 一文讀懂人工智能、機器學習、神經網絡及深度學習關系
一文讀懂人工智能、機器學習、神經網絡及深度學習關系
前段時間看了不少關于人工智能方面的書籍博客和論壇,深深覺得了人工智能是個大坑,里面有太多的知識點和學科,要想深入絕非易事,于是萌發了自己寫一些博客把自己的學習歷程和一些知識點筆記都記錄下來的想法,給自己一個總結收獲,同時監督自己的動力,這樣咱也算是“有監督學習”了:)
這里提到了“有監督學習”,在剛剛開始學習人工智能/機器學習的時候經常看到,對于這個概念從一無所知到懵懵懂懂到略有了解也花費了一點時間,對于老鳥來說這些概念都太基本了因此沒有過多的篇幅來介紹,但對于新手來說,剛剛接觸一個新的領域的時候往往看到的都是一個個“高大上”的名詞,這種名詞多了,學習曲線就陡峭了,因此我們還是從基本的概念開始整理整理吧。因此這篇筆記就是一個基本概念的梳理,若有不恰的地方望不吝賜教。
人工智能,機器學習,神經網絡,深度學習的關系
剛剛接觸人工智能的內容時,經常性的會看到人工智能,機器學習,深度學習還有神經網絡的不同的術語,一個個都很高冷,以致于傻傻分不清到底它們之間是什么樣的關系,很多時候都認為是一個東西的不同表達而已,看了一些具體的介紹后才漸漸有了一個大體的模型。
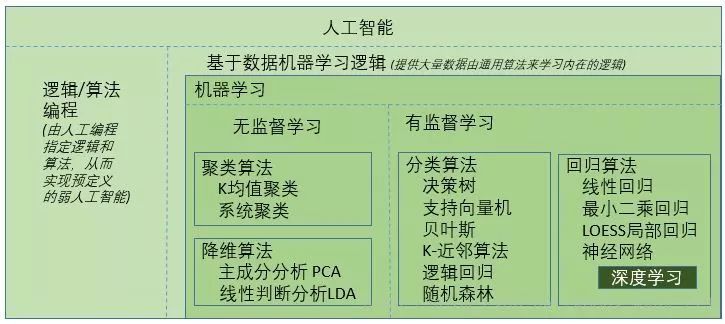
機器學習
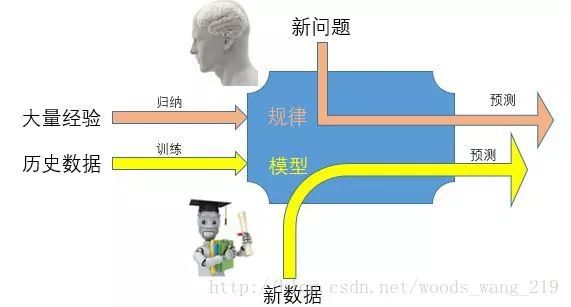
機器學習是人工智能最重要的內容,先來看看它的一個定義(當然有很多不同的定義):“Machine learning is the idea that there are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, youfeed datato thegeneric algorithmand itbuilds its own logicbased on the data.”這里面有幾個重要的關鍵詞,就是你不用寫專門的業務邏輯代碼而是通過輸入大量的數據給機器,由機器通過一個通用的機制來建立它自己的業務邏輯,也就是機器“自我學習”了業務的邏輯,當然這種學習后的邏輯可以用來處理新的數據。這和人類的學習過程有些類似,如下圖:
有監督學習和無監督學習
這兩個概念也是剛剛接觸機器學習經常碰到的概念,通俗/簡單點來說,所謂有監督學習就是訓練用歷史數據是既有問題又有答案,而無監督學習就是訓練用歷史數據是只有問題沒有答案。正式的說法一般是把答案稱之為標簽label還有一種介于兩者之間的混合學習方法,稱為半監督學習
在無監督學習中,主要是發現數據中未知的結構或者是趨勢。雖然原數據不含任何的標簽,但我們希望可以對數據進行整合(分組或者聚類),或是簡化數據(降維、移除不必要的變量或者檢測異常值)。因此無監督算法主要的分類包含:- 聚類算法 (代表:K均值聚類,系統聚類)- 降維算法 (代表:主成份分析PCA,線性判斷分析LDA)
有監督學習,可以根據預測變量的類型再細分。如果預測變量是連續的,那這就屬于回歸問題。而如果預測變量是獨立類別(定性或是定類的離散值),那這就屬于分類問題了。因此有監督學習主要的分類包含:- 回歸算法 (線性回歸,最小二乘回歸,LOESS局部回歸,神經網路,深度學習)- 分類算法(決策樹,支持向量機,貝葉斯,K-近鄰算法,邏輯回歸,隨機森林)
這里面提到了很多的算法,目前還不需要一一去掌握,相信在今后的學習中會經常看到,先混個眼熟:)
這些所有的算法中,目前最熱的恐怕是深度學習了,但要了解深度學習必須先了解它的前任(前生,父類)。
神經網絡
關于神經網絡的介紹在網上有很多很多了,有不少大牛的介紹和課程,本人主要參考/推薦如下:神經網絡淺講:從神經元到深度學習用平常語言介紹神經網絡因此不再贅述細節,做了一個不完全的總結圖: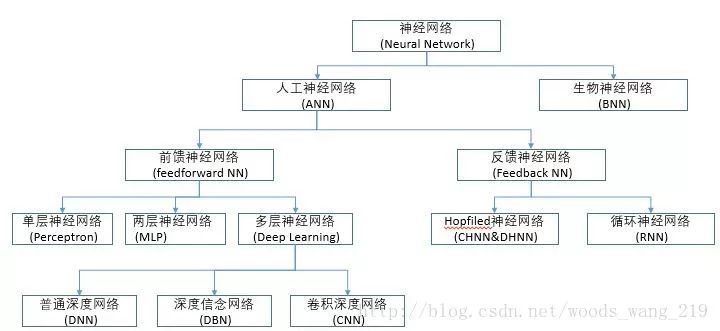
好了,大體的一個機器學習的最最基本的概念總結完畢,其實學習這些基本概念還是比較簡單方便的,畢竟我們有強大的搜索引擎,只要輸入“機器學習”就能得到海量的知識讓我們去學習,不過對于剛開始的初學者來說,先淺嘗即止即可,有了一個框架性的了解,為后續的深入學習做準備。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
人工智能
+關注
關注
1791文章
46853瀏覽量
237544 -
機器學習
+關注
關注
66文章
8377瀏覽量
132406 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
原文標題:人工智能學習筆記-基本概念
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
詳解深度學習、神經網絡與卷積神經網絡的應用






 工商網監
工商網監
評論