 如何描述機器學習中的一些綜合能力
如何描述機器學習中的一些綜合能力
當我在閱讀機器學習相關文獻的時候, 我經常思考這項工作是否:
提高了模型的表達能力;
使模型更易于訓練;
提高了模型的泛化性能。
在這篇博文中, 我們討論當前的機器學習研究:監督學習, 無監督學習和強化學習在這些方面的表現。談到模型的泛化性能的時候, 我把它分為兩類:「弱泛化」和「強泛化」。我將會在后面分別討論它們。 下表總結了我眼中的研究現狀:
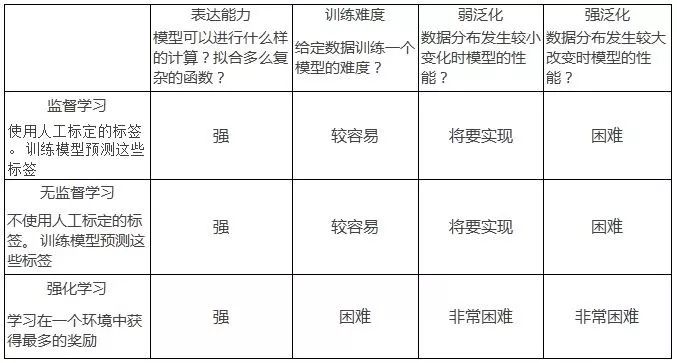
這篇博文涵蓋了相當寬泛的研究領域,僅表達我個人對相關研究的看法,不反映我的同事和公司的觀點。歡迎讀者進行討論以及給出修改的建議, 請在評論中提供反饋或發送電子郵件給我。
表達能力 expressivity
模型可以進行什么樣的計算, 擬合多么復雜的函數?
模型的表達能力用來衡量參數化模型如神經網絡的可以擬合的函數的復雜程度。深度神經網絡的表達能力隨著它的深度指數上升, 這意味著中等規模的神經網絡就擁有表達監督、 半監督、強化學習任務的能力[2]。 深度神經網絡可以記住非常大的數據集就是一個很好的佐證。
最近在產生式模型研究上的突破證明了神經網絡強大的表達能力:神經網絡可以找到幾乎與真實數據難以分辨的極為復雜的數據流形(如音頻, 圖像數據的流形)。下面是NVIDIA研究人員提出的新的基于產生式對抗神經網絡的模型的生成結果:
產生的圖像仍然不是很完美(注意不自然的背景),但是已經非常好了。同樣的, 在音頻合成中,最新的 WaveNet 模型產生的音頻也已經非常像人類了。
在強化學習中神經網絡看起來也有足夠的表達能力。 很小的網絡(2個卷積層2個全連接層)就足夠解決Atari 和 MuJoCo 控制問題了(雖然它們的訓練還是一個問題,我們將在下一個部分討論)。
模型的表達能力問題是最容易的(增加一些層即可), 但同時也是最神秘的:我們無法找到一個很好的方法來度量對于一個給定的任務我們需要多強的(或什么類型的)表達能力。
什么樣的問題會需要比我們現在用的神經網絡大得多的網絡?為什么這些任務需要這么大量的計算?我們現有的神經網絡是否有足夠的表達能力來表現像人類一樣的智能?要解決更加困難的問題的泛化問題會需要表達能力超級強的模型嗎?
人的大腦有比我們現在的大網絡(Inception-ResNet-V2 有大概 25e6 ReLU結點)多很多數量級的「神經節點」(1e11)。 這個結點數量上的差距已經很巨大了, 更別提 ReLU 單元根本無法比擬生物神經元。
訓練難度 trainability
給定一個有足夠表達能力的模型結構, 我能夠訓練出一個好的模型嗎(找到好的參數)
任何一個從數據中學習到一定功能的計算機程序都可以被稱為機器學習模型。在「學習」過程中, 我們在(可能很大的)模型空間內搜索一個比較好的, 利用數據中的知識學到的模型來做決策。 搜索的過程常常被構造成一個在模型空間上的優化問題。

優化的不同類型
一個具體的例子:最小化平均交叉熵是訓練神經網絡分類圖像的標準方法。我們希望模型在訓練集上的交叉熵損失達到最小時, 模型在測試數據上可以以一定精度或召回來正確分類圖像。
搜索好的模型(訓練)最終會變為一個優化問題——沒有別的途徑! 但是有時候我們很難去定義優化目標。 在監督學習中的一個經典的例子就是圖像下采樣:我們無法定義一個標量可以準確反映出我們人眼感受到的下采樣造成的「視覺損失」。
同樣地, 超分辨率圖像和圖像合成也非常困難,因為我們很難把效果的好壞寫成一個標量的最大化目標:想象一下, 如何設計一個函數來判斷一張圖片有多像一張真實的照片?事實上關于如何去評價一個產生式模型的好壞一直爭論到現在。
近年來最受歡迎的的方法是 「協同適應」(co-adaptation)方法:它把優化問題構造成求解兩個相互作用演化的非平穩分布的平衡點求解問題[3]。這種方法比較「自然」, 我們可以將它類比為捕食者和被捕食者之間的生態進化過程。
捕食者會逐漸變得聰明, 這樣它可以更有效地捕獲獵物。然后被捕食者也逐漸變得更聰明以避免被捕食。兩種物種相互促進進化, 最終它們都會變得更加聰明。
演化策略通常把優化看作是仿真。用戶對模型群體指定一些動力系統, 在仿真過程中的每個時間步上, 根據動力系統的運行規則來更新模型群體。 這些模型可能會相互作用也可能不會。 隨著時間的演變, 系統的動態特性可能會使模型群體最終收斂到好的模型上面。
David Ha所著的 《A Visual Guide to Evolution Strategies》 是一部非常好的演化策略在強化學習中應用的教材(其中的「參考文獻和延伸閱讀」部分非常棒!)
研究現狀
監督學習中前饋神經網絡和有顯式目標函數的問題已經基本解決了(經驗之談, 沒有理論保障)。2015年發表的一些重要的突破(批歸一化 Batch Norm,殘差網絡 Resnets,良好初始化 Good Init)現在被廣泛使用, 這使得前饋神經網絡的訓練變得非常容易。
事實上, 數百層的深度網絡已經可以把大的分類數據集的訓練損失減小到零。關于現代深度神經網絡的硬件和算法基礎結構,參考 https://arxiv.org/abs/1703.09039。
有證據表明很多 RNN 結構有相同的表達能力, 模型最終效果的差異僅僅是由于一些結構比另一些更加易于訓練[4]。
無監督學習的模型輸出常常大很多(并不是總是),比如,1024 x 1024 像素的圖片, 很長的語音和文本序列。很不幸, 這導致模型更加難以訓練。
最近 NVIDA 的工作改進了Wasserstein GAN 使之對很多超參, 比如 BN 的參數、網絡結構等不再敏感。模型的穩定性在實踐和工業應用中非常重要:穩定性讓我們相信它會和我們未來的研究思路和應用相兼容。
總的來講, 這些成果令人振奮, 因為這證明了我們的產生網絡有足夠的表達能力來產生正確的圖像, 效果的瓶頸在于訓練的問題——不幸的是對于神經網絡來講我們很難辯別一個模型表現較差僅僅是因為它的表達能力不夠還是我們沒有訓練到位。
不幸的是, 即使在僅僅考慮可訓練性,不考慮泛化的情況下, 強化學習也遠遠地落在了后面。在有多于一個時間步的環境中, 我們實際是在首先搜索一個模型, 這個模型在推理階段會最大化獲得的獎勵。
強化學習比較困難,因為我們要用一個外部的(outer loop)、僅僅依賴角色(agent)見過的數據的優化過程來找到最優的模型, 同時用一個內部的(inner loop)、模型引導的最優控制(optimal control)過程來最大化獲得的獎勵。
不同環境下,實現同樣的算法我們經常得到不同的結果, 因此強化學習文章中報告的結果我們也不能輕易完全相信。
如果我們把強化學習看作一個單純的優化問題(先不考慮模型的泛化和復雜的任務), 這個問題同樣非常棘手。假設現在有一個環境, 只有在一個場景結束時才會有非常稀疏的獎勵(例如:保姆照看孩子, 只有在父母回家時她才會得到酬勞)。
因此, 要想估計模型優化過程中任意一處的策略梯度, 我們都要采樣指數增長的動作空間(action space)中的樣本來獲得一些對學習有用的信號。這就像是我們想要使用蒙特卡洛方法關于一個分布計算期望(在所有動作序列上), 而這個分布集中于一個狄拉克函數(dirac delta distribution)(密度函數見下圖)。
在建議分布(proposal distribution)和獎勵分布(reward distribution)之間幾乎沒有重疊時, 基于有限樣本的蒙特卡洛估計會失效,不管你采了多少樣本。

此外, 如果數據布不是平穩的(比如我們采用帶有重放緩存 replay buffer 的離策略 off-policy 算法), 數據中的「壞點」會給外部的優化過程(outer loop)提供不穩定的反饋。
不從蒙特卡洛估計的角度, 而從優化的角度來看的話:在沒有關于狀態空間的任何先驗的情況下(比如對于世界環境的理解或者顯式地給角色 agent 一些明確的指示), 優化目標函數的形狀(optimization landscape)看起來就像「瑞士芝士」——一個個凸的極值(看作小孔)周圍都是大面積的平地,這樣平坦的「地形」上策略梯度信息幾乎沒用。這意味著整個模型空間幾乎不包含信息(非零的區域幾乎沒有,學習的信號在整個模型空間里是均勻的)。
如果沒有更好的表示方法,我們可能就僅僅是在隨機種子附近游走,隨機采樣一些策略,直到我們幸運地找到一個恰好落在「芝士的洞里」的模型。事實上,這樣訓練出的模型效果其實很好。這說明強化學習的優化目標函數形狀很有可能就是這樣子的。
我相信像 Atari 和 MuJoCo 這樣的強化學習基準模型并沒有真正提高機器學習的能力極限, 雖然從一個單純優化問題來看它們很有趣。這些模型還只是在一個相對簡單的環境中去尋找單一的策略來使模型表現得更好, 沒有任何的選擇性機制讓他們可以泛化。 也就是說, 它們還僅僅是單純的優化問題, 而不是一個復雜的機器學習問題。
要想解決更高維,更復雜的強化學習問題, 在解決數值優化問題之前,我們必須先考慮模型的泛化和一般的感性認知能力。反之就會愚蠢地浪費計算力和數據(當然這可能會讓我們明白僅僅通過暴力計算我們可以做得多好)。
我們要讓每個數據點都給強化學習提供訓練信息,也需要能夠在不用指數增長的數據時就能通過重要性采樣(importance sampling)獲得非常復雜的問題的梯度。只有在這樣的情況下, 我們才能確保通過暴力計算我們可以獲得這個問題的解。
最后做一個總結:監督學習的訓練比較容易。 無監督學習的訓練相對困難但是已經取得了很大的進展。但是對于強化學習,訓練還是一個很大的問題。
泛化性能
在這三個問題中, 泛化性能是最深刻的,也是機器學習的核心問題。簡單來講, 泛化性能用來衡量一個在訓練集上訓練好的模型在測試集上的表現。
泛化問題主要可以分為兩大類:
1) 訓練數據與測試數據來自于同一個分布(我們使用訓練集來學習這個分布)。
2)訓練數據與測試數據來自不同的分布(我們要讓在訓練集上學習的模型在測試集上也表現良好)。
通常我們把(1)稱為「弱泛化」,把(2)稱為「強泛化」。我們也可以把它們理解為「內插(interpolation)」和「外推(extrapolation)」,或「魯棒性(robustness)」與「理解(understanding)」。
弱泛化:考慮訓練集與測試集數據服從兩個類似的分布
如果數據的分布發生了較小的擾動, 模型還能表現得多好?
在「弱泛化」中,我們通常假設訓練集和數據集的數據分布是相同的。但是在實際問題中,即使是「大樣本」(large sample limit)情況下,二者的分布也總會有些許差異。
這些差異有可能來源于傳感器噪聲、物體的磨損、周圍光照條件的變化(可能攝影者收集測試集數據時恰好是陰天)。對抗樣本的出現也可能導致一些不同,對抗的擾動很難被人眼分辨,因此我們可以認為對抗樣本也是從相同的分布里采出來的。
因此,實踐中把「弱泛化」看作是評估模型在「擾動」的訓練集分布上的表現是有用的。

數據分布的擾動也會導致優化目標函數(optimization landscape)的擾動。
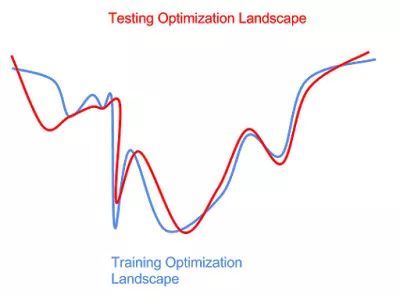
不能事先知道測試數據的分布為我們優化帶來了一些困難。如果我們在訓練集上優化得過于充分(上圖藍色曲線左邊的最低的局部極小點), 我們會得到一個在測試集上并不是最好的模型(紅色曲線左邊的局部極小點)。 這時, 我們就在訓練集上過擬合(overfitting)了, 模型在測試集上沒有很好地泛化。
「正則化」包含一切我們用來防止過擬合的手段。我們一點都不知道測試集分布的擾動是什么,所以我們只能在訓練集或訓練過程中加入噪聲,希望這些引入的噪聲中會包含測試集上的擾動。隨機梯度下降、隨機剪結點(dropout)、權值噪聲(weight noise)、 激活噪聲(activation noise)、 數據增強等都是深度學習中常用的正則化技術。在強化學習中,隨機仿真參數(randomizing simulation parameters)會讓訓練變得更加魯棒。張馳原在 ICLR2017 的報告中認為正則化是所有的可能「增加訓練難度」的方法(而不是傳統上認為的「限制模型容量」)。總的來講,讓優化變得困難一些有助于模型的泛化。
對于弱泛化最大的挑戰可能就是對抗攻擊了。 對抗方法會產生對模型最糟糕的的干擾,在這些擾動下模型會表現得非常差。 我們現在還沒有對對抗樣本魯棒的深度學習方法, 但是我感覺這個問題最終會得到解決[5]。
現在有一些利用信息論的工作表明在訓練過程中神經網絡會明顯地經歷一個由「記住」數據到」壓縮」數據的轉換。這種理論正在興起,雖然仍然有關于這種理論是不是真的有效的討論。請關注這個理論,這個關于「記憶」和」壓縮」的直覺是令人信服的。
強泛化:自然流形
在強泛化范疇,模型是在完全不同的數據分布上進行評估的, 但是數據來自于同一個流形(或數據產生過程)
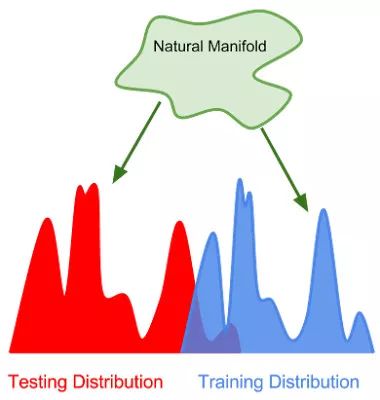
如果測試數據分布于訓練數據分布「完全不同」,我們如何來訓練一個好的模型呢?實際上這些數據都來自同一個「自然數據流形」(natural data manifold)。只要來源于同一個數據產生過程,訓練數據和測試數據仍然含有很多的信息交疊。
強泛化可以看作是模型可以多好地學到這個「超級流形」,訓練這個模型只使用了流形上的很小一部分樣本。一個圖像分類器不需要去發現麥克斯韋方程組——它只需要理解與流形上的數據點相一致的事實。
在 ImageNet 上訓練的現代分類器已經基本上可以做到強泛化了。模型已經可以理解基礎的元素比如邊緣、輪廓以及實體。這也是為什么常常會把這些分類器的權值遷移到其它數據集上來進行少樣本學習(few shot learning)和度量學習(metric learning)。
和弱泛化一樣,我們可以對抗地采樣測試集來讓它的數據分布與訓練集盡量不同。AlphaGo Zero 是我最喜歡的例子:在測試階段,它看到的是與它在訓練階段完全不一樣的, 來自人類選手的數據。
遺憾的是, 強化學習的研究忽略了強泛化問題。 大部分的基準都基于靜態的環境, 沒有多少認知的內容(比如人型機器人只知道一些關節的位置可能會帶來獎勵, 而不知道它的它的世界和它的身體是什么樣子的)。
我相信解決強化學習可訓練性問題的關鍵在于解決泛化性。我們的學習系統對世界的理解越多,它就更容易獲得學習的信號可能需要更少的樣本。這也是為什么說少樣本學習(few shot learning)、模仿學習(imitation learning)、學習如何學習(learning to learn)重要的原因了:它們將使我們擺脫采用方差大而有用信息少的暴力求解方式。
我相信要達到更強的泛化,我們要做到兩件事:
首先我們需要模型可以從觀察和實驗中積極推理世界基本規律。符號推理(symbolic reasoning)和因果推理(causal inference)看起來已經是成熟的研究了, 但是對任何一種無監督學習可能都有幫助。
我們的基于模型的機器學習方法(試圖去「預測」環境的模型)現在正處于哥白尼革命之前的時期:它們僅僅是膚淺地基于一些統計原理進行內插,而不是提出深刻的,一般性的原理來解釋和推斷可能在數百萬光年以外或很久遠的未來的事情。
注意人類不需要對概率論有很好的掌握就能推導出確定性的天體力學,這就產生了一個問題:是否有可能在沒有明確的統計框架下進行機器學習和因果推理?
讓我們的學習系統更具適應性可以大大降低復雜性。我們需要訓練可以在線實時地思考、記憶、學習的模型,而不僅僅是只能靜態地預測和行動的模型。
其次, 我們需要把足夠多樣的數據送給模型來促使它學到更為抽象的表示。
沒有這些限制的話,學習本身就是欠定義的,我們能夠恰好找到一個好的解的可能性也非常小。 也許如果人類不能站起來看到天空,就不會想要知道為什么星星會以這樣奇怪的橢圓形軌跡運行,也就不會獲得智慧。
-
AI
+關注
關注
87文章
30154瀏覽量
268423 -
人工智能
+關注
關注
1791文章
46862瀏覽量
237587 -
機器學習
+關注
關注
66文章
8378瀏覽量
132412
原文標題:如何理解和評價機器學習中的表達能力、訓練難度和泛化性能
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是機器學習?通過機器學習方法能解決哪些問題?

eda在機器學習中的應用
分享一些常見的電路

具身智能與機器學習的關系
【「時間序列與機器學習」閱讀體驗】+ 簡單建議
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
機器學習中的數據分割方法
機器學習中的數據預處理與特征工程
機器學習在數據分析中的應用
細談SolidWorks教育版的一些基礎知識
FPGA在深度學習應用中或將取代GPU
【量子計算機重構未來 | 閱讀體驗】+機器學習的終點是量子計算?
晶振電路中電容電阻的一些基本原理和作用解析





 工商網監
工商網監
評論