 基于內容推薦(CB)的推薦算法
基于內容推薦(CB)的推薦算法
基于內容推薦概要
基于內容的信息推薦方法的理論依據主要來自于信息檢索和信息過濾,所謂的基于內容的推薦方法就是根據用戶過去的瀏覽記錄來向用戶推薦用戶沒有接觸過的推薦項。主要是從兩個方法來描述基于內容的推薦方法:啟發式的方法和基于模型的方法。啟發式的方法就是用戶憑借經驗來定義相關的計算公式,然后再根據公式的計算結果和實際的結果進行驗證,然后再不斷修改公式以達到最終目的。而對于模型的方法就是根據以往的數據作為數據集,然后根據這個數據集來學習出一個模型。一般的推薦系統中運用到的啟發式的方法就是使用tf-idf的方法來計算,跟還有tf-idf的方法計算出這個文檔中出現權重比較高的關鍵字作為描述用戶特征,并使用這些關鍵字作為描述用戶特征的向量;然后再根據被推薦項中的權重高的關鍵字來作為推薦項的屬性特征,然后再將這個兩個向量最相近的(與用戶特征的向量計算得分最高)的項推薦給用戶。在計算用戶特征向量和被推薦項的特征向量的相似性時,一般使用的是cosine方法,計算兩個向量之間夾角的cosine值。
基于內容推薦的步驟
1、對數據內容分析,得到物品的結構化描述
2、分析用戶過去的評分或評論過的物品的,作為用戶的訓練樣本
3、生成用戶畫像
a.可以是統計的結果(后面使用相似度計算)
b.也可以是一個預測模型(后面使用分類預測計算)
4、新的物品到來,分析新物品的物品畫像
5、利用用戶畫像構建的預測模型,預測是否應該推薦給用戶U
a.策略1:相似度計算
b.策略2:分類器做預測
6、進一步,預測模型可以計算出用戶對新物品的興趣度,進而排序
7、進一步,用戶模型在變化,通過反饋更新用戶畫像(用戶畫像在這里就是預測模型)
反饋-學習,構成了用戶畫像的動態變化
基于內容推薦的層次結構
* 內容分析器
文檔的數據處理
得到結構化的數據,存儲在物品庫中
* 信息學習器
收集有關用戶偏好的數據特征,泛華這些數據,構建用戶特征信息(機器學習)
通過歷史數據構建用戶興趣模型(通過分類的方法,提取特征,特征就是組建用戶畫像的基礎)
生成興趣特征(正樣本)和無興趣特征(負樣本)
* 過濾組件
將用戶的個人信息和物品匹配
生成二元或連續性的相關判斷(原型向量和物品向量的余弦相似度)
基于內容推薦(CB)的推薦算法
就目前看,Collaborative Filtering Recommendations (協同過濾,簡稱CF) 還是目前最流行的推薦方法,在研究界和工業界得到大量使用。但是,工業界真正使用的系統一般都不會只有CF推薦算法,Content-based Recommendations (基于內容推薦,CB) 基本也會是其中的一部分。
CB根據用戶過去喜歡的產品(items),為用戶推薦和他過去喜歡的產品相似的產品。例如,一個推薦飯店的系統可以依據某個用戶之前喜歡很多的烤肉店而為他推薦烤肉店。 CB最早主要是應用在信息檢索系統當中,所以很多信息檢索及信息過濾里的方法都能用于CB中。
推薦過程:
CB的推薦過程一般包括下面三步:
Item Representation:即對items做特征工程,通俗來說即對items的屬性表達出來,如item = 農夫山泉(品類:礦泉水,價格:1-5,etc);
Profile Learning:利用一個用戶(id)過去喜歡(以及不喜歡)的item的特征數據,來學習出此用戶的喜好特征(profile),如id=我,喜歡=(農夫山泉,麥當勞),不喜歡=(檳榔,香煙),etc。
Recommendation Generation:通過比較上一步得到的用戶profile與候選item的特征,為此用戶推薦一組相關性最大的item。
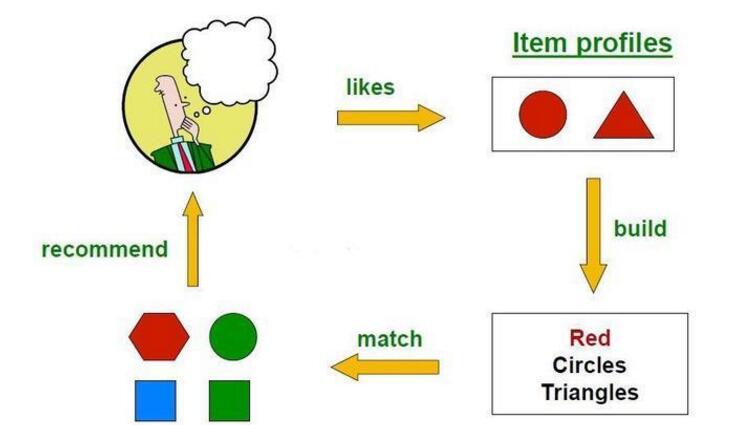
例子:
對于個性化閱讀來說,一個item就是一篇文章,第一步我們要提取文章中的關鍵詞組來表示文章的主題,可以采用的方法例如TF-IDF找文章中詞的權重,例如在python文章中“python”是主要被提及的字眼,那么該詞是關鍵字,利用這種方法,我們就可以把文章向量化。第二步是找出用戶之前喜歡的文章,通過上述TF-IDF方法,將其向量化,然后求平均值,來代表用戶大致喜歡的文章。如果用戶喜歡python語言,那么該用戶的profile中[‘python’]的權重占比較大。第三步就是通過以上二步得到的所有item和該用戶的profile進行匹配,計算方式一般用余弦相似度。
詳細過程
1.Item Representation
Item一般都會有一些描述它的屬性。這些屬性通常可以分為兩種:結構化(structured)和非結構化(unstructured)屬性。所謂結構化屬性就是可以被量化,可直接使用的屬性,如人有性別、學歷、地域等屬性。而非結構化屬性就是需要再進行二次解析,無法直接利用的屬性,如人的購買記錄,一篇文章的內容等。像文章這種非結構化數據可以利用TF-IDF和word2vec等算法把文章中的關鍵詞向量化表示出來。
如果用TF-IDF表示文章對應關鍵詞的權重,那么可以得到以下矩陣:
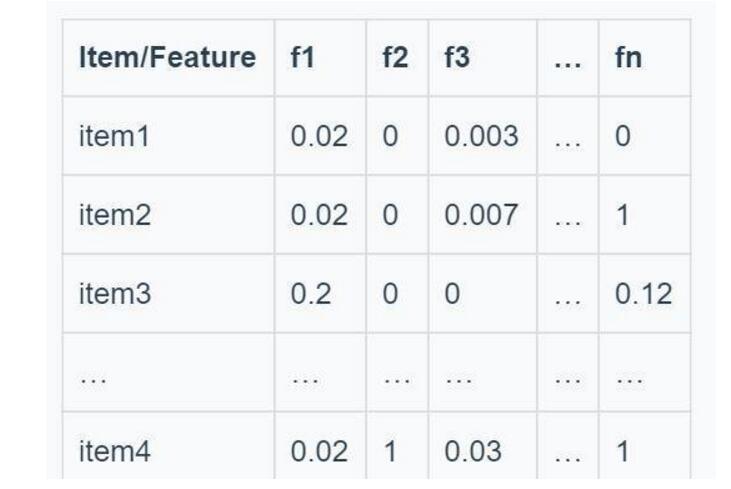
2.Profile Learning
假設用戶(id)已經對一些item做出了喜歡的判斷,對另一部分item做出了不喜歡的判斷,且這些item我們已經有了對應的向量化表示,那么這就是用戶的profile,如何簡單計算用戶的profile呢?公式如下:
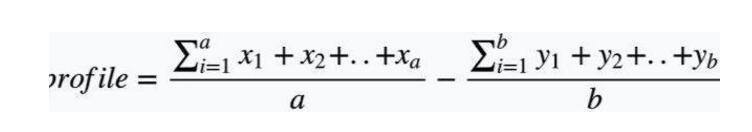
其中x是用戶喜歡的item,a是喜歡item的總數,y是用戶不喜歡的item,b是不喜歡item的總數。這時我們得到另一個用戶矩陣:(當然這里不是協同過濾,無需把全部用戶列成矩陣項,實際應用單個用戶id即可)
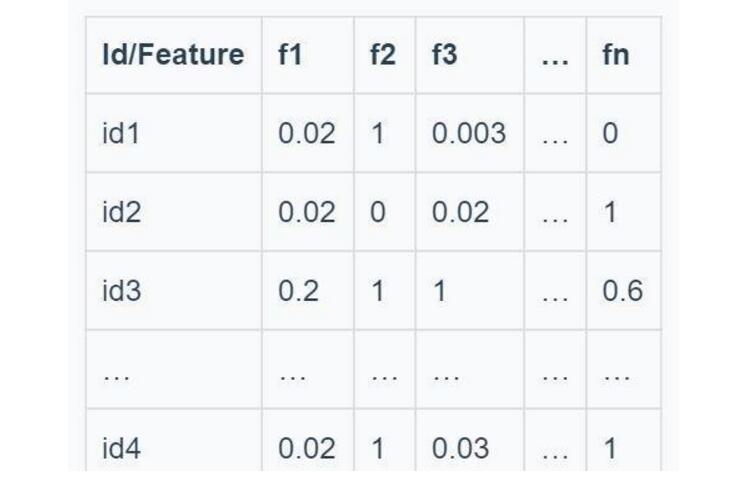
3.Recommendation Generation
通過以上二步得到的所有item和所有用戶的profile,那么要對一個用戶的profile和所有item進行匹配,此時我們計算的方式一般用余弦相似度。余弦相似度的計算方法如下,假設向量a、b的坐標分別為(x1,y1)、(x2,y2) 。則:
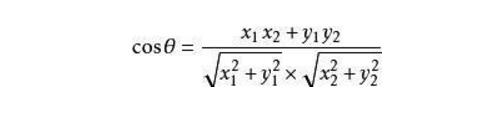
余弦值的范圍在[-1,1]之間,值越趨近于1,代表兩個向量的方向越接近;越趨近于-1,他們的方向越相反。如上述例子我們可以計算以下結果:
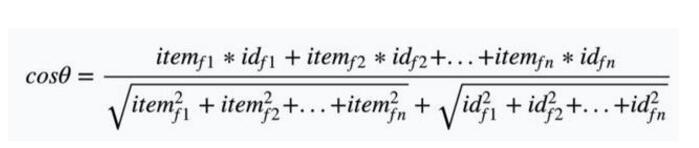
所以最終會把余弦值最大(跟用戶最相關的文章)的前N篇推薦給用戶。
優缺點
優點:可以使用當前的用戶評價來構建用戶的個人信息;由于過程簡單解釋性強,推薦的結果容易被人接受;對于新物品來沒有任何用戶評分的也可以推薦給用戶。
缺點:可分析的內容有限,且新穎度較差,新用戶需要用戶的偏好信息,無法解決冷啟動問題。
-
推薦算法
+關注
關注
0文章
47瀏覽量
9986
發布評論請先 登錄
相關推薦
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+內容簡介

基于BitTorrent種子的內容分發算法
基于內容的推薦算法概覽

基于位串內容感知的數據分塊算法

ASMT-CB00 直角ChipLED







 工商網監
工商網監
評論