 深度學習解決方案的構建方式及應用
深度學習解決方案的構建方式及應用
摘要:英特爾人工智能產品事業部,數據科學主任Yinyin Liu近日撰寫了一篇文章,介紹了深度學習為自然語言處理帶來的種種變化。有趣的大趨勢是首先產生在CV領域的技術也不斷用于NLP,而深度學習解決方案的構建方式也隨著時間在進化。
自然語言處理(NLP)是最常見的人工智能的應用方式之一,它通過消費者數字助理、聊天機器人以及財務和法律記錄的文本分析等商業應用變得無處不在。隨著硬件和軟件能力的提升,以及模塊化NLP組件的發展,Intel 的技術也使得各種各樣的 NLP 應用成為可能。
深度學習性能的上升趨勢
近年來,許多 NLP 領域的進展都是由深度學習領域的普遍進步驅動的。深度學習擁有了更強大的計算資源,可以運用更大的數據集,并且在神經網絡拓撲結構和訓練范式方面有所發展。這些深度學習的進步始于推動計算機視覺應用的改進,但是也讓自然語言處理領域極大地獲益。
在深度學習的網絡層方面,為了使得信號和梯度能夠更容易地傳遞到深度神經網絡的每一層,殘差結構單元(residual layer)、highway 層(全連接的 highway 網絡)以及稠密連接(dense connections)結構應運而生。有了這些網絡層,目前最先進的計算機視覺技術通過利用深度學習網絡的表示能力得以實現。同時,他們也在許多自然語言處理任務上提高了模型的性能。例如,將稠密連接的循環層用于語言模型(Improving Language Modeling using Densely Connected Recurrent Neural Networks,https://arxiv.org/abs/1707.06130 )。
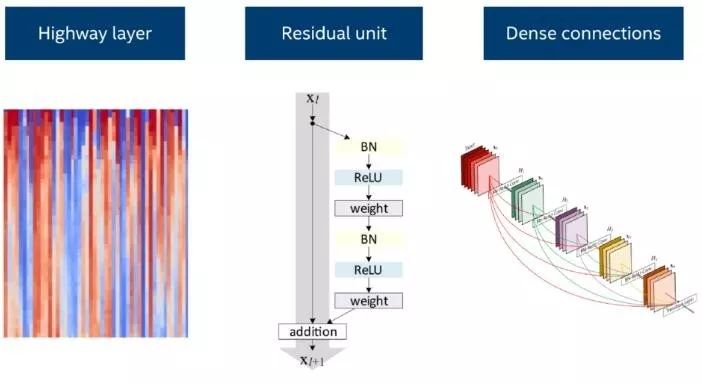
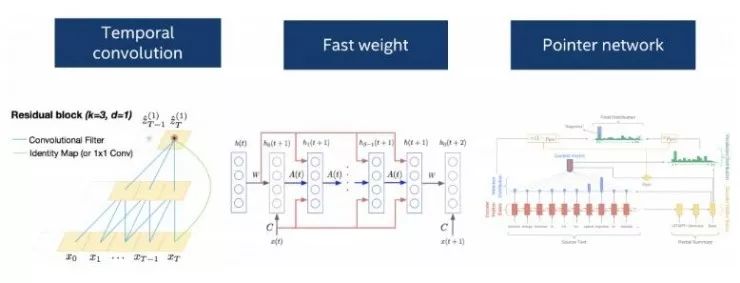
有實證研究中比較了卷積層、循環層或者一種結合了這兩種思想的時序卷積層的表現,時序卷積層在一系列的語言數據集上取得了目前最好的效果(Convolutional Sequence to Sequence Learning,https://arxiv.org/abs/1705.03122;An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling,https://arxiv.org/abs/1803.01271)。有這些不同類型的層可供靈活使用,使得開發者能夠在處理特定的自然語言處理問題時嘗試各種各樣的選項。
在深度學習的拓撲結構方面,一個自編碼器(auto-encoder)模型可以被改進為一個序列到序列(seq2seq)模型用于處理順序語言數據。注意力機制(attention mechanism)解決了隨著時間的推移,解碼網絡應該如何對輸入的編碼做出響應。指針網絡(Pointer network),作為注意力模型的一種變體,專門用于在輸入序列中尋找詞語的位置,它為機器閱讀理解和文本摘要提供了一種新的處理機制(Machine Comprehension Using Match-LSTM and Answer Pointer,https://arxiv.org/abs/1608.07905;Get To The Point: Summarization with Pointer-Generator Networks,https://arxiv.org/abs/1704.04368)。通過增加快速權重(fast weights),(Fast Weights to Attend to the Recent Past,https://arxiv.org/abs/1610.06258)短期聯想記憶的概念可以和長期序列的學習結合到一起。
在訓練范式方面,無監督學習利用訓練數據本身和遷移學習技術去構建數據表示,遷移學習可以把學到的將表征用于一個又一個的任務,都是從計算機視覺領域獲得啟發,推動了自然語言處理技術的進步。
由于這些深度學習模型共用了許多底層的組件,基于深度學習的自然語言處理解決方案可以與計算機視覺和其它人工智能功能的解決方案共用軟件和硬件。對于深度學習的通用軟件棧的優化也可以為深度學習自然語言處理解決方案的性能帶來改善。英特爾的人工智能硬件和軟件組合解決方案為這些在英特爾架構的系統上運行的深度學習進展提供了很好的示例。最近,在我們的硬件和對廣泛使用的深度學習框架的優化上的工作提供了為在英特爾至強可擴展處理器上運行普遍使用的模型和計算任務優化后的工作性能。英特爾也積極地將他們的這些努力回饋到開放的框架中,這樣一來,每個開發者都能很直接地獲得這些經驗。
為自然語言處理用例構建一個靈活的、模塊化的棧
由于基于深度學習的自然語言處理模型通常擁有共用的構建模塊(例如:深度學習網絡層和深度學習拓撲結構),這讓我們在構建自然語言處理用例的基礎時擁有了一個全新的視角。一些底層的功能在很多種應用中同時被需要。在一個開放的、靈活的棧中獲得基本組件對于解決各種各樣的自然語言處理問題是十分恰當的。
相比之下,傳統的機器學習或者深度學習的做法都是每一次只考慮某一個特定問題。而如今,由于深度學習社區已經提供了許多有用的基礎功能模塊,企業中的用戶和數據科學家們就可以考慮其它的方面,在學習、構建起基礎以后,著眼于如何把它們應用于各種不同的問題。
這種轉換的好處主要有這么幾點。首先,這些可以復用的組件可以幫助我們逐步構建「結構性資產」。通過重復應用之前已經構建好的東西,我們可以做得更快、評價得更快。其次,這些構建在英特爾的統一軟硬件平臺上的功能和解決方案可以持續不斷地從英特爾未來的開發和改進中受益。另外,用現有的基礎設施做實驗可以拓展出令人驚喜的新的解決方案或者新的應用,這是更早時候的僅關注于問題本身的思考方式所無法帶來的。
一個靈活的、模塊化的棧還能使用戶可以將傳統的自然語言處理方法和基于深度學習的方法結合起來,并為不同的用戶群提供不同層次的抽象。許多不同的企業用例表明了自然語言處理和它的基本組件的潛力。下面,我們為您提供了幾個例子,但是顯然還有很多別的可能性。
主題分析
金融業面臨著巨大的知識管理挑戰,這是由每天必須處理和理解的文件的數量(太大)所造成的。從一頁又一頁的文本中提取出諸如「某種特定產品的競爭力」這樣的關鍵的見解是十分困難的。
自然語言處理主題分析技術現在可以被用來快速分析大量的文檔,并且識別文檔中不同的部分所關聯的主題。不同的用戶會關注不同的話題,例如:某個公司的價值、競爭力、領導力或者宏觀經濟學。自然語言處理主題分析讓用戶能夠篩選出特定的感興趣的主題,并且獲得更加濃縮的信息。
為了利用大量未標記的數據,模型可以用內容類似的文本進行預訓練,之后這些數據表示可以被遷移至主題分析或者其它附加的任務中。早前的一篇博客介紹了這種解決方案中涉及到的一些方法的概述。為了實現這種方案,從自然語言處理構建模塊的角度來說,我們使用了序列到序列(seq2seq)的拓撲結構,長短期記憶網絡(LSTM),詞嵌入來自遷移學習,而后進行精細調節(fine-tune),還可以與命名實體識別等組件結合在一起。

趨勢分析
諸如醫療保健、工業制造、金融業等行業都面臨著從大量的文本數據中識別基于時間的趨勢的挑戰。通過將文本正則化、名詞短語分塊和抽取、語言模型、語料庫的詞頻-逆文本頻率指數(TF-IDF)算法,以及使用詞向量的分組等技術,我們可以快速的生成一個解決方案,它可以從一組文檔中抽取關鍵詞和重要性估計。接著,隨著時間的推移,通過比較這些抽取出來的關鍵詞,我們能夠發現有用的趨勢,例如:天氣變化如何能夠造成庫存的短缺,或者哪些領域的學術研究隨著時間的推移會吸引更多的貢獻和注意。
情感分析
情感分析功能通常被用于競爭力分析、溝通策略優化、以及產品或市場分析。一個提供了細粒度的情感分析的解決方案能夠為企業用戶提供可行的見解。例如:這種更有針對性的情感分析可以發現,關于一個特定商品的評論普遍是對于它的能耗的正面看法以及對它的可靠性的負面看法。對于這種細粒度的情感分析,我們使用了諸如詞性標注(POS tagging)、文本正則化、依存分析和詞匯擴展等組件。對于不同的領域,相同的的那次可能傳遞不同的情感,所以允許領域自適應的機制也是十分關鍵的。
多功能體系架構上靈活的構造模塊
當我們看到巨大的自然語言處理市場中的種種規劃時,我們應該如何構建解決方案、軟件、硬件來利用這些機會并使它們成為可能?在英特爾,我們希望構建能夠持續創新和改進的技術,這能夠給我們一個用于研究、實踐并應用算法的開放的、靈活的平臺,這種技術還能夠高效地擴展到多種應用程序中,最終形成影響深遠的商業見解。
在英特爾人工智能實驗室,我們的自然語言處理研究人員和開發者正在構建一個開放的、靈活的自然語言處理組件庫,以便為我們的合作伙伴和客戶實現多種自然語言處理用例。它使我們能夠高效地將我們靈活、可靠高性能的英特爾架構為這些自然語言處理應用、其他的人工智能和先進分析工作流提供了硬件、框架工具和軟件層。我們將繼續努力優化這些組件,以提高深度學習的能力。
-
英特爾
+關注
關注
60文章
9886瀏覽量
171528 -
機器視覺
+關注
關注
161文章
4345瀏覽量
120111 -
深度學習
+關注
關注
73文章
5492瀏覽量
120978
原文標題:NLP 解決方案是如何被深度學習改寫的?
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用

AI大模型與深度學習的關系
FPGA做深度學習能走多遠?
深度學習中的時間序列分類方法
基于AI深度學習的缺陷檢測系統
深度學習在視覺檢測中的應用
深度學習與nlp的區別在哪
深度學習與卷積神經網絡的應用
TensorFlow與PyTorch深度學習框架的比較與選擇
深度學習與傳統機器學習的對比
深度解析深度學習下的語義SLAM






 工商網監
工商網監
評論