") 未來(lái)的圖像識(shí)別:更大規(guī)模、自我標(biāo)注
未來(lái)的圖像識(shí)別:更大規(guī)模、自我標(biāo)注
2017 年 7 月,最后一屆 ImageNet 挑戰(zhàn)賽落幕。
為何對(duì)計(jì)算機(jī)視覺(jué)領(lǐng)域有著重要貢獻(xiàn)的 ImageNet 挑戰(zhàn)賽,會(huì)在 8 年后宣告終結(jié)?
畢竟計(jì)算機(jī)系統(tǒng)在圖像識(shí)別等任務(wù)上的準(zhǔn)確率已經(jīng)超過(guò)人類水平,每年一次突破性進(jìn)展的時(shí)代也已經(jīng)過(guò)去。
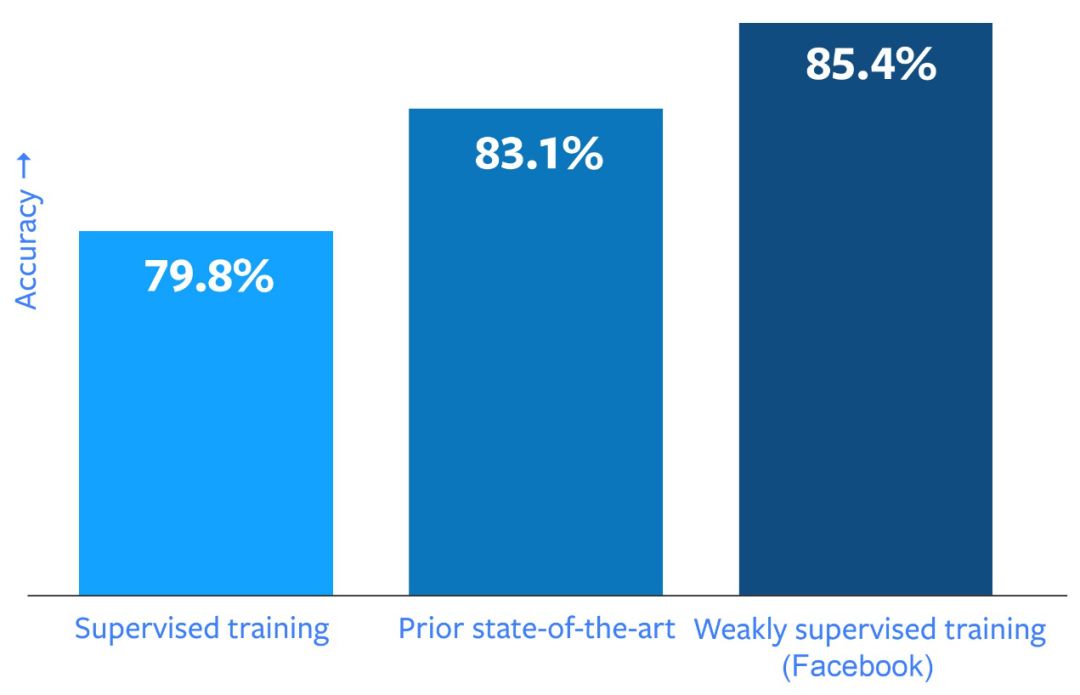
近日,F(xiàn)AIR(Facebook AI Research) 的 Ross Girshick 、何愷明等大神聯(lián)手,在 ImageNet-1k 圖像分類數(shù)據(jù)集上取得了 85.4% 的準(zhǔn)確率,超越了目前的最好成績(jī),而且沒(méi)有使用專門為訓(xùn)練深度學(xué)習(xí)標(biāo)記的圖像作為訓(xùn)練數(shù)據(jù)。

然而,這不能怪大家不努力,只怪 Facebook 實(shí)在太土豪。10 億張帶有 hashtag(類似于微博里面的話題標(biāo)簽)的圖片,以及 336 塊 GPU,敢問(wèn)誰(shuí)能有這種壕氣?
Facebook 表示,實(shí)驗(yàn)的成功證明了弱監(jiān)督學(xué)習(xí)也能有良好表現(xiàn),當(dāng)然,只要數(shù)據(jù)足夠多。
話不多說(shuō),我們一起來(lái)看看 Facebook 是怎樣用數(shù)據(jù)和金錢砸出這個(gè)成果的。
以下內(nèi)容來(lái)自 Facebook 官方博客,人工智能頭條 編譯:
圖像識(shí)別是人工智能研究的重要領(lǐng)域之一,同時(shí)也是 Facebook 的一大重點(diǎn)關(guān)注領(lǐng)域。我們的研究人員和工程師希望盡最大的努力打破計(jì)算機(jī)視覺(jué)系統(tǒng)的邊界,然后將我們的研究成功應(yīng)用到現(xiàn)實(shí)世界的問(wèn)題中。為了改進(jìn)計(jì)算機(jī)視覺(jué)系統(tǒng)的性能,使其能夠高效地識(shí)別和分類各種物體,我們需要擁有至少數(shù)十億張圖像的數(shù)據(jù)集來(lái)作為基礎(chǔ),而不僅僅是百萬(wàn)量級(jí)。
目前比較主流的模型通常是利用人工注釋的單獨(dú)標(biāo)記的數(shù)據(jù)進(jìn)行訓(xùn)練,然而在這種情況下,增強(qiáng)系統(tǒng)的識(shí)別能力并不是往里面“扔”更多的圖片那樣簡(jiǎn)單。監(jiān)督學(xué)習(xí)是勞動(dòng)密集型的,但是它通常能夠達(dá)到最佳的效果,然而手動(dòng)標(biāo)記數(shù)據(jù)集的大小已經(jīng)接近極限。盡管 Facebook 正在利用 5000 萬(wàn)幅圖像對(duì)一些模型進(jìn)行訓(xùn)練,然而在數(shù)據(jù)全部需要人工標(biāo)記的前提下,將訓(xùn)練集擴(kuò)大到數(shù)十億張是不可能實(shí)現(xiàn)。
我們的研究人員和工程師想出了一個(gè)解決辦法:利用大量帶有“hashtag”的公共圖像集來(lái)訓(xùn)練圖像識(shí)別網(wǎng)絡(luò),其中最大的數(shù)據(jù)集包括 35 億張圖像以及 17000 種 hashtag。這種方法的關(guān)鍵是使用現(xiàn)有的、公開的、用戶提供的 hashtag 作為標(biāo)簽,而不是手動(dòng)對(duì)每張圖片進(jìn)行分類。
這種方法在我們的測(cè)試中運(yùn)行十分良好。我們利用具有數(shù)十億張圖像的數(shù)據(jù)集來(lái)訓(xùn)練我們的計(jì)算機(jī)視覺(jué)系統(tǒng),然后在 ImageNet 上獲得了創(chuàng)紀(jì)錄的高分(準(zhǔn)確率達(dá)到了 85.4%)。除了在圖像識(shí)別性能方面實(shí)現(xiàn)突破之外,本研究還為如何從監(jiān)督學(xué)習(xí)轉(zhuǎn)向弱監(jiān)督學(xué)習(xí)轉(zhuǎn)變提供了深刻的洞見:通過(guò)使用現(xiàn)有標(biāo)簽——在本文這種情況下指的是 hashtag——而不是專門的標(biāo)簽來(lái)訓(xùn)練 AI 模型。我們計(jì)劃在不久的將來(lái)會(huì)進(jìn)行開源,讓整個(gè) AI 社區(qū)受益。
▌大規(guī)模使用 hashtag
由于人們經(jīng)常用 hashtag 來(lái)對(duì)照片進(jìn)行標(biāo)注,因此我們認(rèn)為這些圖片是模型訓(xùn)練數(shù)據(jù)的理想來(lái)源。人們?cè)谑褂?hashtag 的主要目的是讓其他人發(fā)現(xiàn)相關(guān)內(nèi)容,讓自己的圖片更容易被找到,這種意圖正好可以為我們所用。
但是 hashtag 經(jīng)常涉及非可視化的概念,例如 “#tbt” 代表“throwback Thursday”;有些時(shí)候,它們的語(yǔ)義也含糊不清,比如 “#party”,它既可以描述一個(gè)活動(dòng),也可以描述一個(gè)背景,或者兩者皆可。為了更好地識(shí)別圖像,這些標(biāo)簽可以作為弱監(jiān)督數(shù)據(jù),而模糊的或者不相關(guān)的 hashtag 則是不相干的標(biāo)簽噪聲,可能會(huì)混淆深度學(xué)習(xí)模型。
由于這些充滿噪聲的標(biāo)簽對(duì)我們的大規(guī)模訓(xùn)練工作至關(guān)重要,我們開發(fā)了新的方法:把 hashtag 當(dāng)作標(biāo)簽來(lái)進(jìn)行圖像識(shí)別實(shí)驗(yàn),其中包括處理每張圖像的多個(gè)標(biāo)簽(因?yàn)橛脩敉粫?huì)只添加一個(gè) hashtag),對(duì) hashtag 同義詞進(jìn)行排序,以及平衡常見的 hashtag 和少見的 hashtag 的影響。
為了使標(biāo)簽對(duì)圖像識(shí)別訓(xùn)練更加有用,我們團(tuán)隊(duì)訓(xùn)練了一個(gè)大型的 hashtag 預(yù)測(cè)模型。這種方法顯示了出色的遷移學(xué)習(xí)結(jié)果,這意味著該模型在圖像分類上的表現(xiàn)可以廣泛適用于其他人工智能系統(tǒng)。
▌在規(guī)模和性能上實(shí)現(xiàn)突破
如果只是用一臺(tái)機(jī)器的話,將需要一年多的時(shí)間才能完成模型訓(xùn)練,因此我們?cè)O(shè)計(jì)了一種可以將該任務(wù)分配給 336 個(gè) GPU 的方法,從而將總訓(xùn)練時(shí)間縮短至數(shù)周。隨著模型規(guī)模越來(lái)越大——這項(xiàng)研究中最大的是 ResNeXt 101-32x48d,其參數(shù)超過(guò)了 8.61 億個(gè)——這種分布式訓(xùn)練變得越來(lái)越重要。此外,我們還設(shè)計(jì)了一種刪除重復(fù)值(副本)的方法,以確保訓(xùn)練集和測(cè)試集之間沒(méi)有重疊。
盡管我們希望看到圖像識(shí)別的性能得到一定提升,但試驗(yàn)結(jié)果遠(yuǎn)超我們的預(yù)期。在 ImageNet 圖像識(shí)別基準(zhǔn)測(cè)試中(該領(lǐng)域最常見的基準(zhǔn)測(cè)試),我們的最佳模型通過(guò) 10 億張圖像的訓(xùn)練之后(其中包含 1,500 個(gè) hashtag)達(dá)到了 85.4% 的準(zhǔn)確率,這是迄今為止 ImageNet 基準(zhǔn)測(cè)試中的最好成績(jī),比之前最先進(jìn)的模型的準(zhǔn)確度高了 2%。再考慮到卷積網(wǎng)絡(luò)架構(gòu)的影響后,我們所觀察到的性能提升效果更為顯著:在深度學(xué)習(xí)粒使用數(shù)十億張帶有 hashtag 的圖像之后,其準(zhǔn)確度相對(duì)提高了 22.5%。
在 COCO 目標(biāo)檢測(cè)挑戰(zhàn)中,我們發(fā)現(xiàn)使用 hashtag 預(yù)訓(xùn)練可以將模型的平均精度(average precision)提高 2% 以上。
這些圖像識(shí)別和物體檢測(cè)領(lǐng)域的基礎(chǔ)改進(jìn),代表了計(jì)算機(jī)視覺(jué)又向前邁出了一步。但是除此之外,該實(shí)驗(yàn)也揭示了與大規(guī)模訓(xùn)練和噪聲標(biāo)簽相關(guān)的挑戰(zhàn)和機(jī)遇。
例如,盡管增加訓(xùn)練數(shù)據(jù)集規(guī)模的大小是值得的,但選擇與特定識(shí)別任務(wù)相匹配的一組 hashtag 也同樣重要。我們選擇了 10 億張圖像以及 1,500 個(gè)與 ImageNet 數(shù)據(jù)集中的類相匹配的 hashtag,相比同樣的圖像加上 17,000 個(gè) hashtag,前者訓(xùn)練出來(lái)的模型取得了更好的成績(jī)。另一方面,對(duì)于圖像類別更多更廣泛的任務(wù),使用 17,000 個(gè)主 hashtag 訓(xùn)練出來(lái)模型性能改進(jìn)的更加明顯,這表明我們應(yīng)該在未來(lái)的訓(xùn)練中增加 hashtag 的數(shù)量。
增加訓(xùn)練數(shù)據(jù)量通常對(duì)圖像分類模型的表現(xiàn)是有益,但它同樣也有可能會(huì)引發(fā)新的問(wèn)題,如在圖像內(nèi)定位物體的能力明顯下降。除此之外我們還觀察到,實(shí)驗(yàn)中最大的模型仍然沒(méi)有能夠充分利用 35 億張巨大圖像集的優(yōu)勢(shì),這表明我們應(yīng)該構(gòu)建更大的模型。
▌未來(lái)的圖像識(shí)別:更大規(guī)模、自我標(biāo)注
本次研究的一個(gè)重要結(jié)果,甚至比在圖像識(shí)別方面的廣泛收益還要重要,是確認(rèn)了基于 hashtag 來(lái)訓(xùn)練計(jì)算機(jī)視覺(jué)模型是完全可行的。雖然我們使用了一些類似融合相似的 hashtag,降低其他 hashtag 權(quán)重的基本技術(shù),但并不需要復(fù)雜的“清洗”程序來(lái)消除標(biāo)簽噪聲。相反,我們能夠使用 hashtag 來(lái)訓(xùn)練我們的模型,而且只需要對(duì)訓(xùn)練過(guò)程進(jìn)行微小的調(diào)整。當(dāng)訓(xùn)練集的規(guī)模達(dá)到十億級(jí)時(shí),我們的模型對(duì)標(biāo)簽噪音表現(xiàn)出了顯著的抗干擾能力,因此數(shù)據(jù)集的規(guī)模在這里顯然是一個(gè)優(yōu)勢(shì)。
在不久的將來(lái),我們還會(huì)設(shè)想使用 hashtag 作為計(jì)算機(jī)視覺(jué)標(biāo)簽的其他方法。這些方法可能包括使用人工智能來(lái)更好地理解視頻片段或更改圖片在 Facebook 信息流中的排名方式。hashtag 還可以幫助系統(tǒng)更具體地識(shí)別圖像是不是屬于更細(xì)致的子類別,而不僅僅是寬泛的分類。一般情況下,圖片的音頻字幕都是僅寬泛地注釋出物種名稱,如“圖片中有一些鳥類棲息”,但如果我們能夠讓注釋更加精確(例如“一只紅雀棲息在糖楓樹上”),就可以為視障用戶提供更加準(zhǔn)確的描述。

此外,這項(xiàng)研究還可以改進(jìn)新產(chǎn)品以及現(xiàn)有產(chǎn)品中的圖像識(shí)別功能帶來(lái)。例如,更準(zhǔn)確的模型可能會(huì)促進(jìn)我們改進(jìn)在 Facebook 上呈現(xiàn) Memories(與QQ的“日跡”相似)的方式。隨著訓(xùn)練數(shù)據(jù)集越來(lái)越大,我們需要應(yīng)用弱監(jiān)督學(xué)習(xí)——而且從長(zhǎng)遠(yuǎn)來(lái)看,無(wú)監(jiān)督學(xué)習(xí)會(huì)變得越來(lái)越重要。
這項(xiàng)研究在論文“Exploring the Limits of Weakly Supervised Pretraining”中有更詳細(xì)的描述。
-
圖像識(shí)別
+關(guān)注
關(guān)注
9文章
519瀏覽量
38242 -
人工智能
+關(guān)注
關(guān)注
1791文章
46896瀏覽量
237671 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5493瀏覽量
121000
原文標(biāo)題:何愷明等在圖像識(shí)別任務(wù)上取得重大進(jìn)展,這次用的是弱監(jiān)督學(xué)習(xí)
文章出處:【微信號(hào):AI_Thinker,微信公眾號(hào):人工智能頭條】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于DSP的快速紙幣圖像識(shí)別技術(shù)研究
圖像識(shí)別模組(包括PCB圖、圖像識(shí)別模組源代碼)
利用Jetson TK1為低功耗圖像識(shí)別挑戰(zhàn)做好準(zhǔn)備
圖像識(shí)別技術(shù) 推動(dòng)智能科技時(shí)代發(fā)展
Food2K:大規(guī)模食品圖像識(shí)別

圖像識(shí)別技術(shù)原理 深度學(xué)習(xí)的圖像識(shí)別應(yīng)用研究
模擬矩陣在圖像識(shí)別中的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論