 一文解析Google基于SDN的B4網絡
一文解析Google基于SDN的B4網絡
如果要問當前最著名、最有影響力的基于SDN技術搭建的商用網絡是哪個,我想大多數人都會投票給Google的B4網絡,一方面因為Google本 身的名氣,另一方面也是因為Google在這個網絡的搭建上投入大、周期長,最后的驗證效果也很好,是為數不多的大型SDN商用案例,而且非常成功,是充 分利用了SDN優點(特別是OpenFlow協議)的案例。
背景介紹
Google 的網絡分為數據中心內部網絡(IDC Network)及骨干網(Backbone Network,也可以稱為WAN網)。其中WAN網按照流量方向由兩張骨干網構成,分別為:第一,數據中心之間互聯的網絡(Inter-DC WAN,即G-scale Network),用來連接Google位于世界各地之間的數據中心,屬于內部網絡;第二,面向Internet用戶訪問的網絡(Internet- facing WAN,即I-Scale Network)。Google選擇使用SDN來改造數據中心之間互聯的WAN網(即G-scale Network),因為這個網絡相對簡單,設備類型以及功能比較單一,而且WAN網鏈路成本高昂(比如很多海底光纜),所以對WAN網的改造無論建設成本、運營成本收益都非常顯著。他們把這個網絡稱為B4(我在網上搜了一下也沒找到該名字的由來)。
Google的數據中心之間傳輸的數據可以分為三大類:
1、用戶數據備份,包括視頻、圖片、語音和文字等;
2、遠程跨數據中心存儲訪問,例如計算資源和存儲資源分布在不同的數據中心;
3、大規模的數據同步(為了分布式訪問,負載分擔)。
這三大類從前往后數據量依次變大,對延時的敏感度依次降低,優先級依次變低。這些都是B4網絡改造中涉及 到的流量工程(TE,Traffic Engineering)部分所要考慮的因素。
促使Google使用SDN改造WAN網的最大原因是 當前連接WAN網的鏈路帶寬利用率很低。GoogleWAN網的出口設備有上百條對外鏈路,分成很多的ECMP負載均衡組,在這些均衡組內的多條鏈路之間 用的是基于靜態Hash的負載均衡方式。由于靜態Hash的方式并不能做到完全均衡,為了避免很大的流量都被分發到同一個鏈路上導致丟包,Google不 得不使用過量鏈路,提供比實際需要多得多的帶寬。這導致實際鏈路帶寬利用率只有30%~40%,且仍不可避免有的鏈路很空,有的鏈路產生擁塞,設備必須支持很大的包緩存,成本太高,而且也無法對上文中不同的數據區別對待。從一個數據中心到另外一個數據中心,中間可以經過不同的數據中心,比如可以是 A→B→D,也可以是A→C→D,也許有的時候B很忙,C很空,路徑不是最優。除此之外,增加網絡可見性、穩定性,簡化管理,希望靠應用程序來控制網絡, 都是本次網絡改造的動機之一。以上原因也決定了Google這個基于SDN的網絡,最主要的應用是流量工程,最主要的控制手段是軟件應用程序。
Google對B4網絡的改造方法,充分考慮了其網絡的一些特性以及想要達到的主要目標,一切都圍繞這幾個事實或者期望。
Google B4網絡的絕大多數的流量都是來自數據中心之間的數據同步應用,這些應用希望給它們的帶寬越大越好,但是可以容忍偶爾的擁塞丟包、鏈路不通以及高延時。Google再強大,數據中心的數量也是有限的,這個特點意味著Controller的scalability的壓力相對小很多。
Google能夠控制應用數據以及每個數據中心的邊界網絡,希望通過控制應用數據的優先級和網絡邊緣的突發流量(Burst)來優化路徑,緩解帶寬壓力,而不是靠無限制地增大出口帶寬。
這個網絡必須要考慮成本,雖然Google富可敵國,但其WAN網的數據流量每天都在增加,無法承受無止境的設備成本的增加,所以必須想辦法降低成本。
Google的部署分為三個階段。
第一階段在2010年春天完成,把OpenFlow交換機引入到網絡里面,但這時OpenFlow交換機對同網絡中的其他非OpenFlow設備表現得就像是傳統交換機一樣,只是網絡協議都是在Controller上完成的,外部行為來看表現得仍然像傳統網絡。
第二階段是到 2011年中完成,這個階段引入更多流量到OpenFlow網絡中,并且開始引入SDN管理,讓網絡開始向SDN網絡演變。
第三個階段在2012年初完 成,整個B4網絡完全切換到了OpenFlow網絡,引入了流量工程,完全靠OpenFlow來規劃流量路徑,對網絡流量進行極大的優化。
為了對這個方案進行充分測試,Google運用了其強大的軟件能力,用軟件模擬了整個B4網絡拓撲和流量。
具體實現
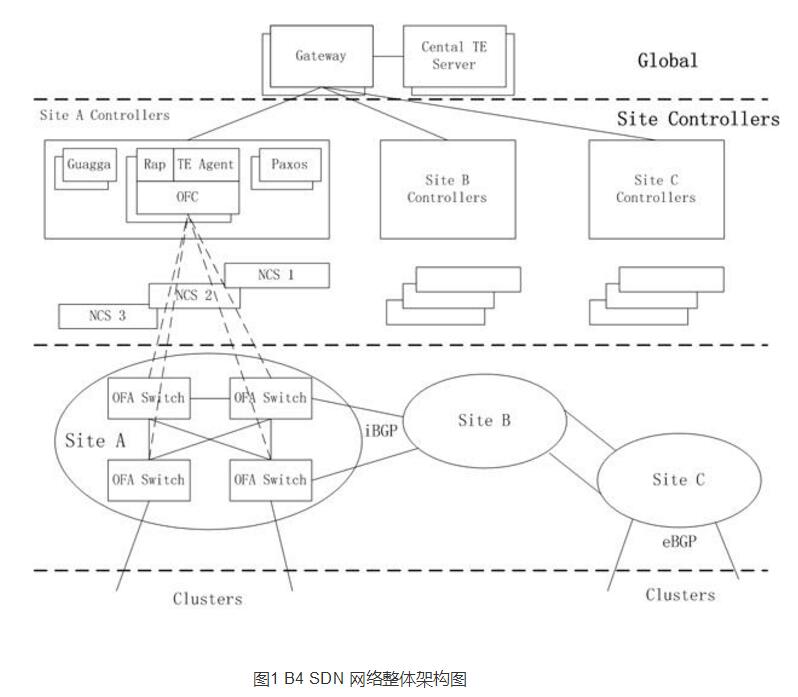
雖然該網絡的應用場景相對簡單,但用來控制該網絡的這套系統并不簡單,它充分體現了Google強大的軟件能力。這個網絡一共分為三個層次,分別是物理設備層(Switch Hardware)、局部網絡控制層(Site Controllers)和全局控制層(Global)。一個Site就是一個數據中心。第一層的物理交換機和第二層的Controller在每個數據中心的內部出口的地方都有部署,而第三層的SDN網關和TE服務器則是在一個全局統一的控制地。 第一層:物理設備層
第一層的物理交換機是Google自己設計并請ODM廠商代工的,用了24顆16×10Gb的芯片,搭建了一個128個10Gb端口的交換機。交換機里面運 行了OpenFlow協議,但它并非僅僅使用一般的OpenFlow交換機最常使用的ACL表,而是用了TTP的方式,包括ACL表、路由表和 Tunnel表等。但向上提供的是OpenFlow接口,只是內部做了包裝。這些交換機會把BGP/IS-IS協議報文送到Controller去供 Controller處理。
說到TTP這里要稍微介紹一下,TTP是ONF的FAWG工作組提出的一個在現有芯片架構基礎上包裝出 OpenFlow接口的一個折中方案。TTP是Table Typing Patterns的縮寫,中文不知道怎么翻譯能比較精確地表達它的本意,但TTP想要達到的目的是很清楚的,就是要利用現有芯片的處理邏輯和表項來組合出 OpenFlow想要達到的功能,當然不可能是所有功能,只能是部分。在2013年,ONF覺得TTP這個名字含義不夠清晰,無法望文生義,所以他們又給 它改了個名字叫NDM(Negotiabable Data-plane Model),即可協商的數據轉發面模型。我認為這個名字比TTP好多了,不僅因為我能翻譯出來,更重要的是這個名字中的三個單詞都能體現方案的精髓。 NDM其實是定義了一個框架,基于這個框架,允許廠商基于實際的應用需求和現有的芯片架構來定義很多種不同的轉發模型,每種模型可以涉及到多張表,匹配不 同的字段,基于查找結果執行不同的動作。由于是基于現有的芯片,所以無論匹配的字段還是執行的動作都是有限制的,不能隨心所欲。關于NDM有很多東西可以 講,但不是本文重點,這里略過不表。不過,我認為也許NDM將是OpenFlow的最終方案,它將大大推動OpenFlow以及SDN的發展。
第二層:局部網絡控制層
在我看來,第二層最復雜。第二層在每個數據中心出口并不是只有一臺服務器,而是有一個服務器集群,每個服務器上都運行了一個Controller,一臺交換 機可以連接到多個Controller,但其中只有一個處于工作狀態。一個Controller可以控制多臺交換機,一個名叫Paxos的程序用來進行 leader選舉(即選出工作狀態的Controller)。從文檔的描述來看,貌似這種選舉不是基于Controller的,而是基于功能的。也就是說 對于控制功能A,可能選舉Controller1為leader;而對于控制功能B,則有可能選舉Controller2為leader。這里說的leader就是OpenFlow標準里面的master。
Google用的Controller是基于分布式的Onix Controller改造來的。Onix是Nicira、Google、NEC和Berkerly大學的一些人一起參與設計的,由Nicira主導。這是 一個分布式架構的Controller模型,被設計用來控制大型網絡,具有很強的可擴展性。它通過引入Control Logic(控制邏輯,可以認為是特殊的應用程序)、Controller和物理設備三層架構,每個Controller只控制部分物理設備,并且只發送 匯聚過后的信息到邏輯控制服務器,邏輯控制服務器了解全網的拓撲情況,來達到分布式控制的目的,從而使整個方案具有高度可擴展性。
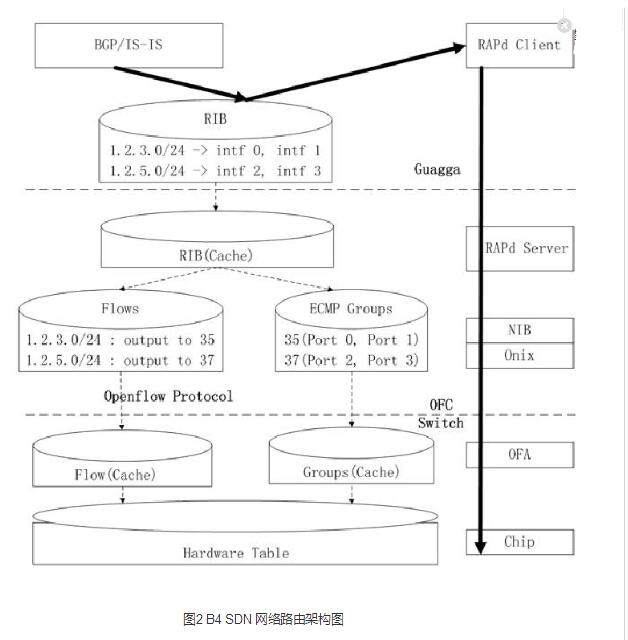
顯而易見,這個架構非常適合Google的網絡,對每個特定的控制功能(比如TE或者Route),每個site有一組Controller(邏輯上是一個)用 來控制該數據中心WAN網的交換機,而一個中心控制服務器運行控制邏輯來協調所有數據中心的所有Controller。 在Controller之上跑了兩個應用,一個叫RAP,是Routing Application Proxy的意思,作為SDN應用跟Quagga通信。Quagga是一個開源的三層路由協議棧,支持很多路由協議,Google用到了BGP和IS- IS。其中跟數據中心內部的路由器運行eBGP,跟其他數據中心WAN里面的設備之間運行iBGP。Onix Controller收到下面交換機送上來的路由協議報文以及鏈路狀態變化通知時,自己并不處理,而是通過RAP把它送給Quagga協議棧。 Controller會把它所管理的所有交換機的端口信息都通過RAP告訴Quagga,Quagga協議棧管理了所有這些端口。Quagga協議計算出 來的路由會在Controller里面保留一份(放在一個叫NIB的數據庫里面,即Network Information Base,類似于傳統路由中的RIB,而NIB是Onix里面的概念),同時會下發到交換機中。路由的下一跳可以是ECMP,即有多個等價下一跳,通過 Hash選擇一個出口。這是最標準的傳統路由轉發。它的路由架構圖如圖2所示。
跑在Controller上面的另外一個應用程序叫TE Agent,跟全局的Gateway通信。每個OpenFlow交換機的鏈路狀態(包括帶寬信息)會通過TE Agent送給全局的Gateway,Gateway匯總后,送給TE Server進行路徑計算。
第三層:全局控制層
第三層中,全局的TE Server通過SDN Gateway從各個數據中心的控制器收集鏈路信息,從而掌握路徑信息。這些路徑被以IP-In-IP Tunnel的方式創建而不是TE最經常使用的MPLS Tunnel,通過Gateway到Onix Controller,最終下發到交換機中。當一個新的業務數據要開始傳輸時,應用程序會評估該應用所需要耗用的帶寬,為它選擇一條最優路徑(如負載最輕 的但非最短路徑雖不丟包但延時大),然后把這個應用對應的流,通過Controller安裝到交換機中,并跟選擇的路徑綁定在一起,從而整體上使鏈路帶寬 利用率達到最優。
對帶寬的分配和路徑的計算是Google本次網絡改造的主要目標也是亮點所在,所以值得深入分析一下。我反復研究了一下Google的這一套邏輯,理出大概的思路,分享如下。 最理想的情況下,當然是能夠基于特定應用程序來分配帶寬,但那樣的話會導致流表項是一個天文數字,既不可能也無必要。Google的做法很聰明:基于{源數 據中心,目的數據中心,QoS}來維護流表項,因為同一類應用程序的QoS優先級(DSCP)都是一樣的,所以這樣做就等同于為所有的從一個數據中心發往 另外一個數據中心的同類別的數據匯聚成一條流。注意:單條流的出口并不是一個端口,而是一個ECMP組,芯片轉發時,會從ECMP組里面根據Hash選取 一條路徑轉發出去。
劃分出流之后,根據管理員配置的權重、優先級等參數,使用一個叫做bandwidth的函數計算出要為這條流分配多少帶寬。為了公平起見,帶寬分配是有最小帶寬和最大帶寬的,既不會飽死,也不會餓死。TE算法有兩個輸入源,一個是Controller通過SDN Gateway報上來的拓撲和鏈路情況,另一個就是bandwidth函數的輸出結果。TE算法要考慮多種因素,不僅僅是需要多少帶寬這么簡單。
TE Server將計算出來的每個流映射到哪個tunnel,并且分配多少帶寬的信息通過SDN Gateway下發到Controller,再由Controller安裝到交換機的TE轉發表中(ACL),這些轉發表項的優先級高于LPM路由表。 圖3是Google的TE架構圖。
有心的讀者可能會注意到,既然有了TE,那還用BGP路由協議干什么?沒錯,TE和BGP都可以為一條流生成轉發路徑,但TE生成的路徑放在ACL 表,BGP生成的放在路由表(LPM),進來的報文如果匹配到ACL表項,會優先使用ACL,匹配不到才會用路由表的結果。一臺交換機既要處理從內部發到 別的數據中心的數據,又要處理從別的數據中心發到本地數據中心內部的數據。對于前者,需要使用ACL Flow表來進行匹配查找,將報文封裝在Tunnel里面轉發去,轉發路徑是TE指定的,是最優路徑。而對于后者,則是解封裝之后直接根據LPM路由表轉 發。還有路過的報文(從一個數據中心經過本數據中心到另外一個數據中心),這種報文也是通過路由表轉發。
這種基于優先級的OpenFlow 轉發表項的設計還有一個很大的好處,就是TE和傳統路由轉發可以獨立存在,這也是為什么B4網絡改造可以分階段進行的原因。開始可以先用傳統路由表,后面 再把TE疊加上來。而且,就算是以后不想用TE時,也可以直接把TE給禁掉就行了,不需要對網絡做任何的改造。
SDN Gateway的作用
這里架構中有一個角色是SDN Gateway,為什么要有這個角色呢?它對TE Server抽象出了OpenFlow和交換機的實現細節,對TE Server來說看不到OpenFlow協議以及交換機具體實現。Controller報上來的鏈路狀態、帶寬、流信息經過它的抽象之后送給TEServer。TE Server下發的轉發表項信息經過SDN Gateway的翻譯之后,通過Controller送給交換機,安裝到芯片轉發表中。
B4網絡改造效果
經過改造之后,據說鏈路帶寬利用率提高了3倍以上,接近100%,鏈路成本大大降低,這應該算是最大的成效了,也是當初最主要的目標,現在看來目標是完成 了。另外的收獲還包括網絡更穩定,對路徑失效的反應更快,管理大大簡化,也不再需要交換機使用大的包緩存,對交換機的要求降低。Google認為 OpenFlow的能力已得到驗證和肯定,包括對整個網絡的視圖可以看得很清楚,可以更好地來做Traffice Engineering,從而更好地進行流量管控和規劃,更好地路由規劃,能夠清楚地了解網絡里面發生了什么事情,包括監控和報警。按照Google的話 說,超出了其最初的期望。 該案例對SDN的積極意義
Google這個基于SDN的網絡改造項目影響非常大,對SDN的推廣有著良好的示范作用,所以是ONF官網上僅有的兩個用戶案例之一(另外一個是NEC的一個醫院網絡的基于SDN的網絡虛擬化改造案例)。這個案例亮點極多,總結如下。
1. 這是第一個公開的使用分布式Controller的SDN應用案例,讓更多的人了解到分布式Controller如何協同工作,以及工作的效果如何。
2. 這是第一個公開的用于數據中心互聯的SDN案例,它證明了即使是在Google這種規模的網絡中,SDN也完全適用,盡管這不能證明SDN在數據中心內部也能用,但至少可以證明它可以用于大型網絡。只要技術得當,可擴展性問題也完全可以解決。
3. QoS。流量工程一直是很多數據中心以及運營商網絡的重點之一,Google這個案例給大家做了一個很好的示范。事實上,據我了解,在Google之后, 又有不少數據中心使用SDN技術來解決數據中心互聯的流量工程問題,比如美國的Vello公司跟國內的盛科網絡合作推出的數據互聯方案就是其中之一,雖然 沒有Google的這么復雜,但也足以滿足其客戶的需要。
4. 這個案例也向大家演示了如何在SDN環境中運行傳統的路由協議,讓大家了解到,SDN也并不都是靜態配置的,仍然會有動態協議。
5. 在這個案例中,軟件起到了決定性的作用,從應用程序到控制器,再到路由協議以及整個網絡的模擬測試平臺,都離不開Google強大的軟件能力。它充分展示了SDN時代,軟件對網絡的巨大影響力以及它所帶來的巨大價值。
Google的OpenFlow交換機使用了TTP的方式而不是標準的OpenFlow流表,但在接口上仍然遵循OpenFlow的要求,它有力地證明了要支持SDN,或者說要支持OpenFlow,并不一定需要專門的OpenFlow芯片。包裝一下現有的芯片,就可以解決大部分問題,就算有些問題還不能解決, 在現有的芯片基礎上做一下優化就可以了,而不需要推翻現有芯片架構,重新設計一顆所謂的OpenFlow芯片。
6. 這個案例實現了Controller之間的選舉機制,OpenFlow標準本身并沒有定義如何選舉。這個案例在這方面做了嘗試。
OpenFlow的挑戰
作為一次完整的全方位的實踐,當然不能只總結好的東西,也總結了OpenFlow仍然需要提高改進的地方,包括OpenFlow協議仍然不成熟,Master Controller(或者說leader)的選舉和控制面的責任劃分仍有很多挑戰,對于大型網絡流表項的下發會速度比較慢,到底哪些功能要留在交換機 上、哪些要移走還沒有一個很科學的劃分。但Google認為,這些問題都是可以克服的。
Google技術不走尋常路的特點也體現在它基于OpenFlow搭建的數據中心WAN網絡(B4) 中。雖然Google已在SIGCOMM上公布了自己的B4網絡技術細節,但很多人認為太深奧。本文將從專業的角度,深入B4網絡的各個層次,用通俗易懂的語言對其進行全面解讀。
-
谷歌
+關注
關注
27文章
6142瀏覽量
105114 -
sdn
+關注
關注
3文章
254瀏覽量
44763
發布評論請先 登錄
相關推薦
RS-485網絡故障查找與排除
ZVB4網絡分析儀,ZVB4
STM32網絡的三大件
IPv6網絡中基于域名的通用用戶標識系統

R4網絡中的關鍵技術
博通宣布Tomahawk 4網絡芯片已出貨 速率可達25.6Tb/s
一文詳談軟件定義網絡SDN
基于網絡地址和協議轉換實現IPv4網絡和IPv6網絡互連






 工商網監
工商網監
評論