 是什么讓變分自編碼器成為如此成功的多媒體生成工具呢?
是什么讓變分自編碼器成為如此成功的多媒體生成工具呢?
與經常作為分類器的神經網絡相比,變分自編碼器是一種十分著名的生成模型,目前被廣泛用于生成偽造的人臉照片,甚至可以用于生成美妙的音樂。然而是什么讓變分自編碼器成為如此成功的多媒體生成工具呢?讓我們來一探其背后的究竟。
當我們使用生成模型時也許只想生成隨機的和訓練數據類似的輸出,但如果想生成特殊的數據或者在已有數據上進行一定的探索那么普通的自動編碼器就不一定能滿足了。而這正是變分自編碼器的獨特之處。
標準自編碼器
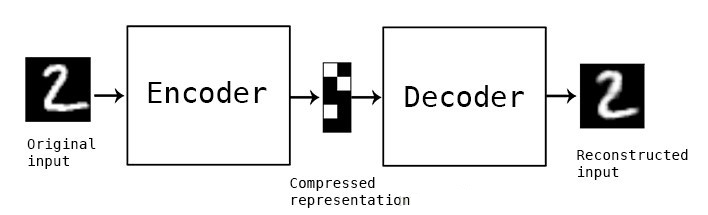
一個標準的自編碼器網絡實際上是一對兒相互連接的神經網絡,包括編碼器和解碼器。編碼器神經網絡將輸入數據轉化為更小更緊湊的編碼表達,而解碼器則將這一編碼重新恢復為原始輸入數據。下面我們用卷積神經網絡來對自編碼器進行具體的說明。
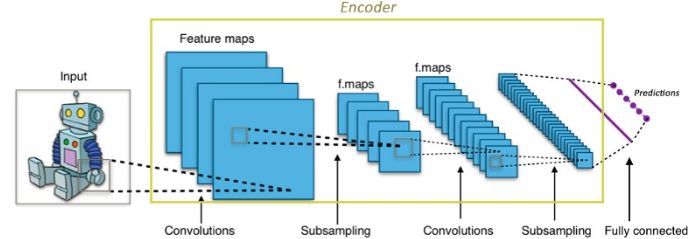
自編碼器中的CNNs
對于卷積神經網絡CNNs來說,將輸入的圖像轉換為更為緊密的表達(ImageNet中通常為1000維的一階張量)。這一緊密的表達用于對輸入圖像進行分類。編碼器的工作原理也與此類似,它將輸入數據轉換為十分小而緊湊的表達(編碼),其中包含了可供解碼器生成期望輸出的足夠信息。編碼器一般與網絡的其他部分一同訓練并通過反向傳播的誤差進行優化從而生成有用的特殊編碼。對于CNNs來說,可以將其看做是特殊的編碼器。其輸出的1000維編碼便是用于分類的分類器。
自編碼器便是基于這樣的思想將編碼器輸出的編碼用作重建其輸入的特殊用途。
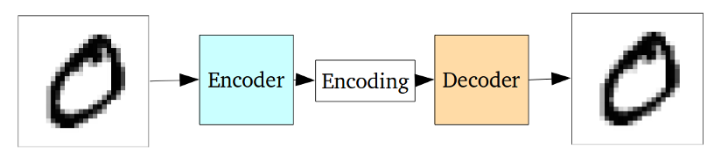
標準的自編碼器
整個自編碼器神經網絡常常作為整體進行訓練,其損失函數則定義為重建輸出與原始輸入之間的均方差/交叉熵,作為重建損失函數來懲罰網絡生成與原始輸入不同的輸出。
中間的編碼作為隱藏層間鏈接的輸出,其維度遠遠小于輸出數據。編碼器必須選擇性的拋棄數據,將盡可能多的相關信息包含到有限的編碼中,同時智能的去除不相關的信息。解碼器則需要從編碼中盡可能的學習如何重建輸入圖像。他們一起構成了自編碼器的左膀右臂。
標準自編碼器面臨的問題
標準自編碼器能學習生成緊湊的數據表達并重建輸入數據,然而除了像去噪自編碼器等為數不多的應用外,它的應用卻極其有限。其根本原因在于自編碼器將輸入轉換為隱含空間中的表達并不是連續的,使得其中的插值和擾動難以完成。
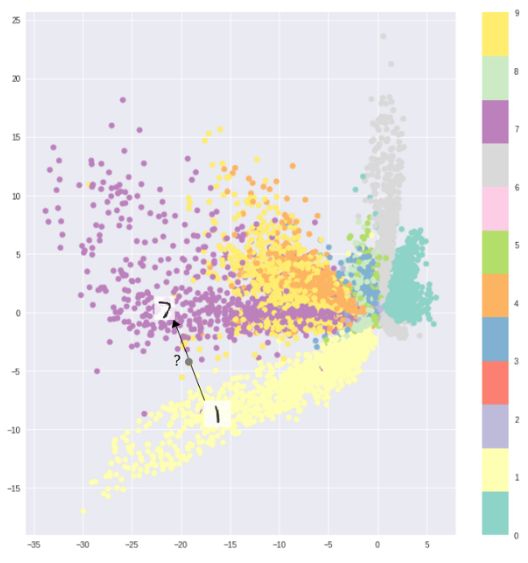
MNIST數據不同分類間的間隔造成了編碼器無法連續采樣
例如利用MNIST數據集訓練的自編碼器將數據映射到2D隱含空間中,圖中顯示不同的分類之間存在著明顯的距離。這使得解碼器對于存在于類別之間的區域無法便捷的進行解碼。如果你不想僅僅只是復現輸入圖像,而是想從隱含空間中隨機的采樣或是在輸入圖像上生成一定的變化,那此時一個連續的隱含空間就變得必不可少了。
如果隱含空間不連續,那么在不同類別中間空白的地方采樣后解碼器就會生成非真實的輸出。因為解碼器不知道如何除了一片空白的隱含區域,它在訓練過程中從未見到過處于這一區域的樣本。
變分自編碼器
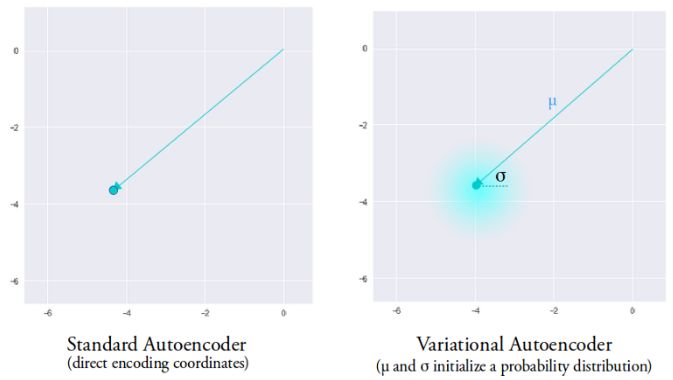
變分自編碼器具有與標準自編碼器完全不同的特性,它的隱含空間被設計為連續的分布以便進行隨機采樣和插值,這使得它成為了有效的生成模型。它通過很獨特的方式來實現這一特性,編碼器不是輸出先前的n維度向量而是輸出兩個n維矢量:分別是均值向量μ和標準差向量σ。
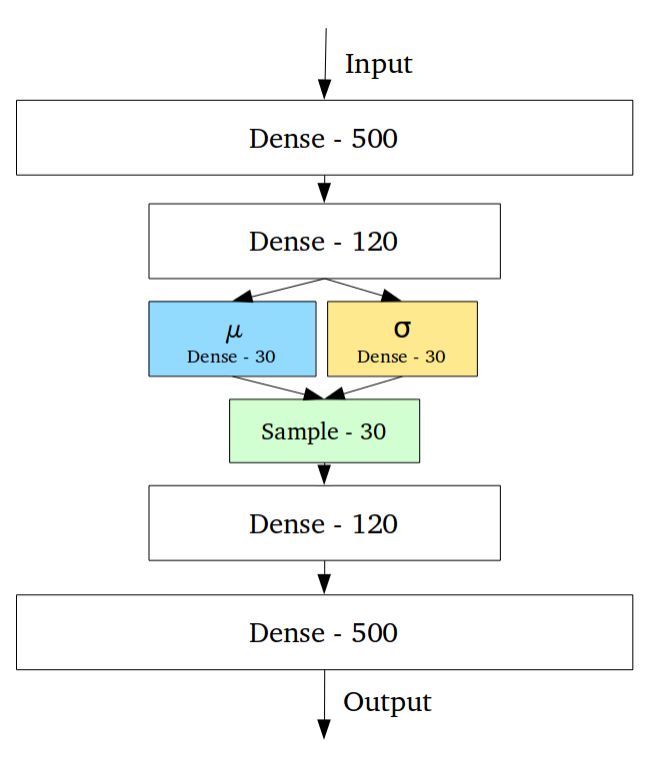
隨后通過對μ和σ作為均值和方差采樣得到了隨機變量Xi,n次采樣后形成了n維的采樣后結果作為編碼輸出,并送入后續的解碼器。

隨機生成編碼矢量
這一隨機生成意味著即使對于均值和方差相同的輸入,實際的編碼也會由于每一次采樣的不同而產生不同的編碼結果。其中均值矢量控制著編碼輸入的中心,而標準差則控制著這一區域的大小(編碼可以從均值發生變化的范圍)。
通過采樣得到的編碼可以是這一區域里的任意位置,解碼器學習到的不僅是單個點在隱含空間中的表示,而是整個鄰域內點的編碼表示。這使得解碼器不僅僅能解碼隱含空間中單一特定的編碼,而且可以解碼在一定程度上變化的編碼,而這是由于解碼器通過了一定程度上變化的編碼訓練而成。
所得到的模型目前就暴露在了一定程度局域變化的編碼中,使得隱含空間中的相似樣本在局域尺度上變得平滑。理想情況下不相似的樣本在隱含空間中存在一定重疊,使得在不同類別間的插值成為可能。但這樣的方法還存在一個問題,我們無法對μ和σ的取值給出限制,這會造成編碼器在不同類別上學習出的均值相去甚遠,使它們間的聚類分開。最小化σ使得相同的樣本不會產生太大差異。這使得解碼器可以從訓練數據進行高效重建。
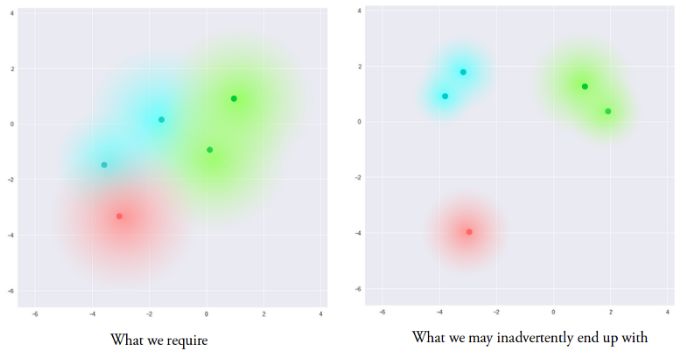
我們希望得到盡量互相靠近但依然有一定距離的編碼,以便在隱含空間中進行插值并重建出新的樣本。為了實現滿足要求的編碼需要在損失函數中引入Kullback-Leibler散度(KL散度)。KL散度描述兩個概率分布之間的發散程度。最小化KL散度在這里意味著優化概率分布的參數(μ,σ)盡可能的接近目標分布。
對于VAE來說KL損失函數是X中所有元素Xi~N(μi, σi2)與標準正態分布的散度和。
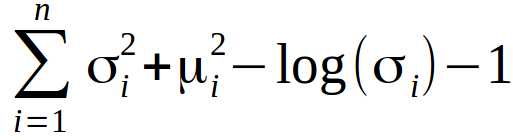
這一損失函數將鼓勵所有編碼在圍繞隱藏層中心分布,同時懲罰不同分類被聚類到分離區域的行為。利用純粹KL散度損失得到的編碼是以隱藏空間中心隨機分布的。但從這些無意義的表達中解碼器卻無從解碼出有意義的信息。
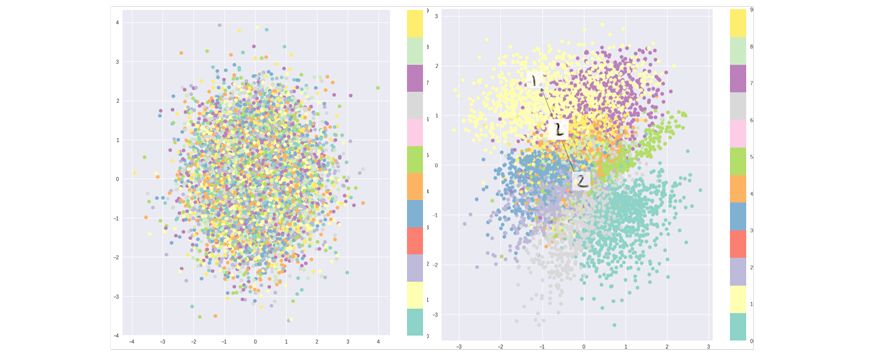
純粹的KL散度優化的隱含空間(左),結合了重建損失優化的隱含空間
這是就需要將KL損失和重建損失結合起來。這使得在局域范圍內的隱藏空間點維持了相同的類別,同時在全局范圍內所有的點也被緊湊的壓縮到了連續的隱含空間中。這一結果是通過重建損失的聚類行為和KL損失的緊密分布行為平衡得到的,從而形成了可供解碼器解碼的隱含空間分布。這意味著可以隨機的采樣并在隱含空間中平滑的插值,得到的結果可控解碼器生成有意義的有效結果。

最終的損失函數
矢量運算
那么現在我們如何在隱含空間中得到平滑的插值呢?這主要通過隱含空間中的矢量運算來實現。
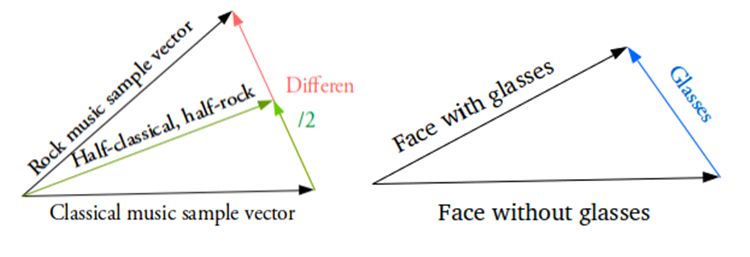
例如想得到兩個樣本之間的新樣本,那么只需要計算出他們均值矢量之差,并以其一半加上原來的矢量。最后將得到的結果送入到解碼器即可。那對于特殊的特征也,比如生成眼鏡該如何操作呢?那就找到分別戴眼鏡和不戴眼鏡的樣本,并得到他們在編碼器隱含空間中矢量之差,這就表示了眼鏡這一特征。將這新的“眼鏡”矢量加到任意的人臉矢量后進行解碼即可得到戴眼鏡的人臉。
展望
對于變分自編碼來說,目前已經出現了各種各樣的改進算法。可以增加、替換標準的全連接編解碼器,并用卷積網絡來代替。有人利用它生成了各種各樣的人臉和著名的MNIST變化數據。
甚至可以用LSTM訓練編解碼器訓練時序離散數據,從而生成文本和音樂等序列樣本。甚至可以模仿人類的簡筆畫。
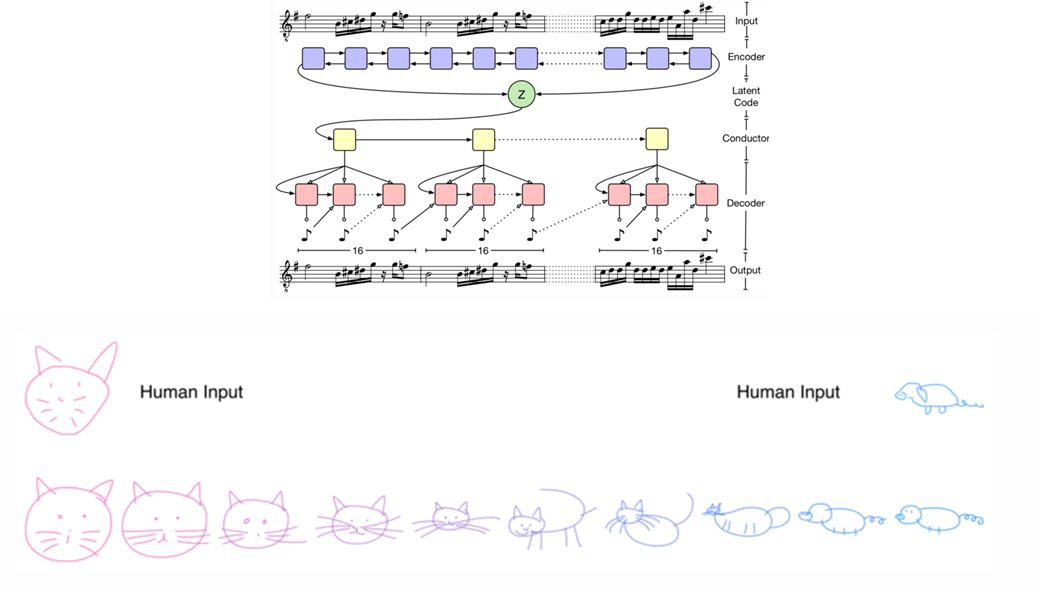
VAE對于各種各樣的數據都有很好的適應性,無論序列或非序列、連續或離散、標記或非標記數據都是強大的生成工具。期待能在未來看到更多獨特矚目的應用。
-
編碼器
+關注
關注
45文章
3601瀏覽量
134201 -
神經網絡
+關注
關注
42文章
4765瀏覽量
100561
原文標題:一篇文章告訴你「變分自編碼器 (VAE)」的優秀
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是編碼器 什么叫編碼器 編碼器什么意思
自編碼器介紹
稀疏自編碼器及TensorFlow實現詳解
基于稀疏自編碼器的屬性網絡嵌入算法SAANE
自編碼器基礎理論與實現方法、應用綜述

基于變分自編碼器的網絡表示學習方法
自編碼器神經網絡應用及實驗綜述
堆疊降噪自動編碼器(SDAE)
自編碼器 AE(AutoEncoder)程序






 工商網監
工商網監
評論