") 一款隨Linux內(nèi)核代碼維護(hù)的性能診斷工具
一款隨Linux內(nèi)核代碼維護(hù)的性能診斷工具
Perf Event 是一款隨 Linux 內(nèi)核代碼一同發(fā)布和維護(hù)的性能診斷工具,由內(nèi)核社區(qū)維護(hù)和發(fā)展。Perf 不僅可以用于應(yīng)用程序的性能統(tǒng)計(jì)分析,也可以應(yīng)用于內(nèi)核代碼的性能統(tǒng)計(jì)和分析。得益于其優(yōu)秀的體系結(jié)構(gòu)設(shè)計(jì),越來越多的新功能被加入 Perf,使其已經(jīng)成為一個多功能的性能統(tǒng)計(jì)工具集 。在第一部分,將介紹 Perf 在應(yīng)用程序開發(fā)上的應(yīng)用。
Perf 簡介Perf 是用來進(jìn)行軟件性能分析的工具。
通過它,應(yīng)用程序可以利用 PMU,tracepoint 和內(nèi)核中的特殊計(jì)數(shù)器來進(jìn)行性能統(tǒng)計(jì)。它不但可以分析指定應(yīng)用程序的性能問題 (per thread),也可以用來分析內(nèi)核的性能問題,當(dāng)然也可以同時分析應(yīng)用代碼和內(nèi)核,從而全面理解應(yīng)用程序中的性能瓶頸。
最初的時候,它叫做 Performance counter,在 2.6.31 中第一次亮相。此后他成為內(nèi)核開發(fā)最為活躍的一個領(lǐng)域。在 2.6.32 中它正式改名為 Performance Event,因?yàn)?perf 已不再僅僅作為 PMU 的抽象,而是能夠處理所有的性能相關(guān)的事件。
使用 perf,您可以分析程序運(yùn)行期間發(fā)生的硬件事件,比如 instructions retired ,processor clock cycles 等;您也可以分析軟件事件,比如 Page Fault 和進(jìn)程切換。
這使得 Perf 擁有了眾多的性能分析能力,舉例來說,使用 Perf 可以計(jì)算每個時鐘周期內(nèi)的指令數(shù),稱為 IPC,IPC 偏低表明代碼沒有很好地利用 CPU。Perf 還可以對程序進(jìn)行函數(shù)級別的采樣,從而了解程序的性能瓶頸究竟在哪里等等。Perf 還可以替代 strace,可以添加動態(tài)內(nèi)核 probe 點(diǎn),還可以做 benchmark 衡量調(diào)度器的好壞。。。
人們或許會稱它為進(jìn)行性能分析的“瑞士軍刀”,但我不喜歡這個比喻,我覺得 perf 應(yīng)該是一把世間少有的倚天劍。
金庸筆下的很多人都有對寶刀的癖好,即便本領(lǐng)低微不配擁有,但是喜歡,便無可奈何。我恐怕正如這些人一樣,因此進(jìn)了酒館客棧,見到相熟或者不相熟的人,就要興沖沖地要講講那倚天劍的故事。
背景知識有些背景知識是分析性能問題時需要了解的。比如硬件 cache;再比如操作系統(tǒng)內(nèi)核。應(yīng)用程序的行為細(xì)節(jié)往往是和這些東西互相牽扯的,這些底層的東西會以意想不到的方式影響應(yīng)用程序的性能,比如某些程序無法充分利用 cache,從而導(dǎo)致性能下降。比如不必要地調(diào)用過多的系統(tǒng)調(diào)用,造成頻繁的內(nèi)核 / 用戶切換。等等。方方面面,這里只是為本文的后續(xù)內(nèi)容做一些鋪墊,關(guān)于調(diào)優(yōu)還有很多東西,我所不知道的比知道的要多的多。
它指的是,需求是開發(fā)的起點(diǎn),先有需求再有功能分支(feature branch)或者補(bǔ)丁分支(hotfix branch)。完成開發(fā)后,該分支就合并到主分支,然后被刪除。
性能相關(guān)的處理器硬件特性,PMU 簡介
當(dāng)算法已經(jīng)優(yōu)化,代碼不斷精簡,人們調(diào)到最后,便需要斤斤計(jì)較了。cache 啊,流水線啊一類平時不大注意的東西也必須精打細(xì)算了。
它指的是,需求是開發(fā)的起點(diǎn),先有需求再有功能分支(feature branch)或者補(bǔ)丁分支(hotfix branch)。完成開發(fā)后,該分支就合并到主分支,然后被刪除。
硬件特性之 cache
內(nèi)存讀寫是很快的,但還是無法和處理器的指令執(zhí)行速度相比。為了從內(nèi)存中讀取指令和數(shù)據(jù),處理器需要等待,用處理器的時間來衡量,這種等待非常漫長。Cache 是一種 SRAM,它的讀寫速率非常快,能和處理器處理速度相匹配。因此將常用的數(shù)據(jù)保存在 cache 中,處理器便無須等待,從而提高性能。Cache 的尺寸一般都很小,充分利用 cache 是軟件調(diào)優(yōu)非常重要的部分。
它指的是,需求是開發(fā)的起點(diǎn),先有需求再有功能分支(feature branch)或者補(bǔ)丁分支(hotfix branch)。完成開發(fā)后,該分支就合并到主分支,然后被刪除。
硬件特性之流水線,超標(biāo)量體系結(jié)構(gòu),亂序執(zhí)行
提高性能最有效的方式之一就是并行。處理器在硬件設(shè)計(jì)時也盡可能地并行,比如流水線,超標(biāo)量體系結(jié)構(gòu)以及亂序執(zhí)行。
處理器處理一條指令需要分多個步驟完成,比如先取指令,然后完成運(yùn)算,最后將計(jì)算結(jié)果輸出到總線上。在處理器內(nèi)部,這可以看作一個三級流水線,如下圖所示:
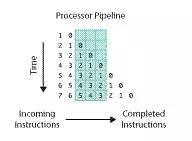
指令從左邊進(jìn)入處理器,上圖中的流水線有三級,一個時鐘周期內(nèi)可以同時處理三條指令,分別被流水線的不同部分處理。
超標(biāo)量(superscalar)指一個時鐘周期發(fā)射多條指令的流水線機(jī)器架構(gòu),比如 Intel 的 Pentium 處理器,內(nèi)部有兩個執(zhí)行單元,在一個時鐘周期內(nèi)允許執(zhí)行兩條指令。
此外,在處理器內(nèi)部,不同指令所需要的處理步驟和時鐘周期是不同的,如果嚴(yán)格按照程序的執(zhí)行順序執(zhí)行,那么就無法充分利用處理器的流水線。因此指令有可能被亂序執(zhí)行。
上述三種并行技術(shù)對所執(zhí)行的指令有一個基本要求,即相鄰的指令相互沒有依賴關(guān)系。假如某條指令需要依賴前面一條指令的執(zhí)行結(jié)果數(shù)據(jù),那么 pipeline 便失去作用,因?yàn)榈诙l指令必須等待第一條指令完成。因此好的軟件必須盡量避免這種代碼的生成。
它指的是,需求是開發(fā)的起點(diǎn),先有需求再有功能分支(feature branch)或者補(bǔ)丁分支(hotfix branch)。完成開發(fā)后,該分支就合并到主分支,然后被刪除。
硬件特性之分支預(yù)測
分支指令對軟件性能有比較大的影響。尤其是當(dāng)處理器采用流水線設(shè)計(jì)之后,假設(shè)流水線有三級,當(dāng)前進(jìn)入流水的第一條指令為分支指令。假設(shè)處理器順序讀取指令,那么如果分支的結(jié)果是跳轉(zhuǎn)到其他指令,那么被處理器流水線預(yù)取的后續(xù)兩條指令都將被放棄,從而影響性能。為此,很多處理器都提供了分支預(yù)測功能,根據(jù)同一條指令的歷史執(zhí)行記錄進(jìn)行預(yù)測,讀取最可能的下一條指令,而并非順序讀取指令。
分支預(yù)測對軟件結(jié)構(gòu)有一些要求,對于重復(fù)性的分支指令序列,分支預(yù)測硬件能得到較好的預(yù)測結(jié)果,而對于類似 switch case 一類的程序結(jié)構(gòu),則往往無法得到理想的預(yù)測結(jié)果。
上面介紹的幾種處理器特性對軟件的性能有很大的影響,然而依賴時鐘進(jìn)行定期采樣的 profiler 模式無法揭示程序?qū)@些處理器硬件特性的使用情況。處理器廠商針對這種情況,在硬件中加入了 PMU 單元,即 performance monitor unit。
PMU 允許軟件針對某種硬件事件設(shè)置 counter,此后處理器便開始統(tǒng)計(jì)該事件的發(fā)生次數(shù),當(dāng)發(fā)生的次數(shù)超過 counter 內(nèi)設(shè)置的值后,便產(chǎn)生中斷。比如 cache miss 達(dá)到某個值后,PMU 便能產(chǎn)生相應(yīng)的中斷。
捕獲這些中斷,便可以考察程序?qū)@些硬件特性的利用效率了。
它指的是,需求是開發(fā)的起點(diǎn),先有需求再有功能分支(feature branch)或者補(bǔ)丁分支(hotfix branch)。完成開發(fā)后,該分支就合并到主分支,然后被刪除。
Tracepoints
Tracepoint 是散落在內(nèi)核源代碼中的一些 hook,一旦使能,它們便可以在特定的代碼被運(yùn)行到時被觸發(fā),這一特性可以被各種 trace/debug 工具所使用。Perf 就是該特性的用戶之一。
假如您想知道在應(yīng)用程序運(yùn)行期間,內(nèi)核內(nèi)存管理模塊的行為,便可以利用潛伏在 slab 分配器中的 tracepoint。當(dāng)內(nèi)核運(yùn)行到這些 tracepoint 時,便會通知 perf。
Perf 將 tracepoint 產(chǎn)生的事件記錄下來,生成報(bào)告,通過分析這些報(bào)告,調(diào)優(yōu)人員便可以了解程序運(yùn)行時期內(nèi)核的種種細(xì)節(jié),對性能癥狀作出更準(zhǔn)確的診斷。
perf 的基本使用說明一個工具的最佳途徑是列舉一個例子。
考查下面這個例子程序。其中函數(shù) longa() 是個很長的循環(huán),比較浪費(fèi)時間。函數(shù) foo1 和 foo2 將分別調(diào)用該函數(shù) 10 次,以及 100 次。
清單 1. 測試程序 t1
//test.c void longa() { int i,j; for(i = 0; i < 1000000; i++) j=i; //am I silly or crazy? I feel boring and desperate. } void foo2() { int i; for(i=0 ; i < 10; i++) longa(); } void foo1() { int i; for(i = 0; i< 100; i++) longa(); } int main(void) { foo1(); foo2(); }
找到這個程序的性能瓶頸無需任何工具,肉眼的閱讀便可以完成。Longa() 是這個程序的關(guān)鍵,只要提高它的速度,就可以極大地提高整個程序的運(yùn)行效率。
但,因?yàn)槠浜唵危瑓s正好可以用來演示 perf 的基本使用。假如 perf 告訴您這個程序的瓶頸在別處,您就不必再浪費(fèi)寶貴時間閱讀本文了。
它指的是,需求是開發(fā)的起點(diǎn),先有需求再有功能分支(feature branch)或者補(bǔ)丁分支(hotfix branch)。完成開發(fā)后,該分支就合并到主分支,然后被刪除。
準(zhǔn)備使用 perf
安裝 perf 非常簡單,只要您有 2.6.31 以上的內(nèi)核源代碼,那么進(jìn)入 tools/perf 目錄然后敲入下面兩個命令即可:
make make install
性能調(diào)優(yōu)工具如 perf,Oprofile 等的基本原理都是對被監(jiān)測對象進(jìn)行采樣,最簡單的情形是根據(jù) tick 中斷進(jìn)行采樣,即在 tick 中斷內(nèi)觸發(fā)采樣點(diǎn),在采樣點(diǎn)里判斷程序當(dāng)時的上下文。假如一個程序 90% 的時間都花費(fèi)在函數(shù) foo() 上,那么 90% 的采樣點(diǎn)都應(yīng)該落在函數(shù) foo() 的上下文中。運(yùn)氣不可捉摸,但我想只要采樣頻率足夠高,采樣時間足夠長,那么以上推論就比較可靠。因此,通過 tick 觸發(fā)采樣,我們便可以了解程序中哪些地方最耗時間,從而重點(diǎn)分析。
稍微擴(kuò)展一下思路,就可以發(fā)現(xiàn)改變采樣的觸發(fā)條件使得我們可以獲得不同的統(tǒng)計(jì)數(shù)據(jù):
以時間點(diǎn) ( 如 tick) 作為事件觸發(fā)采樣便可以獲知程序運(yùn)行時間的分布。
以 cache miss 事件觸發(fā)采樣便可以知道 cache miss 的分布,即 cache 失效經(jīng)常發(fā)生在哪些程序代碼中。如此等等。
因此讓我們先來了解一下 perf 中能夠觸發(fā)采樣的事件有哪些。
它指的是,需求是開發(fā)的起點(diǎn),先有需求再有功能分支(feature branch)或者補(bǔ)丁分支(hotfix branch)。完成開發(fā)后,該分支就合并到主分支,然后被刪除。
Perf list,perf 事件
使用 perf list 命令可以列出所有能夠觸發(fā) perf 采樣點(diǎn)的事件。比如
$ perf list List of pre-defined events (to be used in -e): cpu-cycles OR cycles [Hardware event] instructions [Hardware event] … cpu-clock [Software event] task-clock [Software event] context-switches OR cs [Software event] … ext4:ext4_allocate_inode [Tracepoint event] kmem:kmalloc [Tracepoint event] module:module_load [Tracepoint event] workqueue:workqueue_execution [Tracepoint event] sched:sched_{wakeup,switch} [Tracepoint event] syscalls:sys_{enter,exit}_epoll_wait [Tracepoint event] …
不同的系統(tǒng)會列出不同的結(jié)果,在 2.6.35 版本的內(nèi)核中,該列表已經(jīng)相當(dāng)?shù)拈L,但無論有多少,我們可以將它們劃分為三類:
Hardware Event 是由 PMU 硬件產(chǎn)生的事件,比如 cache 命中,當(dāng)您需要了解程序?qū)τ布匦缘氖褂们闆r時,便需要對這些事件進(jìn)行采樣;
Software Event 是內(nèi)核軟件產(chǎn)生的事件,比如進(jìn)程切換,tick 數(shù)等 ;
Tracepoint event 是內(nèi)核中的靜態(tài) tracepoint 所觸發(fā)的事件,這些 tracepoint 用來判斷程序運(yùn)行期間內(nèi)核的行為細(xì)節(jié),比如 slab 分配器的分配次數(shù)等。
上述每一個事件都可以用于采樣,并生成一項(xiàng)統(tǒng)計(jì)數(shù)據(jù),時至今日,尚沒有文檔對每一個 event 的含義進(jìn)行詳細(xì)解釋。我希望能和大家一起努力,以弄明白更多的 event 為目標(biāo)。。。
它指的是,需求是開發(fā)的起點(diǎn),先有需求再有功能分支(feature branch)或者補(bǔ)丁分支(hotfix branch)。完成開發(fā)后,該分支就合并到主分支,然后被刪除。
Perf stat
做任何事都最好有條有理。老手往往能夠做到不慌不忙,循序漸進(jìn),而新手則往往東一下,西一下,不知所措。
面對一個問題程序,最好采用自頂向下的策略。先整體看看該程序運(yùn)行時各種統(tǒng)計(jì)事件的大概,再針對某些方向深入細(xì)節(jié)。而不要一下子扎進(jìn)瑣碎細(xì)節(jié),會一葉障目的。
有些程序慢是因?yàn)橛?jì)算量太大,其多數(shù)時間都應(yīng)該在使用 CPU 進(jìn)行計(jì)算,這叫做 CPU bound 型;有些程序慢是因?yàn)檫^多的 IO,這種時候其 CPU 利用率應(yīng)該不高,這叫做 IO bound 型;對于 CPU bound 程序的調(diào)優(yōu)和 IO bound 的調(diào)優(yōu)是不同的。
如果您認(rèn)同這些說法的話,Perf stat 應(yīng)該是您最先使用的一個工具。它通過概括精簡的方式提供被調(diào)試程序運(yùn)行的整體情況和匯總數(shù)據(jù)。
還記得我們前面準(zhǔn)備的那個例子程序么?現(xiàn)在將它編譯為可執(zhí)行文件 t1
gcc – o t1 – g test.c
下面演示了 perf stat 針對程序 t1 的輸出:
$perf stat ./t1 Performance counter stats for './t1': 262.738415 task-clock-msecs # 0.991 CPUs 2 context-switches # 0.000 M/sec 1 CPU-migrations # 0.000 M/sec 81 page-faults # 0.000 M/sec 9478851 cycles # 36.077 M/sec (scaled from 98.24%) 6771 instructions # 0.001 IPC (scaled from 98.99%) 111114049 branches # 422.908 M/sec (scaled from 99.37%) 8495 branch-misses # 0.008 % (scaled from 95.91%) 12152161 cache-references # 46.252 M/sec (scaled from 96.16%) 7245338 cache-misses # 27.576 M/sec (scaled from 95.49%) 0.265238069 seconds time elapsed 上面告訴我們,程序 t1 是一個 CPU bound 型,因?yàn)?task-clock-msecs 接近 1。
對 t1 進(jìn)行調(diào)優(yōu)應(yīng)該要找到熱點(diǎn) ( 即最耗時的代碼片段 ),再看看是否能夠提高熱點(diǎn)代碼的效率。
缺省情況下,除了 task-clock-msecs 之外,perf stat 還給出了其他幾個最常用的統(tǒng)計(jì)信息:
Task-clock-msecs:CPU 利用率,該值高,說明程序的多數(shù)時間花費(fèi)在 CPU 計(jì)算上而非 IO。
Context-switches:進(jìn)程切換次數(shù),記錄了程序運(yùn)行過程中發(fā)生了多少次進(jìn)程切換,頻繁的進(jìn)程切換是應(yīng)該避免的。
Cache-misses:程序運(yùn)行過程中總體的 cache 利用情況,如果該值過高,說明程序的 cache 利用不好
CPU-migrations:表示進(jìn)程 t1 運(yùn)行過程中發(fā)生了多少次 CPU 遷移,即被調(diào)度器從一個 CPU 轉(zhuǎn)移到另外一個 CPU 上運(yùn)行。
Cycles:處理器時鐘,一條機(jī)器指令可能需要多個 cycles,
Instructions: 機(jī)器指令數(shù)目。
IPC:是 Instructions/Cycles 的比值,該值越大越好,說明程序充分利用了處理器的特性。
Cache-references: cache 命中的次數(shù)
Cache-misses: cache 失效的次數(shù)。
通過指定 -e 選項(xiàng),您可以改變 perf stat 的缺省事件 ( 關(guān)于事件,在上一小節(jié)已經(jīng)說明,可以通過 perf list 來查看 )。假如您已經(jīng)有很多的調(diào)優(yōu)經(jīng)驗(yàn),可能會使用 -e 選項(xiàng)來查看您所感興趣的特殊的事件。
它指的是,需求是開發(fā)的起點(diǎn),先有需求再有功能分支(feature branch)或者補(bǔ)丁分支(hotfix branch)。完成開發(fā)后,該分支就合并到主分支,然后被刪除。
perf Top
使用 perf stat 的時候,往往您已經(jīng)有一個調(diào)優(yōu)的目標(biāo)。比如我剛才寫的那個無聊程序 t1。
也有些時候,您只是發(fā)現(xiàn)系統(tǒng)性能無端下降,并不清楚究竟哪個進(jìn)程成為了貪吃的 hog。
此時需要一個類似 top 的命令,列出所有值得懷疑的進(jìn)程,從中找到需要進(jìn)一步審查的家伙。類似法制節(jié)目中辦案民警常常做的那樣,通過查看監(jiān)控錄像從茫茫人海中找到行為古怪的那些人,而不是到大街上抓住每一個人來審問。
Perf top 用于實(shí)時顯示當(dāng)前系統(tǒng)的性能統(tǒng)計(jì)信息。該命令主要用來觀察整個系統(tǒng)當(dāng)前的狀態(tài),比如可以通過查看該命令的輸出來查看當(dāng)前系統(tǒng)最耗時的內(nèi)核函數(shù)或某個用戶進(jìn)程。
讓我們再設(shè)計(jì)一個例子來演示吧。
不知道您怎么想,反正我覺得做一件有益的事情很難,但做點(diǎn)兒壞事兒卻非常容易。我很快就想到了如代碼清單 2 所示的一個程序:
清單 2. 一個死循環(huán)
while (1) i++;
我叫他 t2。啟動 t2,然后用 perf top 來觀察:
下面是 perf top 的可能輸出:
PerfTop: 705 irqs/sec kernel:60.4% [1000Hz cycles] -------------------------------------------------- sampl pcnt function DSO 1503.00 49.2% t2 72.00 2.2% pthread_mutex_lock /lib/libpthread-2.12.so 68.00 2.1% delay_tsc [kernel.kallsyms] 55.00 1.7% aes_dec_blk [aes_i586] 55.00 1.7% drm_clflush_pages [drm] 52.00 1.6% system_call [kernel.kallsyms] 49.00 1.5% __memcpy_ssse3 /lib/libc-2.12.so 48.00 1.4% __strstr_ia32 /lib/libc-2.12.so 46.00 1.4% unix_poll [kernel.kallsyms] 42.00 1.3% __ieee754_pow /lib/libm-2.12.so 41.00 1.2% do_select [kernel.kallsyms] 40.00 1.2% pixman_rasterize_edges libpixman-1.so.0.18.0 37.00 1.1% _raw_spin_lock_irqsave [kernel.kallsyms] 36.00 1.1% _int_malloc /lib/libc-2.12.so ^C
很容易便發(fā)現(xiàn) t2 是需要關(guān)注的可疑程序。不過其作案手法太簡單:肆無忌憚地浪費(fèi)著 CPU。所以我們不用再做什么其他的事情便可以找到問題所在。但現(xiàn)實(shí)生活中,影響性能的程序一般都不會如此愚蠢,所以我們往往還需要使用其他的 perf 工具進(jìn)一步分析。
通過添加 -e 選項(xiàng),您可以列出造成其他事件的 TopN 個進(jìn)程 / 函數(shù)。比如 -e cache-miss,用來看看誰造成的 cache miss 最多。
它指的是,需求是開發(fā)的起點(diǎn),先有需求再有功能分支(feature branch)或者補(bǔ)丁分支(hotfix branch)。完成開發(fā)后,該分支就合并到主分支,然后被刪除。
3使用 perf record, 解讀 report
使用 top 和 stat 之后,您可能已經(jīng)大致有數(shù)了。要進(jìn)一步分析,便需要一些粒度更細(xì)的信息。比如說您已經(jīng)斷定目標(biāo)程序計(jì)算量較大,也許是因?yàn)橛行┐a寫的不夠精簡。那么面對長長的代碼文件,究竟哪幾行代碼需要進(jìn)一步修改呢?這便需要使用 perf record 記錄單個函數(shù)級別的統(tǒng)計(jì)信息,并使用 perf report 來顯示統(tǒng)計(jì)結(jié)果。
您的調(diào)優(yōu)應(yīng)該將注意力集中到百分比高的熱點(diǎn)代碼片段上,假如一段代碼只占用整個程序運(yùn)行時間的 0.1%,即使您將其優(yōu)化到僅剩一條機(jī)器指令,恐怕也只能將整體的程序性能提高 0.1%。俗話說,好鋼用在刀刃上,不必我多說了。
仍以 t1 為例。
perf record – e cpu-clock ./t1 perf report
結(jié)果如下圖所示:
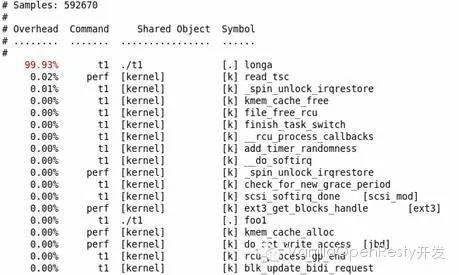
不出所料,hot spot 是 longa( ) 函數(shù)。
但,代碼是非常復(fù)雜難說的,t1 程序中的 foo1() 也是一個潛在的調(diào)優(yōu)對象,為什么要調(diào)用 100 次那個無聊的 longa() 函數(shù)呢?但我們在上圖中無法發(fā)現(xiàn) foo1 和 foo2,更無法了解他們的區(qū)別了。
我曾發(fā)現(xiàn)自己寫的一個程序居然有近一半的時間花費(fèi)在 string 類的幾個方法上,string 是 C++ 標(biāo)準(zhǔn),我絕不可能寫出比 STL 更好的代碼了。因此我只有找到自己程序中過多使用 string 的地方。因此我很需要按照調(diào)用關(guān)系進(jìn)行顯示的統(tǒng)計(jì)信息。
使用 perf 的 -g 選項(xiàng)便可以得到需要的信息:
perf record – e cpu-clock – g ./t1 perf report
結(jié)果如下圖所示:
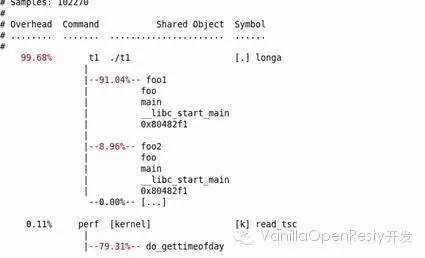
通過對 calling graph 的分析,能很方便地看到 91% 的時間都花費(fèi)在 foo1() 函數(shù)中,因?yàn)樗{(diào)用了 100 次 longa() 函數(shù),因此假如 longa() 是個無法優(yōu)化的函數(shù),那么程序員就應(yīng)該考慮優(yōu)化 foo1,減少對 longa() 的調(diào)用次數(shù)。
它指的是,需求是開發(fā)的起點(diǎn),先有需求再有功能分支(feature branch)或者補(bǔ)丁分支(hotfix branch)。完成開發(fā)后,該分支就合并到主分支,然后被刪除。
使用 PMU 的例子
例子 t1 和 t2 都較簡單。所謂魔高一尺,道才能高一丈。要想演示 perf 更加強(qiáng)大的能力,我也必須想出一個高明的影響性能的例子,我自己想不出,只好借助于他人。下面這個例子 t3 參考了文章“Branch and Loop Reorganization to Prevent Mispredicts”[6]
該例子考察程序?qū)Ρ简v處理器分支預(yù)測的利用率,如前所述,分支預(yù)測能夠顯著提高處理器的性能,而分支預(yù)測失敗則顯著降低處理器的性能。首先給出一個存在 BTB 失效的例子:
清單 3. 存在 BTB 失效的例子程序
//test.c #include #include void foo() { int i,j; for(i=0; i< 10; i++) j+=2; } int main(void) { int i; for(i = 0; i< 100000000; i++) foo(); return 0; }
用 gcc 編譯生成測試程序 t3:
gcc – o t3 – O0 test.c
用 perf stat 考察分支預(yù)測的使用情況:
[lm@ovispoly perf]$ ./perf stat ./t3 Performance counter stats for './t3': 6240.758394 task-clock-msecs # 0.995 CPUs 126 context-switches # 0.000 M/sec 12 CPU-migrations # 0.000 M/sec 80 page-faults # 0.000 M/sec 17683221 cycles # 2.834 M/sec (scaled from 99.78%) 10218147 instructions # 0.578 IPC (scaled from 99.83%) 2491317951 branches # 399.201 M/sec (scaled from 99.88%) 636140932 branch-misses # 25.534 % (scaled from 99.63%) 126383570 cache-references # 20.251 M/sec (scaled from 99.68%) 942937348 cache-misses # 151.093 M/sec (scaled from 99.58%) 6.271917679 seconds time elapsed
可以看到 branche-misses 的情況比較嚴(yán)重,25% 左右。我測試使用的機(jī)器的處理器為 Pentium4,其 BTB 的大小為 16。而 test.c 中的循環(huán)迭代為 20 次,BTB 溢出,所以處理器的分支預(yù)測將不準(zhǔn)確。
對于上面這句話我將簡要說明一下,但關(guān)于 BTB 的細(xì)節(jié),請閱讀參考文獻(xiàn) [6]。
for 循環(huán)編譯成為 IA 匯編后如下:
清單 4. 循環(huán)的匯編
// C code for ( i=0; i < 20; i++ ) { … } //Assembly code; mov esi, data mov ecx, 0 ForLoop: cmp ecx, 20 jge EndForLoop … add ecx, 1 jmp ForLoop EndForLoop:
可以看到,每次循環(huán)迭代中都有一個分支語句 jge,因此在運(yùn)行過程中將有 20 次分支判斷。每次分支判斷都將寫入 BTB,但 BTB 是一個 ring buffer,16 個 slot 寫滿后便開始覆蓋。假如迭代次數(shù)正好為 16,或者小于 16,則完整的循環(huán)將全部寫入 BTB,比如循環(huán)迭代次數(shù)為 4 次,則 BTB 應(yīng)該如下圖所示:

這個 buffer 完全精確地描述了整個循環(huán)迭代的分支判定情況,因此下次運(yùn)行同一個循環(huán)時,處理器便可以做出完全正確的預(yù)測。但假如迭代次數(shù)為 20,則該 BTB 隨著時間推移而不能完全準(zhǔn)確地描述該循環(huán)的分支預(yù)測執(zhí)行情況,處理器將做出錯誤的判斷。
我們將測試程序進(jìn)行少許的修改,將迭代次數(shù)從 20 減少到 10,為了讓邏輯不變,j++ 變成了 j+=2;
清單 5. 沒有 BTB 失效的代碼
#include #include void foo() { int i,j; for(i=0; i< 10; i++) j+=2; } int main(void) { int i; for(i = 0; i< 100000000; i++) foo(); return 0; }
此時再次用 perf stat 采樣得到如下結(jié)果:
[lm@ovispoly perf]$ ./perf stat ./t3 Performance counter stats for './t3: 2784.004851 task-clock-msecs # 0.927 CPUs 90 context-switches # 0.000 M/sec 8 CPU-migrations # 0.000 M/sec 81 page-faults # 0.000 M/sec 33632545 cycles # 12.081 M/sec (scaled from 99.63%) 42996 instructions # 0.001 IPC (scaled from 99.71%) 1474321780 branches # 529.569 M/sec (scaled from 99.78%) 49733 branch-misses # 0.003 % (scaled from 99.35%) 7073107 cache-references # 2.541 M/sec (scaled from 99.42%) 47958540 cache-misses # 17.226 M/sec (scaled from 99.33%) 3.002673524 seconds time elapsed
Branch-misses 減少了。
本例只是為了演示 perf 對 PMU 的使用,本身并無意義,關(guān)于充分利用 processor 進(jìn)行調(diào)優(yōu)可以參考 Intel 公司出品的調(diào)優(yōu)手冊,其他的處理器可能有不同的方法,還希望讀者明鑒。
小結(jié)以上介紹的這些 perf 用法主要著眼點(diǎn)在于對于應(yīng)用程序的性能統(tǒng)計(jì)分析,本文的第二部分將繼續(xù)講述 perf 的一些特殊用法,并偏重于內(nèi)核本身的性能統(tǒng)計(jì)分析。
調(diào)優(yōu)是需要綜合知識的工作,要不斷地修煉自己。Perf 雖然是一把寶劍,但寶劍配英雄,只有武功高強(qiáng)的大俠才能隨心所欲地使用它。以我的功力,也只能道聽途說地講述一些關(guān)于寶刀的事情。但若本文能引起您對寶刀的興趣,那么也算是有一點(diǎn)兒作用了。
-
嵌入式
+關(guān)注
關(guān)注
5072文章
19026瀏覽量
303516 -
Linux
+關(guān)注
關(guān)注
87文章
11232瀏覽量
208950
原文標(biāo)題:運(yùn)維必殺技Perf -- Linux下的系統(tǒng)性能調(diào)優(yōu)工具
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Linux內(nèi)核開發(fā)工具介紹
Linux內(nèi)核開發(fā)工具介紹
如何采用VC++ 6.0開發(fā)一款基于串口通訊的PROFIBUS性能分析診斷軟件?
Linux內(nèi)核源代碼
嵌入式LINUX內(nèi)核網(wǎng)絡(luò)棧(源代碼)

Linux內(nèi)核代碼感悟

你知道perf學(xué)習(xí)-linux自帶性能分析工具怎么用?
Linux 內(nèi)核維護(hù)者需要更好的協(xié)作工具來改變貢獻(xiàn)方式
關(guān)于Linux的內(nèi)核代碼風(fēng)格
Linux內(nèi)核代碼修改將為性能測試獲8450%提升
Linux 6.1發(fā)布,微軟貢獻(xiàn)Linux內(nèi)核代碼
Linux內(nèi)核代碼60%都是驅(qū)動?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論