") 機器學(xué)習(xí)中的代價函數(shù)與交叉熵
機器學(xué)習(xí)中的代價函數(shù)與交叉熵
本文將介紹信息量,熵,交叉熵,相對熵的定義,以及它們與機器學(xué)習(xí)算法中代價函數(shù)的定義的聯(lián)系。
1. 信息量
信息的量化計算: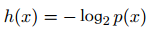
解釋如下:
信息量的大小應(yīng)該可以衡量事件發(fā)生的“驚訝程度”或不確定性:
如果有人告訴我們一個相當不可能的事件發(fā)生了,我們收到的信息要多于我們被告知某個很可能發(fā)?的事件發(fā)?時收到的信息。如果我們知道某件事情?定會發(fā)?,那么我們就不會接收到信息。 也就是說,信息量應(yīng)該連續(xù)依賴于事件發(fā)生的概率分布p(x)。因此,我們想要尋找一個基于概率p(x)計算信息量的函數(shù)h(x),它應(yīng)該具有如下性質(zhì):
h(x) >= 0,因為信息量表示得到多少信息,不應(yīng)該為負數(shù)。
h(x, y) = h(x) + h(y),也就是說,對于兩個不相關(guān)事件x和y,我們觀察到兩個事件x, y同時發(fā)?時獲得的信息應(yīng)該等于觀察到事件各?發(fā)?時獲得的信息之和;
h(x)是關(guān)于p(x)的單調(diào)遞減函數(shù),也就是說,事件x越容易發(fā)生(概率p(x)越大),信息量h(x)越小。
又因為如果兩個不相關(guān)事件是統(tǒng)計獨?的,則有p(x, y) =p(x)p(y)。根據(jù)不相關(guān)事件概率可乘、信息量可加,很容易想到對數(shù)函數(shù),看出h(x)一定與p(x)的對數(shù)有關(guān)。因此,有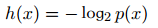 滿足上述性質(zhì)。
滿足上述性質(zhì)。
2. 熵(信息熵)
對于一個隨機變量X而言,它的所有可能取值的信息量的期望就稱為熵。熵的本質(zhì)的另一種解釋:最短平均編碼長度(對于離散變量)。
離散變量:
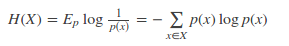
連續(xù)變量:
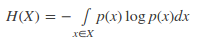
3. 交叉熵
現(xiàn)有關(guān)于樣本集的2個概率分布p和q,其中p為真實分布,q非真實分布。按照真實分布p來衡量識別一個樣本的熵,即基于分布p給樣本進行編碼的最短平均編碼長度為:
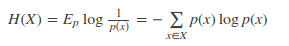
如果使用非真實分布q來給樣本進行編碼,則是基于分布q的信息量的期望(最短平均編碼長度),由于用q來編碼的樣本來自分布p,所以期望與真實分布一致。所以基于分布q的最短平均編碼長度為:
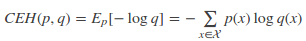
上式CEH(p, q)即為交叉熵的定義。
4. 相對熵
將由q得到的平均編碼長度比由p得到的平均編碼長度多出的bit數(shù),即使用非真實分布q計算出的樣本的熵(交叉熵),與使用真實分布p計算出的樣本的熵的差值,稱為相對熵,又稱KL散度。
KL(p, q) = CEH(p, q) - H(p)=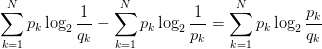
相對熵(KL散度)用于衡量兩個概率分布p和q的差異。注意,KL(p, q)意味著將分布p作為真實分布,q作為非真實分布,因此KL(p, q) != KL(q, p)。
5. 機器學(xué)習(xí)中的代價函數(shù)與交叉熵
若 p(x)是數(shù)據(jù)的真實概率分布, q(x)是由數(shù)據(jù)計算得到的概率分布。機器學(xué)習(xí)的目的就是希望q(x)盡可能地逼近甚至等于p(x) ,從而使得相對熵接近最小值0. 由于真實的概率分布是固定的,相對熵公式的后半部分(-H(p))就成了一個常數(shù)。那么相對熵達到最小值的時候,也意味著交叉熵達到了最小值。對q(x)的優(yōu)化就等效于求交叉熵的最小值。另外,對交叉熵求最小值,也等效于求最大似然估計(maximum likelihood estimation)。
特別的,在logistic regression中,p:真實樣本分布,服從參數(shù)為p的0-1分布,即X~B(1,p)
p(x = 1) = y
p(x = 0) = 1 - yq:待估計的模型,服從參數(shù)為q的0-1分布,即X~B(1,q)
p(x = 1) = h(x)
p(x = 0) = 1-h(x)
其中h(x)為logistic regression的假設(shè)函數(shù)。兩者的交叉熵為:
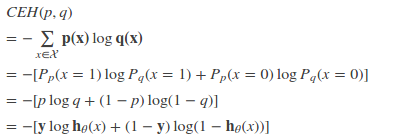
對所有訓(xùn)練樣本取均值得:
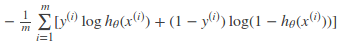
這個結(jié)果與通過最大似然估計方法求出來的結(jié)果一致。使用最大似然估計方法參加博客Logistic Regression.
-
函數(shù)
+關(guān)注
關(guān)注
3文章
4308瀏覽量
62434 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8381瀏覽量
132425 -
交叉熵
+關(guān)注
關(guān)注
0文章
4瀏覽量
2352
原文標題:信息量,熵,交叉熵,相對熵與代價函數(shù)
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
機器學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)參數(shù)的代價函數(shù)
機器學(xué)習(xí)的分類器
大數(shù)據(jù)中邊界向量調(diào)節(jié)熵函數(shù)支持向量機研究
機器學(xué)習(xí)經(jīng)典損失函數(shù)比較
機器學(xué)習(xí)的logistic函數(shù)和softmax函數(shù)總結(jié)
基于交叉熵算法的跟馳模型標定

當機器學(xué)習(xí)遇上SSD,會擦出怎樣的火花呢?
機器學(xué)習(xí)和深度學(xué)習(xí)中分類與回歸常用的幾種損失函數(shù)
機器學(xué)習(xí)中若干典型的目標函數(shù)構(gòu)造方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論