巧,也可以用于看圖說話。在解碼網絡中,每個時刻,除了預測下一個詞外,還需要輸出一個二維注意力圖,用于對深度卷積特征進行加權匯合。使用注意力機制的一個額外的好處是可以對網絡進行可視化,以觀察在生成每個詞的時候網絡注意到圖像中的哪些部分。
Adaptive attention之前的注意力機制會對每個待預測詞生成一個二維注意力圖(圖(a)),但對于像the、of這樣的詞實際上并不需要借助來自圖像的線索,并且有的詞可以根據上文推測出也不需要圖像信息。該工作擴展了LSTM,以提出“視覺哨兵”機制以判斷預測當前詞時應更關注上文語言信息還是更關注圖像信息(圖(b))。此外,和之前工作利用上一時刻的隱層狀態計算注意力圖不同,該工作使用當前隱層狀態。
視覺問答(visual question answering)
給定一張圖像和一個關于該圖像內容的文字問題,視覺問答旨在從若干候選文字回答中選出正確的答案。其本質是分類任務,也有工作是用RNN解碼來生成文字回答。視覺問答也是視覺和自然語言處理兩個領域的交叉任務。
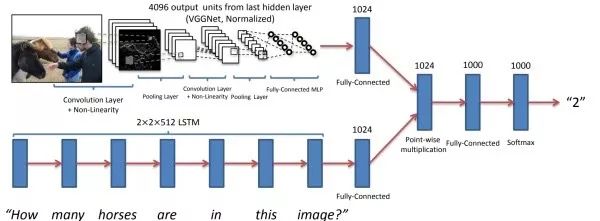
基本思路使用CNN從圖像中提取圖像特征,用RNN從文字問題中提取文本特征,之后設法融合視覺和文本特征,最后通過全連接層進行分類。該任務的關鍵是如何融合這兩個模態的特征。直接的融合方案是將視覺和文本特征拼成一個向量、或者讓視覺和文本特征向量逐元素相加或相乘。
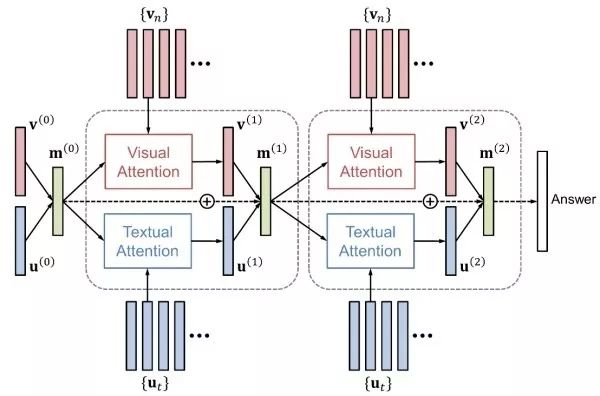
注意力機制和“看圖說話”相似,使用注意力機制也會提升視覺問答的性能。注意力機制包括視覺注意力(“看哪里”)和文本注意力(“關注哪個詞”)兩者。HieCoAtten可同時或交替產生視覺和文本注意力。DAN將視覺和文本的注意力結果映射到一個相同的空間,并據此同時產生下一步的視覺和文本注意力。
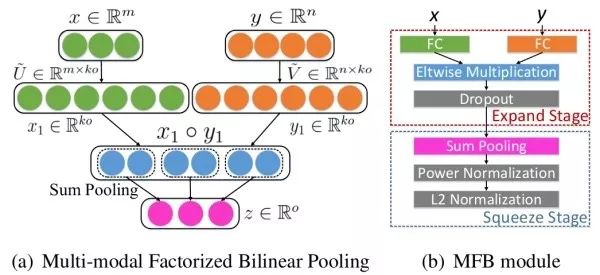
雙線性融合通過視覺特征向量和文本特征向量的外積,可以捕獲這兩個模態特征各維之間的交互關系。為避免顯式計算高維雙線性匯合結果,細粒度識別中的精簡雙線性匯合思想也可用于視覺問答。例如,MFB采用了低秩近似思路,并同時使用了視覺和文本注意力機制。
網絡可視化(visualizing)和網絡理解(understanding)
這些方法旨在提供一些可視化的手段以理解深度卷積神經網絡。
直接可視化第一層濾波器由于第一層卷積層的濾波器直接在輸入圖像中滑動,我們可以直接對第一層濾波器進行可視化。可以看出,第一層權重關注于特定朝向的邊緣以及特定色彩組合。這和生物的視覺機制是符合的。但由于高層濾波器并不直接作用于輸入圖像,直接可視化只對第一層濾波器有效。

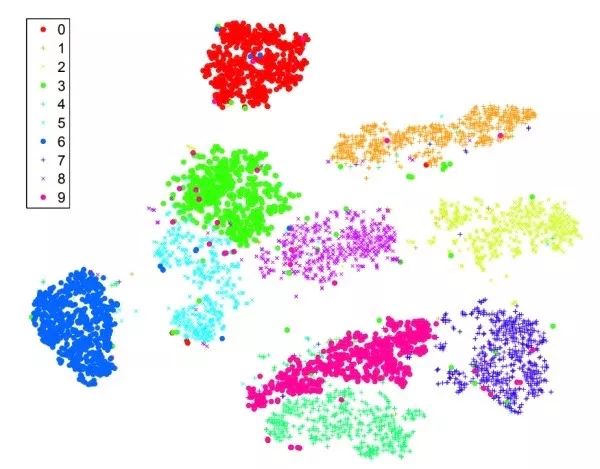
t-SNE對圖像的fc7或pool5特征進行低維嵌入,比如降維到2維使得可以在二維平面畫出。具有相近語義信息的圖像應該在t-SNE結果中距離相近。和PCA不同的是,t-SNE是一種非線性降維方法,保留了局部之間的距離。下圖是直接對MNIST原始圖像進行t-SNE的結果。可以看出,MNIST是比較容易的數據集,屬于不同類別的圖像聚類十分明顯。
可視化中間層激活值對特定輸入圖像,畫出不同特征圖的響應。觀察發現,即使ImageNet中沒有人臉或文字相關的類別,網絡會學習識別這些語義信息,以輔助后續的分類。
最大響應圖像區域選擇某一特定的中間層神經元,向網絡輸入許多不同的圖像,找出使該神經元響應最大的圖像區域,以觀察該神經元用于響應哪種語義特征。是“圖像區域”而不是“完整圖像”的原因是中間層神經元的感受野是有限的,沒有覆蓋到全部圖像。
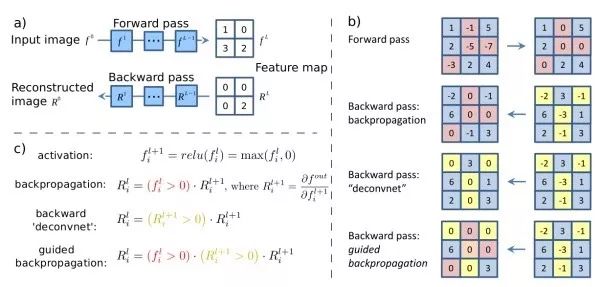
輸入顯著性圖對給定輸入圖像,計算某一特定神經元對輸入圖像的偏導數。其表達了輸入圖像不同像素對該神經元響應的影響,即輸入圖像的不同像素的變化會帶來怎樣的神經元響應值的變化。Guided backprop只反向傳播正的梯度值,即只關注對神經元正向的影響,這會產生比標準反向傳播更好的可視化效果。
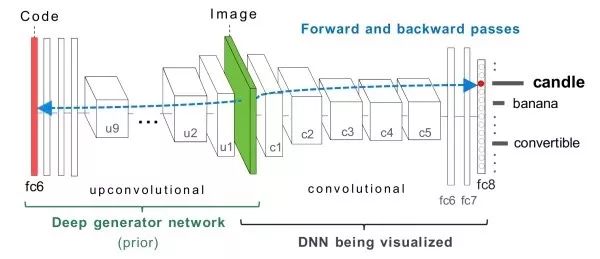
梯度上升優化選擇某一特定的神經元,計算某一特定神經元對輸入圖像的偏導數,對輸入圖像使用梯度上升進行優化,直到收斂。此外,我們需要一些正則化項使得產生的圖像更接近自然圖像。此外,除了在輸入圖像上進行優化外,我們也可以對fc6特征進行優化并從其生成需要的圖像。
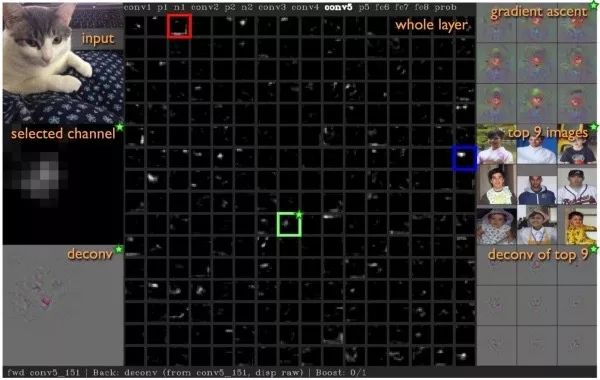
DeepVisToolbox該工具包同時提供了以上四種可視化結果。該鏈接中提供了一個演示視頻:Jason Yosinski(yosinski.com/deepvis#toolbox)
遮擋實驗(occlusion experiment)用一個灰色方塊遮擋住圖像的不同區域,之后前饋網絡,觀察其對輸出的影響。對輸出影響最大的區域即是對判斷該類別最重要的區域。從下圖可以看出,遮擋住狗的臉對結果影響最大。
Deep dream選擇一張圖像和某一特定層,優化目標是通過對圖像的梯度上升,最大化該層激活值的平方。實際上,這是在通過正反饋放大該層神經元捕獲到的語義特征。可以看出,生成的圖像中出現了很多狗的圖案,這是因為ImageNet數據集1000類別中有200類關于狗,因此,神經網絡中有很多神經元致力于識別圖像中的狗。
對抗樣本(adversarial examples)選擇一張圖像和一個不是它真實標記的類別,計算該類別對輸入圖像的偏導數,對圖像進行梯度上升優化。實驗發現,在對圖像進行難以察覺的微小改變后,就可以使網絡以相當大的信心認為該圖像屬于那個錯誤的類別。實際應用中,對抗樣本會將會對金融、安防等領域產生威脅。有研究認為,這是由于圖像空間非常高維,即使有非常多的訓練數據,也只能覆蓋該空間的很小一部分。只要輸入稍微偏離該流形空間,網絡就難以得到正常的判斷。
紋理生成(texture synthesis)和風格遷移(style transform)
給定一小張包含特定紋理的圖像,紋理合成旨在生成更大的包含相同紋理的圖像。給定一張普通圖像和一張包含特定繪畫風格的圖像,風格遷移旨在保留原圖內容的同時,將給定風格遷移到該圖中。
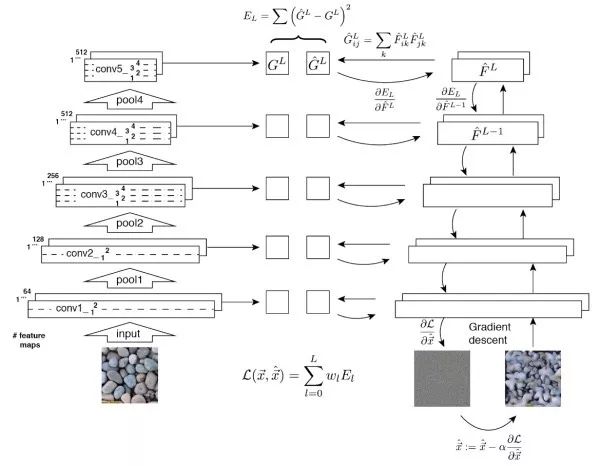
特征逆向工程(feature inversion)這兩類問題的基本思路。給定一個中間層特征,我們希望通過迭代優化,產生一個特征和給定特征接近的圖像。此外,特征逆向工程也可以告訴我們中間層特征中蘊含了多少圖像中信息。可以看出,低層的特征中幾乎沒有損失圖像信息,而高層尤其是全連接特征會丟失大部分的細節信息。從另一方面講,高層特征對圖像的顏色和紋理變化更不敏感。
Gram矩陣給定D×H×W的深度卷積特征,我們將其轉換為D×(HW)的矩陣X,則該層特征對應的Gram矩陣定義為
G=XX^T
通過外積,Gram矩陣捕獲了不同特征之間的共現關系。
紋理生成基本思路對給定紋理圖案的Gram矩陣進行特征逆向工程。使生成圖像的各層特征的Gram矩陣接近給定紋理圖像的各層Gram。低層特征傾向于捕獲細節信息,而高層特征可以捕獲更大面積的特征。
風格遷移基本思路優化目標包括兩項,使生成圖像的內容接近原始圖像內容,及使生成圖像風格接近給定風格。風格通過Gram矩陣體現,而內容則直接通過神經元激活值體現。
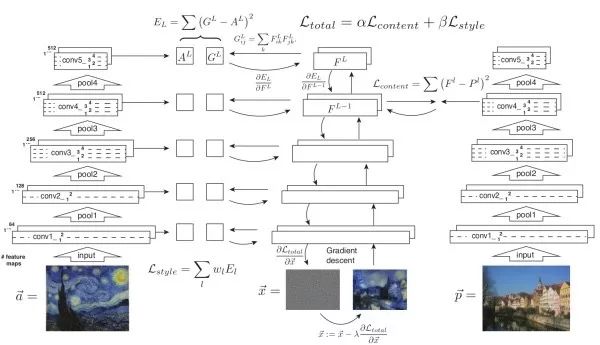
直接生成風格遷移的圖像上述方法的缺點是需要多次迭代才能收斂。該工作提出的解決方案是訓練一個神經網絡來直接生成風格遷移的圖像。一旦訓練結束,進行風格遷移只需前饋網絡一次,十分高效。在訓練時,將生成圖像、原始圖像、風格圖像三者前饋一固定網絡以提取不同層特征用于計算損失函數。
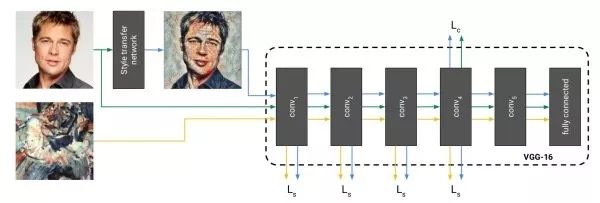
示例歸一化(instance normalization)和批量歸一化(batch normalization)作用于一個批量不同,示例歸一化的均值和方差只由圖像自身決定。實驗中發現,在風格遷移網絡中使用示例歸一化可以從圖像中去除和示例有關的對比度信息以簡化生成過程。
條件示例歸一化(conditional instance normalization)上述方法的一個問題是對每種不同的風格,我們需要分別訓練一個模型。由于不同風格之間存在共性,該工作旨在讓對應于不同風格的風格遷移網絡共享參數。具體來說,其修改了風格遷移網絡中的示例歸一化,使其具有N組縮放和平移參數,每組對應一個不同的風格。這樣,我們可以通過一次前饋過程同時獲得N張風格遷移圖像。
人臉驗證/識別(face verification/recognition)
人臉驗證/識別可以認為是一種更加精細的細粒度圖像識別任務。人臉驗證是給定兩張圖像、判斷其是否屬于同一個人,而人臉識別是回答圖像中的人是誰。一個人臉驗證/識別系統通常包括三大步:檢測圖像中的人臉,特征點定位、及對人臉進行驗證/識別。人臉驗證/識別的難題在于需要進行小樣本學習。通常情況下,數據集中每人只有對應的一張圖像,這稱為一次學習(one-shot learning)。
兩種基本思路當作分類問題(需要面對非常多的類別數),或者當作度量學習問題。如果兩張圖像屬于同一個人,我們希望它們的深度特征比較接近,否則,我們希望它們不接近。之后,根據深度特征之間的距離進行驗證(對特征距離設定閾值以判斷是否屬于同一個人),或識別(k近鄰分類)。

DeepFace第一個將深度神經網絡成功用于人臉驗證/識別的模型。DeepFace使用了非共享參數的局部連接。這是由于人臉不同區域存在不同的特征(例如眼睛和嘴巴具有不同的特征),經典卷積層的“共享參數”性質在人臉識別中不再適用。因此,人臉識別網絡中會采用不共享參數的局部連接。其使用孿生網絡(siamese network)進行人臉驗證。當兩張圖像的深度特征小于給定閾值時,認為其來自同一個人。

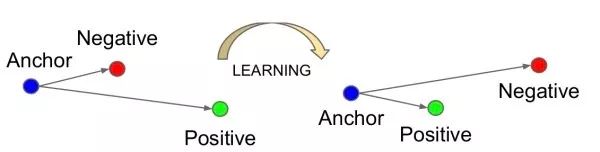
FaceNet三元輸入,希望和負樣本之間的距離以一定間隔(如0.2)大于和正樣本之間的距離。此外,輸入三元的選擇不是隨機的,否則由于和負樣本之間的差異很大,網絡學不到什么東西。選擇最困難的三元組(即最遠的正樣本和最近的負樣本)會使網絡陷入局部最優。FaceNet采用半困難策略,選擇比正樣本遠的負樣本。
大間隔交叉熵損失近幾年的一大研究熱點。由于類內波動大而類間相似度高,有研究工作旨在提升經典的交叉熵損失對深度特征的判斷能力。例如,L-Softmax加強優化目標,使對應類別的參數向量和深度特征夾角增大。 A-Softmax進一步約束L-Softmax的參數向量長度為1,使訓練更集中到優化深度特征和夾角上。實際中,L-Softmax和A-Softmax都很難收斂,訓練時采用了退火方法,從標準softmax逐漸退火至L-Softmax或A-Softmax。
活體檢測(liveness detection)判斷人臉是來自真人或是來自照片等,這是人臉驗證/識別需要解決的關鍵問題。在產業界目前主流的做法是利用人的表情變化、紋理信息、眨眼、或讓用戶完成一系列動作等。
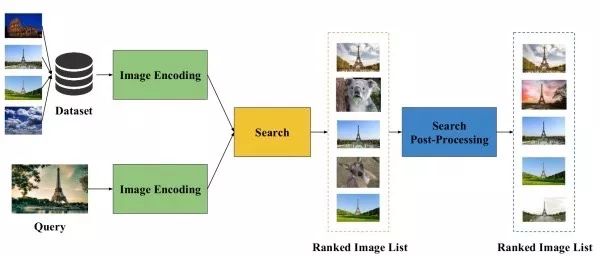
圖像檢索(image retrieval)
給定一個包含特定實例(例如特定目標、場景、建筑等)的查詢圖像,圖像檢索旨在從數據庫圖像中找到包含相同實例的圖像。但由于不同圖像的拍攝視角、光照、或遮擋情況不同,如何設計出能應對這些類內差異的有效且高效的圖像檢索算法仍是一項研究難題。
圖像檢索的典型流程首先,設法從圖像中提取一個合適的圖像的表示向量。其次,對這些表示向量用歐式距離或余弦距離進行最近鄰搜索以找到相似的圖像。最后,可以使用一些后處理技術對檢索結果進行微調。可以看出,決定一個圖像檢索算法性能的關鍵在于提取的圖像表示的好壞。
(1)無監督圖像檢索
無監督圖像檢索旨在不借助其他監督信息,只利用ImageNet預訓練模型作為固定的特征提取器來提取圖像表示。
直覺思路由于深度全連接特征提供了對圖像內容高層級的描述,且是“天然”的向量形式,一個直覺的思路是直接提取深度全連接特征作為圖像的表示向量。但是,由于全連接特征旨在進行圖像分類,缺乏對圖像細節的描述,該思路的檢索準確率一般。
利用深度卷積特征由于深度卷積特征具有更好的細節信息,并且可以處理任意大小的圖像輸入,目前的主流方法是提取深度卷積特征,并通過加權全局求和匯合(sum-pooling)得到圖像的表示向量。其中,權重體現了不同位置特征的重要性,可以有空間方向權重和通道方向權重兩種形式。
CroW深度卷積特征是一個分布式的表示。雖然一個神經元的響應值對判斷對應區域是否包含目標用處不大,但如果多個神經元同時有很大的響應值,那么該區域很有可能包含該目標。因此,CroW把特征圖沿通道方向相加,得到一張二維聚合圖,并將其歸一化并根號規范化的結果作為空間權重。CroW的通道權重根據特征圖的稀疏性定義,其類似于自然語言處理中TF-IDF特征中的IDF特征,用于提升不常出現但具有判別能力的特征。
Class weighted features該方法試圖結合網絡的類別預測信息來使空間權重更具判別能力。具體來說,其利用CAM來獲取預訓練網絡中對應各類別的最具代表性區域的語義信息,進而將歸一化的CAM結果作為空間權重。
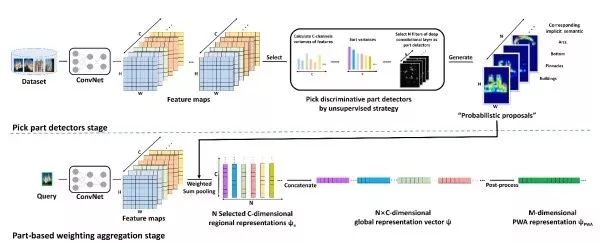
PWAPWA發現,深度卷積特征的不同通道對應于目標不同部位的響應。因此,PWA選取一系列有判別能力的特征圖,將其歸一化之后的結果作為空間權重進行匯合,并將其結果級聯起來作為最終圖像表示。
(2)有監督圖像檢索
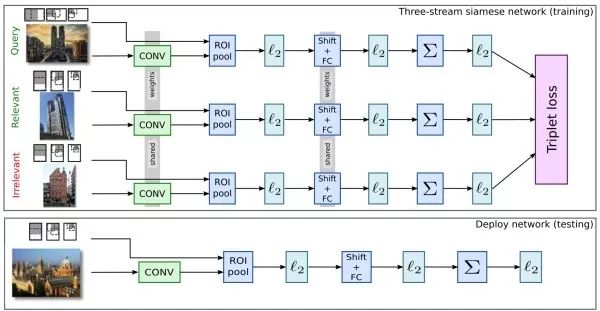
有監督圖像檢索首先將ImageNet預訓練模型在一個額外的訓練數據集上進行微調,之后再從這個微調過的模型中提取圖像表示。為了取得更好的效果,用于微調的訓練數據集通常和要用于檢索的數據集比較相似。此外,可以用候選區域網絡提取圖像中可能包含目標的前景區域。
孿生網絡(siamese network)和人臉識別的思路類似,使用二元或三元(++-)輸入,訓練模型使相似樣本之間的距離盡可能小,而不相似樣本之間的距離盡可能大。
目標跟蹤(object tracking)
目標跟蹤旨在跟蹤一段視頻中的目標的運動情況。通常,視頻第一幀中目標的位置會以包圍盒的形式給出,我們需要預測其他幀中該目標的包圍盒。目標跟蹤類似于目標檢測,但目標跟蹤的難點在于事先不知道要跟蹤的目標具體是什么,因此無法事先收集足夠的訓練數據以訓練一個專門的檢測器。
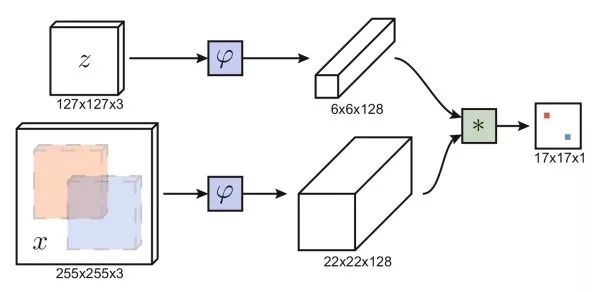
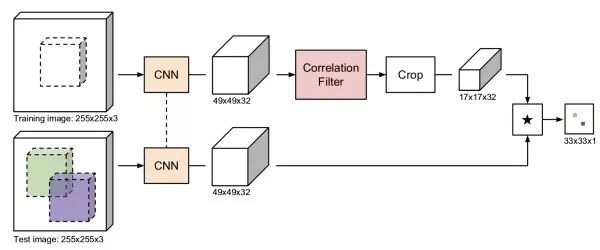
孿生網絡類似于人臉驗證的思路,利用孿生網絡,一支輸入第一幀包圍盒內圖像,另一支輸入其他幀的候選圖像區域,輸出兩張圖的相似度。我們不需要遍歷其他幀的所有可能的候選區域,利用全卷積網絡,我們只需要前饋整張圖像一次。通過互相關操作(卷積),得到二維的響應圖,其中最大響應位置確定了需要預測的包圍盒位置。基于孿生網絡的方法速度快,能處理任意大小的圖像。
CFNet相關濾波通過訓練一個線性模板來區分圖像區域和它周圍區域,利用傅里葉變換,相關濾波有十分高效的實現。CFNet結合離線訓練的孿生網絡和在線更新的相關濾波模塊,提升輕量級網絡的跟蹤性能。
生成式模型(generative models)
這類模型旨在學得數據(圖像)的分布,或從該分布中采樣得到新的圖像。生成式模型可以用于超分辨率重建、圖像著色、圖像轉換、從文字生成圖像、學習圖像潛在表示、半監督學習等。此外,生成式模型可以和強化學習結合,用于仿真和逆強化學習。
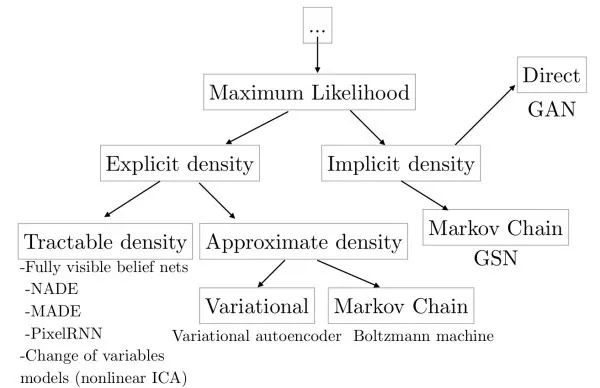
顯式建模根據條件概率公式,直接進行最大似然估計對圖像的分布進行學習。該方法的弊端是,由于每個像素依賴于之前的像素,生成圖像時由于需要從一角開始序列地進行,所以會比較慢。例如,WaveNet可以生成類似人類說話的語音,但由于無法并行生成,得到1秒的語音需要2分鐘的計算,無法達到實時。
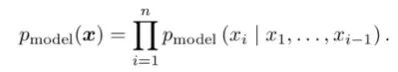
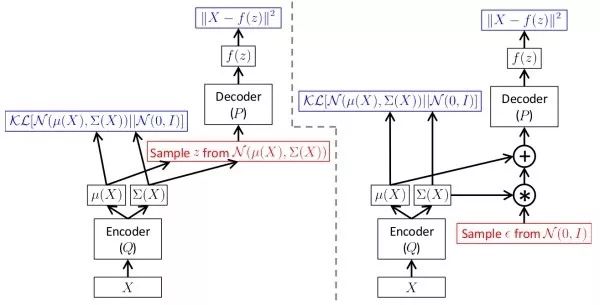
變分自編碼器(variational auto-encoder, VAE)為避免顯式建模的弊端,變分自編碼器對數據分布進行隱式建模。其認為圖像的生成受一個隱變量控制,并假設該隱變量服從對角高斯分布。變分自編碼器通過一個解碼網絡從隱變量生成圖像。由于無法直接進行最大似然估計,在訓練時,類似于EM算法,變分自編碼器會構造似然函數的下界函數,并對這個下界函數進行優化。變分自編碼器的好處是,由于各維獨立,我們可以通過控制隱變量來控制輸出圖像的變化因素。
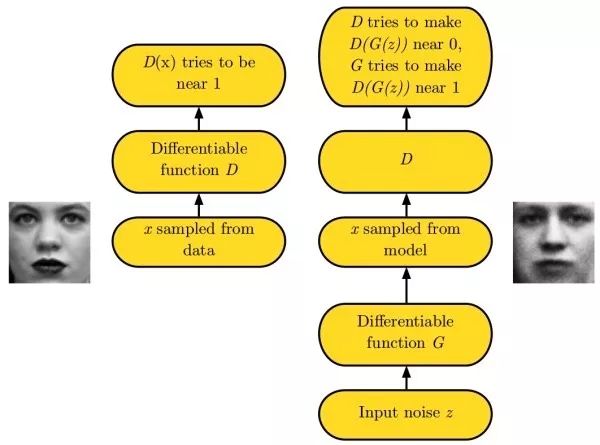
生成式對抗網絡(generative adversarial networks, GAN)由于學習數據分布十分困難,生成式對抗網絡繞開這一步驟,直接生成新的圖像。生成式對抗網絡使用一個生成網絡G從隨機噪聲中生成圖像,以及一個判別網絡D判斷其輸入圖像是真實/偽造圖像。在訓練時,判別網絡D的目標是能判斷真實/偽造圖像,而生成網絡G的目標是使得判別網絡D傾向于判斷其輸出是真實圖像。實際中,直接訓練生成式對抗網絡會遇到mode collapse問題,即生成式對抗網絡無法學到完整的數據分布。隨后,出現了LS-GAN和W-GAN的改進。和變分自編碼器相比,生成式對抗網絡的細節信息更好。以下鏈接整理了許多和生成式對抗網絡有關的論文:hindupuravinash/the-gan-zoo。以下鏈接整理了許多訓練生成式對抗網絡的其技巧:soumith/ganhacks。
視頻分類(video classification)
前面介紹的大部分任務也可以用于視頻數據,這里僅以視頻分類任務為例,簡要介紹處理視頻數據的基本方法。
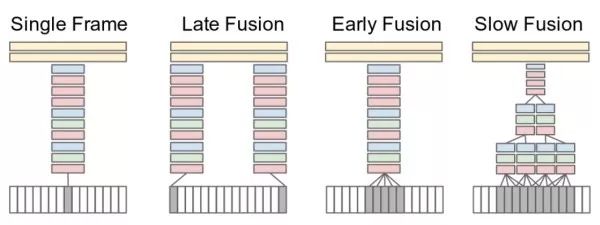
多幀圖像特征匯合這類方法將視頻看成一系列幀的圖像組合。網絡同時接收屬于一個視頻片段的若干幀圖像(例如15幀),并分別提取其深度特征,之后融合這些圖像特征得到該視頻片段的特征,最后進行分類。實驗發現,使用"slow fusion"效果最好。此外,獨立使用單幀圖像進行分類即可得到很有競爭力的結果,這說明單幀圖像已經包含很多的信息。
三維卷積將經典的二維卷積擴展到三維卷積,使之在時間維度也局部連接。例如,可以將VGG的3×3卷積擴展為3×3×3卷積,2×2匯合擴展為2×2×2匯合。

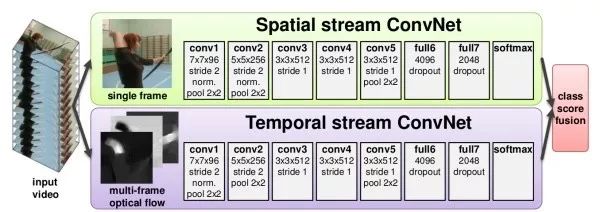
圖像+時序兩分支結構這類方法用兩個獨立的網絡分別捕獲視頻中的圖像信息和隨時間運動信息。其中,圖像信息從單幀靜止圖像中得到,是經典的圖像分類問題。運動信息則通過光流(optical flow)得到,其捕獲了目標在相鄰幀之間的運動情況。
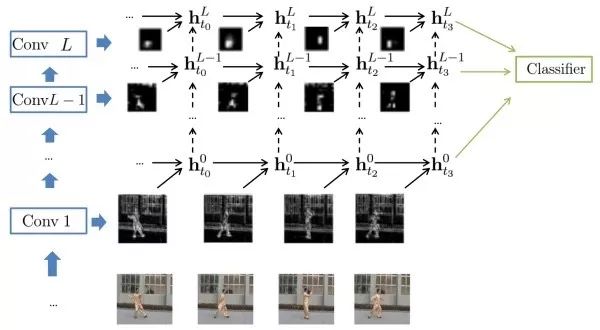
CNN+RNN捕獲遠距離依賴之前的方法只能捕獲幾幀圖像之間的依賴關系,這類方法旨在用CNN提取單幀圖像特征,之后用RNN捕獲幀之間的依賴。
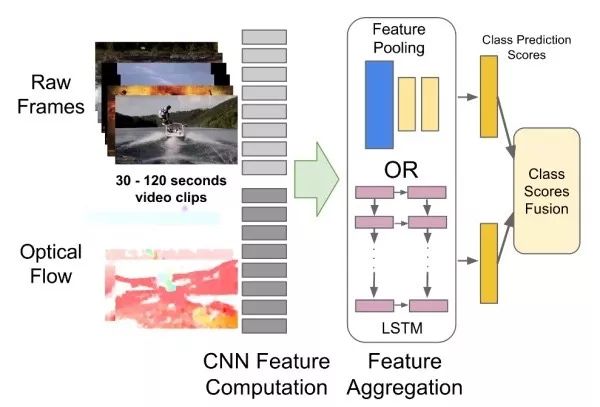
此外,有研究工作試圖將CNN和RNN合二為一,使每個卷積層都能捕獲遠距離依賴。
-
目標跟蹤
+關注
關注
2文章
88瀏覽量
14874 -
人臉識別
+關注
關注
76文章
4005瀏覽量
81764
原文標題:【新智元干貨】計算機視覺必讀:目標跟蹤、網絡壓縮、圖像分類、人臉識別等
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
目標檢測與識別技術的關系是什么
計算機視覺的五大技術
計算機視覺的工作原理和應用
深度學習在計算機視覺領域的應用
計算機視覺的十大算法

計算機視覺與圖像處理、模式識別、機器學習學科之間的關系
計算機視覺:AI如何識別與理解圖像





 工商網監
工商網監
評論