 一種結合二者的新方法,展示如何查找已發布軟件中的bug
一種結合二者的新方法,展示如何查找已發布軟件中的bug
程序分析通常有兩種方法,分別基于數理邏輯和自然語言理解。通過將程序表示成圖結構,來自微軟研究院和西門菲莎大學的研究者展示了一種結合二者的新方法,可以直接從源代碼中學習,且更準確地查找已發布軟件中的 bug。
過去五年,基于深度學習的方法給大量應用帶來了變革,如需要理解圖像、話語和自然語言的應用。對于計算機科學家而言,一個自然出現的問題是:計算機是否能夠學會理解源代碼。乍一看這個問題似乎很簡單,因為編程語言的設計初衷就是被計算機理解。但是,很多軟件 bug 的出現是因為我想讓軟件這么做,但是寫出來卻是另外一回事。也就是說,小的拼寫錯誤可能導致嚴重后果。
看一下以下這個簡單示例:
float getHeight { return this.width; }.
該示例中,人類或者理解「height」和「width」意思的系統可以很快發現問題所在。源代碼具備兩種功能。首先,它與計算機進行準確交流,以執行硬件指令。其次,它與其他程序員(或源代碼作者)針對程序的運行情況進行交流。后者通過選擇代號、代碼布局和代碼注釋來實現。在發現兩種交流渠道似乎可以分離后,一個自動發現軟件 bug 的系統出現了。
之前的程序分析主要關注程序的正式、機器可理解語義或將程序看作(有點奇怪的)自然語言。前者的方法來自于數理邏輯,要求對每個需要處理的新案例進行大量的工程工作。而自然語言方法需要在純句法任務上性能優越但尚無法學習程序語義的自然語言處理工具。
在 ICLR 2018 的一篇論文《Learning to Represent Programs with Graphs》中,來自微軟研究院和西門菲莎大學的研究者展示了一種結合二者的新方法,并展示了如何查找已發布軟件中的 bug。
程序圖
為了學習源代碼中的大量結構,研究者首先把源代碼轉換成程序圖(program graph)。圖中的節點包括程序的 token(即變量、運算子、方法名等)及其抽象句法樹的節點(定義語言句法的語法元素,如 IfStatement)。程序圖包含兩種不同類型的邊:句法邊,表示代碼解析方式,如 while loop 和 if block;語義邊,即簡單程序分析的結果。
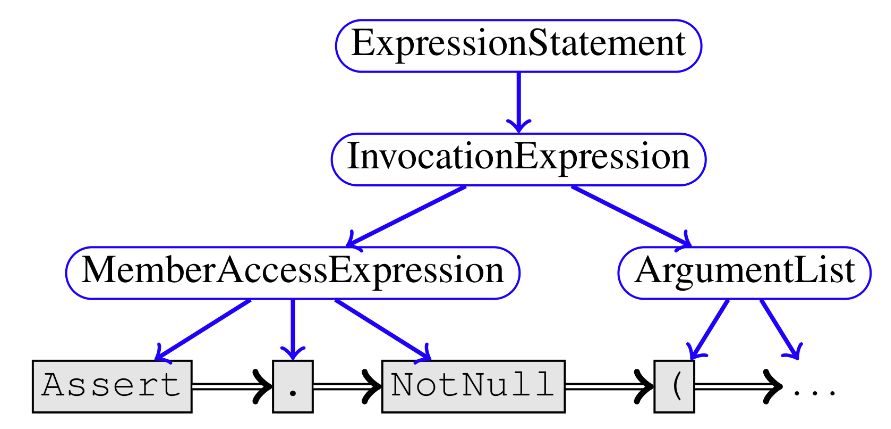
圖 1:句法邊
句法邊包括簡單的「NextToken」邊、用于表示抽象句法樹的「Child」邊,以及連接一個 token 和源代碼中它最后一次出現的「LastLexicalUse」邊。圖 1 展示了此類邊用于 statement Assert.NotNull(clazz) 的部分示例,其中對應 token 的節點是灰色框,對應程序語法的非終端的節點是藍色橢圓形框。Child 邊是藍色的實線邊,而 NextToken 邊是黑色的雙線邊。
語義邊包括連接一個變量和它在程序執行中最后一次使用的「LastUse」邊(如果是循環案例,則變量在程序執行中最后一次使用的情況出現得更晚一些)、連接一個變量和它最后一次寫入的「LastWrite」邊,以及連接一個變量和它據此計算的值的「ComputedFrom」邊。也可能有更多語義邊,利用程序分析工具箱的其他工具,如 aliasing、points-to 分析,以及程序條件。圖 2 是在一個小代碼段(黑色)上形成的一些語義邊。
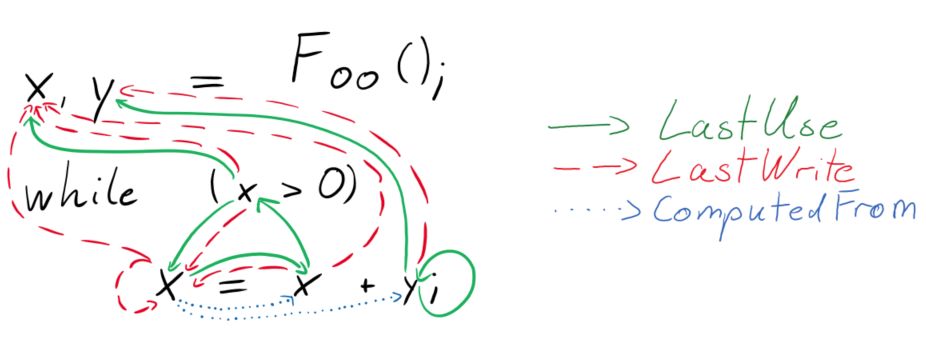
圖 2:語義邊
LastUse 關系用綠色邊表示,y 與循環前 y 最后一次使用的情況連接。類似地,LastWrite 關系用紅色邊表示,while 條件中的 x 的使用與循環前 x 的分配和循環中 x 的分配連接起來。最后,ComputedFrom 關系用藍色邊表示,變量與其據此計算的變量連接起來。
句法邊大概對應程序員在閱讀源代碼時所看到的。語義邊對應程序如何執行。通過在一個圖中結合二者,該系統可以比單一方法學習到更多的信息。
從圖中學習
由于圖通常作為表征數據和數據關系的標準方式,從圖結構數據中學習的方法近期受到了一定程度的關注。一個組織可以用圖的形式展現出來,正如藥物分子可以看成是原子構成的圖。近期成功的應用深度學習的圖方法是圖卷積網絡(卷積神經網絡的一種擴展)和門控圖神經網絡(循環神經網絡的一種擴展)。
這兩種方法都是首先獨立地處理每個節點,以獲取節點本身的內部表征(即低維空間中的一個向量),然后將互相連接的節點的表征進行重復連接(兩種方法的組合方式不同)。因此,經過一個步驟之后,每個節點擁有自身的信息和它的直接近鄰節點的信息;經過兩個步驟之后,每個節點將獲得距離兩個節點的信息,以此類推。由于所有的步驟都使用(小型)神經網絡,因此這些方法可以被訓練用于從數據中提取整個任務相關的信息。
搜索 bug
在程序圖上學習可以用于搜索 bug,例如本文開頭描述的那個例子。給定一個程序、程序中的某個位置以及在該位置上可以使用的一系列變量。然后模型被詢問應該使用哪些變量。為了執行這項任務,程序被變換為程序圖,某個特定節點對應所考慮的位置。通過考慮該特定節點的計算表征,以及對應可用變量的節點表征,網絡可以計算每個變量的可能性。這樣的模型可以很容易地通過幾百萬行已有代碼來訓練,并且不需要專門標注的數據集。
當模型在新代碼上運行,并以很高的概率預測出 var1,然而程序員選擇的是 var2,這可能就是一個 bug。通過標記這些問題讓人類專家審核,可以發現真正的 bug。例如,以下來自 Roslyn(微軟 C# 編譯器)的例子:
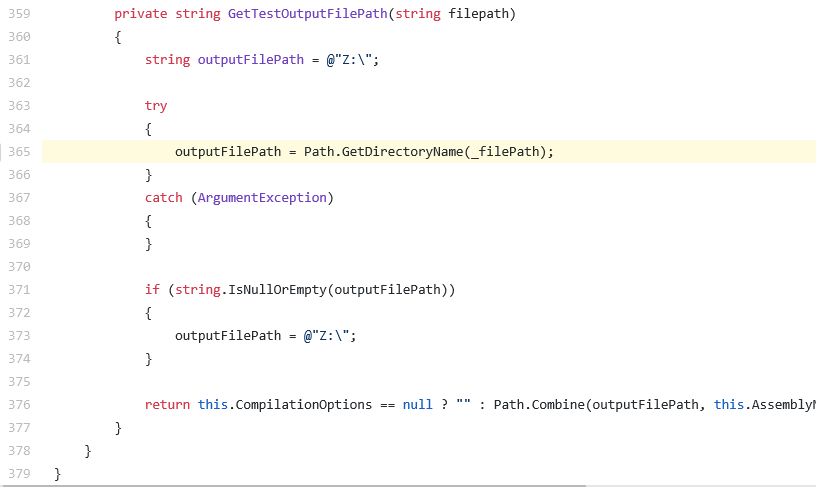
注意參數 filepath 和字段_filePath 的使用,二者很容易被混淆。然而,_filePath 只是一個打字錯誤,開發者在研究員報告這個問題和類似問題之后將其修改了。相似的 bug 在很多其它 C# 項目中也被找到、報告和修改。
在一個更大規模的定量評估中,新方法遠遠超越了傳統的機器學習技術。作為基線方法,雙向循環神經網絡(BiRNN)直接在源代碼上執行,BiRNN 的簡單擴展可以訪問數據流的某些信息。為了評估不同的模型,微軟分析了包含 290 萬行源代碼的開源 C# 項目。在測試時,源代碼的某個變量被遮蓋,然后讓模型找出原始使用的變量(假定源代碼是準確并經過良好測試的)。在第一個實驗中,模型在項目的留出文件上進行測試(其他文件用于訓練)。在第二個實驗中,模型在全新項目的數據上測試。結果如下表所示,在新的程序圖上學習的模型得到了明顯更好的結果。
未來應用
程序圖對于在程序上應用深度學習方法是很通用的工具,微軟將繼續朝這個方向探索。
-
微軟
+關注
關注
4文章
6567瀏覽量
103958 -
源代碼
+關注
關注
96文章
2944瀏覽量
66670 -
自然語言
+關注
關注
1文章
287瀏覽量
13332
原文標題:微軟提出基于程序圖簡化程序分析,直接從源代碼中學習
文章出處:【微信號:gh_ecbcc3b6eabf,微信公眾號:人工智能和機器人研究院】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種求解非線性約束優化全局最優的新方法
未知雷達輻射源分選的一種新方法
Abacus展示了一種用于深度學習的新方法的技術
一種復制和粘貼URL的新方法
分享一種利用膠體量子點(QD)獲得中紅外發射的新方法

一種產生激光脈沖新方法
一種無透鏡成像的新方法






 工商網監
工商網監
評論