") K-means算法原理理論+opencv實(shí)現(xiàn)
K-means算法原理理論+opencv實(shí)現(xiàn)
寫(xiě)在前面:之前想分類圖像的時(shí)候有看過(guò)k-means算法,當(dāng)時(shí)一知半解的去使用,不懂原理不懂使用規(guī)則。。。顯然最后失敗了,然后看了《機(jī)器學(xué)習(xí)》這本書(shū)對(duì)k-means算法有了理論的認(rèn)識(shí),現(xiàn)在通過(guò)賈志剛老師的視頻有了實(shí)際應(yīng)用的理解。
k-means算法原理
注:還是和之前一樣,核心都是別人的,我只是知識(shí)的搬運(yùn)工并且加上了自己的理解。弄完之后發(fā)現(xiàn)理論部分都是別人的~~沒(méi)辦法這算法太簡(jiǎn)單了。。。
k-means含義:無(wú)監(jiān)督的聚類算法。
無(wú)監(jiān)督:就是不需要人干預(yù),拿來(lái)一大批東西直接放進(jìn)算法就可以進(jìn)行分類。SVM和神經(jīng)網(wǎng)絡(luò)都是需要提前訓(xùn)練好然后再進(jìn)行分類這樣就是監(jiān)督學(xué)習(xí)。而k-means和K近鄰都是無(wú)監(jiān)督學(xué)習(xí)。
聚類:通過(guò)一個(gè)中心聚在一起的分類,比如給你一批數(shù)據(jù)讓你分成三類,那就是三個(gè)中心,那這三個(gè)中心代表的意思就是三個(gè)類。
k-means步驟:
從上圖中,我們可以看到,A,B,C,D,E是五個(gè)在圖中點(diǎn)。而灰色的點(diǎn)是我們的種子點(diǎn),也就是我們用來(lái)找點(diǎn)群的點(diǎn)。有兩個(gè)種子點(diǎn),所以K=2。
然后,K-Means的算法如下:
隨機(jī)在圖中取K(這里K=2)個(gè)種子點(diǎn)。
然后對(duì)圖中的所有點(diǎn)求到這K個(gè)種子點(diǎn)的距離,假如點(diǎn)Pi離種子點(diǎn)Si最近,那么Pi屬于Si點(diǎn)群。(上圖中,我們可以看到A,B屬于上面的種子點(diǎn),C,D,E屬于下面中部的種子點(diǎn))
接下來(lái),我們要移動(dòng)種子點(diǎn)到屬于他的“點(diǎn)群”的中心。(見(jiàn)圖上的第三步)
然后重復(fù)第2)和第3)步,直到,種子點(diǎn)沒(méi)有移動(dòng)(我們可以看到圖中的第四步上面的種子點(diǎn)聚合了A,B,C,下面的種子點(diǎn)聚合了D,E)。
這個(gè)算法很簡(jiǎn)單,但是有些細(xì)節(jié)我要提一下,求距離的公式我不說(shuō)了,大家有初中畢業(yè)水平的人都應(yīng)該知道怎么算的。我重點(diǎn)想說(shuō)一下“求點(diǎn)群中心的算法”。
求點(diǎn)群中心的算法
一般來(lái)說(shuō),求點(diǎn)群中心點(diǎn)的算法你可以很簡(jiǎn)的使用各個(gè)點(diǎn)的X/Y坐標(biāo)的平均值。不過(guò),我這里想告訴大家另三個(gè)求中心點(diǎn)的的公式:
Minkowski Distance公式——λ可以隨意取值,可以是負(fù)數(shù),也可以是正數(shù),或是無(wú)窮大。
Euclidean Distance公式——也就是第一個(gè)公式λ=2的情況
CityBlock Distance公式——也就是第一個(gè)公式λ=1的情況
k-means的缺點(diǎn):
在 K-means 算法中 K 是事先給定的,這個(gè) K 值的選定是非常難以估計(jì)的。很多時(shí)候,事先并不知道給定的數(shù)據(jù)集應(yīng)該分成多少個(gè)類別才最合適。這也是 K-means 算法的一個(gè)不足。
在 K-means 算法中,首先需要根據(jù)初始聚類中心來(lái)確定一個(gè)初始劃分,然后對(duì)初始劃分進(jìn)行優(yōu)化。這個(gè)初始聚類中心的選擇對(duì)聚類結(jié)果有較大的影響,一旦初始值選擇的不好,可能無(wú)法得到有效的聚類結(jié)果,這也成為 K-means算法的一個(gè)主要問(wèn)題。
從 K-means 算法框架可以看出,該算法需要不斷地進(jìn)行樣本分類調(diào)整,不斷地計(jì)算調(diào)整后的新的聚類中心,因此當(dāng)數(shù)據(jù)量非常大時(shí),算法的時(shí)間開(kāi)銷是非常大的。
opencv+K-means
沒(méi)什么好寫(xiě)的,因?yàn)檫@個(gè)k-means比較簡(jiǎn)單,主要說(shuō)的就是函數(shù)參數(shù)的應(yīng)用而已:
voidRNG::fill(InputOutputArraymat, intdistType, InputArraya, InputArrayb, boolsaturateRange=false)
這個(gè)函數(shù)是對(duì)矩陣mat填充隨機(jī)數(shù),隨機(jī)數(shù)的產(chǎn)生方式有參數(shù)2來(lái)決定,如果為參數(shù)2的類型為RNG::UNIFORM,則表示產(chǎn)生均一分布的隨機(jī)數(shù),如果為RNG::NORMAL則表示產(chǎn)生高斯分布的隨機(jī)數(shù)。對(duì)應(yīng)的參數(shù)3和參數(shù)4為上面兩種隨機(jī)數(shù)產(chǎn)生模型的參數(shù)。比如說(shuō)如果隨機(jī)數(shù)產(chǎn)生模型為均勻分布,則參數(shù)a表示均勻分布的下限,參數(shù)b表示上限。如果隨機(jī)數(shù)產(chǎn)生模型為高斯模型,則參數(shù)a表示均值,參數(shù)b表示方程。參數(shù)5只有當(dāng)隨機(jī)數(shù)產(chǎn)生方式為均勻分布時(shí)才有效,表示的是是否產(chǎn)生的數(shù)據(jù)要布滿整個(gè)范圍(沒(méi)用過(guò),所以也沒(méi)仔細(xì)去研究)。另外,需要注意的是用來(lái)保存隨機(jī)數(shù)的矩陣mat可以是多維的,也可以是多通道的,目前最多只能支持4個(gè)通道。
voidrandShuffle(InputOutputArraydst, doubleiterFactor=1.,RNG*rng=0)
該函數(shù)表示隨機(jī)打亂1D數(shù)組dst里面的數(shù)據(jù),隨機(jī)打亂的方式由隨機(jī)數(shù)發(fā)生器rng決定。iterFactor為隨機(jī)打亂數(shù)據(jù)對(duì)數(shù)的因子,總共打亂的數(shù)據(jù)對(duì)數(shù)為:dst.rows*dst.cols*iterFactor,因此如果為0,表示沒(méi)有打亂數(shù)據(jù)。
Class TermCriteria
類TermCriteria 一般表示迭代終止的條件,如果為CV_TERMCRIT_ITER,則用最大迭代次數(shù)作為終止條件,如果為CV_TERMCRIT_EPS則用精度作為迭代條件,如果為CV_TERMCRIT_ITER+CV_TERMCRIT_EPS則用最大迭代次數(shù)或者精度作為迭代條件,看哪個(gè)條件先滿足。
doublekmeans(InputArraydata, intK, InputOutputArraybestLabels, TermCriteriacriteria, intattempts, intflags, OutputArraycenters=noArray())
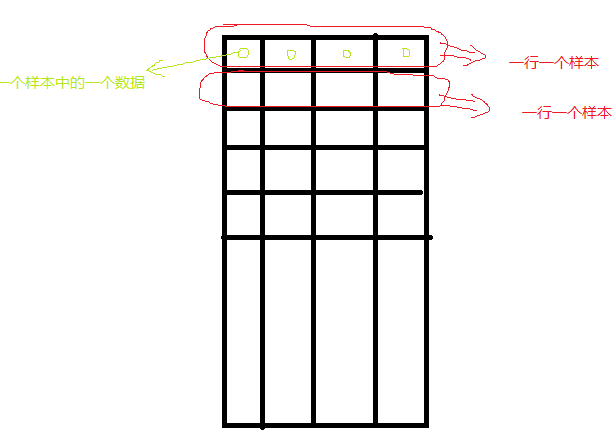
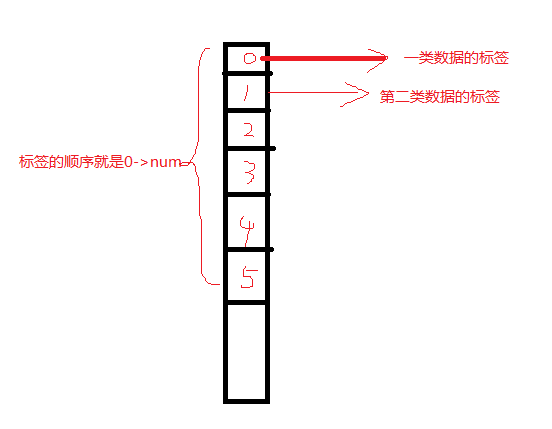
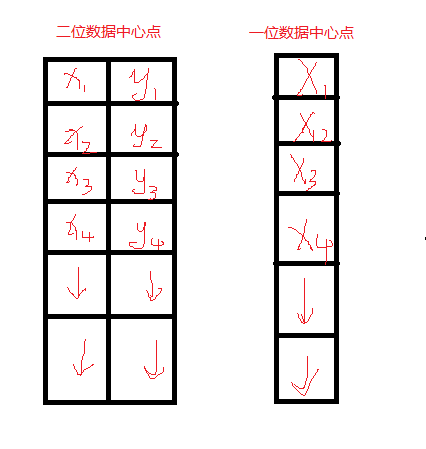
該函數(shù)為kmeans聚類算法實(shí)現(xiàn)函數(shù)。參數(shù)data表示需要被聚類的原始數(shù)據(jù)集合,一行表示一個(gè)數(shù)據(jù)樣本,每一個(gè)樣本的每一列都是一個(gè)屬性;參數(shù)k表示需要被聚類的個(gè)數(shù);參數(shù)bestLabels表示每一個(gè)樣本的類的標(biāo)簽,是一個(gè)整數(shù),從0開(kāi)始的索引整數(shù);參數(shù)criteria表示的是算法迭代終止條件;參數(shù)attempts表示運(yùn)行kmeans的次數(shù),取結(jié)果最好的那次聚類為最終的聚類,要配合下一個(gè)參數(shù)flages來(lái)使用;參數(shù)flags表示的是聚類初始化的條件。其取值有3種情況,如果為KMEANS_RANDOM_CENTERS,則表示為隨機(jī)選取初始化中心點(diǎn),如果為KMEANS_PP_CENTERS則表示使用某一種算法來(lái)確定初始聚類的點(diǎn);如果為KMEANS_USE_INITIAL_LABELS,則表示使用用戶自定義的初始點(diǎn),但是如果此時(shí)的attempts大于1,則后面的聚類初始點(diǎn)依舊使用隨機(jī)的方式;參數(shù)centers表示的是聚類后的中心點(diǎn)存放矩陣。該函數(shù)返回的是聚類結(jié)果的緊湊性,其計(jì)算公式為:
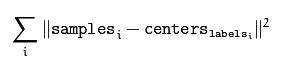
注意點(diǎn)一:
這是說(shuō)個(gè)我自己不理解的地方:fill(InputOutputArraymat, intdistType, InputArraya, InputArrayb, boolsaturateRange=false)
這里的InputArraya, InputArrayb------>>>分別用了Scalar(center.x, center.y, 0, 0), Scalar(img.cols*0.05, img.rows*0.05, 0, 0)去替換
去查了一下手冊(cè):InputArray這個(gè)接口類可以是Mat、Mat_
特意定義了一個(gè):InputArray test = Scalar(1,1);這個(gè)又是可以的,定義Mat不行,Vector也不行,這個(gè)真的不知道什么原因,有時(shí)間得去看源碼a,b的使用。
//----下面的定義都是錯(cuò)誤的,運(yùn)行的結(jié)果都不對(duì),原因暫時(shí)不知道
Mat a = (Mat_
Mat b = (Mat_
InputArray a1 = Scalar(center.x, center.y);
InputArray b1 = Scalar(img.cols*0.05, img.rows*0.05);
Mat a2 = a1.getMat();
Mat b2 = b1.getMat();
Mat c(1, 2, CV_8UC1);
c = Scalar(center.x, center.y);
Mat c1(1, 2, CV_8UC1);
c1 = Scalar(img.cols*0.05, img.rows*0.05);
rng.fill(pointChunk, RNG::NORMAL, a, b, 0);
注意點(diǎn)二:
kmeans()函數(shù)的輸入只接受data0.dims <= 2 && type == CV_32F && K > 0 ,
第一個(gè)dims一般都不會(huì)越界(三維不行)
第二個(gè)參數(shù)CV_32F == float,千萬(wàn)別帶入CV_8U == uchar
第三個(gè)參數(shù)不用說(shuō)了,設(shè)置的種類肯定是大于0的
注意點(diǎn)三:
opencv里面k-means函數(shù)的樣本數(shù)據(jù)、標(biāo)簽、中心點(diǎn)的存儲(chǔ):
#include
#include
using namespace cv;
using namespace std;
int main(int argc, char** argv) {
Mat img(500, 500, CV_8UC3);
RNG rng(12345);
const int Max_nCluster = 5;
Scalar colorTab[] = {
Scalar(0, 0, 255),
Scalar(0, 255, 0),
Scalar(255, 0, 0),
Scalar(0, 255, 255),
Scalar(255, 0, 255)
};
//InputArray a = Scalar(1,1);
int numCluster = rng.uniform(2, Max_nCluster + 1);//隨機(jī)類數(shù)
int sampleCount = rng.uniform(5, 1000);//樣本點(diǎn)數(shù)量
Mat matPoints(sampleCount, 1, CV_32FC2);//樣本點(diǎn)矩陣:sampleCount X 2
Mat labels;
Mat centers;
// 生成隨機(jī)數(shù)
for (int k = 0; k < numCluster; k++) {
Point center;//隨機(jī)產(chǎn)生中心點(diǎn)
center.x = rng.uniform(0, img.cols);
center.y = rng.uniform(0, img.rows);
Mat pointChunk = matPoints.rowRange( k*sampleCount / numCluster,
(k + 1)*sampleCount / numCluster);
//-----這句話的意思我不明白作用是什么,沒(méi)意義啊!
/*Mat pointChunk = matPoints.rowRange(k*sampleCount / numCluster,
k == numCluster - 1 ? sampleCount : (k + 1)*sampleCount / numCluster);*/
//-----符合高斯分布的隨機(jī)高斯
rng.fill(pointChunk, RNG::NORMAL, Scalar(center.x, center.y, 0, 0), Scalar(img.cols*0.05, img.rows*0.05, 0, 0));
}
randShuffle(matPoints, 1, &rng);//打亂高斯生成的數(shù)據(jù)點(diǎn)順序
// 使用KMeans
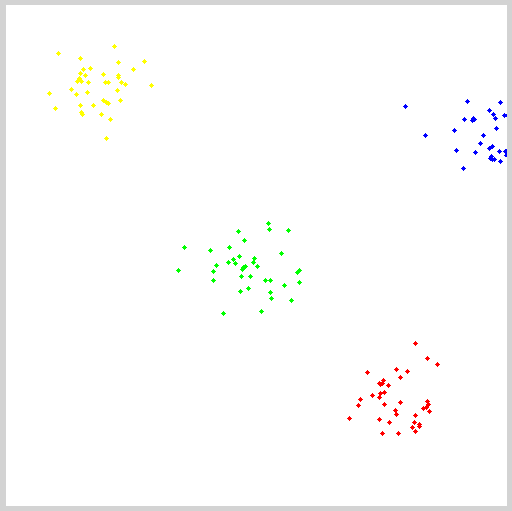
kmeans(matPoints, numCluster, labels, TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 0.1), 3, KMEANS_PP_CENTERS, centers);
// 用不同顏色顯示分類
img = Scalar::all(255);
for (int i = 0; i < sampleCount; i++) {
int index = labels.at
Point p = matPoints.at
circle(img, p, 2, colorTab[index], -1, 8);
}
// 每個(gè)聚類的中心來(lái)繪制圓
for (int i = 0; i < centers.rows; i++) {
int x = centers.at
int y = centers.at
printf("c.x= %d, c.y=%d", x, y);
circle(img, Point(x, y), 40, colorTab[i], 1, LINE_AA);
}
imshow("KMeans-Data-Demo", img);
waitKey(0);
return 0;
}

分類代碼:
#include
#include
using namespace cv;
using namespace std;
RNG rng(12345);
const int Max_nCluster = 5;
int main(int argc, char** argv) {
//Mat img(500, 500, CV_8UC3);
Mat inputImage = imread("1.jpg");
assert(!inputImage.data);
Scalar colorTab[] = {
Scalar(0, 0, 255),
Scalar(0, 255, 0),
Scalar(255, 0, 0),
Scalar(0, 255, 255),
Scalar(255, 0, 255)
};
Mat matData = Mat::zeros(Size(inputImage.channels(), inputImage.rows*inputImage.cols), CV_32FC1);
int ncluster = 5; //rng.uniform(2, Max_nCluster + 1);//聚類數(shù)量
Mat label;//聚類標(biāo)簽
Mat centers(ncluster, 1, matData.type());
for (size_t i = 0; i < inputImage.rows; i++)//把圖像存儲(chǔ)到樣本容器
{
uchar* ptr = inputImage.ptr
for (size_t j = 0; j < inputImage.cols; j++)
{
matData.at
matData.at
matData.at
}
}
Mat result = Mat::zeros(inputImage.size(), inputImage.type());
TermCriteria criteria = TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 20, 0.1);
kmeans(matData, ncluster, label, criteria, 3, KMEANS_PP_CENTERS, centers);
for (size_t i = 0; i < inputImage.rows; i++)
{
for (size_t j = 0; j < inputImage.cols; j ++)
{
int index = label.at
result.at
result.at
result.at
}
}
imshow("12", result);
waitKey(0);
return 0;
}
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8377瀏覽量
132407 -
K-means
+關(guān)注
關(guān)注
0文章
28瀏覽量
11286
原文標(biāo)題:K-means算法(理論+opencv實(shí)現(xiàn))
文章出處:【微信號(hào):AI_shequ,微信公眾號(hào):人工智能愛(ài)好者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于距離的聚類算法K-means的設(shè)計(jì)實(shí)現(xiàn)
改進(jìn)的k-means聚類算法在供電企業(yè)CRM中的應(yīng)用
Web文檔聚類中k-means算法的改進(jìn)
K-means+聚類算法研究綜述

基于密度的K-means算法在聚類數(shù)目中應(yīng)用
K-Means算法改進(jìn)及優(yōu)化
基于布谷鳥(niǎo)搜索的K-means聚類算法
k-means算法原理解析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論