") 怎樣優(yōu)化CatBoost參數
怎樣優(yōu)化CatBoost參數
CatBoost是由Yandex發(fā)布的梯度提升庫。在Yandex提供的基準測試中,CatBoost的表現超過了XGBoost和LightGBM。許多Kaggle競賽的優(yōu)勝者使用了XGBoost,因此CatBoost很值得考察一下。
快速示例
通過如下命令安裝CatBoost
pip install catboost
在Windows 10/python 3.5上,一切工作良好。CatBoost的接口基本上和大部分sklearn分類器差不多,所以,如果你用過sklearn,那你使用CatBoost不會遇到什么麻煩。CatBoost可以處理缺失的特征以及類別特征,你只需告知分類器哪些維度是類別維度。
讓我們在UCI Repository Adult Dataset上做個快速的試驗。這一數據集包含約32000個訓練樣本,16000個測試樣本。其中有14個特征,包括類別和連續(xù)值,其中一些特征缺失。我們將使用pandas解析csv文件:
import pandas
import numpy as np
import catboost as cb
# 從csv文件讀取訓練數據和測試數據
colnames = ['age','wc','fnlwgt','ed','ednum','ms','occ','rel','race','sex','cgain','closs','hpw','nc','label']
train_set = pandas.read_csv("adult.data.txt",header=None,names=colnames,na_values='?')
test_set = pandas.read_csv("adult.test.txt",header=None,names=colnames,na_values='?',skiprows=[0])
# 轉換類別欄為整數
category_cols = ['wc','ed','ms','occ','rel','race','sex','nc','label']
for header in category_cols:
train_set[header] = train_set[header].astype('category').cat.codes
test_set[header] = test_set[header].astype('category').cat.codes
# 將標簽從數據集中分離
train_label = train_set['label']
train_set = train_set.drop('label', axis=1) # 移除標簽
test_label = test_set['label']
test_set = test_set.drop('label', axis=1) # 移除標簽
# 訓練默認分類器
clf = cb.CatBoostClassifier()
cat_dims = [train_set.columns.get_loc(i) for i in category_cols[:-1]]
clf.fit(train_set, np.ravel(train_label), cat_features=cat_dims)
res = clf.predict(test_set)
print('error:',1-np.mean(res==np.ravel(test_label)))
使用如下命令運行這一試驗:
python cb_adult.py
20次運行的平均錯誤率是12.91%. 這比數據集列出的所有樣本分類結果都要好(列出的最好結果是樸素貝葉斯的14%錯誤率)。考慮到我們還沒有進行任何優(yōu)化,這個結果可不賴。
數據集中的類別特征都以字符串的形式表示。我們需要將其轉換為整數,以便CatBoost使用。使用pandas,這很容易辦到。CatBoost看起來不能夠處理類別欄中的缺失特征,我們通過pandas修正了這一點,直接將missing作為一個類別。CatBoost可以很好地處理連續(xù)值類型的缺失特征。
梯度提升介紹
CatBoost是一個梯度提升庫,我將在本節(jié)中簡要地描述梯度提升是如何工作的。
“梯度提升”源于“提升”,或者說,通過組合弱模型以構建強模型,從而提升弱模型的表現。梯度提升是提升的一個擴展,其中疊加生成弱模型的過程規(guī)劃為基于一個目標函數的梯度下降算法。梯度提升屬于監(jiān)督學習方法,這意味著它接受一個帶標簽的訓練實例集合作為輸入,構建一個模型,該模型基于給定的特征,嘗試正確預測新的未見樣本的標簽。
梯度提升可以使用許多不同種類的模型,但在實踐中幾乎總是使用決策樹。開始訓練時,構建單棵決策樹預測標簽。這第一棵決策樹將預測一些實例,但在另一些實例上會失敗。從真實標簽(yi)減去預測標簽(?i),將顯示預測是低估還是高估,這稱為殘差(ri)。
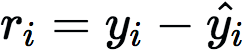
為了提升這一模型,我們可以構建另一棵決策樹,不過這回將預測殘差而不是原始標簽。這可以認為是構建另一個模型以糾正現有模型的錯誤。添加新樹至模型后,做出新預測,接著再次計算殘差。為了使用多棵樹做出預測,直接讓給定實例通過每棵樹,并累加每棵樹的預測。通過構建估計殘差的預測器,我們實際上最小化了真實標簽和預測標簽的方差的梯度:
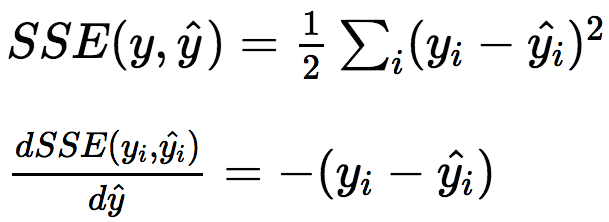
如果我們不想使用方差,我們可以使用交叉熵之類的其他可微函數,接著預測相應的殘差。以上覆蓋了梯度提升的基礎,但還有一些額外的術語,例如,正則化。你可以看下XGBoost是如何進行正則化的。
分類調優(yōu)參數
上一節(jié)概覽了梯度提升如何工作的基礎,本節(jié)中我將介紹CatBoost提供的一些調整預測的把手。你可以在文檔中找到更多參數,但如果關注的是模型表現的話,并不需要調整更多參數。
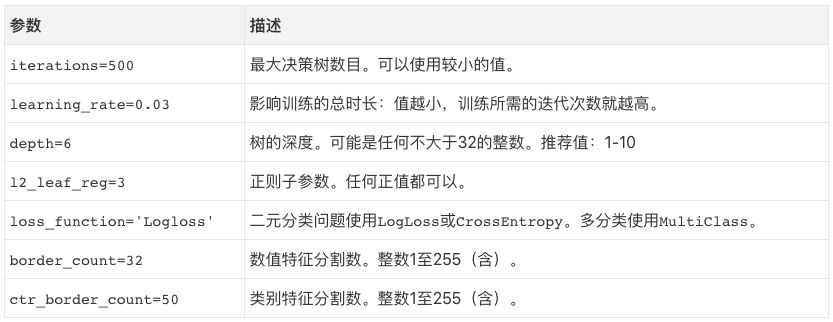
還有一些隱秘的選項,但使用以上這些參數效果已經很好了。
參數搜索
這一步驟通常叫做網格搜索,基本上就是尋找能取得最高分數的參數值。需要牢記的是我們不能用測試集來調優(yōu)參數,否則我們會過擬合測試集。我們需要在訓練集上做交叉驗證(或者使用獨立的驗證集),直到最后的精確度計算階段才能碰測試集。
這里我們不會做全網格搜索,因為所有參數組合的可能性實在太多了。我們將一小組參數一小組參數地做網格搜索,也就是局部搜索。
我們從默認的參數設定開始,因為它們已經相當不錯了。首先我們獨立優(yōu)化ctr_border_count、border_count、l2_leaf_reg。我們將記住最佳的設定,然后我們將同時對iterations和learning_rate進行網格搜索,因為兩者是緊密耦合的。最后,我們將查找最佳depth。因為我們并沒有進行全網格搜索,我們可能不會得到最優(yōu)設定,不過我們應該能得到相當接近最優(yōu)設定的結果。
我編寫了進行網格搜索的代碼。開頭部分基本和“快速示例”中的代碼一樣,讀取數據集,轉換類別特征為整數,并提取標簽。
import pandas
import numpy as np
import catboost as cb
from sklearn.model_selection importKFold
from paramsearch import paramsearch
from itertools import product,chain
# 從csv文件讀取訓練數據和測試數據
colnames = ['age','wc','fnlwgt','ed','ednum','ms','occ','rel','race','sex','cgain','closs','hpw','nc','label']
train_set = pandas.read_csv("adult.data.txt",header=None,names=colnames,na_values='?')
test_set = pandas.read_csv("adult.test.txt",header=None,names=colnames,na_values='?',skiprows=[0])
# 轉換類別欄為整數
category_cols = ['wc','ed','ms','occ','rel','race','sex','nc','label']
cat_dims = [train_set.columns.get_loc(i) for i in category_cols[:-1]]
for header in category_cols:
train_set[header] = train_set[header].astype('category').cat.codes
test_set[header] = test_set[header].astype('category').cat.codes
# 將標簽從數據集中分離
train_label = train_set['label']
train_set = train_set.drop('label', axis=1)
test_label = test_set['label']
test_set = test_set.drop('label', axis=1)
然后是具體的參數搜索部分。我們首先指定將要進行網格搜索的參數,以及我們想要搜索的值。
params = {'depth':[3,1,2,6,4,5,7,8,9,10],
'iterations':[250,100,500,1000],
'learning_rate':[0.03,0.001,0.01,0.1,0.2,0.3],
'l2_leaf_reg':[3,1,5,10,100],
'border_count':[32,5,10,20,50,100,200],
'ctr_border_count':[50,5,10,20,100,200],
'thread_count':4}
然后我們定義進行交叉驗證的函數——這一函數接受指定參數的集合,在訓練數據集上進行n折驗證,并返回每折的平均精確度。
# 這一函數基于catboostclassifier進行3折交叉驗證
def crossvaltest(params,train_set,train_label,cat_dims,n_splits=3):
kf = KFold(n_splits=n_splits,shuffle=True)
res = []
for train_index, test_index in kf.split(train_set):
train = train_set.iloc[train_index,:]
test = train_set.iloc[test_index,:]
labels = train_label.ix[train_index]
test_labels = train_label.ix[test_index]
clf = cb.CatBoostClassifier(**params)
clf.fit(train, np.ravel(labels), cat_features=cat_dims)
res.append(np.mean(clf.predict(test)==np.ravel(test_labels)))
return np.mean(res)
下面是實際調用網格搜索函數的代碼。我們使用itertools中的chain將多個迭代器組合為一個。我們首先搜索border_count,其他參數都保持默認值。接著我們使用之前找到的最佳參數搜索ctr_border_count。然后我們同時對iterations和learning_rate進行網格搜索(測試兩者的所有可能組合)。在此之后我們找到最佳深度。一旦我們測試了所有組合后,我們直接使用最佳參數調用catBoostClassifier。
# 這一函數在一些參數上進行網格搜索
def catboost_param_tune(params,train_set,train_label,cat_dims=None,n_splits=3):
ps = paramsearch(params)
# 單獨搜索'border_count'、'l2_leaf_reg'等參數,
# 但同時搜索'iterations'和'learning_rate'
for prms in chain(ps.grid_search(['border_count']),
ps.grid_search(['ctr_border_count']),
ps.grid_search(['l2_leaf_reg']),
ps.grid_search(['iterations','learning_rate']),
ps.grid_search(['depth'])):
res = crossvaltest(prms,train_set,train_label,cat_dims,n_splits)
# 保存交叉驗證結果,這樣以后的迭代可以復用最佳參數
ps.register_result(res,prms)
print(res,prms,s'best:',ps.bestscore(),ps.bestparam())
return ps.bestparam()
bestparams = catboost_param_tune(params,train_set,train_label,cat_dims)
現在我們使用找到的最佳參數調用CatBoost:
# 使用調優(yōu)的參數訓練分類器
clf = cb.CatBoostClassifier(**bestparams)
clf.fit(train_set, np.ravel(train_label), cat_features=cat_dims)
res = clf.predict(test_set)
print('error:',1-np.mean(res==np.ravel(test_label)))
調優(yōu)參數后我們得到的最終分數實際上和調優(yōu)之前一樣!看起來我做的調優(yōu)沒能超越默認值。這體現了CatBoost分類器的質量,默認值是精心挑選的(至少就這一問題而言)。增加交叉驗證的n_splits,通過多次運行分類器減少得到的噪聲可能會有幫助,不過這樣的話網格搜索的耗時會更長。如果你想要測試更多參數或不同的組合,那么上面的代碼很容易修改。
預防過擬合
CatBoost提供了預防過擬合的良好設施。如果你把iterations設得很高,分類器會使用許多樹創(chuàng)建最終的分類器,會有過擬合的風險。如果初始化的時候設置了use_best_model=True和eval_metric='Accuracy',接著設置eval_set(驗證集),那么CatBoost不會使用所有迭代,它將返回在驗證集上達到最佳精確度的迭代。這和神經網絡的及早停止(early stopping)很像。如果你碰到過擬合問題,試一下這個會是個好主意。不過我沒能在這一數據集上看到任何改善,大概是因為有這么多訓練數據點,很難過擬合。
CatBoost集成
集成指組合某種基礎分類器的多個實例(或不同類型的分類器)為一個分類器。在CatBoost中,這意味著多次運行CatBoostClassify(比如10次),然后選擇10個分類器中最常見的預測作為最終分類標簽。一般而言,組成集成的每個分類器需要有一些差異——每個分類器犯的錯不相關時我們能得到最好的結果,也就是說,分類器盡可能地不一樣。
使用不同參數的CatBoost能給我們帶來一些多樣性。在網格搜索過程中,我們保存了我們測試的所有參數,以及相應的分數,這意味著,得到最佳的10個參數組合是一件輕而易舉的事情。一旦我們具備了10個最佳參數組合,我們直接構建分類器集成,并選取結果的眾數作為結果。對這一具體問題而言,我發(fā)現組合10個糟糕的參數設定,能夠改善原本糟糕的結果,但集成看起來在調優(yōu)過的設定上起不了多少作用。不過,由于大多數kaggle競賽的冠軍使用集成,一般而言,使用集成明顯會有好處。
-
參數
+關注
關注
11文章
1791瀏覽量
32111 -
分類器
+關注
關注
0文章
152瀏覽量
13175
原文標題:使用網格搜索優(yōu)化CatBoost參數
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
PGA309溫漂是否可以通過設置參數軟件方式優(yōu)化,如何優(yōu)化?
WCDMA網絡無線參數優(yōu)化資料
FOA優(yōu)化算法整定PID控制器參數
電流環(huán)控制器的優(yōu)化過程是怎樣的
蟻群算法參數優(yōu)化
GSM系統(tǒng)—網絡維護優(yōu)化參數的提取
電控噴油器關鍵參數優(yōu)化






 工商網監(jiān)
工商網監(jiān)
評論