 吳恩達深度學習專項課程的信息圖deeplearning.ai課程總結
吳恩達深度學習專項課程的信息圖deeplearning.ai課程總結
深度學習基礎
1 深度學習基本概念
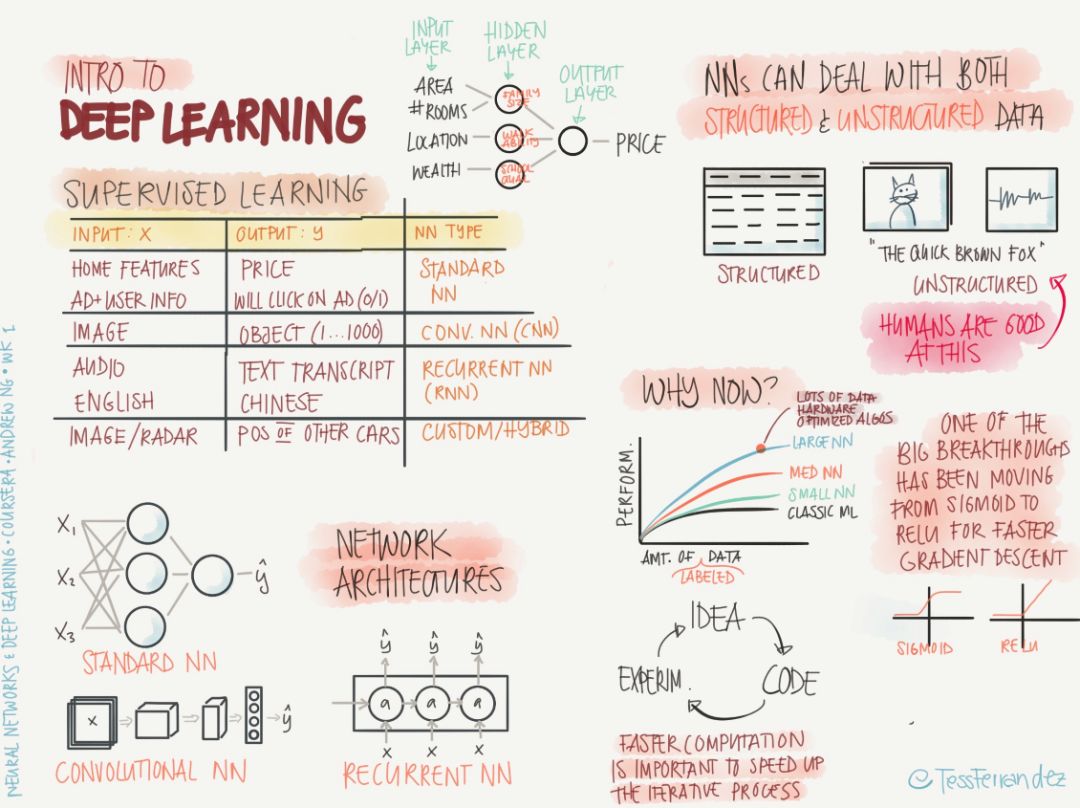
監督學習:所有輸入數據都有確定的對應輸出數據,在各種網絡架構中,輸入數據和輸出數據的節點層都位于網絡的兩端,訓練過程就是不斷地調整它們之間的網絡連接權重。
左上:列出了各種不同網絡架構的監督學習,比如標準的神經網絡(NN)可用于訓練房子特征和房價之間的函數,卷積神經網絡(CNN)可用于訓練圖像和類別之間的函數,循環神經網絡(RNN)可用于訓練語音和文本之間的函數。
左下:分別展示了 NN、CNN 和 RNN 的簡化架構。這三種架構的前向過程各不相同,NN 使用的是權重矩陣(連接)和節點值相乘并陸續傳播至下一層節點的方式;CNN 使用矩形卷積核在圖像輸入上依次進行卷積操作、滑動,得到下一層輸入的方式;RNN 記憶或遺忘先前時間步的信息以為當前計算過程提供長期記憶。
右上:NN 可以處理結構化數據(表格、數據庫等)和非結構化數據(圖像、音頻等)。
右下:深度學習能發展起來主要是由于大數據的出現,神經網絡的訓練需要大量的數據;而大數據本身也反過來促進了更大型網絡的出現。深度學習研究的一大突破是新型激活函數的出現,用 ReLU 函數替換 sigmoid 函數可以在反向傳播中保持快速的梯度下降過程,sigmoid 函數在正無窮處和負無窮處會出現趨于零的導數,這正是梯度消失導致訓練緩慢甚至失敗的主要原因。要研究深度學習,需要學會「idea—代碼—實驗—idea」的良性循環。
2 logistic 回歸
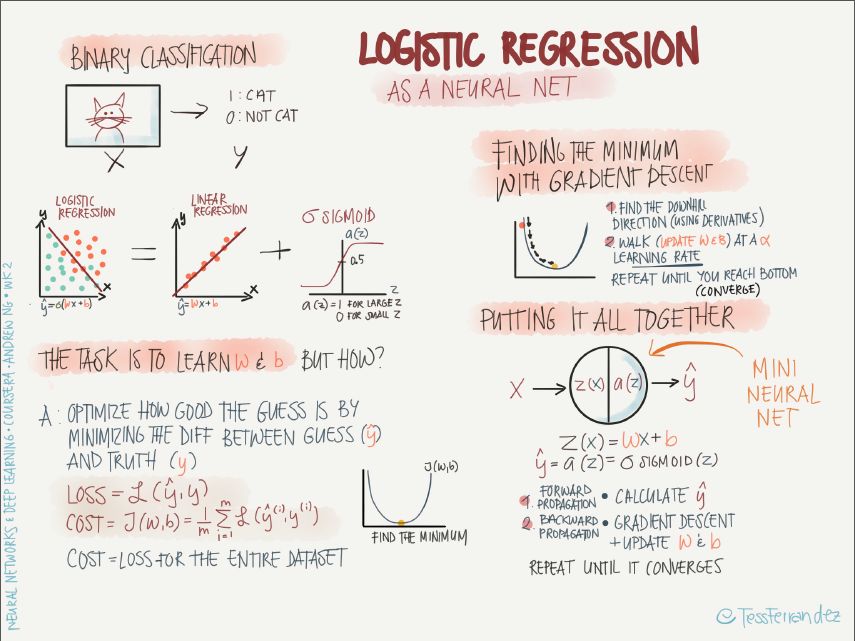
左上:logistic 回歸主要用于二分類問題,如圖中所示,logistic 回歸可以求解一張圖像是不是貓的問題,其中圖像是輸入(x),貓(1)或非貓(0)是輸出。我們可以將 logistic 回歸看成將兩組數據點分離的問題,如果僅有線性回歸(激活函數為線性),則對于非線性邊界的數據點(例如,一組數據點被另一組包圍)是無法有效分離的,因此在這里需要用非線性激活函數替換線性激活函數。在這個案例中,我們使用的是 sigmoid 激活函數,它是值域為(0, 1)的平滑函數,可以使神經網絡的輸出得到連續、歸一(概率值)的結果,例如當輸出節點為(0.2, 0.8)時,判定該圖像是非貓(0)。
左下:神經網絡的訓練目標是確定最合適的權重 w 和偏置項 b,那這個過程是怎么樣的呢?
這個分類其實就是一個優化問題,優化過程的目的是使預測值 y hat 和真實值 y 之間的差距最小,形式上可以通過尋找目標函數的最小值來實現。所以我們首先確定目標函數(損失函數、代價函數)的形式,然后用梯度下降逐步更新 w、b,當損失函數達到最小值或者足夠小時,我們就能獲得很好的預測結果。
右上:損失函數值在參數曲面上變化的簡圖,使用梯度可以找到最快的下降路徑,學習率的大小可以決定收斂的速度和最終結果。學習率較大時,初期收斂很快,不易停留在局部極小值,但后期難以收斂到穩定的值;學習率較小時,情況剛好相反。一般而言,我們希望訓練初期學習率較大,后期學習率較小,之后會介紹變化學習率的訓練方法。
右下:總結整個訓練過程,從輸入節點 x 開始,通過前向傳播得到預測輸出 y hat,用 y hat 和 y 得到損失函數值,開始執行反向傳播,更新 w 和 b,重復迭代該過程,直到收斂。
3 淺層網絡的特點
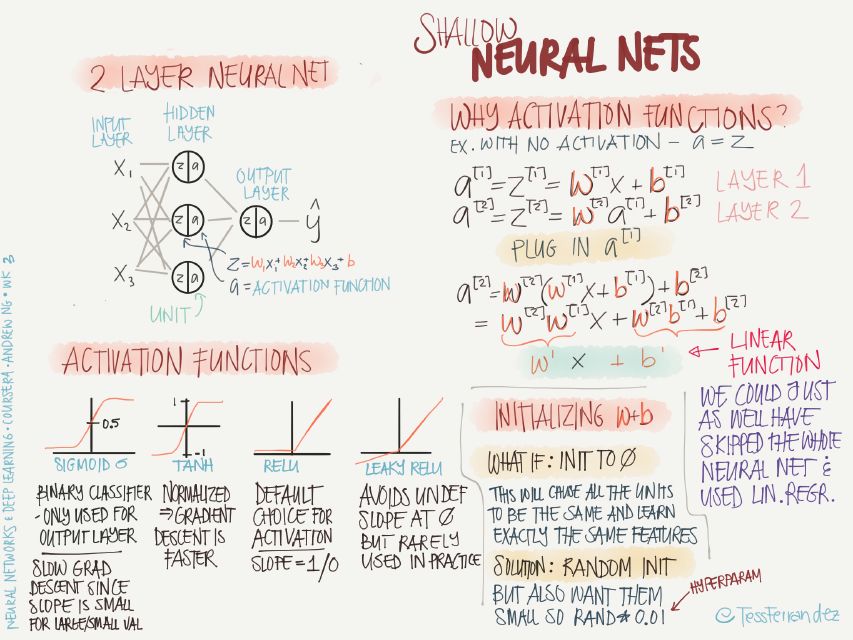
左上:淺層網絡即隱藏層數較少,如圖所示,這里僅有一個隱藏層。
左下:這里介紹了不同激活函數的特點:
sigmoid:sigmoid 函數常用于二分分類問題,或者多分類問題的最后一層,主要是由于其歸一化特性。sigmoid 函數在兩側會出現梯度趨于零的情況,會導致訓練緩慢。
tanh:相對于 sigmoid,tanh 函數的優點是梯度值更大,可以使訓練速度變快。
ReLU:可以理解為閾值激活(spiking model 的特例,類似生物神經的工作方式),該函數很常用,基本是默認選擇的激活函數,優點是不會導致訓練緩慢的問題,并且由于激活值為零的節點不會參與反向傳播,該函數還有稀疏化網絡的效果。
Leaky ReLU:避免了零激活值的結果,使得反向傳播過程始終執行,但在實踐中很少用。
右上:為什么要使用激活函數呢?更準確地說是,為什么要使用非線性激活函數呢?
上圖中的實例可以看出,沒有激活函數的神經網絡經過兩層的傳播,最終得到的結果和單層的線性運算是一樣的,也就是說,沒有使用非線性激活函數的話,無論多少層的神經網絡都等價于單層神經網絡(不包含輸入層)。
右下:如何初始化參數 w、b 的值?
當將所有參數初始化為零的時候,會使所有的節點變得相同,在訓練過程中只能學到相同的特征,而無法學到多層級、多樣化的特征。解決辦法是隨機初始化所有參數,但僅需少量的方差就行,因此使用 Rand(0.01)進行初始化,其中 0.01 也是超參數之一。
4 深度神經網絡的特點
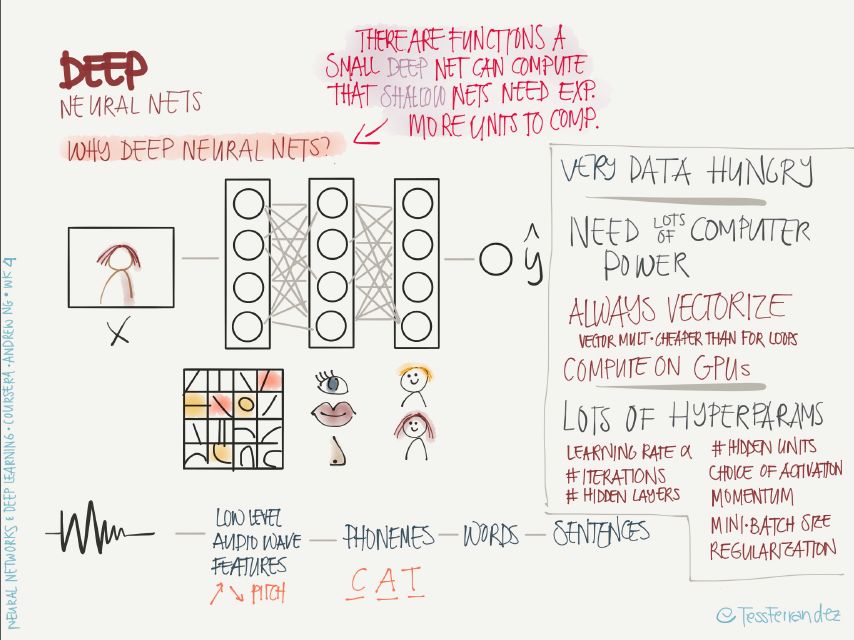
左上:神經網絡的參數化容量隨層數增加而指數式地增長,即某些深度神經網絡能解決的問題,淺層神經網絡需要相對的指數量級的計算才能解決。
左下:CNN 的深度網絡可以將底層的簡單特征逐層組合成越來越復雜的特征,深度越大,其能分類的圖像的復雜度和多樣性就越大。RNN 的深度網絡也是同樣的道理,可以將語音分解為音素,再逐漸組合成字母、單詞、句子,執行復雜的語音到文本任務。
右邊:深度網絡的特點是需要大量的訓練數據和計算資源,其中涉及大量的矩陣運算,可以在 GPU 上并行執行,還包含了大量的超參數,例如學習率、迭代次數、隱藏層數、激活函數選擇、學習率調整方案、批尺寸大小、正則化方法等。
5 偏差與方差
那么部署你的機器學習模型需要注意些什么?下圖展示了構建 ML 應用所需要的數據集分割、偏差與方差等問題。
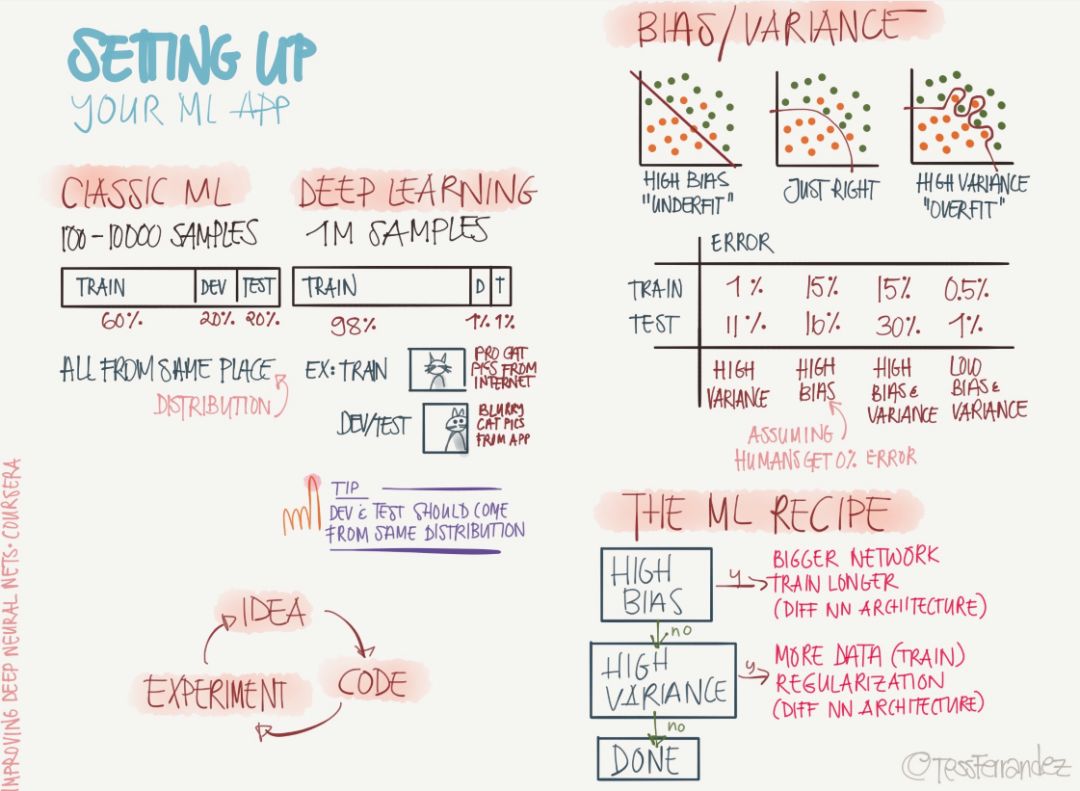
如上所示,經典機器學習和深度學習模型所需要的樣本數有非常大的差別,深度學習的樣本數是經典 ML 的成千上萬倍。因此訓練集、開發集和測試集的分配也有很大的區別,當然我們假設這些不同的數據集都服從同分布。
偏差與方差問題同樣是機器學習模型中常見的挑戰,上圖依次展示了由高偏差帶來的欠擬合和由高方差帶來的過擬合。一般而言,解決高偏差的問題是選擇更復雜的網絡或不同的神經網絡架構,而解決高方差的問題可以添加正則化、減少模型冗余或使用更多的數據進行訓練。
當然,機器學習模型需要注意的問題遠不止這些,但在配置我們的 ML 應用中,它們是最基礎和最重要的部分。其它如數據預處理、數據歸一化、超參數的選擇等都在后面的信息圖中有所體現。
6 正則化
正則化是解決高方差或模型過擬合的主要手段,過去數年,研究者提出和開發了多種適合機器學習算法的正則化方法,如數據增強、L2 正則化(權重衰減)、L1 正則化、Dropout、Drop Connect、隨機池化和提前終止等。
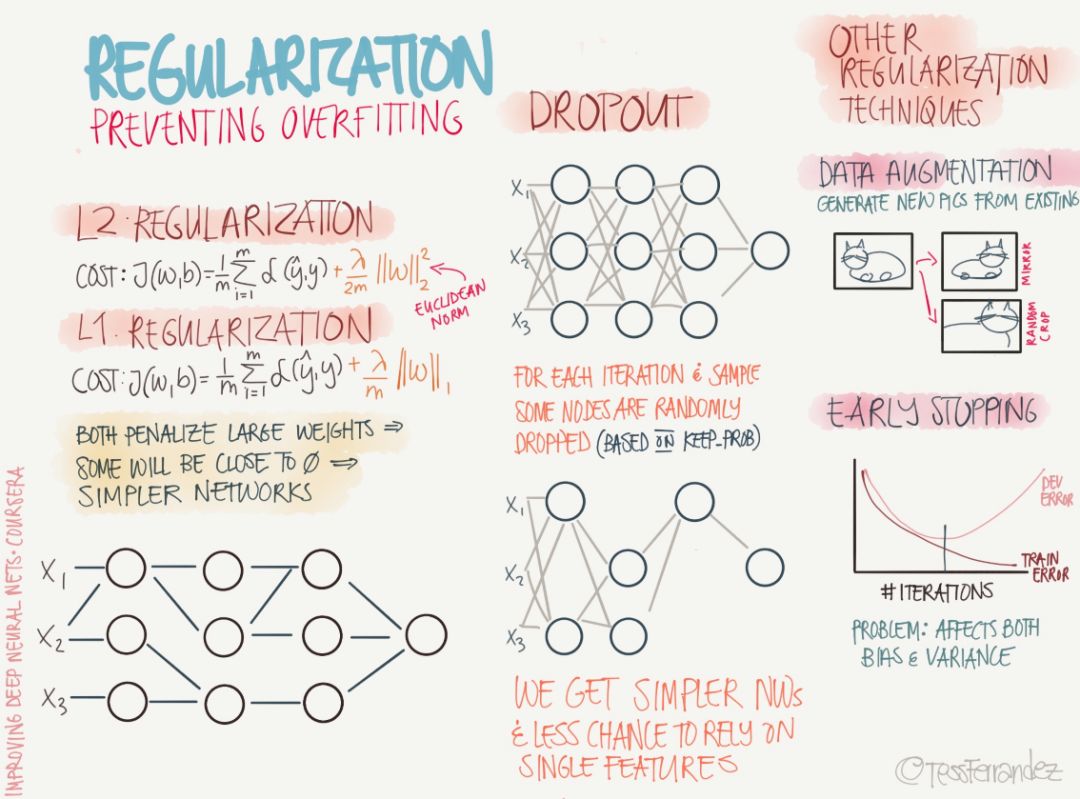
如上圖左列所示,L1 和 L2 正則化也是是機器學習中使用最廣泛的正則化方法。L1 正則化向目標函數添加正則化項,以減少參數的絕對值總和;而 L2 正則化中,添加正則化項的目的在于減少參數平方的總和。根據之前的研究,L1 正則化中的很多參數向量是稀疏向量,因為很多模型導致參數趨近于 0,因此它常用于特征選擇設置中。此外,參數范數懲罰 L2 正則化能讓深度學習算法「感知」到具有較高方差的輸入 x,因此與輸出目標的協方差較小(相對增加方差)的特征權重將會收縮。
在中間列中,上圖展示了 Dropout 技術,即暫時丟棄一部分神經元及其連接的方法。隨機丟棄神經元可以防止過擬合,同時指數級、高效地連接不同網絡架構。一般使用了 Dropout 技術的神經網絡會設定一個保留率 p,然后每一個神經元在一個批量的訓練中以概率 1-p 隨機選擇是否去掉。在最后進行推斷時所有神經元都需要保留,因而有更高的準確度。
Bagging 是通過結合多個模型降低泛化誤差的技術,主要的做法是分別訓練幾個不同的模型,然后讓所有模型表決測試樣例的輸出。而 Dropout 可以被認為是集成了大量深層神經網絡的 Bagging 方法,因此它提供了一種廉價的 Bagging 集成近似方法,能夠訓練和評估值數據數量的神經網絡。
最后,上圖還描述了數據增強與提前終止等正則化方法。數據增強通過向訓練數據添加轉換或擾動來人工增加訓練數據集。數據增強技術如水平或垂直翻轉圖像、裁剪、色彩變換、擴展和旋轉通常應用在視覺表象和圖像分類中。而提前終止通常用于防止訓練中過度表達的模型泛化性能差。如果迭代次數太少,算法容易欠擬合(方差較小,偏差較大),而迭代次數太多,算法容易過擬合(方差較大,偏差較小)。因此,提前終止通過確定迭代次數解決這個問題。
7 最優化
最優化是機器學習模型中非常非常重要的模塊,它不僅主導了整個訓練過程,同時還決定了最后模型性能的好壞和收斂需要的時長。以下兩張信息圖都展示了最優化方法需要關注的知識點,包括最優化的預備和具體的最優化方法。
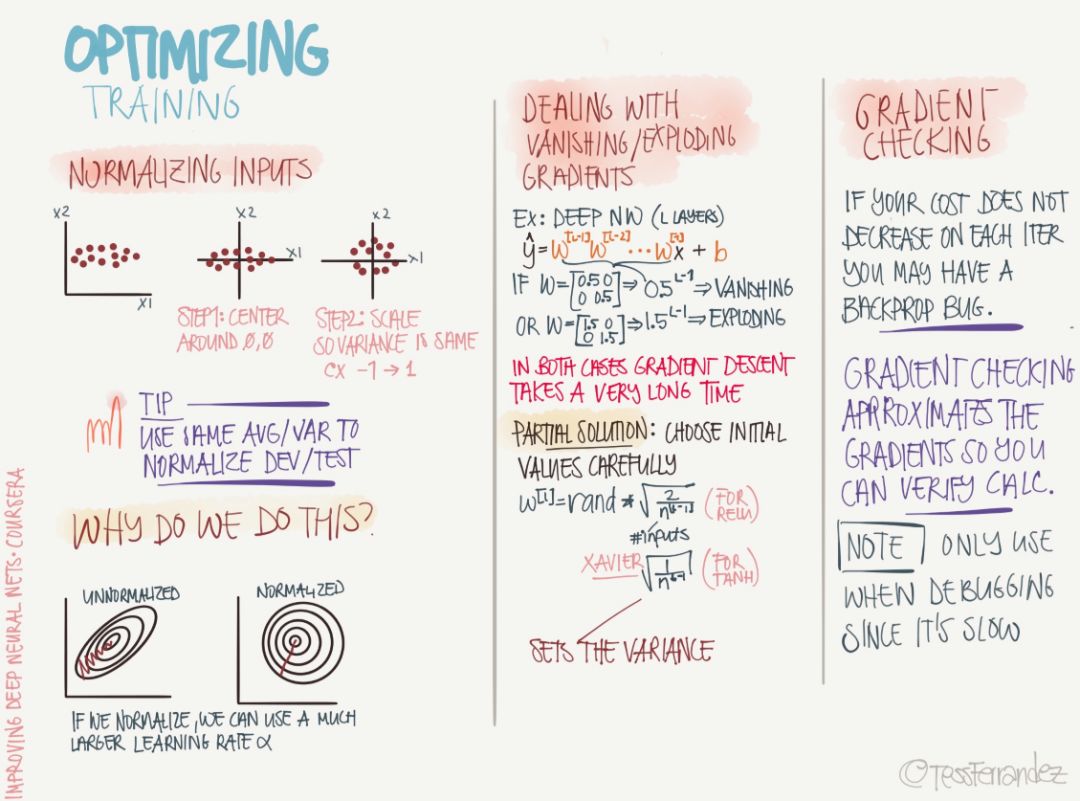
以上展示了最優化常常出現的問題和所需要的操作。首先在執行最優化前,我們需要歸一化輸入數據,而且開發集與測試集歸一化的常數(均值與方差)與訓練集是相同的。上圖也展示了歸一化的原因,因為如果特征之間的量級相差太大,那么損失函數的表面就是一張狹長的橢圓形,而梯度下降或最速下降法會因為「鋸齒」現象而很難收斂,因此歸一化為圓形有助于減少下降方向的震蕩。
后面的梯度消失與梯度爆炸問題也是十分常見的現象。「梯度消失」指的是隨著網絡深度增加,參數的梯度范數指數式減小的現象。梯度很小,意味著參數的變化很緩慢,從而使得學習過程停滯。梯度爆炸指神經網絡訓練過程中大的誤差梯度不斷累積,導致模型權重出現很大的更新,在極端情況下,權重的值變得非常大以至于出現 NaN 值。
梯度檢驗現在可能用的比較少,因為我們在 TensorFlow 或其它框架上執行最優化算法只需要調用優化器就行。梯度檢驗一般是使用數值的方法計算近似的導數并傳播,因此它能檢驗我們基于解析式算出來的梯度是否正確。
下面就是具體的最優化算法了,包括最基本的小批量隨機梯度下降、帶動量的隨機梯度下降和 RMSProp 等適應性學習率算法。
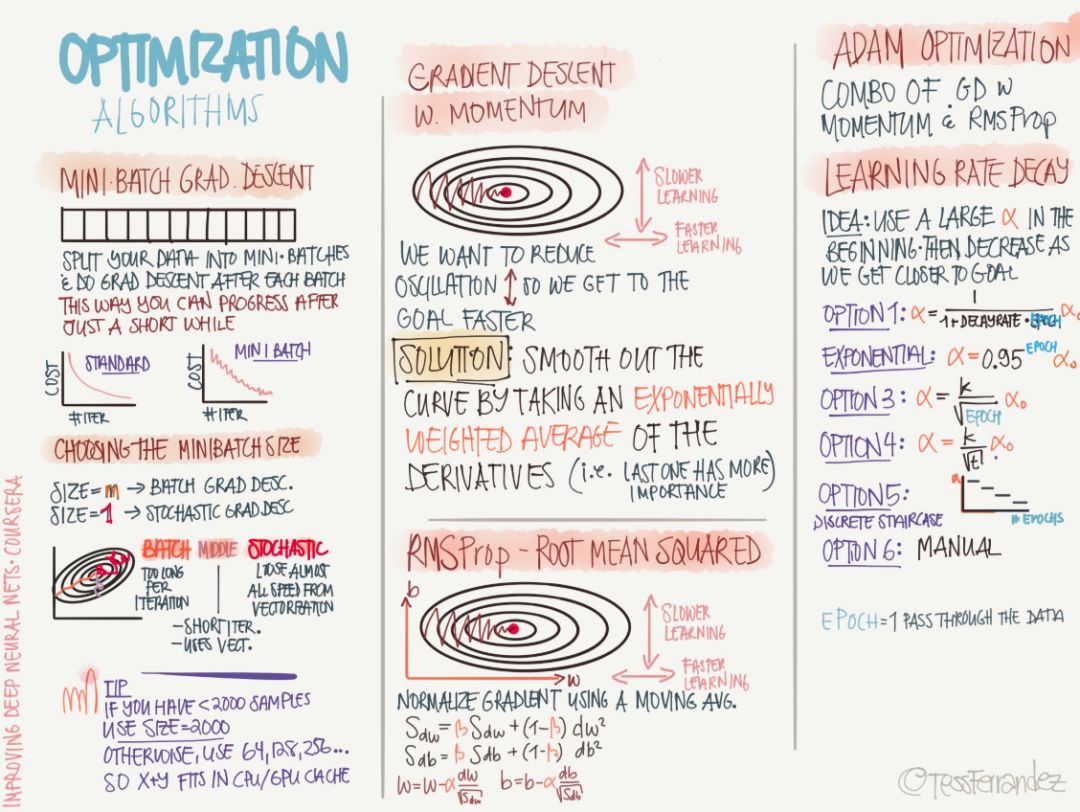
小批量隨機梯度下降(通常 SGD 指的就是這種)使用一個批量的數據更新參數,因此大大降低了一次迭代所需的計算量。這種方法降低了更新參數的方差,使得收斂過程更為穩定;它也能利用流行深度學習框架中高度優化的矩陣運算器,從而高效地求出每個小批數據的梯度。通常一個小批數據含有的樣本數量在 50 至 256 之間,但對于不同的用途也會有所變化。
動量策略旨在加速 SGD 的學習過程,特別是在具有較高曲率的情況下。一般而言,動量算法利用先前梯度的指數衰減滑動平均值在該方向上進行修正,從而更好地利用歷史梯度的信息。該算法引入了變量 v 作為參數在參數空間中持續移動的速度向量,速度一般可以設置為負梯度的指數衰減滑動平均值。
上圖后面所述的 RMSProp 和 Adam 等適應性學習率算法是目前我們最常用的最優化方法。RMSProp 算法(Hinton,2012)修改 AdaGrad 以在非凸情況下表現更好,它改變梯度累積為指數加權的移動平均值,從而丟棄距離較遠的歷史梯度信息。RMSProp 是 Hinton 在公開課上提出的最優化算法,其實它可以視為 AdaDelta 的特例。但實踐證明 RMSProp 有非常好的性能,它目前在深度學習中有非常廣泛的應用。
Adam 算法同時獲得了 AdaGrad 和 RMSProp 算法的優點。Adam 不僅如 RMSProp 算法那樣基于一階矩均值計算適應性參數學習率,它同時還充分利用了梯度的二階矩均值(即有偏方差/uncentered variance)。
8 超參數
以下是介紹超參數的信息圖,它在神經網絡中占據了重要的作用,因為它們可以直接提升模型的性能。
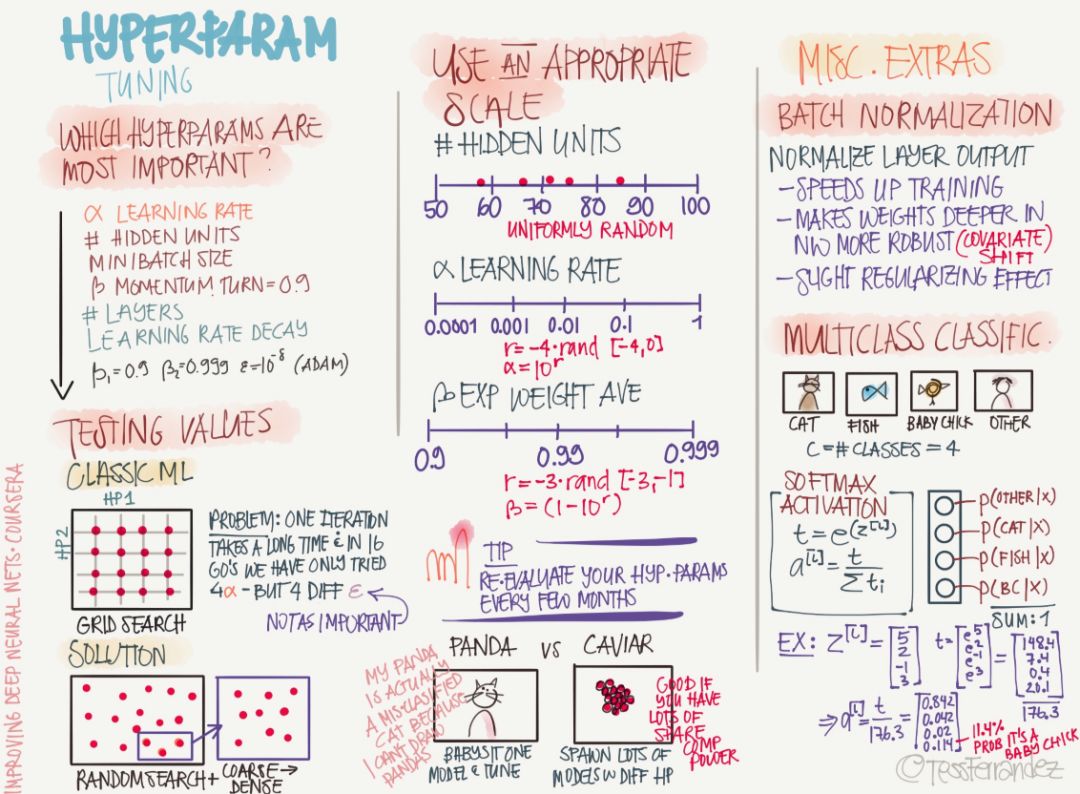
眾所周知學習率、神經網絡隱藏單元數、批量大小、層級數和正則化系數等超參數可以直接影響模型的性能,而怎么調就顯得非常重要。目前最常見的還是手動調參,開發者會根據自身建模經驗選擇「合理」的超參數,然后再根據模型性能做一些小的調整。而自動化調參如隨機過程或貝葉斯優化等仍需要非常大的計算量,且效率比較低。不過近來關于使用強化學習、遺傳算法和神經網絡等方法搜索超參數有很大的進步,研究者都在尋找一種高效而準確的方法。
目前的超參數搜索方法有:
依靠經驗:聆聽自己的直覺,設置感覺上應該對的參數然后看看它是否工作,不斷嘗試直到累趴。
網格搜索:讓計算機嘗試一些在一定范圍內均勻分布的數值。
隨機搜索:讓計算機嘗試一些隨機值,看看它們是否好用。
貝葉斯優化:使用類似 MATLAB bayesopt 的工具自動選取最佳參數——結果發現貝葉斯優化的超參數比你自己的機器學習算法還要多,累覺不愛,回到依靠經驗和網格搜索方法上去。
因為篇幅有限,后面的展示將只簡要介紹信息圖,相信它們對各位讀者都十分有幫助。
9 結構化機器學習過程
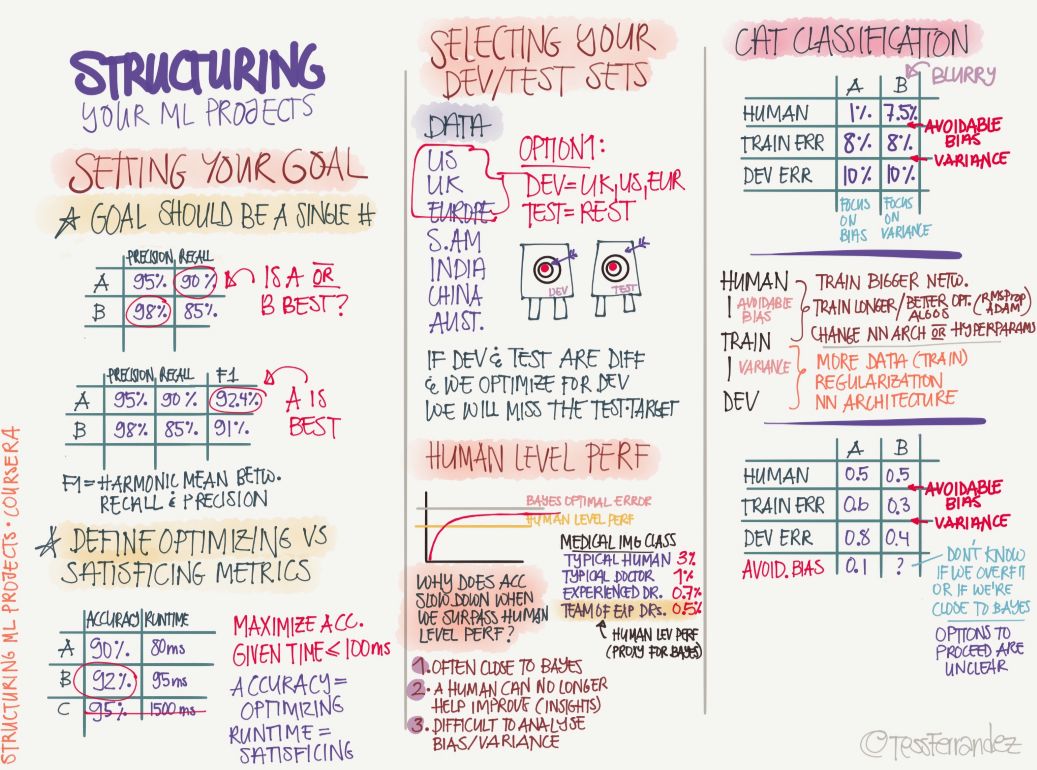
我們需要按過程或結構來設定我們的機器學習系統,首先需要設定模型要達到的目標,例如它的預期性能是多少、度量方法是什么等。然后分割訓練、開發和測試集,并預期可能到達的優化水平。隨后再構建模型并訓練,在開發集和測試集完成驗證后就可以用于推斷了。
10 誤差分析
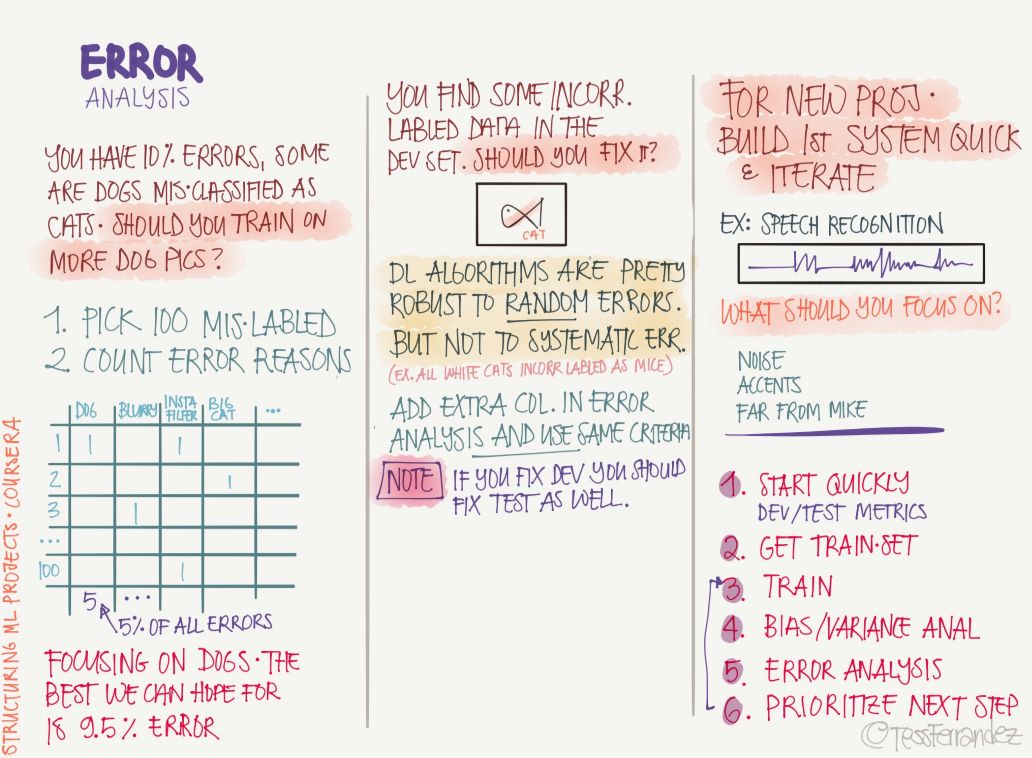
在完成訓練后,我們可以分析誤差的來源而改進性能,包括發現錯誤的標注、不正確的損失函數等。
11 訓練集、開發集與測試集
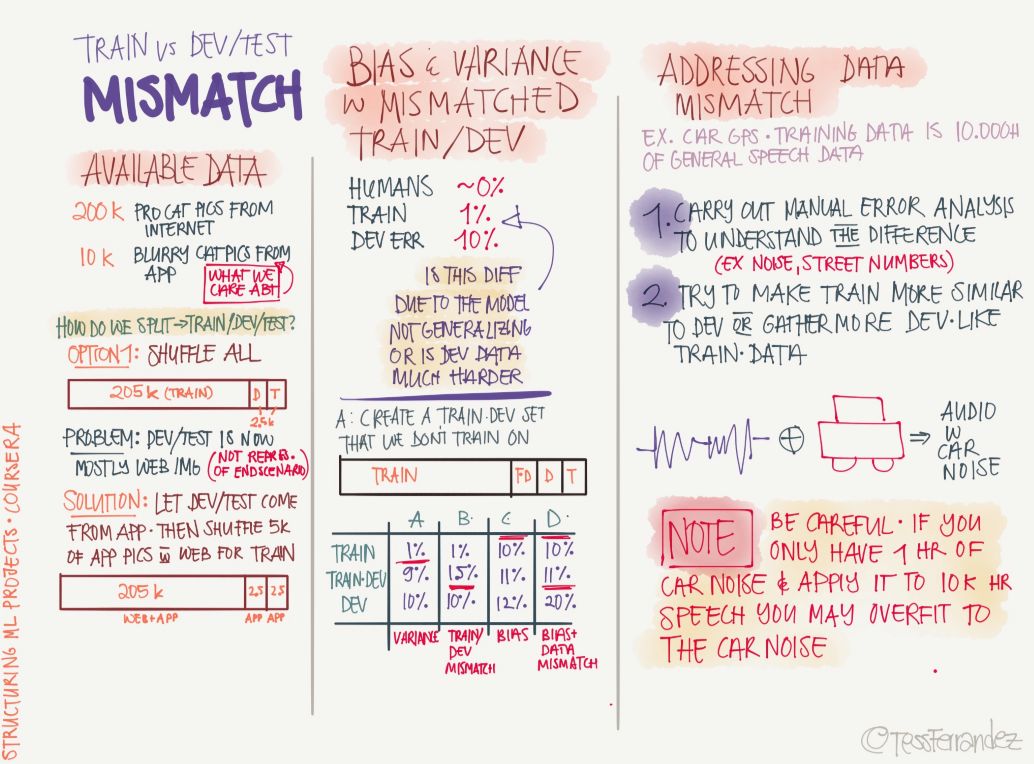
上圖展示了三個分割數據集及其表現所需要注意的地方,也就是說如果它們間有不同的正確率,那么我們該如何修正這些「差別」。例如訓練集的正確率明顯高于驗證集與測試集表明模型過擬合,三個數據集的正確率都明顯低于可接受水平可能是因為欠擬合。
12 其它學習方法
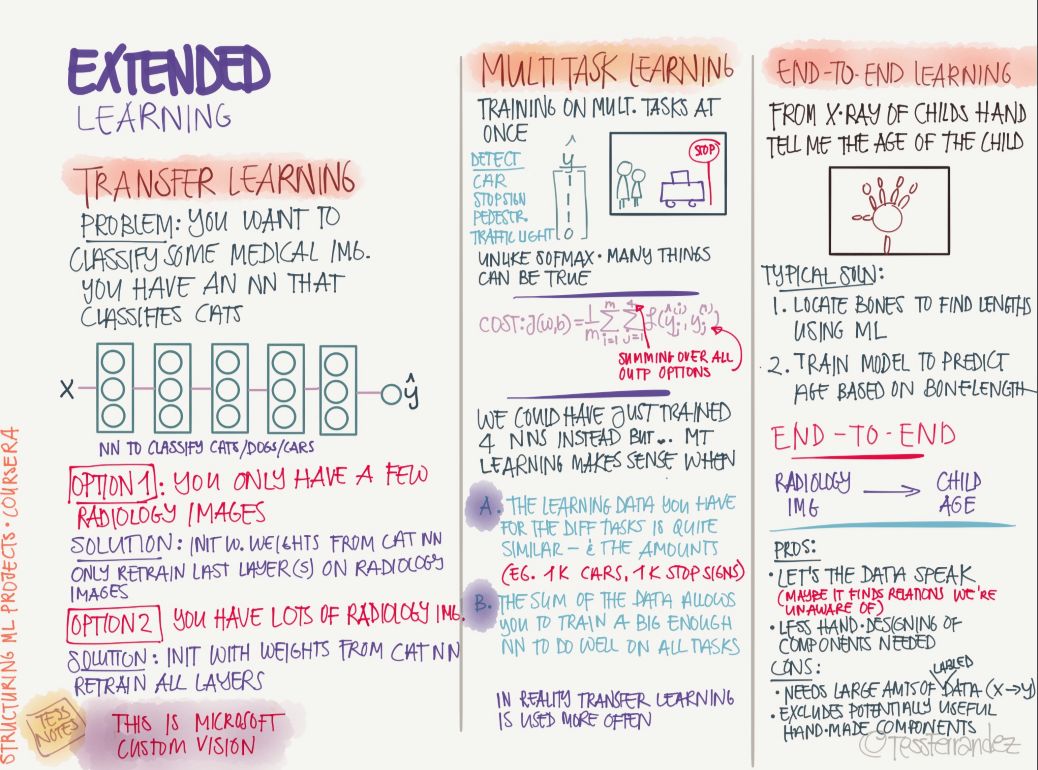
機器學習和深度學習當然不止監督學習方法,還有如遷移學習、多任務學習和端到端的學習等。
卷積網絡
13 卷積神經網絡基礎
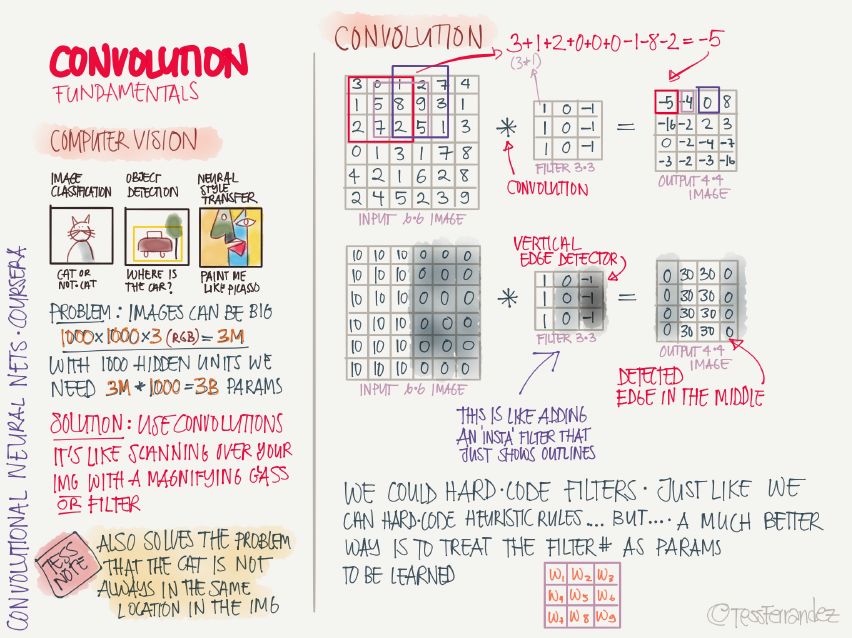
計算機視覺任務涉及的數據體量是特別大的,一張圖像就有上千個數據點,更別提高分辨率圖像和視頻了。這時用全連接網絡的話,參數數量太大,因而改用卷積神經網絡(CNN),參數數量可以極大地減小。CNN 的工作原理就像用檢測特定特征的過濾器掃描整張圖像,進行特征提取,并逐層組合成越來越復雜的特征。這種「掃描」的工作方式使其有很好的參數共享特性,從而能檢測不同位置的相同目標(平移對稱)。
卷積核對應的檢測特征可以從其參數分布簡單地判斷,例如,權重從左到右變小的卷積核可以檢測到黑白豎條紋的邊界,并顯示為中間亮,兩邊暗的特征圖,具體的相對亮暗結果取決于圖像像素分布和卷積核的相對關系。卷積核權重可以直接硬編碼,但為了讓相同的架構適應不同的任務,通過訓練得到卷積核權重是更好的辦法。
卷積運算的主要參數:
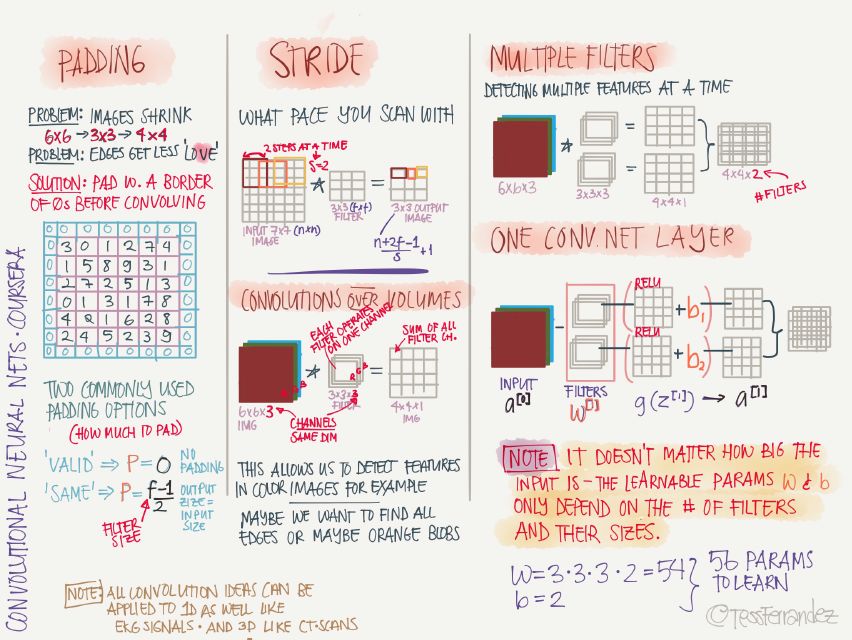
padding:直接的卷積運算會使得到的特征圖越來越小,padding 操作會在圖像周圍添加 0 像素值的邊緣,使卷積后得到的特征圖大小和原圖像(長寬,不包括通道數)相同。
常用的兩個選項是:『VALID』,不執行 padding;『SAME』,使輸出特征圖的長寬和原圖像相同。
stride:兩次卷積操作之間的步長大小。
一個卷積層上可以有多個卷積核,每個卷積核運算得到的結果是一個通道,每個通道的特征圖的長寬相同,可以堆疊起來構成多通道特征圖,作為下一個卷積層的輸入。
深度卷積神經網絡的架構:
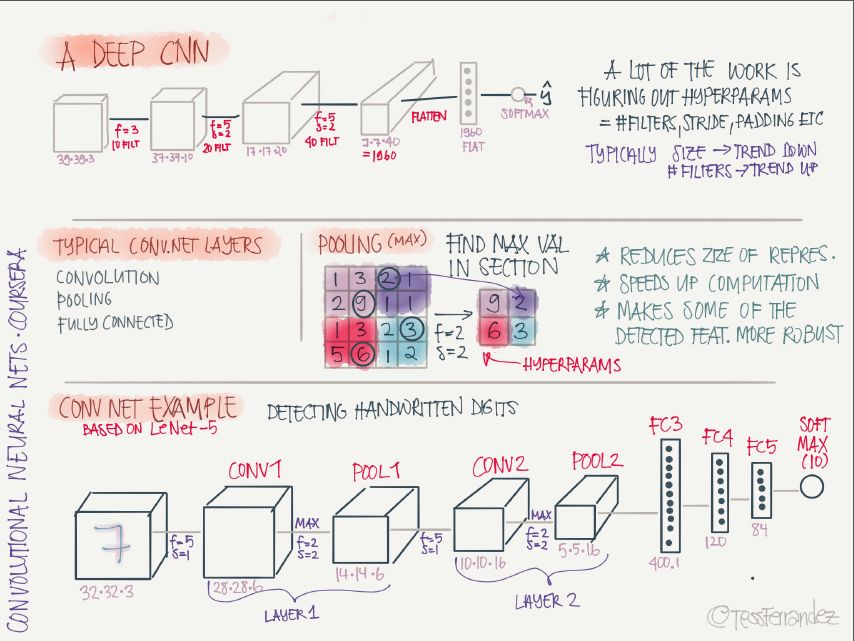
深度卷積神經網絡的架構主要以卷積層、池化層的多級堆疊,最后是全連接層執行分類。池化層的主要作用是減少特征圖尺寸,進而減少參數數量,加速運算,使其目標檢測表現更加魯棒。
14 經典卷積神經網絡
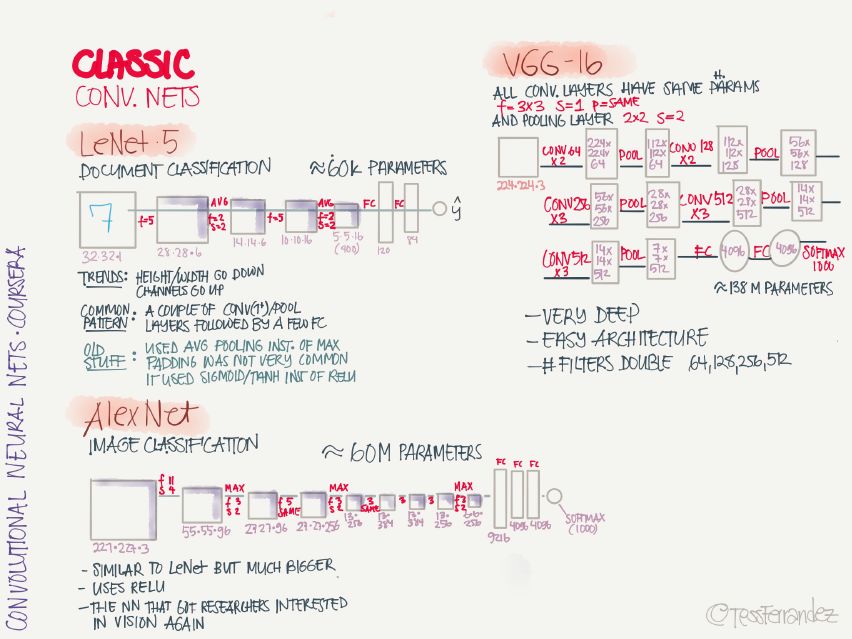
LeNet·5:手寫識別分類網絡,這是第一個卷積神經網絡,由 Yann LeCun 提出。
AlexNet:圖像分類網絡,首次在 CNN 引入 ReLU 激活函數。
VGG-16:圖像分類網絡,深度較大。
15 特殊卷積神經網絡
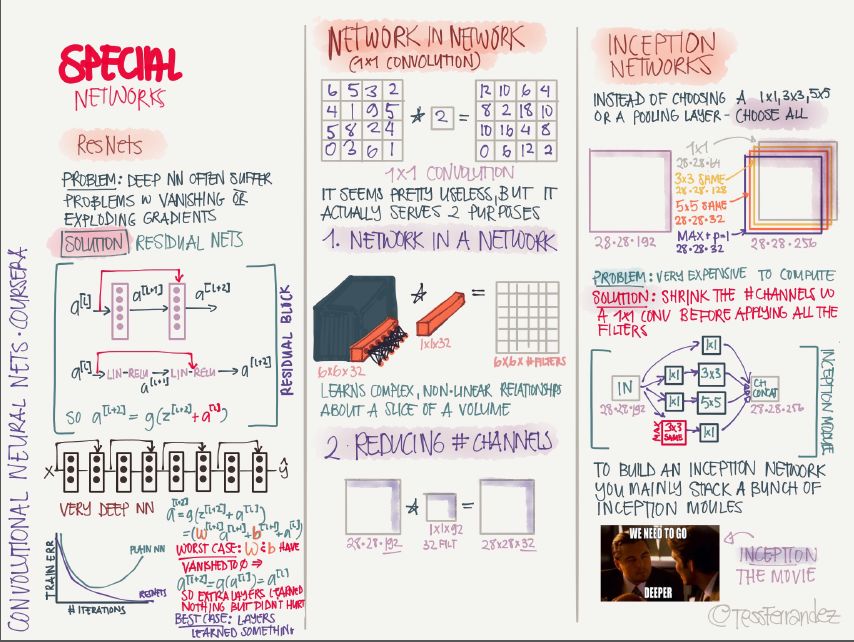
ResNet:引入殘差連接,緩解梯度消失和梯度爆炸問題,可以訓練非常深的網絡。
Network in Network:使用 1x1 卷積核,可以將卷積運算變成類似于全連接網絡的形式,還可以減少特征圖的通道數,從而減少參數數量。
Inception Network:使用了多種尺寸卷積核的并行操作,再堆疊成多個通道,可以捕捉多種規模的特征,但缺點是計算量太大,可以通過 1x1 卷積減少通道數。
16 實踐建議
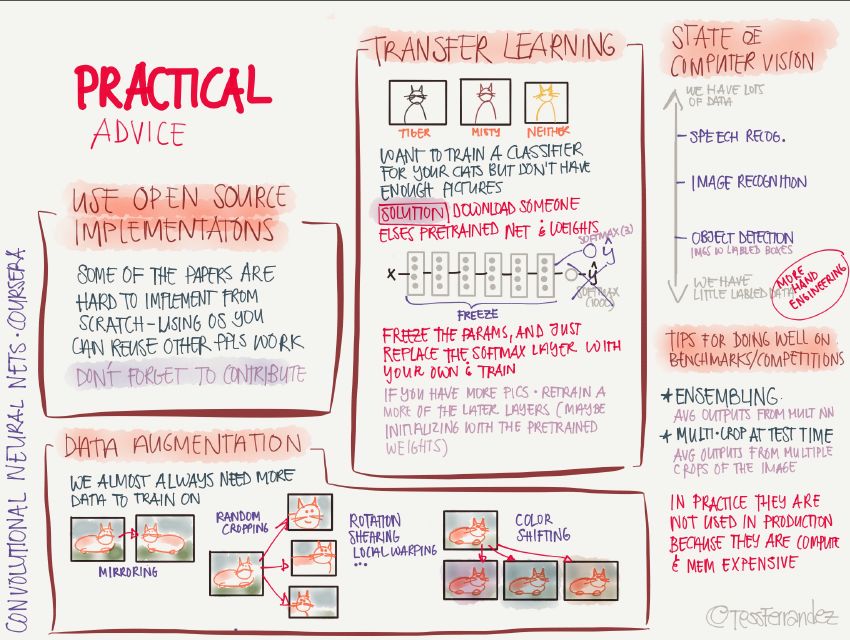
使用開源實現:從零開始實現時非常困難的,利用別人的實現可以快速探索更復雜有趣的任務。
數據增強:通過對原圖像進行鏡像、隨機裁剪、旋轉、顏色變化等操作,增加訓練數據量和多樣性。
遷移學習:針對當前任務的訓練數據太少時,可以將充分訓練過的模型用少量數據微調獲得足夠好的性能。
基準測試和競賽中表現良好的訣竅:使用模型集成,使用多模型輸出的平均結果;在測試階段,將圖像裁剪成多個副本分別測試,并將測試結果取平均。
17 目標檢測算法
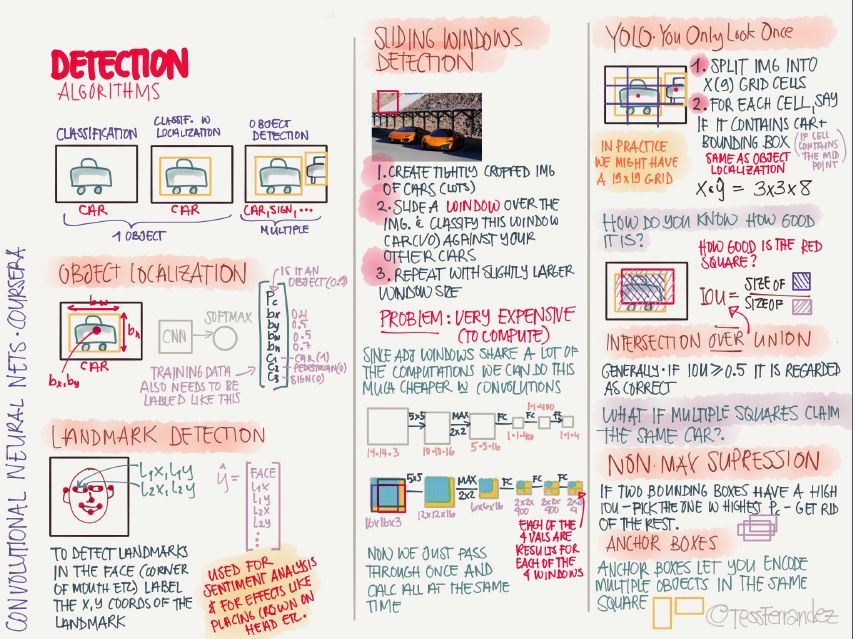
目標檢測即使用邊界框檢測圖像中物體的位置,Faster R-CNN、R-FCN 和 SSD 是三種目前最優且應用最廣泛的目標檢測模型,上圖也展示了 YOLO 的基本過程。
18 人臉識別
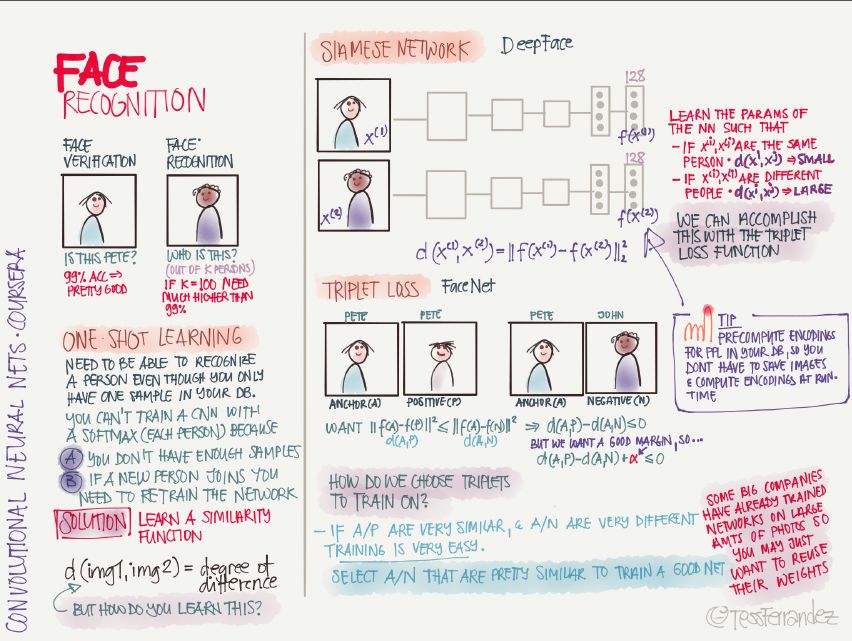
人臉識別有兩大類應用:人臉驗證(二分分類)和人臉識別(多人分類)。
當樣本量不足時,或者不斷有新樣本加入時,需要使用 one-shot learning,解決辦法是學習相似性函數,即確定兩張圖像的相似性。比如在 Siamese Network 中學習人臉識別時,就是利用兩個網絡的輸出,減少同一個人的兩個輸出的差別,增大不同人的兩個輸出之間的差別。
19 風格遷移
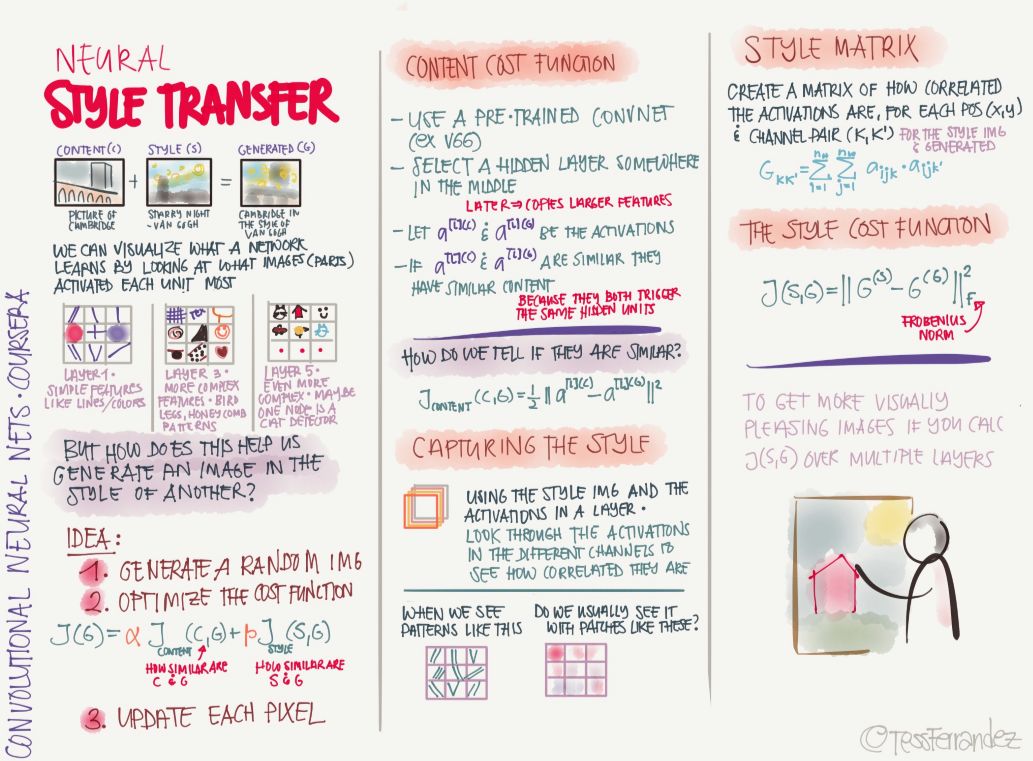
風格遷移是一個熱門話題,它會在視覺上給人耳目一新的感覺。例如你有一副圖,然后將另一幅圖的風格特征應用到這幅圖上,比如用一位著名畫家或某一副名畫的風格來修改你的圖像,因此我們可以獲得獨特風格的作品。
循環網絡
20 循環神經網絡基礎
如上所示,命名實體識別等序列問題在現實生活中占了很大的比例,而隱馬爾可夫鏈等傳統機器學習算法只能作出很強的假設而處理部分序列問題。但近來循環神經網絡在這些問題上有非常大的突破,RNN 隱藏狀態的結構以循環形的形式成記憶,每一時刻的隱藏層的狀態取決于它的過去狀態,這種結構使得 RNN 可以保存、記住和處理長時期的過去復雜信號。
循環神經網絡(RNN)能夠從序列和時序數據中學習特征和長期依賴關系。RNN 具備非線性單元的堆疊,其中單元之間至少有一個連接形成有向循環。訓練好的 RNN 可以建模任何動態系統;但是,訓練 RNN 主要受到學習長期依賴性問題的影響。
以下展示了 RNN 的應用、問題以及變體等:
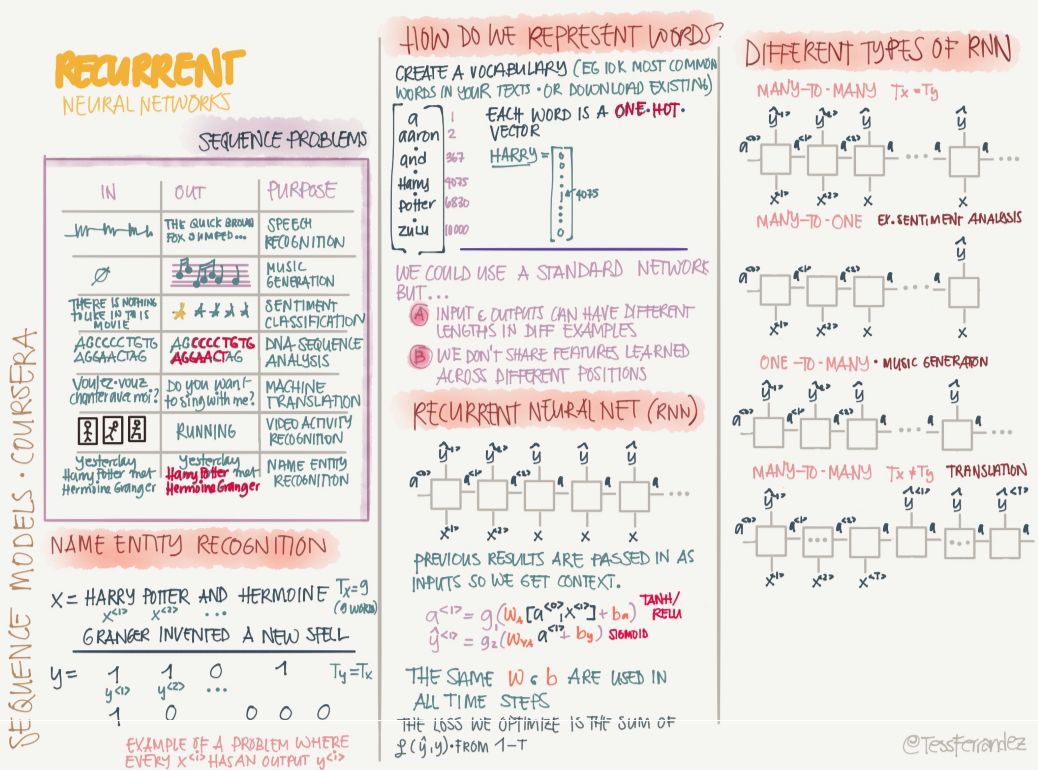
循環神經網絡在語言建模等序列問題上有非常強大的力量,但同時它也存在很嚴重的梯度消失問題。因此像 LSTM 和 GRU 等基于門控的 RNN 有非常大的潛力,它們使用門控機制保留或遺忘前面時間步的信息,并形成記憶以提供給當前的計算過程。
21 NLP 中的詞表征

詞嵌入在自然語言處理中非常重要,因為不論執行怎樣的任務,將詞表征出來都是必須的。上圖展示了詞嵌入的方法,我們可以將詞匯庫映射到一個 200 或 300 維的向量,從而大大減少表征詞的空間。此外,這種詞表征的方法還能表示詞的語義,因為詞義相近的詞在嵌入空間中距離相近。
除了以上所述的 Skip Grams,以下還展示了學習詞嵌入的常見方法:
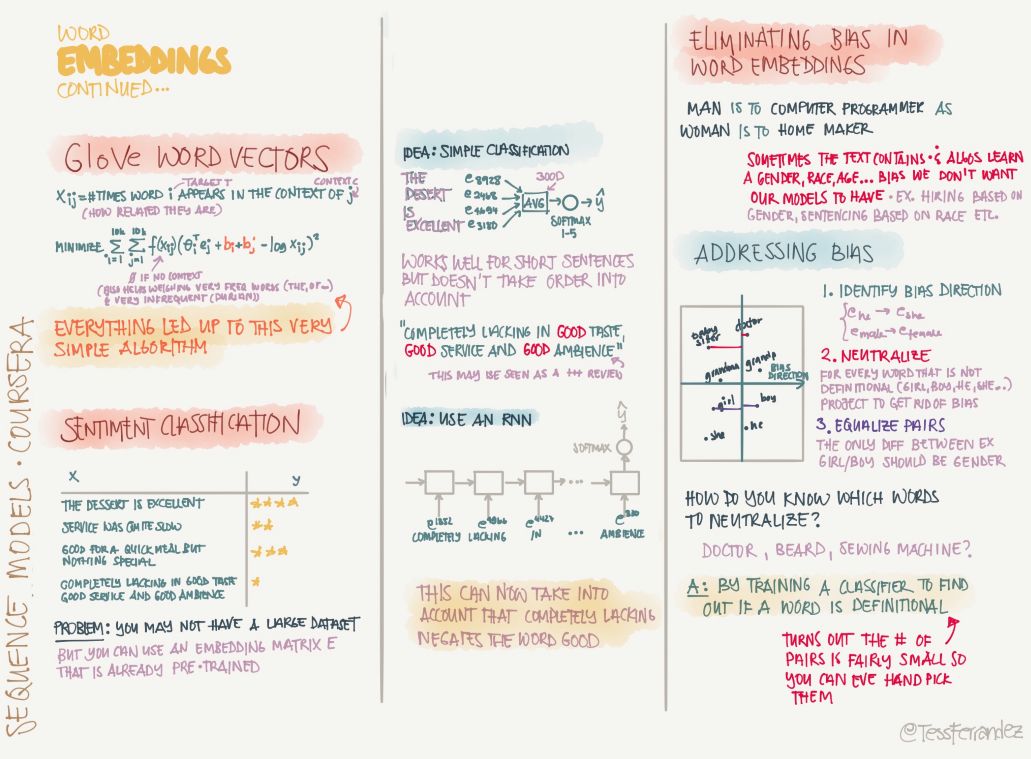
GloVe 詞向量是很常見的詞向量學習方法,它學到的詞表征可進一步用于語句分類等任務。
22 序列到序列
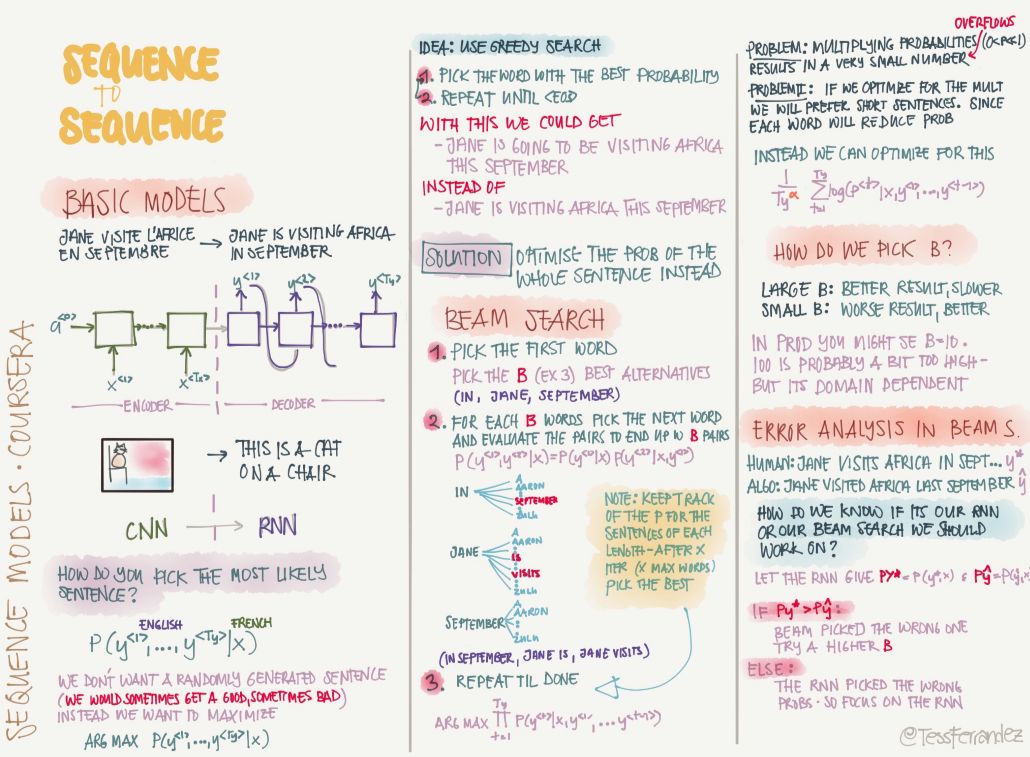
序列到序列的方法使用最多的就是編碼器解碼器框架,其它還有束搜索等模塊的介紹。
編碼器解碼器架構加上注意力機制可以解決非常多的自然語言處理問題,以下介紹了 BLEU 分值和注意力機制。它們在機器翻譯的架構和評估中都是不能缺少的部分。
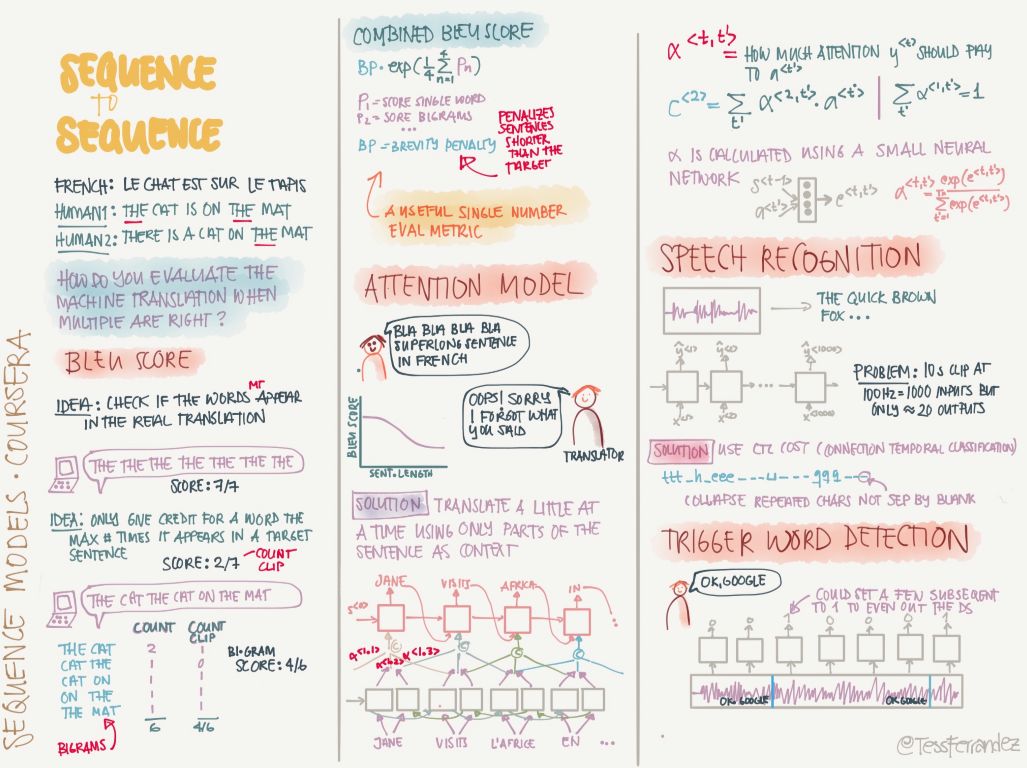
以上是所有關于吳恩達深度學習專項課程的信息圖,由于它們包含的信息較多,我們只介紹了一部分,還有很多內容只是簡單的一筆帶過。所以各位讀者最好可以下載該信息圖,并在后面的學習過程中慢慢理解與優化。
-
神經網絡
+關注
關注
42文章
4764瀏覽量
100541 -
深度學習
+關注
關注
73文章
5493瀏覽量
120979
原文標題:這是一份優美的信息圖,吳恩達點贊的deeplearning.ai課程總結
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論