") 在CP攻擊下監(jiān)視自動(dòng)駕駛汽車(AV)動(dòng)力狀態(tài)估計(jì)過程
在CP攻擊下監(jiān)視自動(dòng)駕駛汽車(AV)動(dòng)力狀態(tài)估計(jì)過程
對于自動(dòng)駕駛汽車(AV)而言,要想在未來的智能交通系統(tǒng)中以真正自主的方式運(yùn)行,它必須能夠處理通過大量傳感器和通信鏈路所收集的數(shù)據(jù)。這對于減少車輛碰撞的可能性和改善道路上的車流量至關(guān)重要。然而,這種對通信和數(shù)據(jù)處理的依賴性使得AV很容易受到網(wǎng)絡(luò)物理攻擊。
最近,美國弗吉尼亞理工大學(xué)電氣與計(jì)算機(jī)工程系的Aidin Ferdowsi和Walid Saad教授,瑞典愛立信研究院的Ursula Challita教授,以及美國羅格斯大學(xué)的Narayan B. Mandayam教授,針對自動(dòng)駕駛汽車系統(tǒng)中的“安全性”問題,提出了一種新型對抗深度強(qiáng)化學(xué)習(xí)(RL)框架,以解決自動(dòng)駕駛汽車的安全性問題。
可以這樣說,為了能夠在未來的智能城市有效地運(yùn)行,自動(dòng)駕駛汽車(AV)必須依靠車內(nèi)傳感器,如攝像頭和雷達(dá),以及車輛間的通信。這種對于傳感器和通信鏈路的依賴使得AV暴露于攻擊者的網(wǎng)絡(luò)物理(CP)攻擊之下,他們試圖通過操縱它們的數(shù)據(jù)來控制AV。因此,為了確保安全和最佳的AV動(dòng)力學(xué)控制,AV中的數(shù)據(jù)處理功能必須針對這種CP攻擊具有強(qiáng)大的魯棒性。
為此,本文分析了在存在CP攻擊情況下監(jiān)視AV動(dòng)力學(xué)的狀態(tài)估計(jì)過程,并提出了一種新的對抗深度強(qiáng)化學(xué)習(xí)(RL)算法,以最大化AV動(dòng)力學(xué)控制針對CP攻擊的魯棒性。我們在博弈論框架中對攻擊者的行為和AV對CP攻擊的反應(yīng)進(jìn)行了研究。
在制定的游戲中,攻擊者試圖向AV傳感器讀數(shù)中注入錯(cuò)誤數(shù)據(jù),以操縱車輛間的最佳安全間距,并潛在地增加AV事故的風(fēng)險(xiǎn)或減少道路上的車流量。與此同時(shí),AV作為一名防守者,試圖將間距的偏差最小化,以確保具有針對攻擊者行為的魯棒性。由于AV沒有關(guān)于攻擊者行為的信息,并且由于數(shù)據(jù)值操作的無限可能性,因此玩家以往交互的結(jié)果被輸入到長短期記憶網(wǎng)絡(luò)(LSTM)塊中。
每個(gè)玩家的LSTM塊學(xué)習(xí)由其自身行為產(chǎn)生的預(yù)期間距偏差并將其饋送給其RL算法。然后,攻擊者的RL算法選擇能夠最大化間距偏差的動(dòng)作,而AV的RL算法試圖找到最小化這種偏差的最佳動(dòng)作。模擬結(jié)果表明,我們所提出的對抗深度RL算法可以提高AV動(dòng)力學(xué)控制的魯棒性,因?yàn)樗梢宰钚』疉V間的間距偏差。
智能交通系統(tǒng)(ITS)將包括自動(dòng)駕駛汽車(AV)、路邊智能傳感器(RSS)、車輛通信、甚至是無人機(jī)。為了在未來的ITS中能夠以真正自主的方式運(yùn)行,AV必須能夠處理通過大量傳感器和通信鏈路所收集的大量ITS數(shù)據(jù)。這些數(shù)據(jù)的可靠性對于減少車輛碰撞的可能性和改善道路上的車流量至關(guān)重要。然而,這種對通信和數(shù)據(jù)處理的依賴性使得AV很容易受到網(wǎng)絡(luò)物理攻擊。
特別是,攻擊者可能會在AV數(shù)據(jù)處理階段進(jìn)行插入,通過注入錯(cuò)誤數(shù)據(jù)來降低測量的可靠性,并最終導(dǎo)致事故或危及ITS中的交通流量。這樣的流量中斷還可以波及到其他相互依賴的關(guān)鍵基礎(chǔ)設(shè)施中,例如為ITS提供服務(wù)的電網(wǎng)或蜂窩通信系統(tǒng)。

圖1:文中所提出的對抗深度強(qiáng)化學(xué)習(xí)算法的體系結(jié)構(gòu)
最近,科學(xué)家們已經(jīng)提出了一些解決車輛內(nèi)部安全問題的安全性解決方案。P. Kleberger、T. Olovsson和E. Jonsson在他們所著的《聯(lián)網(wǎng)汽車車載網(wǎng)絡(luò)的安全問題》中,確定了車輛控制器的關(guān)鍵漏洞所在,并提出了許多入侵檢測算法用以保護(hù)該控制器。此外,在《對聯(lián)網(wǎng)汽車的實(shí)際無線攻擊和車輛內(nèi)部的安全協(xié)議》中,作者指出,AVs當(dāng)前安全協(xié)議中的遠(yuǎn)程無線攻擊可能會中斷其控制器區(qū)域網(wǎng)絡(luò)。
他們分析了AVs車輛內(nèi)部網(wǎng)絡(luò)對局外無線攻擊的脆弱性。同時(shí),《插入式車輛的安全性問題》的作者解決了插電式電動(dòng)汽車的安全性挑戰(zhàn),同時(shí)考慮了它們對電力系統(tǒng)的影響。此外,在《關(guān)于嵌入式汽車網(wǎng)絡(luò)安全威脅和保護(hù)機(jī)制的調(diào)查》中介紹了嵌入式汽車網(wǎng)絡(luò)安全威脅和保護(hù)機(jī)制的調(diào)查。
此外,最近科學(xué)家們還研究了車輛通信安全挑戰(zhàn)和解決方案。分析了當(dāng)前車輛通信體系架構(gòu)的安全漏洞。此外,科學(xué)家們發(fā)現(xiàn),通過使用短期認(rèn)證方案和合作車輛計(jì)算架構(gòu),可以減輕由信標(biāo)加密引起的計(jì)算開銷。
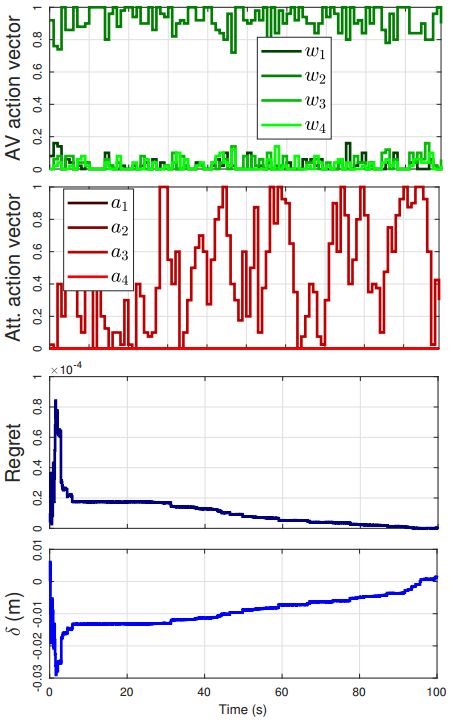
圖2:在攻擊者只攻擊信標(biāo)信息的情況下,AV和攻擊者的行為、regret以及我們提出的算法的偏差
然而,在設(shè)計(jì)安全解決方案時(shí),以往的一些研究成果中的體系構(gòu)架和解決方案沒有兼顧AV 的網(wǎng)絡(luò)層與物理層之間的相互依賴性。此外,現(xiàn)有的研究沒有對攻擊者的行為和目標(biāo)進(jìn)行合理的建模。在這種情況下,攻擊者的行為和目標(biāo)的這種網(wǎng)絡(luò)-物理依賴性將有助于提供更好的安全解決方案。
另外,在一些以往的研究成果中,現(xiàn)有技術(shù)沒有提供能夠增強(qiáng)AV動(dòng)力學(xué)控制應(yīng)對攻擊的魯棒性的解決方案。然而,設(shè)計(jì)一個(gè)最佳且安全的ITS需要對車輛間傳感器和車輛間通信的攻擊具有魯棒性。此外,現(xiàn)有的ITS安全性研究往往假設(shè)攻擊者的行為處于穩(wěn)定狀態(tài),然而在許多真實(shí)情況下,攻擊者可能會自適應(yīng)地改變其策略以增強(qiáng)攻擊對ITS的影響。
因此,本文的主要貢獻(xiàn)在于提出了一種新型對抗式深度強(qiáng)化學(xué)習(xí)(RL)框架,旨在提供具有魯棒性的AV控制。特別要強(qiáng)調(diào)的是,我們提出了一種車輛跟隨模型(car following model),在該模型中,我們將關(guān)注的重點(diǎn)放在緊跟在另一個(gè)AV后的一個(gè)AV的控制上。這樣的模型是恰當(dāng)?shù)模驗(yàn)樗鼤蹲紸V的動(dòng)力學(xué)控制,同時(shí)記錄AV的傳感器讀數(shù)和信標(biāo)。
我們考慮通過車內(nèi)傳感器(例如:攝像頭、雷達(dá)、RSS、車內(nèi)信標(biāo))收集領(lǐng)先AV的四個(gè)信息源。我們認(rèn)為攻擊者可以向這些信息中心注入不良數(shù)據(jù),并試圖增加事故風(fēng)險(xiǎn)或減少車流量。相比之下,AV的目標(biāo)是保持對攻擊者的數(shù)據(jù)注入攻擊(data injection attacks)具有魯棒性的同時(shí),最大限度地控制其速度。為了分析AV和攻擊者之間的交互,我們提出了一個(gè)博弈問題,并分析了它的納什均衡(NE)。然而,我們注意到,由于存在連續(xù)的攻擊者和AV動(dòng)作集以及連續(xù)的AV速度和間隔,使得在NE處獲得AV和攻擊者動(dòng)作具有挑戰(zhàn)性。
為了解決這一問題,我們提出了兩個(gè)基于長-短期記憶(long-short term memory)(LSTM)塊的深度神經(jīng)網(wǎng)絡(luò)(DNN),針對AV和攻擊者,提取過去AV動(dòng)態(tài)的摘要,并將這些摘要反饋給每個(gè)玩家的RL算法。一方面,AV的RL算法試圖通過結(jié)合傳感器讀數(shù)來從領(lǐng)先的AV速度中學(xué)習(xí)最佳估計(jì)。另一方面,攻擊者的RL算法試圖欺騙AV,并偏離車輛間的最佳安全距離。模擬結(jié)果表明,所提出的深度RL算法收斂于混合策略的納什均衡點(diǎn),可以顯著提高AV針對數(shù)據(jù)注入攻擊的魯棒性。
結(jié)果還表明,AV可以利用所提出的深度RL算法來有效學(xué)習(xí)傳感器融合規(guī)則,最大限度地減小速度估計(jì)誤差,從而減小了與最優(yōu)安全間距的偏差。
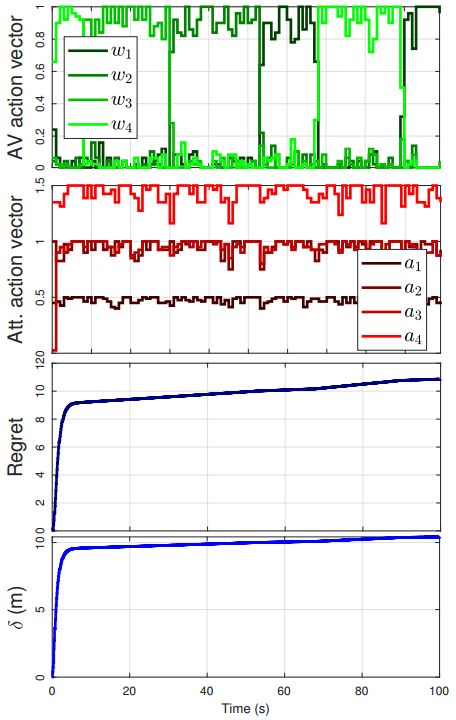
圖3:在攻擊者攻擊所有傳感器的情況下,AV和攻擊者的行為、regret和偏差
本文提出了一種新型深度RL方法,該方法能夠在傳感器讀數(shù)受到數(shù)據(jù)注入攻擊的情況下,實(shí)現(xiàn)對AV的具有魯棒性的動(dòng)力學(xué)控制(robust dynamics control)。為了分析攻擊者攻擊AV數(shù)據(jù)的動(dòng)機(jī),同時(shí)了解AV對這類攻擊的反應(yīng),我們提出了攻擊者與AV之間的博弈問題。我們已經(jīng)表明,在納什均衡(the mixed strategies at Nash equilibrium)中推導(dǎo)出混合策略從分析角度而言具有挑戰(zhàn)性。
因此,我們使用我們提出的深度RL算法學(xué)習(xí)AV在每個(gè)時(shí)間步長中的最優(yōu)傳感器融合。在所提出的深度RL算法中,我們使用了LSTM塊,它可以提取AV和攻擊者動(dòng)作及偏差值之間的時(shí)間特征與依懶性,并將其反饋給強(qiáng)化學(xué)習(xí)算法。模擬結(jié)果表明,利用所提出的深度RL算法,AV可以緩解數(shù)據(jù)注入攻擊對傳感器數(shù)據(jù)的影響,從而保持對這些攻擊的魯棒性。
-
智能傳感器
+關(guān)注
關(guān)注
16文章
588瀏覽量
55277 -
智能交通系統(tǒng)
+關(guān)注
關(guān)注
0文章
40瀏覽量
12137 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
783文章
13694瀏覽量
166166
原文標(biāo)題:「對抗深度強(qiáng)化學(xué)習(xí)」是如何解決自動(dòng)駕駛汽車系統(tǒng)中的「安全性」問題的?
文章出處:【微信號:AItists,微信公眾號:人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
MEMS技術(shù)在自動(dòng)駕駛汽車中的應(yīng)用
鑒源實(shí)驗(yàn)室·如何通過雷達(dá)攻擊自動(dòng)駕駛汽車-針對點(diǎn)云識別模型的對抗性攻擊的科普
自動(dòng)駕駛汽車安全嗎?

使用STT全面提升自動(dòng)駕駛中的多目標(biāo)跟蹤
FPGA在自動(dòng)駕駛領(lǐng)域有哪些優(yōu)勢?
FPGA在自動(dòng)駕駛領(lǐng)域有哪些應(yīng)用?
自動(dòng)駕駛汽車如何識別障礙物
自動(dòng)駕駛汽車傳感器有哪些
未來已來,多傳感器融合感知是自動(dòng)駕駛破局的關(guān)鍵
大眾汽車和Mobileye加強(qiáng)自動(dòng)駕駛合作
自動(dòng)駕駛汽車技術(shù) | 車載雷達(dá)系統(tǒng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論