 PRAM模型、BSP模型、LogP模型優缺點分析
PRAM模型、BSP模型、LogP模型優缺點分析
并行計算模型通常指從并行算法的設計和分析出發,將各種并行計算機(至少某一類并行計算機)的基本特征抽象出來,形成一個抽象的計算模型。
PRAM模型
PRAM(Parallel Random Access Machine,隨機存取并行機器)模型,也稱為共享存儲的SIMD模型,是一種抽象的并行計算模型,它是從串行的RAM模型直接發展起來的。在這種模型中,假定存在一個容量無限大的共享存儲器,有有限個或無限個功能相同的處理器,且他們都具有簡單的算術運算和邏輯判斷功能,在任何時刻各處理器都可以通過共享存儲單元相互交互數據。根據處理器對共享存儲單元同時讀、同時寫的限制,PRAM模型可以分為下面幾種:
不允許同時讀和同時寫(Exclusive-Read and Exclusive-Write)的PRAM模型,簡稱為PRAM-EREW;
允許同時讀但不允許同時寫(Concurrent-Read and Exclusive-Write)的PRAM模型,簡稱為PRAM-CREW;
允許同時讀和同時寫(Concurrent-Read and Concurrent-Write)的PRAM模型,簡稱為PRAM-CRCW。
顯然,允許同時寫是不現實的,于是又對PRAM-CRCW模型做了進一步約定,于是形成了下面幾種模型:
只允許所有的處理器同時寫相同的數,此時稱為公共(common)的PRAM-CRCW,簡稱為CPRAM-CRCW;
只允許最優先的處理器先寫,此時稱為優先(Priority)的PRAM-CRCW,簡稱為PPRAM-CRCW;
允許任意處理器自由寫,此時稱為任意(Arbitrary)的PRAM-CRCW,簡稱為APRAM-CRCW。
往存儲器中寫的實際內容是所有處理器寫的數的和,此時稱為求和(Sum)的PRAM-CRCE,將稱為SPRAM-CRCW。
PRAM模型的優點
PRAM模型特別適合于并行算法的表達、分析和比較,使用簡單,很多關于并行計算機的底層細節,比如處理器間通信、存儲系統管理和進程同步都被隱含在模型中;易于設計算法和稍加修改便可以運行在不同的并行計算機系統上;根據需要,可以在PRAM模型中加入一些諸如同步和通信等需要考慮的內容。
PRAM模型的缺點
(1)模型中使用了一個全局共享存儲器,且局存容量較小,不足以描述分布主存多處理機的性能瓶頸,而且共享單一存儲器的假定,顯然不適合于分布存儲結構的MIMD機器;
(2)PRAM模型是同步的,這就意味著所有的指令都按照鎖步的方式操作,用戶雖然感覺不到同步的存在,但同步的存在的確很耗費時間,而且不能反映現實中很多系統的異步性;
(3)PRAM模型假設了每個處理器可在單位時間訪問共享存儲器的任一單元,因此要求處理機間通信無延遲、無限帶寬和無開銷,假定每個處理器均可以在單位時間內訪問任何存儲單元而略去了實際存在的,合理的細節,比如資源競爭和有限帶寬,這是不現實的;
(4) PRAM模型假設處理機有限或無限,對并行任務的增大無開銷;
(5)未能描述所線程技術和流水線預取技術,而這兩種技術又是當今并行體系結構用的最普遍的技術。
BSP模型
BSP模型基本原理
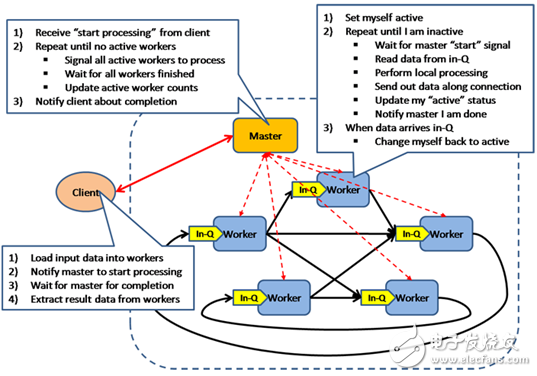
BSP模型是一種異步MIMD-DM模型(DM: distributed memory,SM: shared memory),BSP模型支持消息傳遞系統,塊內異步并行,塊間顯式同步,該模型基于一個master協調,所有的worker同步(lock-step)執行, 數據從輸入的隊列中讀取,該模型的架構如圖所示:
另外,BSP并行計算模型可以用 p/s/g/I 4個參數進行描述:
P為處理器的數目(帶有存儲器)。
s為處理器的計算速度。
g為每秒本地計算操作的數目/通信網絡每秒傳送的字節數,稱之為選路器吞吐率,視為帶寬因子 (time steps/packet)=1/bandwidth。
i為全局的同步時間開銷,稱之為全局同步之間的時間間隔 (Barrier synchronization time)。
那么假設有p臺處理器同時傳送h個字節信息,則gh就是通信的開銷。同步和通信的開銷都規格化為處理器的指定條數。
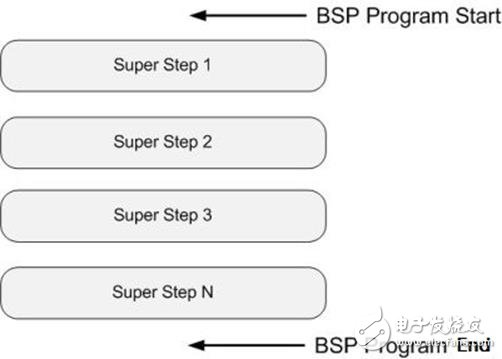
BSP計算模型不僅是一種體系結構模型,也是設計并行程序的一種方法。BSP程序設計準則是整體同步(bulk synchrony),其獨特之處在于超步(superstep)概念的引入。一個BSP程序同時具有水平和垂直兩個方面的結構。從垂直上看,一個BSP程序由一系列串行的超步(superstep)組成,如圖所示:
這種結構類似于一個串行程序結構。從水平上看,在一個超步中,所有的進程并行執行局部計算。一個超步可分為三個階段,如圖所示:
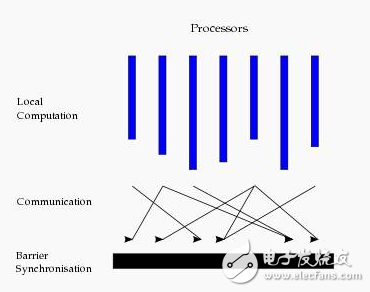
本地計算階段,每個處理器只對存儲本地內存中的數據進行本地計算。
全局通信階段,對任何非本地數據進行操作。
柵欄同步階段,等待所有通信行為的結束。
BSP模型特點
1. BSP模型將計算劃分為一個一個的超步(superstep),有效避免死鎖。
2. 它將處理器和路由器分開,強調了計算任務和通信任務的分開,而路由器僅僅完成點到點的消息傳遞,不提供組合、復制和廣播等功能,這樣做既掩蓋具體的互連網絡拓撲,又簡化了通信協議;
3. 采用障礙同步的方式以硬件實現的全局同步是在可控的粗粒度級,從而提供了執行緊耦合同步式并行算法的有效方式,而程序員并無過分的負擔;
4. 在分析BSP模型的性能時,假定局部操作可以在一個時間步內完成,而在每一個超級步中,一個處理器至多發送或接收h條消息(稱為h-relation)。假定s是傳輸建立時間,所以傳送h條消息的時間為gh+s,如果 ,則L至少應該大于等于gh。很清楚,硬件可以將L設置盡量小(例如使用流水線或大的通信帶寬使g盡量小),而軟件可以設置L的上限(因為L越大,并行粒度越大)。在實際使用中,g可以定義為每秒處理器所能完成的局部計算數目與每秒路由器所能傳輸的數據量之比。如果能夠合適的平衡計算和通信,則BSP模型在可編程性方面具有主要的優點,而直接在BSP模型上執行算法(不是自動的編譯它們),這個優點將隨著g的增加而更加明顯;
5. 為PRAM模型所設計的算法,都可以采用在每個BSP處理器上模擬一些PRAM處理器的方法來實現。
BSP模型的評價
1. 在并行計算時,Valiant試圖也為軟件和硬件之間架起一座類似于馮·諾伊曼機的橋梁,它論證了BSP模型可以起到這樣的作用,正是因為如此,BSP模型也常叫做橋模型。
2. 一般而言,分布存儲的MIMD模型的可編程性比較差,但在BSP模型中,如果計算和通信可以合適的平衡(例如g=1),則它在可編程方面呈現出主要的優點。
3. 在BSP模型上,曾直接實現了一些重要的算法(如矩陣乘、并行前序運算、FFT和排序等),他們均避免了自動存儲管理的額外開銷。
4. BSP模型可以有效的在超立方體網絡和光交叉開關互連技術上實現,顯示出,該模型與特定的技術實現無關,只要路由器有一定的通信吞吐率。
5. 在BSP模型中,超級步的長度必須能夠充分的適應任意的h-relation,這一點是人們最不喜歡的。
6. 在BSP模型中,在超級步開始發送的消息,即使網絡延遲時間比超級步的長度短,該消息也只能在下一個超級步才能被使用。
7. BSP模型中的全局障礙同步假定是用特殊的硬件支持的,但很多并行機中可能沒有相應的硬件。
BSP與MapReduce對比
執行機制:MapReduce是一個數據流模型,每個任務只是對輸入數據進行處理,產生的輸出數據作為另一個任務的輸入數據,并行任務之間獨立地進行,串行任務之間以磁盤和數據復制作為交換介質和接口。
BSP是一個狀態模型,各個子任務在本地的子圖數據上進行計算、通信、修改圖的狀態等操作,并行任務之間通過消息通信交流中間計算結果,不需要像MapReduce那樣對全體數據進行復制。
迭代處理:MapReduce模型理論上需要連續啟動若干作業才可以完成圖的迭代處理,相鄰作業之間通過分布式文件系統交換全部數據。BSP模型僅啟動一個作業,利用多個超步就可以完成迭代處理,兩次迭代之間通過消息傳遞中間計算結果。由于減少了作業啟動、調度開銷和磁盤存取開銷,BSP模型的迭代執行效率較高。
數據分割:基于BSP的圖處理模型,需要對加載后的圖數據進行一次再分布的過程,以確定消息通信時的路由地址。例如,各任務并行加載數據過程中,根據一定的映射策略,將讀入的數據重新分發到對應的計算任務上(通常是放在內存中),既有磁盤I/O又有網絡通信,開銷很大。但是一個BSP作業僅需一次數據分割,在之后的迭代計算過程中除了消息通信之外,不再需要進行數據的遷移。而基于MapReduce的圖處理模型,一般情況下,不需要專門的數據分割處理。但是Map階段和Reduce階段存在中間結果的Shuffle過程,增加了磁盤I/O和網絡通信開銷。
MapReduce的設計初衷:解決大規模、非實時數據處理問題。"大規模"決定數據有局部性特性可利用(從而可以劃分)、可以批處理;"非實時"代表響應時間可以較長,有充分的時間執行程序。而BSP模型在實時處理有優異的表現。這是兩者最大的一個區別。
BSP模型的實現
1.Pregel
Google的大規模圖計算框架,首次提出了將BSP模型應用于圖計算,具體請看Pregel——大規模圖處理系統,不過至今未開源。
2.Apache Giraph
ASF社區的Incubator項目,由Yahoo!貢獻,是BSP的java實現,專注于迭代圖計算(如pagerank,最短連接等),每一個job就是一個沒有reducer過程的hadoop job。
3.Apache Hama
也是ASF社區的Incubator項目,與Giraph不同的是它是一個純粹的BSP模型的java實現,并且不單單是用于圖計算,意在提供一個通用的BSP模型的應用框架。
4.GraphLab
CMU的一個迭代圖計算框架,C++實現的一個BSP模型應用框架,不過對BSP模型做了一定的修改,比如每一個超步之后并不設置全局同步點,計算可以完全異步進行,加快了任務的完成時間。
5.Spark
加州大學伯克利分校實現的一個專注于迭代計算的應用框架,用Scala語言寫就,提出了RDD(彈性分布式數據集)的概念,每一步的計算數據都從上一步結果精簡而來,大大降低了網絡傳輸,同時保證了血統的純正性(即出錯只需返回上一步即可),增強了容錯功能。Spark論文里也基于此框架實現了BSP模型(叫Bagel)。值得一提的是國內的豆瓣也基于該思想用Python實現了這樣一個框架叫Dpark,并且已經開源。https://github.com/douban/dpark
6.Trinity
這是微軟的一個圖計算平臺,C#開發的,它是為了提供一個專用的圖計算應用平臺,包括底層的存儲到上層的應用,應該是可以實現BSP模型的,文章發在SIGMOD13上,可恨的是也不開源。主頁
7.GoldenOrb
另一個BSP模型的java實現,是對Pregel的一個開源實現,應用在hadoop上。
官網:(要FQ)
源碼:https://github.com/jzachr/goldenorb
8.Phoebus
Erlang語言實現的BSP模型,也是對Pregel的一個開源實現。https://github.com/xslogic/phoebus
9.Rubicon
Pregel的開源實現。https://launchpad.net/rubicon
10.Signal/Collect
也是一個Scala版的BSP模型實現。
11.PEGASUS
在hadoop上實現的一個java版的BSP模型,發表在SIGKDD2011上。~pegasus/index.htm
LogP模型
根據技術發展的趨勢,20世紀90年代末和未來的并行計算機發展的主流之一是巨量并行機,即MPC(Massively Parallel Computers),它由成千個功能強大的處理器/存儲器節點,通過具有有限帶寬的和相當大的延遲的互連網絡構成。所以我們建立并行計算模型應該充分考慮到這個情況,這樣基于模型的并行算法才能在現有和將來的并行計算機上有效的運行。根據已有的編程經驗,現有的共享存儲、消息傳遞和數據并行等編程方式都很流行,但還沒有一個公認的和占支配地位的編程方式,因此應該尋求一種與上面的編程方式無關的計算模型。而根據現有的理論模型,共享存儲PRAM模型和互連網絡的SIMD模型對開發并行算法還不夠合適,因為它們既沒有包含分布存儲的情況,也沒有考慮通信和同步等實際因素,從而也不能精確的反映運行在真實的并行計算機上的算法的行為,所以,1993年D.Culer等人在分析了分布式存儲計算機特點的基礎上,提出了點對點通信的多計算機模型,它充分說明了互聯網絡的性能特性,而不涉及到具體的網絡結構,也不假定算法一定要用現實的消息傳遞操作進行描述。
LogP模型是一種分布存儲的、點到點通信的多處理機模型,其中通信網絡由4個主要參數來描述:
(1)L(Latency) 表示源處理機與目的處理機進行消息(一個或幾個字)通信所需要的等待或延遲時間的上限,表示網絡中消息的延遲。
(2)o(overhead)表示處理機準備發送或接收每個消息的時間開銷(包括操作系統核心開銷和網絡軟件開銷),在這段時間里處理不能執行其它操作。
(3)g(gap)表示一臺處理機連續兩次發送或接收消息時的最小時間間隔,其倒數即微處理機的通信帶寬。
(4)P(Processor)處理機/存儲器模塊個數
假定一個周期完成一次局部操作,并定義為一個時間單位,那么,L,o和g都可以表示成處理器周期的整數倍。
LogP模型的特點
(1)抓住了網絡與處理機之間的性能瓶頸。g反映了通信帶寬,單位時間內最多有L/g個消息能進行處理機間傳送。
(2)處理機之間異步工作,并通過處理機間的消息傳送來完成同步。
(3)對多線程技術有一定反映。每個物理處理機可以模擬多個虛擬處理機(VP),當某個VP有訪問請求時,計算不會終止,但VP的個數受限于通信帶寬和上下文交換的開銷。VP受限于網絡容量,至多有L/g個VP。
(4)消息延遲不確定,但延遲不大于L。消息經歷的等待時間是不可預測的,但在沒有阻塞的情況下,最大不超過L。
(5)LogP模型鼓勵編程人員采用一些好的策略,如作業分配,計算與通信重疊以及平衡的通信模式等。
(6)可以預估算法的實際運行時間。
LogP模型的不足之處
(1)對網絡中的通信模式描述的不夠深入。如重發消息可能占滿帶寬、中間路由器緩存飽和等未加描述。
(2)LogP模型主要適用于消息傳遞算法設計,對于共享存儲模式,則簡單地認為遠地讀操作相當于兩次消息傳遞,未考慮流水線預取技術、Cache引起的數據不一致性以及Cache命中率對計算的影響。
(3)未考慮多線程技術的上下文開銷。
-
BSP
+關注
關注
1文章
86瀏覽量
26109 -
并行計算
+關注
關注
0文章
27瀏覽量
9421 -
PRAM
+關注
關注
0文章
4瀏覽量
9443
發布評論請先 登錄
相關推薦
SPICE仿真模型的優點和缺點
LogP簡化模型參數估計
基于多級混合模型的圖像分割方法
什么是IBIS模型?以及IBIS模型的仿真及優缺點
深度分析RNN的模型結構,優缺點以及RNN模型的幾種應用





 工商網監
工商網監
評論