") 基于Numpy實現(xiàn)神經網絡:如何加入和調整dropout?
基于Numpy實現(xiàn)神經網絡:如何加入和調整dropout?
和DeepMind數(shù)據科學家、Udacity深度學習導師Andrew Trask一起,基于Numpy手寫神經網絡,更深刻地理解dropout這一概念。
總結:幾乎所有目前最先進的神經網絡都用到了dropout. 這篇教程介紹如何通過幾行Python代碼在神經網絡中加入Dropout. 讀完這篇教程之后,你將得到一個可以工作的dropout實現(xiàn),并且掌握在任何神經網絡中加入和調整dropout的技能。
如果你對我的文章感興趣,歡迎在推特上關注 @iamtrask,也歡迎給我反饋。
直接給我代碼
import numpy as np
X = np.array([ [0,0,1],[0,1,1],[1,0,1],[1,1,1] ])
y = np.array([[0,1,1,0]]).T
alpha,hidden_dim,dropout_percent,do_dropout = (0.5,4,0.2,True)
synapse_0 = 2*np.random.random((3,hidden_dim)) - 1
synapse_1 = 2*np.random.random((hidden_dim,1)) - 1
for j in xrange(60000):
layer_1 = (1/(1+np.exp(-(np.dot(X,synapse_0)))))
if(do_dropout):
layer_1 *= np.random.binomial([np.ones((len(X),hidden_dim))],1-dropout_percent)[0] * (1.0/(1-dropout_percent))
layer_2 = 1/(1+np.exp(-(np.dot(layer_1,synapse_1))))
layer_2_delta = (layer_2 - y)*(layer_2*(1-layer_2))
layer_1_delta = layer_2_delta.dot(synapse_1.T) * (layer_1 * (1-layer_1))
synapse_1 -= (alpha * layer_1.T.dot(layer_2_delta))
synapse_0 -= (alpha * X.T.dot(layer_1_delta))
一、什么是dropout?
如同前一篇文章提到的,神經網絡是一個美化的搜索問題。神經網絡中的每一個節(jié)點搜索輸入數(shù)據和正確的輸出數(shù)據之間的相關性。
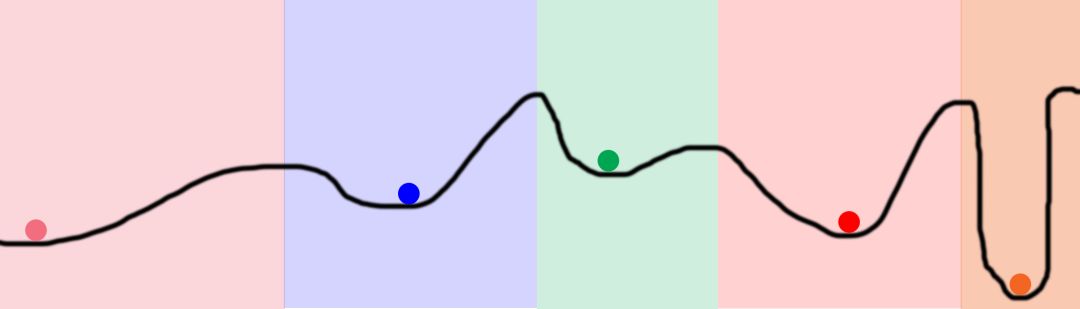
考慮前一篇中的圖片。曲線表示網絡對應每個具體權重產生的誤差。曲線的低點(讀作:低誤差)標志著權重“找到”輸入和輸出之間的關系。圖中的球標志著不同的權重。它們都試圖找到低點。
考慮顏色。球的初始位置是隨機生成的(就像神經網絡的權重)。如果兩個球隨機開始于同一顏色區(qū)域,那么它們將收斂于同一點。這里存在冗余!浪費算力和內存!這正是神經網絡中發(fā)生的事。
為何dropout:dropout有助于防止權重收斂于同一位置。它通過在前向傳播階段隨機關閉節(jié)點做到這一點。接著在反向傳播時激活所有節(jié)點。讓我們仔細看看。
二、如何加入和調整dropout?
為了在網絡層上執(zhí)行dropout,我們在前向傳播階段隨機設置層的值為0——見第10行。
第9行:參數(shù)化是否使用dropout. 我們只打算在訓練階段使用dropout. 不要在運行時使用dropout,也不要在測試數(shù)據集上使用dropout. 此外,這一行也意味著我們需要增大前向傳播的值。這與關閉的值的數(shù)目成正比。一個簡單的直覺是,如果你關閉一半的隱藏層,那么你需要加倍前向傳播的值,以正確補償輸出。感謝@karpathy指出這一點。
調整的最佳實踐
第4行:參數(shù)化dropout百分比。這影響關閉任何一個節(jié)點的概率。對隱藏層而言,較好的初始值設定是50%. 如果將dropout應用于輸入層,最好不要超過25%.
Hinton主張在調整dropout的同時調整隱藏層的大小。首先關閉dropout,增加隱藏層尺寸,直到你完美地擬合了你的數(shù)據。接著,使用相同的隱藏層尺寸,開啟dropout進行訓練。這應該是一個近乎最優(yōu)的配置。一旦結束訓練,關閉dropout。萬歲!你有了一個可以工作的神經網絡!
-
神經網絡
+關注
關注
42文章
4717瀏覽量
100009 -
深度學習
+關注
關注
73文章
5422瀏覽量
120593
原文標題:基于Numpy實現(xiàn)神經網絡:dropout
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
labview BP神經網絡的實現(xiàn)
【PYNQ-Z2試用體驗】神經網絡基礎知識
【案例分享】ART神經網絡與SOM神經網絡
人工神經網絡實現(xiàn)方法有哪些?
如何構建神經網絡?
matlab實現(xiàn)神經網絡 精選資料分享
基于BP神經網絡的PID控制
使用keras搭建神經網絡實現(xiàn)基于深度學習算法的股票價格預測
基于Numpy實現(xiàn)同態(tài)加密神經網絡
基于Numpy實現(xiàn)神經網絡:反向傳播

如何使用numpy搭建一個卷積神經網絡詳細方法和程序概述
如何使用Numpy搭建神經網絡





 工商網監(jiān)
工商網監(jiān)
評論