 LSTM的工作原理究竟是什么?深入了解LSTM
LSTM的工作原理究竟是什么?深入了解LSTM
長短期記憶(Long Short-Term Memory,LSTM)是一種時間遞歸神經網絡(RNN),適合被用于處理和預測時間序列中間隔和延遲非常長的重要事件,經多年實驗證實,它通常比RNN和HMM效果更好。那么LSTM的工作原理究竟是什么?為了講述這個概念,搬運了chrisolah的一篇經典文章,希望能給各位讀者帶來幫助。
遞歸神經網絡
當人類接觸新事物時,他們不會從頭開始思考。就像你在閱讀這篇文章時,你會根據以前的知識理解每個單詞,而不是舍棄一切,從字母開始重新學習。換句話說,你的思維有延續性。
神經網絡的出現旨在賦予計算機人腦的機能,但在很長一段時間內,傳統的神經網絡并不能模仿到這一點。而這似乎是個很嚴峻的缺點,因為它意味著神經網絡無法從當前發生的事推斷之后將要發生的事,也就是無法分類電影中流暢發生的各個事件。
后來,遞歸神經網絡(RNN)的出現解決了這個問題,通過在網絡中添加循環,它能讓信息被“記憶”地更長久。
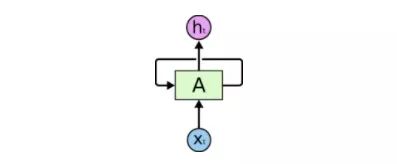
RNN有循環
上圖是一個大型神經網絡A,輸入一些數據xt后,它會輸出最終值ht。循環允許信息從當前步驟傳遞到下一個步驟。
這些循環使它看起來有些神秘。但如果仔細一想,你會發現其實它和普通的神經網絡并沒有太大區別:一個RNN就相當于是一個神經網絡的多個副本,每個副本都會把自己收集到的信息傳遞給后繼者。如果我們把它展開,它是這樣的:
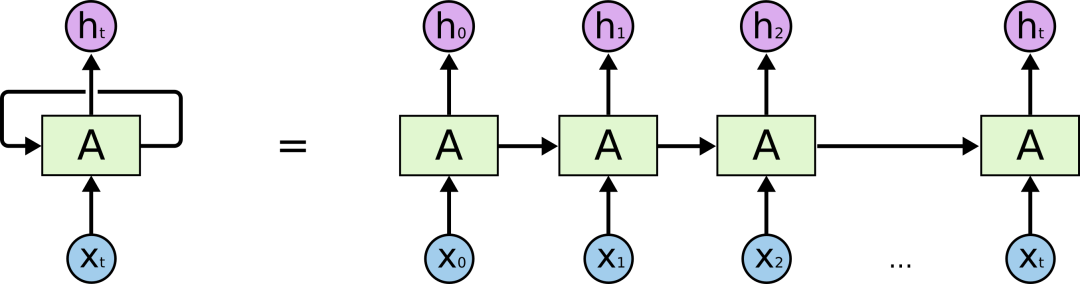
展開的RNN
這種鏈式性質揭示了RNN和序列、列表之間的密切關系。從某種程度上來說,它就是專為這類數據設計的神經網絡自然架構。
實踐也證實,RNN確實有用!過去幾年里,它在各類任務中取得了令人難以置信的成功:語音識別、語言建模、機器翻譯、圖像字幕……應用場景十分廣闊。幾年前,現任特斯拉AI總監Andrej Karpathy寫了一篇名為The Unreasonable Effectiveness of Recurrent Neural Networks的博客,專門介紹了RNN“不合理”的適用性,有興趣的讀者可以前去一讀。
在文章中我們可以發現,這種適用性的關鍵是“LSTM”的使用。這是一種非常特殊的RNN,所有能用RNN實現的東西,LSTM都能做,而且相較于普通版,它在許多任務中還會有更優秀的表現。所以下文我們就來看看什么是LSTM。
長期依賴問題
RNN最具吸引力的一點是它能把之前的信息連接到當前的任務上,比如我們可以用之前的視頻圖像理解這一幀的圖像。如果能建立起這種聯系,它的前途將不可限量。所以它真的能做到嗎?答案是:不一定。
有時候,我們只需要查看最近的信息就能執行當前任務,如構建一個能根據前一個詞預測下一個詞的語言模型。如果我們要預測“天空中漂浮著云朵,”這個句子的最后一個詞語,模型不需要任何進一步的語義背景——很明顯,最后一個詞是“云朵”。在這種情況下,如果相關信息和目標位置差距不大,RNN完全能學著去用以前的知識。
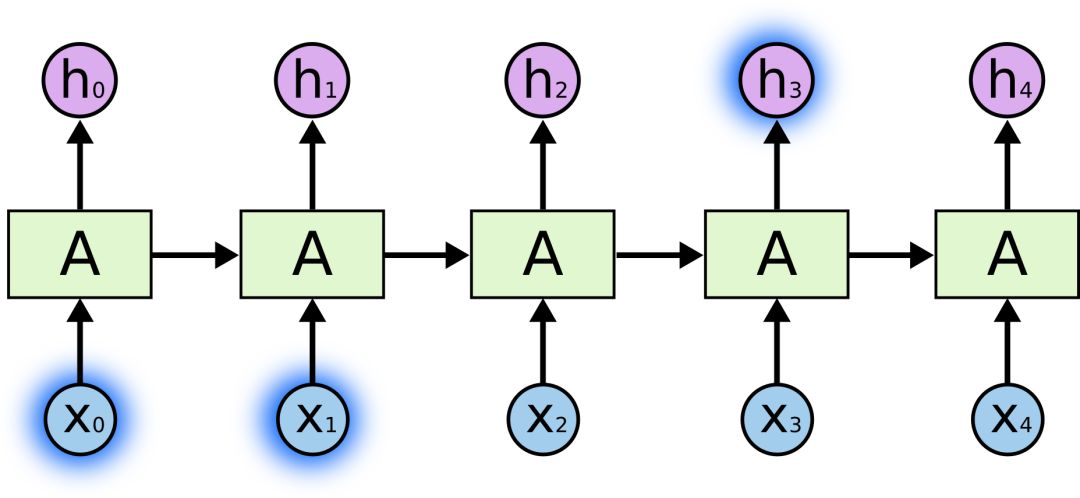
但有時我們也會希望模型能聯系下上文進行理解,比如預測“我在法國長大......我會說流利的法語。”這句話的最后一個詞。最近的信息提示是這個詞很可能是一種語言的名稱,如果要精確到是哪種語言,我們就需要結合句子開頭的“法國”來理解。這時兩個相關信息之間間隔的距離就非常遠。
不幸的是,隨著距離不斷拉大,RNN會逐漸難以學習其中的連接信息。
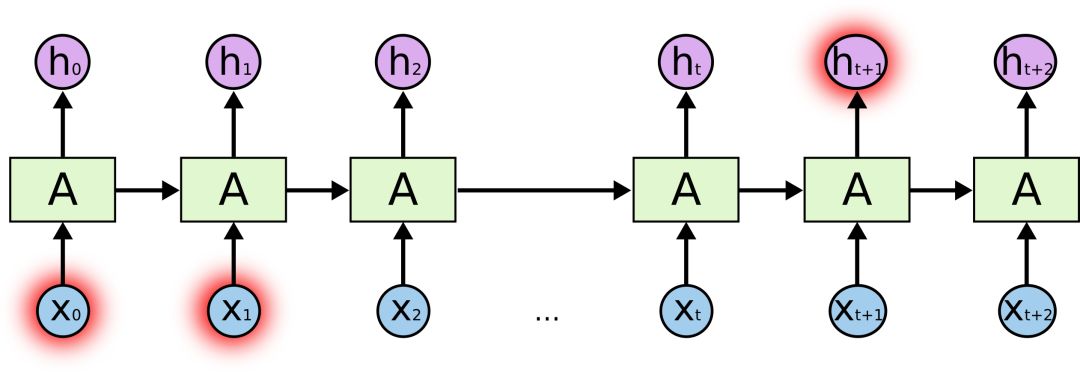
從理論上看,RNN絕對有能力去處理這種長期依賴性,我們可以不斷調參來解決各種玩具問題,但在實踐中,RNN卻徹頭徹尾地失敗了。關于這個問題,之前Hochreiter(1991)和Bengio等人(1994)已經做了深入探討,此處不再贅述。
謝天謝地,LSTM沒有這些問題。
LSTM網絡
長期短期記憶網絡——通常被稱為“LSTM”——是一種特殊的RNN,能學習長期依賴性。它最早由Hochreiter&Schmidhuber于1997年提出,后經眾多專家學者提煉和推廣,現在因性能出色已經被廣泛使用。
LSTM的設計目的非常明確:避免長期依賴性問題。對LSTM來說,長時間“記住”信息是一種默認的行為,而不是難以學習的東西。
之前我們提到了,RNN是一個包含大量重復神經網絡模塊的鏈式形式,在標準RNN里,這些重復的神經網絡結構往往也非常簡單,比如只包含單個tanh層:
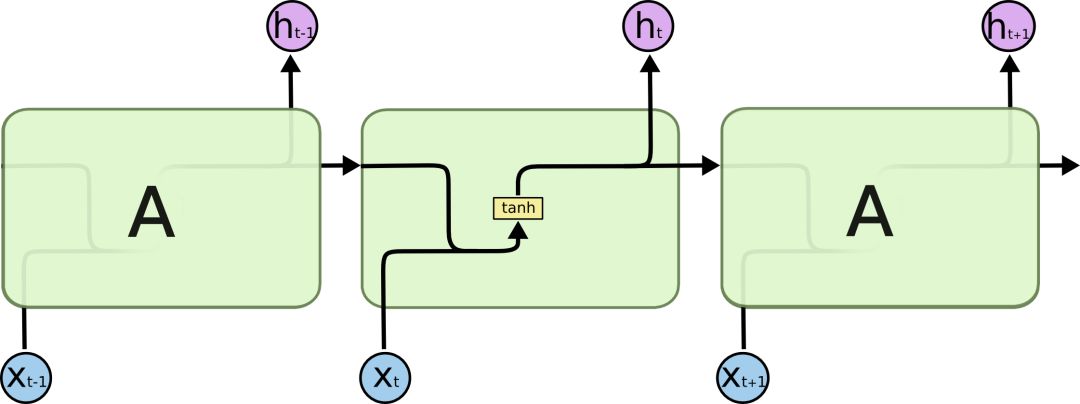
標準RNN中只包含單個tanh層的重復模塊
LSTM也有與之相似的鏈式結構,但不同的是它的重復模塊結構不同,是4個以特殊方式進行交互的神經網絡。
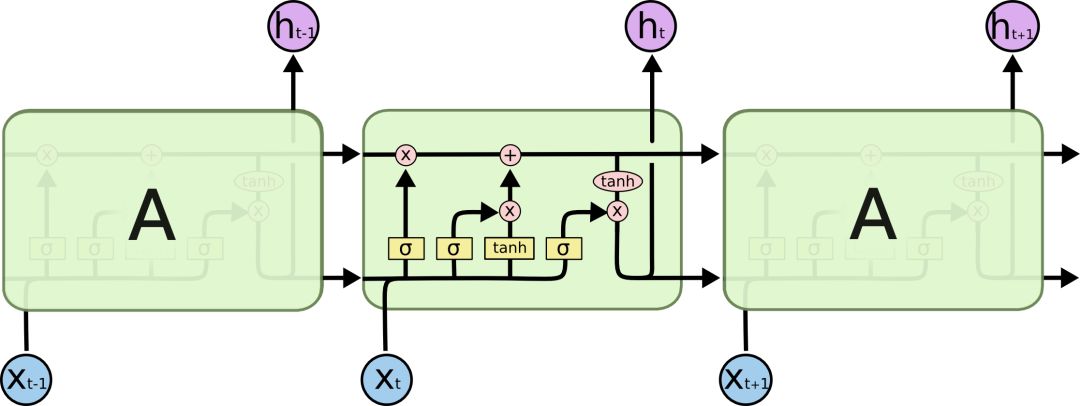
LSTM示意圖
這里我們先來看看圖中的這些符號:

在示意圖中,從某個節點的輸出到其他節點的輸入,每條線都傳遞一個完整的向量。粉色圓圈表示pointwise操作,如節點求和,而黃色框則表示用于學習的神經網絡層。合并的兩條線表示連接,分開的兩條線表示信息被復制成兩個副本,并將傳遞到不同的位置。
LSTMs背后的核心理念
LSTMs的關鍵是cell的狀態,即貫穿示意圖頂部的水平線。
cell狀態有點像傳送帶,它只用一些次要的線性交互就能貫穿整個鏈式結構,這其實也就是信息記憶的地方,因此信息能很容易地以不變的形式從中流過。
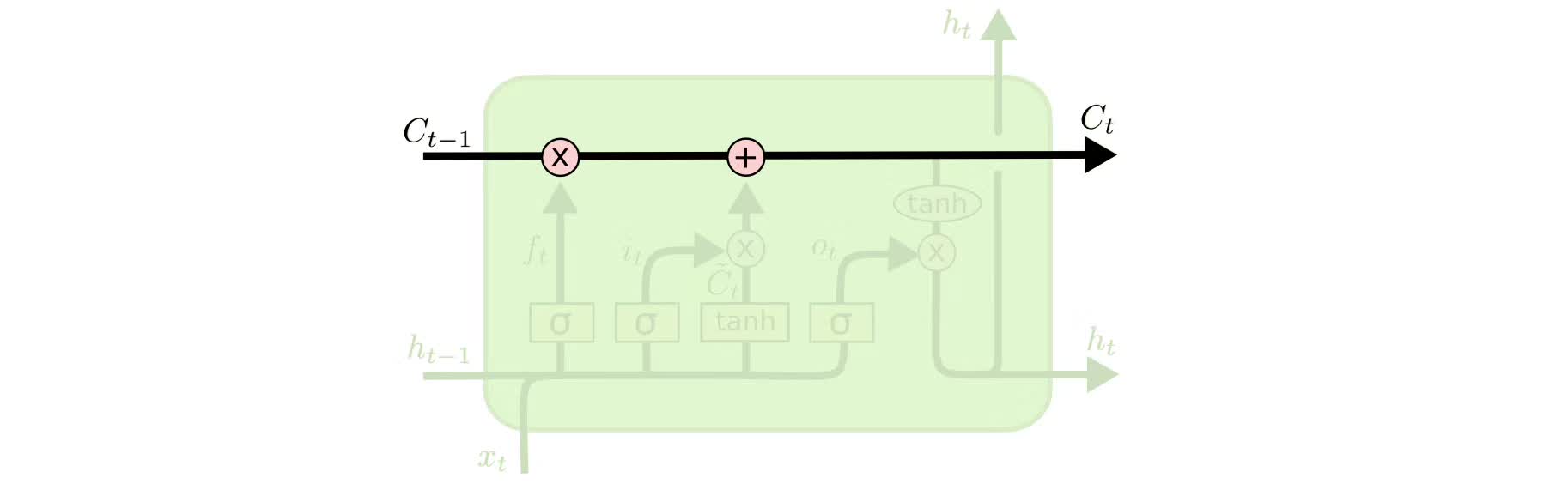
為了增加/刪除cell中的信息,LSTM中有一些控制門(gate)。它們決定了信息通過的方式,包含一個sigmoid神經網絡層和一個pointwise點乘操作。
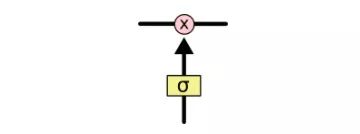
sigmoid層輸出0到1之間的數字,點乘操作決定多少信息可以傳送過去,當為0時,不傳送;當為1時,全部傳送。
像這樣的控制門,LSTM共有3個,以此保護和控制cell狀態。
深入了解LSTM
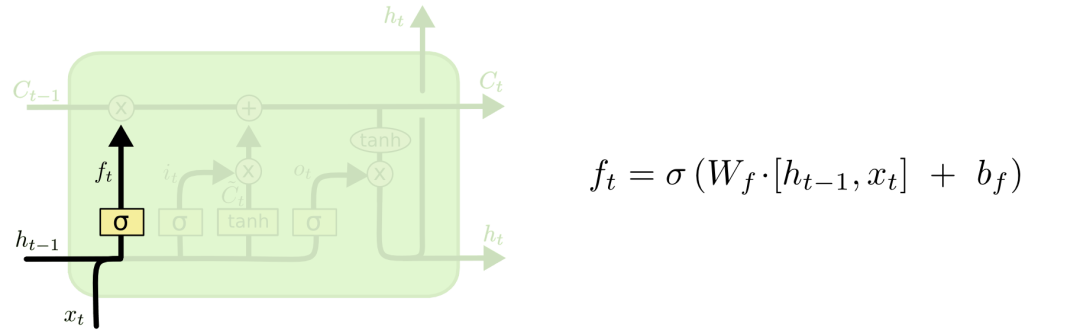
我們先來看看cell該刪除哪些信息,做這個決定的是包含sigmoid層的遺忘門。對于輸入xt和ht-1,遺忘門會輸出一個值域為[0, 1]的數字,放進細胞狀態Ct?1中。當為0時,全部刪除;當為1時,全部保留。
以之前預測下一個詞的語言模型為例,對于“天空中漂浮著云朵,”這個句子,LSTM的cell狀態會記住句子主語“云朵”的詞性,這之后才能判斷正確的代詞。等下次再遇到新主語時,cell會“忘記”“云朵”的詞性。
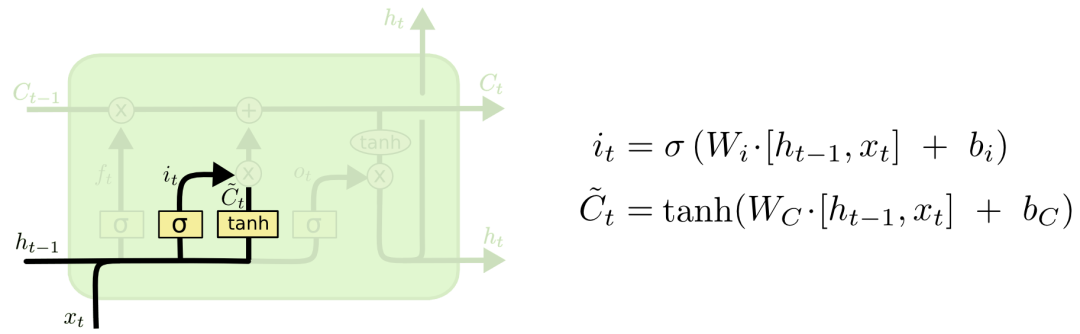
我們再來看看cell該如何增加新信息。這可以分為兩步,首先,LSTM會用一個包含sigmoid層的輸入門決定哪些信息該保留,其次,它會用一個tanh層為這些信息生成一個向量C~t,用來更新細胞狀態。
在語言模型例子中,如果句子變成了“天空中漂浮著云朵,草地上奔跑著駿馬”。那LSTM就會用“駿馬”的詞性代替正在被遺忘的“云朵”的詞性。
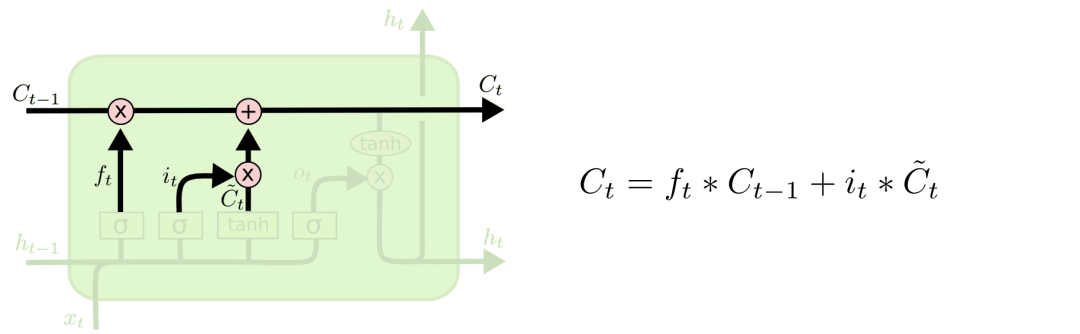
有了遺忘門和輸入門,現在我們就能把細胞狀態Ct?1更新為Ct了。如下圖所示,其中ft×Ct?1表示希望刪除的信息,it×Ct表示新增的信息。
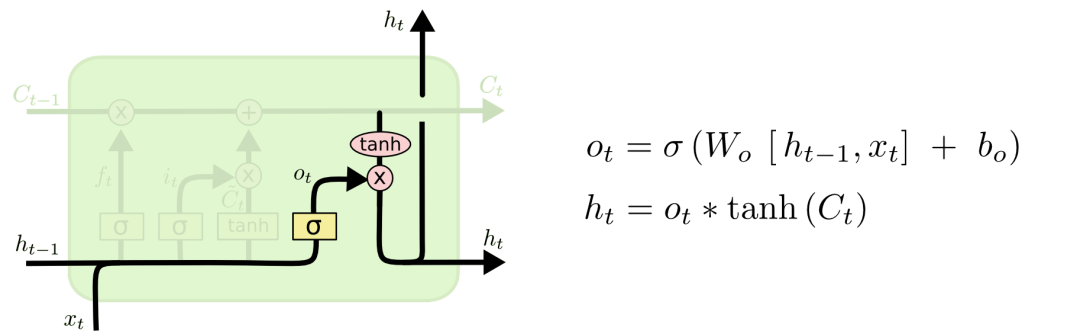
最后就是決定LSTM輸出內容的輸出門。它的信息基于cell狀態,但還要經過一定過濾。我們先用sigmoid層決定將要輸出的cell內容,再用tanh層把cell狀態值推到-1和1之間,并將其乘以sigmoid層的輸出,以此做到只輸出想要輸出的部分。
LSTM的變體
以上介紹的是一個非常常規的LSTM,但在實踐中我們也會遇到很多很不一樣的神經網絡,因為一旦涉及使用,人們就會不可避免地要用到一些DIY版本。雖然它們差異不大,但其中有一部分值得一提。
2000年的時候,Gers&Schmidhuber提出了一種添加了“peephole connections”的LSTM變體。它意味著我們能在相應控制門內觀察cell狀態。下圖為每個門都添加了窺視孔,我們也可以只加一處或兩處。
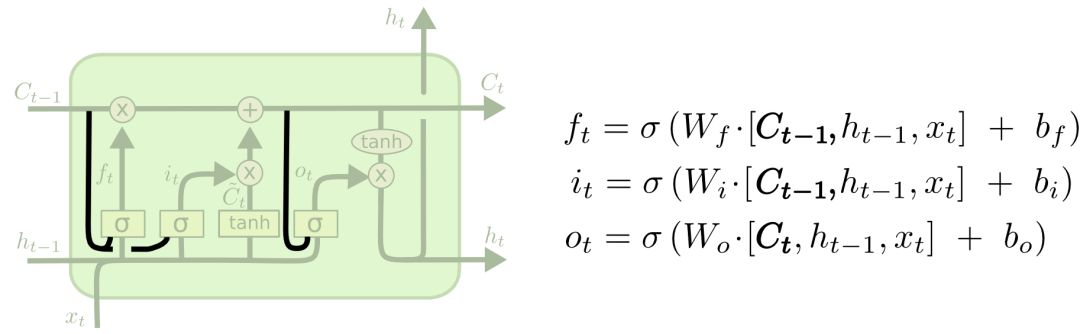
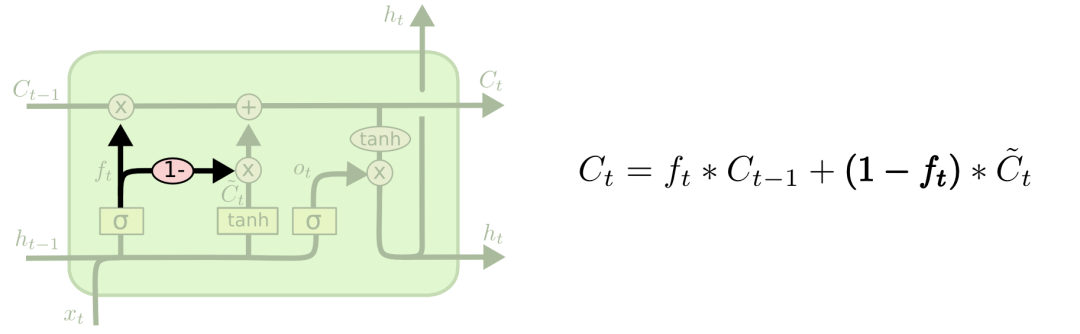
第二種變體是耦合遺忘門和輸入門,讓一個模塊同時決定該增加/刪除什么信息。
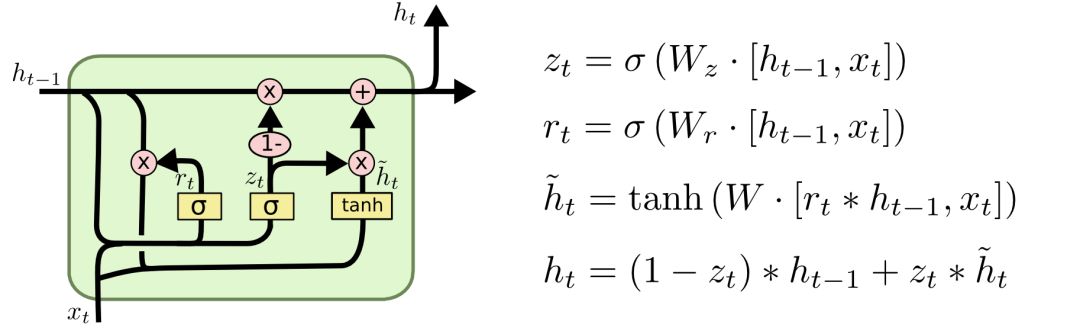
第三種稍具戲劇化的變體是Cho等人于2014年提出的帶有GRU的LSTM。它把遺忘門和輸入門組合成一個“更新門”,合并了cell狀態和隱藏狀態,并做了一些其他的修改。這個模型的優點是更簡單,也更受歡迎。
以上只是幾個最知名的LSTM變體,還有很多其他的,比如Yao等人的Depth Gated RNN。此外一些人也一直在嘗試用完全不同的方法來解決長期依賴問題,比如Koutnik等人的Clockwork RNN。
小結
如果只是列一大堆數學公式,LSTM看起來會非常嚇人。因此為了讓讀者更容易理解掌握,本文制作了大量可視化圖片,它們也一直深受業內人士認可,在各類文章中被廣泛引用。
LSTM是完善RNN的重要內容,雖然它到現在已經成果累累,但我們以此為起點,探索RNN身上的其他研究方向,如近兩年非常紅火的注意力機制(Attention Mechanism)、在GAN中使用RNN等。過去幾年對神經網絡來說是激動人心的一段時光,相信未來會更加如此!
-
神經網絡
+關注
關注
42文章
4764瀏覽量
100542 -
rnn
+關注
關注
0文章
88瀏覽量
6875
原文標題:一文詳解LSTM網絡
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
SLC、MLC、Parallel NOR Flash等究竟是什么意思?

計算機究竟是如何理解并執行我們所寫的代碼的呢?





 工商網監
工商網監
評論