 如何利用機器學習破解驗證碼的源代碼教程
如何利用機器學習破解驗證碼的源代碼教程
驗證碼的設計是為了防止計算機自動填寫表格,驗證你是一個真實的“人”。但隨著深度學習和計算機視覺的興起,現在他們往往容易被擊敗。
我一直在讀一本由AdrianRosebrock所寫的書《Deep Learning for Computer Vision with Python》(Python計算機視覺深度學習)。在這本書中,Adrian回顧了如何通過機器學習破解e – zpass紐約網站上的驗證碼系統:
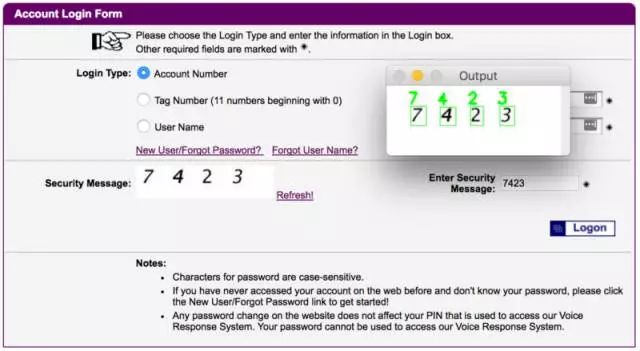
Adrian沒有訪問生成驗證碼圖像的應用程序的源代碼。為了破解這個系統,他不得不下載數百個示例圖像,并手動解決它們以訓練他的系統。
但是,如果我們想要破解一個開源的驗證碼系統,我們去哪里訪問源代碼呢?
我訪問了WordPress.org插件登記網站,并搜索了“CAPTCHA”。上面的結果被稱為“Really Simple CAPTCHA”,并且有超過100萬的安裝量:
WordPress.org插件登記地址:https://wordpress.org/plugins/
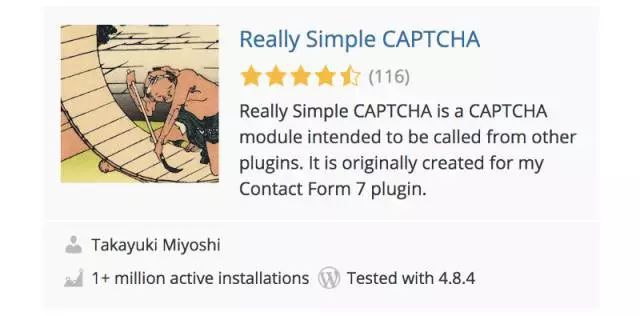
最棒的是,這里有它的源代碼!因為有生成驗證碼的源代碼,所以這應該很容易被破解。為了讓事情變得更有挑戰性,讓我們給自己一個時間限制。我們能在15分鐘內徹底破解這個驗證碼系統嗎?讓我們試一試!
重要提示:這絕不是批評“Really Simple CAPTCHA”插件或其作者。插件作者自己說它已經不安全了,建議你使用其他的東西。這只是一個有趣并且快速的技術挑戰。但如果你是100萬用戶之一,或許你應該有所防備了:)
挑戰
首先,讓我們需要知道 Really Simple CAPTCHA生成什么樣的圖像。在演示網站上,我們看到:
Really Simple CAPTCHA地址:https://wordpress.org/plugins/really-simple-captcha/

演示驗證碼圖片
驗證碼圖像看起來是四個字母。讓我們在PHP源代碼中驗證這一點:
public function __construct() { $this->chars = 'ABCDEFGHJKLMNPQRSTUVWXYZ23456789'; $this->char_length = 4;}
是的,它生成了4個字母的驗證碼,使用4種不同字體的隨機組合。我們可以看到,在代碼中它從不使用“O”或“I”,以此避免用戶的混淆。這就給我們留下了32個可能的字母和數字。
到目前為止的時間:2分鐘
我們的工具集
在我們進一步討論之前,我們先來討論一下解決這個問題需要的工具:
Python 3
Python是一種很有趣的編程語言,包含很好的機器學習和計算機視覺庫。
OpenCV
OpenCV是一個流行的計算機視覺和圖像處理框架。我們將使用OpenCV來處理驗證碼圖像。它有一個Python API,因此我們可以直接在Python中使用。
Keras
Keras是用Python編寫的深度學習框架。它使得定義、訓練和使用具有最小編碼的深度神經網絡變得很容易。
TensorFlow是谷歌的機器學習庫。我們將在Keras中編碼,但是Keras并沒有真正實現神經網絡邏輯本身。相反,它使用谷歌在幕后的TensorFlow庫來完成繁重的任務。
好了,回到挑戰。
創建數據集
訓練任何機器學習系統,都需要訓練數據。要破解驗證碼系統,我們需要這樣的訓練數據:

我們有了WordPress插件的源代碼,就可以修改它來保存10000個驗證碼圖像,以及每個圖像的預期答案。
在對代碼進行了幾分鐘的破解并添加了一個簡單的for循環之后,我有了一個包含訓練數據的文件夾—10,000個PNG文件,將正確的答案作為其文件名:

這是唯一的我不給你示例代碼的部分。我們這樣做是為了教學,我不希望你真的去垃圾郵件網站。但是我會給你我在最后生成的10000張照片,這樣你就可以復制我的結果。
到目前為止的時間:5分鐘
簡化問題
現在我們有了訓練數據,我們可以直接用它來訓練神經網絡:
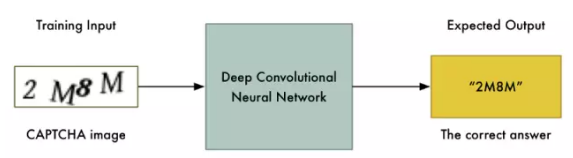
如果有足夠的訓練數據,這種方法可能有效——但是我們可以使問題變得簡單得多。問題越簡單,訓練數據越少,我們解決需要的計算力就越少。我們畢竟只有15分鐘!
幸運的是,驗證碼圖像通常只由四個字母組成。如果我們能把圖像分割開來,這樣每個字母都是一個單獨的圖像,那么我們只需訓練神經網絡識別單個字母:
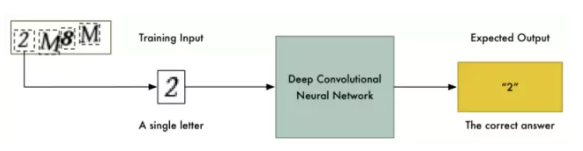
我沒有時間去瀏覽10000個訓練圖像,并且用Photoshop將它們手工分割成單獨的圖像。這需要幾天的時間,但我只剩下10分鐘了。我們不能將圖像分割成4個等分大小的塊,因為驗證碼隨機將字母放置在不同的水平位置,如下圖所示:
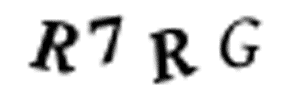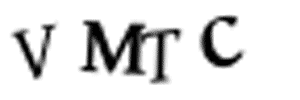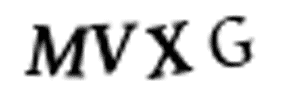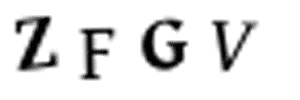
每個圖像中的字母都是隨機放置的,使圖像分割變得更加困難。
幸運的是,我們仍然可以實現自動化。在圖像處理中,我們經常需要檢測具有相同顏色的像素的“blob”。這些連續像素點的邊界稱為輪廓。OpenCV有一個內置的findContours()函數,我們可以用它來檢測這些連續區域。
我們將從一個原始的驗證碼圖像開始:
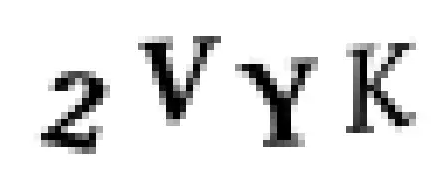
然后我們將圖像轉換成純黑白像素點(這稱為色彩閾值法),這樣就很容易找到連續區域的輪廓邊界:
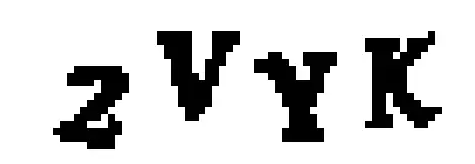
接下來,我們將使用OpenCV的findContours()函數來檢測圖像中包含相同顏色連續像素塊的分離部分:

接著把每個區域作為一個單獨的圖像文件保存。因為我們知道每個圖像應該包含從左到右的四個字母,所以我們可以用這些知識來標記我們保存的字母。我們按這個順序把它們存起來,并用相應的字母名稱來保存每一個圖像字母。
但是等一下—我發現問題了!有時驗證碼有這樣重疊的字母:
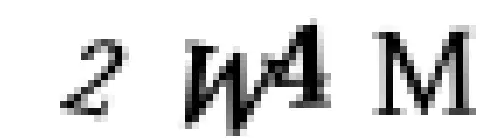
這意味著我們最終將提取將兩個字母拼湊在一起的區域:

如果我們不處理這個問題,我們就會產生糟糕的訓練數據。我們需要解決這個問題,這樣我們就不會偶然地讓機器將這兩個squashed – together字母識別為一個字母。
有一個簡單的竅門:如果一個區域的寬比它的高度大,那就意味著我們可能有兩個字母擠壓在一起了。在這種情況下,我們可以把這兩個字母放在中間,把它分成兩個獨立的字母:
現在我們有了一種提取單個字母的方法,讓我們在所有的驗證碼圖像中運行它。目的是收集每個字母的不同變體。我們可以把每個字母都保存在自己的文件夾里。
這是我摘取所有字母后,“W”文件夾的圖片:

到目前為止的時間:10分鐘
構建并訓練神經網絡
因為我們只需要識別單個字母的圖像,所以并需要一個非常復雜的神經網絡結構。識別字母比識別像貓和狗這樣的復雜圖像要容易得多。
我們將使用一個簡單的卷積神經網絡架構,它有兩個卷積層和兩個完全連通的層:

定義這個神經網絡架構只需要使用Keras的幾行代碼:
model = Sequential() model.add(Conv2D(20, (5, 5), padding="same", input_shape=(20, 20, 1), activation="relu")) model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2))) model.add(Conv2D(50, (5, 5), padding="same", activation="relu")) model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2))) model.add(Flatten()) model.add(Dense(500, activation="relu")) model.add(Dense(32, activation="softmax")) model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
現在我們可以運行它了。
# Train the neural network model.fit(X_train, Y_train, validation_data=(X_test, Y_test), batch_size=32, epochs=10, verbose=1)
經過訓練數據集10次之后,我們達到了接近100%的準確度。我們應該能夠在任何我們需要的時候自動繞過這個驗證碼。
時間過了:15分鐘
使用訓練的模型來以解決驗證碼
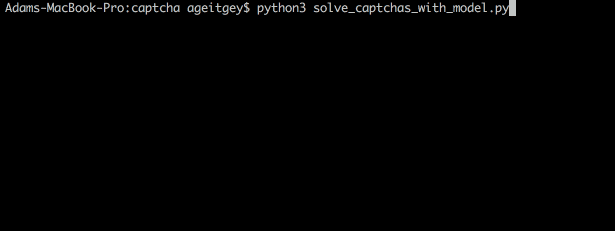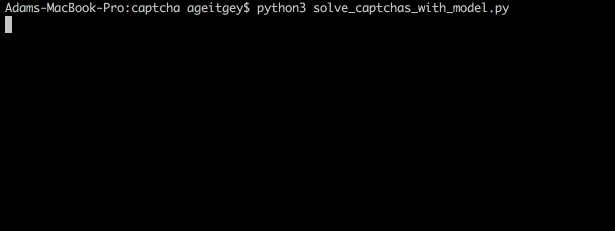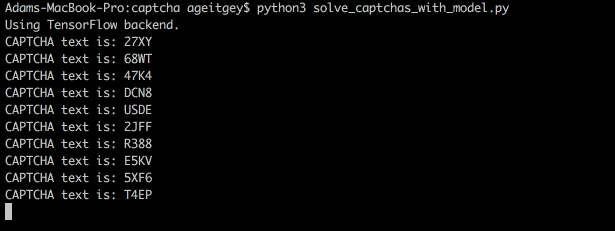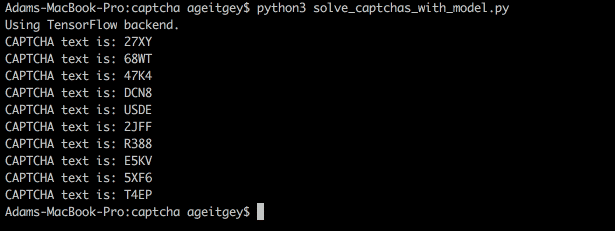
現在我們有了一個經過訓練的神經網絡,用它來破解驗證碼是很簡單的:
1. 從WordPress插件的網站上獲取真正的驗證碼圖像。
2. 用我們用來創建訓練數據集的方法將驗證碼圖像分割成四個不同的字母圖像。
3. 讓我們的神經網絡對每個字母圖像做一個單獨的預測。
4. 用四個預測字母作為驗證碼的答案。
下面是我們的模型如何解碼真實的驗證碼:
或從命令行:
-
源代碼
+關注
關注
96文章
2944瀏覽量
66673 -
機器學習
+關注
關注
66文章
8382瀏覽量
132439 -
驗證碼
+關注
關注
2文章
20瀏覽量
4694
原文標題:利用機器學習在15分鐘內破解驗證碼
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文解析驗證碼與打碼平臺的攻防對抗
打碼平臺是如何高效的破解市面上各家驗證碼平臺的各種形式驗證碼的?
多樣變換的手寫驗證碼自動識別算法
簡單地描述了如何用機器學習繞過E-ZPass New York網站的驗證碼
以一個真實網站的驗證碼為例,實現了基于一下KNN的驗證碼識別
驗證碼層出不窮?試試這個自動跳過驗證碼的工具
驗證碼太麻煩,自動跳過驗證碼神器試一試
一個用于破解Google驗證碼的方法
一個短信驗證碼爆破重置

Java 中驗證碼的使用





 工商網監
工商網監
評論