") 對(duì)抗樣本是如何在不同的媒介上發(fā)揮作用的,為什么保護(hù)系統(tǒng)很難對(duì)抗它們?
對(duì)抗樣本是如何在不同的媒介上發(fā)揮作用的,為什么保護(hù)系統(tǒng)很難對(duì)抗它們?
一般來(lái)說(shuō),對(duì)抗樣本(adversarial examples)是機(jī)器學(xué)習(xí)模型的輸入,攻擊者故意設(shè)計(jì)它們以引起模型出錯(cuò);它們就像是機(jī)器的視覺錯(cuò)覺。這篇文章中,將展示對(duì)抗樣本是如何在不同的媒介上發(fā)揮作用的,并將討論為什么保護(hù)系統(tǒng)很難對(duì)抗它們。
在OpenAI中,我們認(rèn)為對(duì)抗樣本是安全工作的一個(gè)很好的方面。因?yàn)樗鼈兇砹?a target="_blank">人工智能安全中的一個(gè)具體問題,而它們可以在短期內(nèi)得以解決。而且由于修復(fù)它們非常困難,需要進(jìn)行認(rèn)真的研究工作(盡管我們需要探索機(jī)器學(xué)習(xí)安全的許多方面,以實(shí)現(xiàn)我們構(gòu)建安全、廣泛分布的人工智能的目標(biāo))。
想要了解對(duì)抗樣本看起來(lái)是什么樣的,請(qǐng)參考《解釋和利用對(duì)抗樣本》(Explaining and Harnessing Adversarial Examples)中的闡釋:從一張熊貓的圖像開始,攻擊者添加一個(gè)小干擾,且該小干擾被計(jì)算出來(lái),使圖像被認(rèn)為是一個(gè)具有高置信度的長(zhǎng)臂猿。
覆蓋在典型圖像上的對(duì)抗輸入會(huì)導(dǎo)致分類器將熊貓誤歸類為長(zhǎng)臂猿
這種方法相當(dāng)具有魯棒性;最近的研究表明,對(duì)抗樣本可以在標(biāo)準(zhǔn)紙張上打印出來(lái),然后用標(biāo)準(zhǔn)智能手機(jī)拍攝,而且用的仍然是傻瓜系統(tǒng)。
對(duì)抗樣本可以在標(biāo)準(zhǔn)紙張上打印出來(lái)并用標(biāo)準(zhǔn)分辨率的智能手機(jī)拍照,并且在這種情況下仍然會(huì)導(dǎo)致分類器將“洗衣機(jī)”標(biāo)記為“安全”
對(duì)抗樣本是有潛在危險(xiǎn)性的。例如,攻擊者可以通過(guò)這種方法攻擊自動(dòng)駕駛汽車:使用貼紙或涂料創(chuàng)建一個(gè)對(duì)抗性的停車標(biāo)志,讓車輛將其解釋為“屈服”或其他標(biāo)志,就像《使用對(duì)抗樣本對(duì)深度學(xué)習(xí)系統(tǒng)進(jìn)行實(shí)用黑盒攻擊》(Practical Black-Box Attacks against Deep Learning Systems using Adversarial Examples)中所述的那樣。
加州大學(xué)伯克利分校、OpenAI和賓夕法尼亞州立大學(xué)的新研究《對(duì)神經(jīng)網(wǎng)絡(luò)策略的對(duì)抗性攻擊》(Adversarial Attacks on Neural Network Policies)以及內(nèi)華達(dá)大學(xué)雷諾分校的研究《深度強(qiáng)化學(xué)習(xí)對(duì)策略誘導(dǎo)攻擊的脆弱性》(Vulnerability of Deep Reinforcement Learning to Policy Induction Attacks)表明,強(qiáng)化學(xué)習(xí)智能體也可以被對(duì)抗樣本操縱。研究表明,諸如DQN、TRPO和A3C等這些廣泛使用的RL算法,很容易受到對(duì)抗輸入的影響。即使是在所存在的干擾微小到人類無(wú)法察覺,這些也會(huì)導(dǎo)致性能下降,使智能體在應(yīng)該將乒乓球拍向上移動(dòng)的時(shí)候?qū)⑺蛳乱苿?dòng)了,或者使其在Seaquest中發(fā)現(xiàn)對(duì)手的能力受到了干擾。
如果你想嘗試打破你自己的模型,你可以使用cleverhans,這是一個(gè)由Ian Goodfellow和Nicolas Papernot共同開發(fā)的開源庫(kù),用來(lái)測(cè)試你的AI對(duì)對(duì)抗樣本的漏洞。
對(duì)抗樣本讓我們?cè)谌斯ぶ悄馨踩矫嬗辛艘恍﹦?dòng)力
當(dāng)我們思考人工智能安全的研究時(shí),我們通常會(huì)想到這個(gè)領(lǐng)域中最困難的一些問題——我們?nèi)绾未_保那些比人類聰明得多的復(fù)雜的強(qiáng)化學(xué)習(xí)智能體能夠以它們的設(shè)計(jì)者所期望的方式行事?
對(duì)抗樣本告訴我們,對(duì)于監(jiān)督和強(qiáng)化學(xué)習(xí)而言,即使是簡(jiǎn)單的現(xiàn)代算法,也已經(jīng)可能以并非我們所想的令人驚訝的方式表現(xiàn)出來(lái)。
防御對(duì)抗樣本所做出過(guò)的嘗試
如權(quán)值衰減(weight decay)和dropout等這種使機(jī)器學(xué)習(xí)模型更具有魯棒性的傳統(tǒng)技術(shù),通常不能為對(duì)抗樣本提供實(shí)際的防御。到目前為止,只有兩種方法提供了重要的防御。
對(duì)抗性訓(xùn)練:這是一種暴力破解(brute force)的解決方案。其中,我們只是簡(jiǎn)單地生成很多對(duì)抗樣本,并明確訓(xùn)練模型不會(huì)被它們中的任何一個(gè)愚弄。對(duì)抗性訓(xùn)練的開源實(shí)現(xiàn)可以在cleverhans庫(kù)中找到,下面的教程對(duì)其用法在進(jìn)行了說(shuō)明。
防御性精煉:這是一種策略。我們訓(xùn)練模型來(lái)輸出不同類的概率,而不是將哪個(gè)類輸出的艱難決策。概率由早期的模型提供,該模型使用硬分類標(biāo)簽在相同的任務(wù)上進(jìn)行訓(xùn)練。這就創(chuàng)建了一個(gè)模型,其表面在攻擊者通常會(huì)試圖開拓的方向上是平滑的,從而使它們難以發(fā)現(xiàn)導(dǎo)致錯(cuò)誤分類的對(duì)抗輸入調(diào)整(精煉(Distillation)最初是在《神經(jīng)網(wǎng)絡(luò)中知識(shí)的精煉》(Distilling the Knowledge in a Neural Network)中作為模型壓縮的一種技術(shù)而被引入的,在這種技術(shù)中,一個(gè)小模型被訓(xùn)練以模仿一個(gè)大模型,以便節(jié)省計(jì)算量)。
然而,即使是這些專門的算法,也可能被擁有了更多計(jì)算火力的攻擊者輕易破解。
失敗的防御:“梯度掩碼”(gradient masking)
舉一個(gè)簡(jiǎn)單防御失敗的例子,讓我們考慮一下為什么一種叫做“梯度掩碼”的技術(shù)不起作用。
“梯度掩碼”是一個(gè)在《使用對(duì)抗樣本對(duì)深度學(xué)習(xí)系統(tǒng)進(jìn)行實(shí)用黑盒攻擊》(Practical Black-Box Attacks against Deep Learning Systems using Adversarial Examples)中所引入的術(shù)語(yǔ),用于描述一整套失敗的防御方法——它們?cè)噲D阻止攻擊者訪問一個(gè)有用的梯度。
大多數(shù)對(duì)抗樣本構(gòu)造技術(shù)使用模型的梯度來(lái)進(jìn)行攻擊。換句話說(shuō),它們看一張飛機(jī)的圖片,它們對(duì)圖片空間進(jìn)行測(cè)試,以發(fā)現(xiàn)哪個(gè)方向使“貓”類的概率增加,然后它們給予這個(gè)方向一點(diǎn)推動(dòng)力(換句話說(shuō),它們擾亂輸入)。這張新的、修改后的圖像被錯(cuò)誤地認(rèn)為是一只貓。
但是如果沒有梯度,如果對(duì)圖像進(jìn)行一個(gè)無(wú)窮小的修改會(huì)導(dǎo)致模型的輸出沒有變化,那該怎么辦?這似乎提供了一些防御,因?yàn)楣粽卟恢朗窍蚰膫€(gè)方向“助推”圖像。
我們可以很容易地想象一些非常簡(jiǎn)單的方法來(lái)擺脫梯度。例如,大多數(shù)圖像分類模型可以在兩種模式下運(yùn)行:一種模式是只輸出最可能的類的標(biāo)識(shí),另一種模式是輸出概率。如果模型的輸出是“99.9%的可能是飛機(jī),0.1%的可能是貓”,那么對(duì)輸入的微小改變會(huì)給輸出帶來(lái)很小的變化,而且梯度告訴我們哪個(gè)變化會(huì)增加“貓”類的概率。如果我們?cè)谳敵鲋皇恰帮w機(jī)”的模式下運(yùn)行模型,那么對(duì)輸入的微小改變就完全不會(huì)改變輸出,而且梯度不會(huì)告訴我們?nèi)魏螙|西。
讓我們進(jìn)行一個(gè)思考實(shí)驗(yàn),看看我們?cè)凇白羁赡艿念悺蹦J较拢皇恰案怕誓J健毕拢軌蛞栽鯓拥某潭葋?lái)保護(hù)我們的模型抵抗對(duì)抗樣本。攻擊者不再知道去哪里尋找那些將被歸類為貓的輸入,所以我們可能有了一些防御。不幸的是,之前被歸類為貓的每張圖像現(xiàn)在仍然被歸類為貓。如果攻擊者能夠猜測(cè)哪些點(diǎn)是對(duì)抗樣本,那么這些點(diǎn)仍然會(huì)被錯(cuò)誤分類。我們還沒有使這個(gè)模型更具魯棒性;我們剛剛給了攻擊者更少的線索來(lái)找出模型防御漏洞的位置。
更不幸的是,事實(shí)證明,攻擊者有一個(gè)非常好的策略來(lái)猜測(cè)防守漏洞的位置。攻擊者可以訓(xùn)練出自己的一種具有梯度的平滑模型來(lái)為它們的模型提供對(duì)抗樣本,然后將這些對(duì)抗樣本配置到我們的非平滑模型上。很多時(shí)候,我們的模型也會(huì)對(duì)這些樣本進(jìn)行錯(cuò)誤的分類。最后,我們的思考實(shí)驗(yàn)表明,隱藏梯度并沒有給我們帶來(lái)任何幫助。
執(zhí)行梯度掩碼的防御策略通常會(huì)導(dǎo)致一個(gè)模型在特定的方向和訓(xùn)練點(diǎn)的附近非常平滑,這使得攻擊者很難找到指示好候選方向的梯度,從而以損害模型的方式干擾輸入。然而,攻擊者可以訓(xùn)練一種替代模型:一種通過(guò)觀察被防御模型分配給攻擊者精心選擇的輸入的標(biāo)簽來(lái)模仿防御模型的副本。
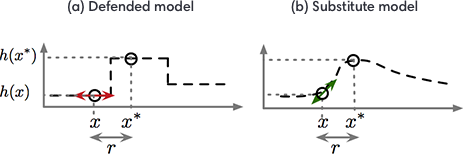
在“黑箱攻擊”論文中引入了執(zhí)行這種模型提取攻擊的過(guò)程。然后,攻擊者還可以使用替代模型的梯度來(lái)找到被防御模型錯(cuò)誤分類的對(duì)抗樣本。在上圖中,對(duì)從《機(jī)器學(xué)習(xí)中的安全和隱私科學(xué)》(Towards the Science of Security and Privacy in Machine Learning)中找到的梯度掩碼的討論再現(xiàn),我們用一維的ML問題來(lái)說(shuō)明這種攻擊策略。對(duì)于更高維度的問題,梯度掩碼現(xiàn)象將會(huì)加劇,但難以描述。
我們發(fā)現(xiàn),對(duì)抗性訓(xùn)練和防御性精煉都意外地執(zhí)行了一種梯度掩碼。這兩種算法都沒有明確地被設(shè)計(jì)來(lái)執(zhí)行梯度掩碼,但是當(dāng)算法被訓(xùn)練來(lái)保護(hù)自己并且沒有給出具體的指令時(shí),梯度掩碼顯然是一種機(jī)器學(xué)習(xí)算法可以相對(duì)容易地發(fā)明出的防御措施。如果我們將對(duì)抗樣本從一個(gè)模型遷移到另一個(gè)用對(duì)抗性訓(xùn)練或防御性精煉訓(xùn)練過(guò)的模型,攻擊通常也會(huì)成功,即使對(duì)第二個(gè)模型直接的攻擊失敗了。這表明,這兩種訓(xùn)練技術(shù)都會(huì)做更多的工作來(lái)使模型平滑并消除梯度,而不是確保它能夠正確地對(duì)更多的點(diǎn)進(jìn)行分類。
為什么很難防御對(duì)抗樣本
難以防御對(duì)抗樣本,因?yàn)殡y以構(gòu)建一個(gè)對(duì)抗樣本制作過(guò)程的理論模型。對(duì)于包括神經(jīng)網(wǎng)絡(luò)在內(nèi)的許多ML模型來(lái)說(shuō),對(duì)抗樣本是對(duì)非線性和非凸性的優(yōu)化問題的解決方案。因?yàn)槲覀儧]有很好的理論工具來(lái)描述這些復(fù)雜的優(yōu)化問題的解決方案,所以很難做出任何理論上的論證來(lái)證明一個(gè)防御系統(tǒng)會(huì)排除一系列對(duì)抗樣本。
難以防御對(duì)抗樣本,還因?yàn)樗鼈円髾C(jī)器學(xué)習(xí)模型為每一個(gè)可能的輸入產(chǎn)生良好的輸出。大多數(shù)情況下,機(jī)器學(xué)習(xí)模型運(yùn)行得很好,但所能處理的只是它們可能遇到的所有可能輸入中的很小一部分。
我們迄今為止測(cè)試的每一種策略都失敗了,因?yàn)樗皇亲赃m應(yīng)的:它可能會(huì)阻止一種攻擊,但是留給攻擊者另一個(gè)漏洞,而攻擊者知道此次所使用的防御。設(shè)計(jì)一種可以防御強(qiáng)大的、自適應(yīng)的攻擊者的防御系統(tǒng)是一個(gè)重要的研究領(lǐng)域。
結(jié)論
對(duì)抗樣本表明,許多現(xiàn)代機(jī)器學(xué)習(xí)算法可以以多種令人驚訝的方式被打破。機(jī)器學(xué)習(xí)的這些失敗表明,即使是簡(jiǎn)單的算法也能與其設(shè)計(jì)者的意圖截然不同。我們鼓勵(lì)機(jī)器學(xué)習(xí)研究人員參與進(jìn)來(lái)并設(shè)計(jì)防范對(duì)抗樣本的方法,以縮小設(shè)計(jì)師意圖和算法行為之間的差距。
-
人工智能
+關(guān)注
關(guān)注
1791文章
46872瀏覽量
237598 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8378瀏覽量
132417
原文標(biāo)題:OpenAI詳細(xì)解析:攻擊者是如何使用「對(duì)抗樣本」攻擊機(jī)器學(xué)習(xí)的
文章出處:【微信號(hào):gh_ecbcc3b6eabf,微信公眾號(hào):人工智能和機(jī)器人研究院】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
電子對(duì)抗系統(tǒng)中的概率準(zhǔn)則存在哪些缺陷?
數(shù)據(jù)轉(zhuǎn)換器是如何拯救電子監(jiān)控與對(duì)抗系統(tǒng)的?
網(wǎng)絡(luò)對(duì)抗訓(xùn)練模擬系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)
機(jī)載雷達(dá)對(duì)抗系統(tǒng)仿真
機(jī)器學(xué)習(xí)算法之基于黑盒語(yǔ)音識(shí)別的目標(biāo)對(duì)抗樣本
對(duì)抗樣本真的是bug嗎?對(duì)抗樣本不是Bug, 它們是特征

Reddit熱議MIT新發(fā)現(xiàn) 對(duì)抗樣本是有意義的數(shù)據(jù)特征

如何在NLP領(lǐng)域?qū)嵤?b class='flag-5'>對(duì)抗攻擊
深度學(xué)習(xí)模型的對(duì)抗攻擊及防御措施

基于生成器的圖像分類對(duì)抗樣本生成模型

基于深度學(xué)習(xí)的自然語(yǔ)言處理對(duì)抗樣本模型
GAN圖像對(duì)抗樣本生成方法研究綜述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論