 文本數據預處理的方法
文本數據預處理的方法
文本數據分析(一):基本框架
在文本數據分析基本框架中,我們涉及到了六個步驟:
數據收集
數據預處理
數據挖掘和可視化
模型構建
模型評估
雖然框架需要迭代,但是我們先將其看作是一個線性的過程:
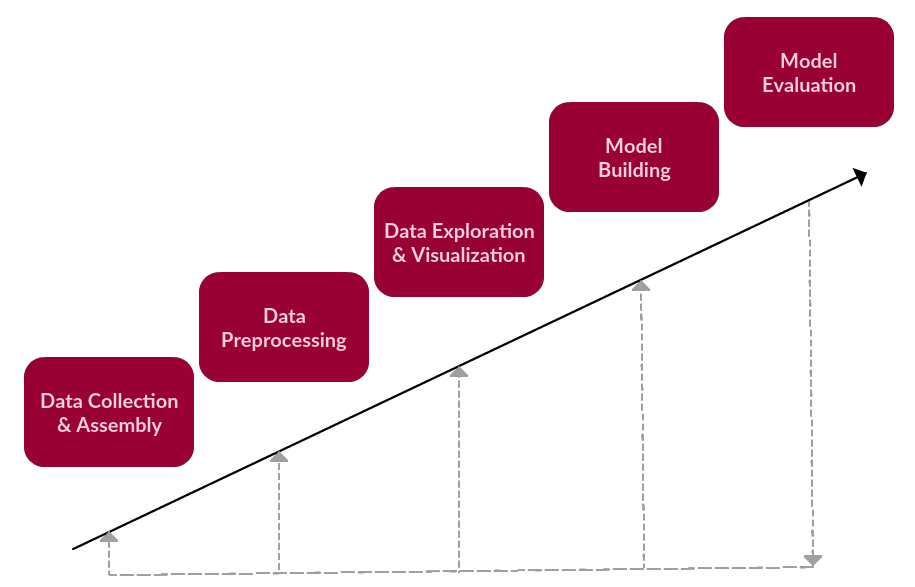
修正過的文本數據處理框架(依然很簡單……)
很顯然,文本數據預處理位于框架的第二步,這一步所包含的詳細步驟有以下兩個:
在原始文本語料上進行預處理,為文本挖掘或NLP任務做準備
數據預處理分為好幾步,其中有些步驟可能適用于給定的任務,也可能不適用。但通常都是標記化、歸一化和替代的其中一種(tokenization, normalization, substitution)。
通常,我們會選取一段預先準備好的文本,對其進行基本的分析和變換,遺留下更有用的文本數據,方便之后更深入、更有意義的分析任務。接下來將是文本挖掘或自然語言處理工作的核心工作。
所以再次重復以便,文本預處理的三個主要組成部分:
標記化(tokenization)
歸一化(normalization)
替換(substitution)
在下面介紹預處理方法的過程中,我們需要時刻牢記這三個概念。
文本預處理框架
接下來,我們將介紹這個框架的概念,而不涉及工具。在下一篇文章中我們會降到這些步驟的安裝過程,看看它們是如何在Python中實現的。
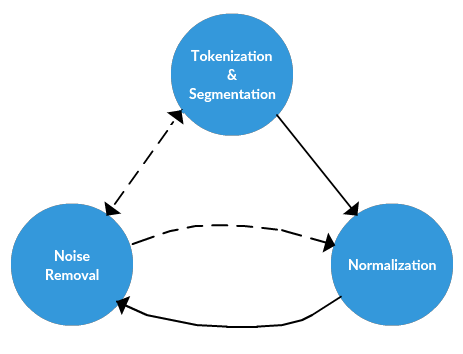
文本數據預處理框架
1.標記化(Tokenization)
標記化是將文本中的長字符串分割成小的片段或者tokens的過程。大段文字可以被分割成句子,句子又可以被分割成單詞等等。只有經過了tokenization,才能對文本進行進一步的處理。Tokenization同樣被稱作文本分割或者詞法分析。有時,分割(segmentation)用來表示大段文字編程小片段的過程(例如段落或句子)。而tokenization指的是將文本變為只用單詞表示的過程。
這一過程聽起來很直接,但事實并非如此。在較大的文本中如何識別句子?你的第一反應一定是“用標點符號”。
的確,下面的句子用傳統的分割方法很容易理解:
The quick brown fox jumps over the lazy dog.
但是下面這句呢:
Dr. Ford did not ask Col. Mustard the name of Mr. Smith’s dog.
還有這個:
“What is all the fuss about?” Asked Mr. Peters.
上面的都只是簡單的句子,那么單詞又怎樣呢?
This full-time student isn’t living in on-campus housing, and she’s not wanting to visit Hawai’i.
我們應該意識到,許多策略不只是針對句子分割,而是針對分割的邊界確定之后應該做什么。例如,我們可能會采用一種分割策略,它能夠(正確地)將單詞“she’s”的tokens之間特定邊界標識識別為撇號(單獨用空格標記的策略不足以識別這一點)。但是我們可以從多種策略中選擇,例如是將標點符號保留在單詞的某一部分中或是一同舍棄。其中一種方法似乎是正確的,并且似乎不會構成實際的問題。但是仔細想想,在英語中我們還需要考慮其他特殊情況。
即,當我們將文本分割成句子時,是否應該保留句末分隔符?我們是否在意句子在哪里結束?
2.歸一化(Normalization)
再進一步處理之前,文本需要進行歸一化。歸一化指的是一系列相關的任務,能夠將所有文本放在同一水平區域上:將所有文本轉化成同樣的實例,刪除標點,將數字轉換成相應的文字等等。對文本進行歸一化可以執行多種任務,但是對于我們的框架,歸一化有3個特殊的步驟:
詞干提取(stemming)
詞形還原(lemmatizatiion)
其他
詞干提取
詞干提取是刪除詞綴的過程(包括前綴、后綴、中綴、環綴),從而得到單詞的詞干。
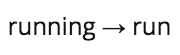
詞形還原
詞形還原與詞干提取相關,不同的是,詞形還原能夠捕捉基于詞根的規范單詞形式。
例如,對“better”一詞進行詞干提取,可能無法生成另一個詞根的詞。然而對其進行詞形還原,就得到:
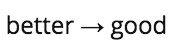
其他
詞形還原和詞干提取是文本預處理的主要部分,所以這兩項一定要認真對待。他們不是簡單地文本操作,而要依賴語法規則和對規則細致的理解。
然而,還有許多其他步驟可以幫助處理文本,讓它們變成平等的地位,其中有一些只是簡單地替換或刪除。其他重要的方法包括:
將所有字母變成小寫
刪除數字(或者將數字換成對應的文字)
刪除標點(者通常是tokenization的一部分,但是仍然需要在這一步做)
刪除空白格
刪除默認停止詞
停止詞是那些在對文本進一步與處理之前需要過濾掉的單詞,因為這些單詞并不影響整體意義。例如“the”、“and”、“a”這些詞。下面的例子就表明,即使刪除停止詞,句子的意思也很容易理解。

刪除特定的停止詞
刪除稀疏的特定詞語(盡管不是必須的)
在這里,我們應該清除文本預處理很大程度上依賴于預先建立的詞典、數據庫和規則。在我們下一篇用Python進行預處理的文章中,你會發現這些支持工具會非常有用。
3.噪聲清除
噪聲消除延續了框架的替代任務。雖然框架的前兩個主要步驟(標記化和歸一化)通常適用于幾乎任何的文本或項目,噪聲去除是預處理框架中一個更加具體的部分。
再次記住,我們的處理過程并不是線性的,其中的過程必須以特定的順序進行,視具體情況而定。因此,噪聲消除可以發生在上述步驟之前或之后,或者是某個時刻。
具體來說,假設我們從網上獲取了一個語料庫,并且以原始的web格式存儲,那么我們可以認為文本很大程度上可能有HTML或XML標簽。盡管這種對元數據的思考可以作為文本收集或組裝的過程中的一部分,但它取決于數據是如何獲取和收集的。在上一篇文章中,我簡單講述了如何從維基百科中獲取原始數據并搭建語料庫。由于我們控制了數據收集的過程,因此在這時處理噪聲也是可行的。
但情況并非總是如此。如果你正在使用的語料庫很嘈雜,你必須處理它。數據分析的效果80%都在于數據的準備。
好消息是,此時可以用到模式匹配:
刪除文件標題、頁腳
刪除HTML、XML等標記和元數據
從其他格式(如JSON)或數據庫中提取有價值的數據
如果你害怕正則表達式,這可能會成為文本預處理的一部分
噪聲消除和數據收集之間的界限很模糊,因此噪聲消除必須在其他步驟之前進行。例如,從JSON結構中獲取的文本顯然要在tokenization之前消除噪音。
-
數據收集
+關注
關注
0文章
72瀏覽量
11154 -
噪聲消除
+關注
關注
0文章
9瀏覽量
8102 -
python
+關注
關注
56文章
4782瀏覽量
84465
原文標題:文本數據分析(二):文本數據預處理的方法
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
labview樹形控件讀取子文本數據(child text)
從一個文本數據的文件夾中,怎樣實現數據的連續提取
C預處理與C語言基本數據類型
LabVIEW操作Excel報表時會丟失所有的非文本數據
文本數據分析:文本挖掘還是自然語言處理?
textCNN論文與原理——短文本分類
異構文本數據轉換過程中解析XML文本的方法對比






 工商網監
工商網監
評論