") 自動(dòng)駕駛四大核心技術(shù)的環(huán)境感知的詳細(xì)概述
自動(dòng)駕駛四大核心技術(shù)的環(huán)境感知的詳細(xì)概述
人類駕駛員會(huì)根據(jù)行人的移動(dòng)軌跡大概評(píng)估其下一步的位置,然后根據(jù)車速,計(jì)算出安全空間(路徑規(guī)劃),公交司機(jī)最擅長(zhǎng)此道。無(wú)人駕駛汽車同樣要能做到。要注意這是多個(gè)移動(dòng)物體的軌跡的追蹤與預(yù)測(cè),難度比單一物體要高得多。這就是環(huán)境感知,也是無(wú)人駕駛汽車最具難度的技術(shù)。
今天介紹一下環(huán)境感知的內(nèi)容。環(huán)境感知也被稱為MODAT(Moving Object Detection andTracking)。
自動(dòng)駕駛四大核心技術(shù),分別是環(huán)境感知、精確定位、路徑規(guī)劃、線控執(zhí)行。環(huán)境感知是其中被研究最多的部分,不過(guò)基于視覺(jué)的環(huán)境感知是無(wú)法滿足無(wú)人汽車自動(dòng)駕駛要求的。實(shí)際的無(wú)人駕駛汽車面對(duì)的路況遠(yuǎn)比實(shí)驗(yàn)室仿真或者試車場(chǎng)的情況要復(fù)雜很多,這就需要建立大量的數(shù)學(xué)方程。而良好的規(guī)劃必須建立對(duì)周邊環(huán)境,尤其是動(dòng)態(tài)環(huán)境的深刻理解。
環(huán)境感知主要包括三個(gè)方面,路面、靜態(tài)物體和動(dòng)態(tài)物體。對(duì)于動(dòng)態(tài)物體,不僅要檢測(cè)還要對(duì)其軌跡進(jìn)行追蹤,并根據(jù)追蹤結(jié)果,預(yù)測(cè)該物體下一步的軌跡(位置)。這在市區(qū),尤其中國(guó)市區(qū)必不可少,最典型場(chǎng)景就是北京五道口:如果你見(jiàn)到行人就停,那你就永遠(yuǎn)無(wú)法通過(guò)五道口,行人幾乎是從不停歇地從車前走過(guò)。人類駕駛員會(huì)根據(jù)行人的移動(dòng)軌跡大概評(píng)估其下一步的位置,然后根據(jù)車速,計(jì)算出安全空間(路徑規(guī)劃),公交司機(jī)最擅長(zhǎng)此道。無(wú)人駕駛汽車同樣要能做到。要注意這是多個(gè)移動(dòng)物體的軌跡的追蹤與預(yù)測(cè),難度比單一物體要高得多。這就是MODAT(Moving Object Detectionand Tracking)。也是無(wú)人駕駛汽車最具難度的技術(shù)。
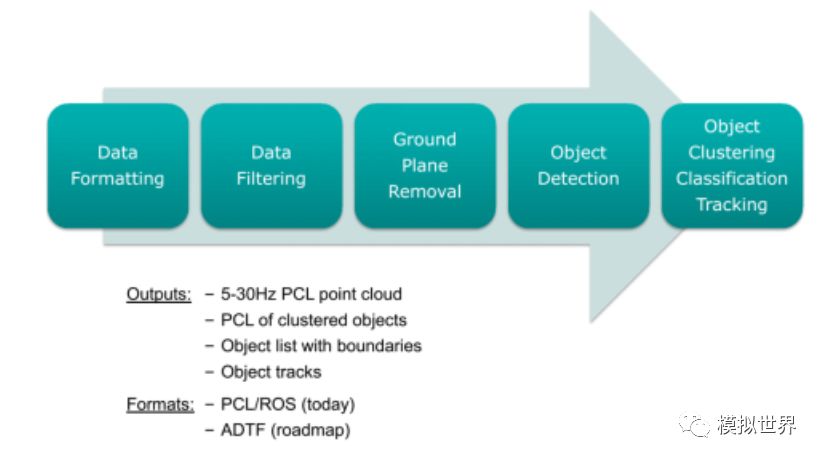
下圖是一個(gè)典型的無(wú)人駕駛汽車環(huán)境感知框架 :
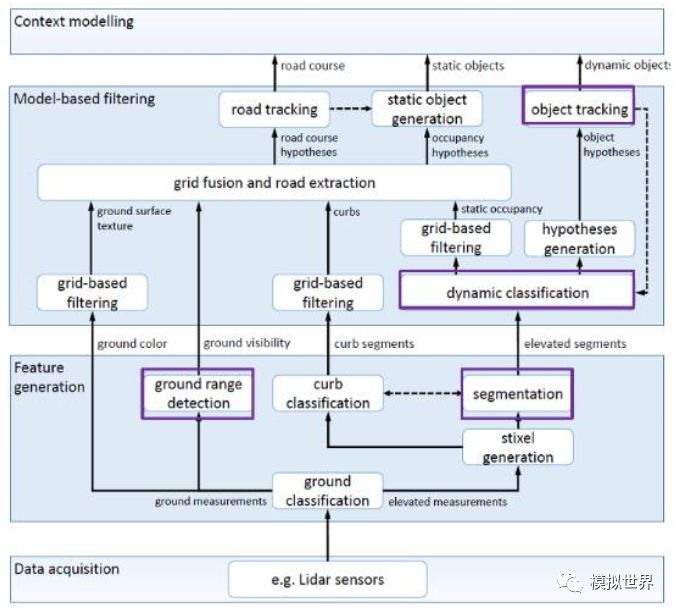
這是基于激光雷達(dá)的環(huán)境感知模型,目前來(lái)說(shuō),搞視覺(jué)環(huán)境感知模型研究的人遠(yuǎn)多于激光雷達(dá)。不過(guò)很遺憾地講,在無(wú)人駕駛汽車這件事上,視覺(jué)肯定是不夠的,長(zhǎng)遠(yuǎn)來(lái)說(shuō), 激光雷達(dá)配合毫米波雷達(dá), 再加上視覺(jué)環(huán)境感知的綜合方案才能真正做到無(wú)人駕駛。
讓我們來(lái)看計(jì)算機(jī)視覺(jué)的發(fā)展歷程,神經(jīng)網(wǎng)絡(luò)的歷史可追述到上世紀(jì)四十年代,曾經(jīng)在八九十年代流行。神經(jīng)網(wǎng)絡(luò)試圖通過(guò)模擬大腦認(rèn)知的機(jī)理,解決各種機(jī)器學(xué)習(xí)的問(wèn)題。1986年Rumelhart,Hinton和Williams在《自然》發(fā)表了著名的反向傳播算法用于訓(xùn)練神經(jīng)網(wǎng)絡(luò),直到今天仍被廣泛應(yīng)用。
不過(guò)深度學(xué)習(xí)自80年代后沉寂了許久。神經(jīng)網(wǎng)絡(luò)有大量的參數(shù),經(jīng)常發(fā)生過(guò)擬合問(wèn)題,即往往在訓(xùn)練集上準(zhǔn)確率很高,而在測(cè)試集上效果差。這部分歸因于當(dāng)時(shí)的訓(xùn)練數(shù)據(jù)集規(guī)模都較小,而且計(jì)算資源有限,即便是訓(xùn)練一個(gè)較小的網(wǎng)絡(luò)也需要很長(zhǎng)的時(shí)間。神經(jīng)網(wǎng)絡(luò)與其它模型相比并未在識(shí)別的準(zhǔn)確率上體現(xiàn)出明顯的優(yōu)勢(shì),而且難于訓(xùn)練。
因此更多的學(xué)者開(kāi)始采用諸如支持向量機(jī)(SVM)、Boosting、最近鄰等分類器。這些分類器可以用具有一個(gè)或兩個(gè)隱含層的神經(jīng)網(wǎng)絡(luò)模擬,因此被稱作淺層機(jī)器學(xué)習(xí)模型。它們不再模擬大腦的認(rèn)知機(jī)理;相反,針對(duì)不同的任務(wù)設(shè)計(jì)不同的系統(tǒng),并采用不同的手工設(shè)計(jì)的特征。例如語(yǔ)音識(shí)別采用高斯混合模型和隱馬爾可夫模型,物體識(shí)別采用SIFT特征,人臉識(shí)別采用LBP特征,行人檢測(cè)采用HOG特征。
2006年以后,得益于電腦游戲愛(ài)好者對(duì)性能的追求,GPU性能飛速增長(zhǎng)。同時(shí),互聯(lián)網(wǎng)很容易獲得海量訓(xùn)練數(shù)據(jù)。兩者結(jié)合,深度學(xué)習(xí)或者說(shuō)神經(jīng)網(wǎng)絡(luò)煥發(fā)了第二春。2012年,Hinton的研究小組采用深度學(xué)習(xí)贏得了ImageNet圖像分類的比賽。從此深度學(xué)習(xí)開(kāi)始席卷全球。
深度學(xué)習(xí)與傳統(tǒng)模式識(shí)別方法的最大不同在于它是從大數(shù)據(jù)中自動(dòng)學(xué)習(xí)特征,而非采用手工設(shè)計(jì)的特征。好的特征可以極大提高模式識(shí)別系統(tǒng)的性能。在過(guò)去幾十年模式識(shí)別的各種應(yīng)用中,手工設(shè)計(jì)的特征處于統(tǒng)治地位。它主要依靠設(shè)計(jì)者的先驗(yàn)知識(shí),很難利用大數(shù)據(jù)的優(yōu)勢(shì)。由于依賴手工調(diào)參數(shù),特征的設(shè)計(jì)中只允許出現(xiàn)少量的參數(shù)。深度學(xué)習(xí)可以從大數(shù)據(jù)中自動(dòng)學(xué)習(xí)特征的表示,其中可以包含成千上萬(wàn)的參數(shù)。手工設(shè)計(jì)出有效的特征是一個(gè)相當(dāng)漫長(zhǎng)的過(guò)程。回顧計(jì)算機(jī)視覺(jué)發(fā)展的歷史,往往需要五到十年才能出現(xiàn)一個(gè)受到廣泛認(rèn)可的好的特征。而深度學(xué)習(xí)可以針對(duì)新的應(yīng)用從訓(xùn)練數(shù)據(jù)中很快學(xué)習(xí)得到新的有效的特征表示。
一個(gè)模式識(shí)別系統(tǒng)包括特征和分類器兩個(gè)主要的組成部分,二者關(guān)系密切,而在傳統(tǒng)的方法中它們的優(yōu)化是分開(kāi)的。在神經(jīng)網(wǎng)絡(luò)的框架下,特征表示和分類器是聯(lián)合優(yōu)化的。兩者密不可分。深度學(xué)習(xí)的檢測(cè)和識(shí)別是一體的,很難割裂,從一開(kāi)始訓(xùn)練數(shù)據(jù)即是如此,語(yǔ)義級(jí)標(biāo)注是訓(xùn)練數(shù)據(jù)的最明顯特征。絕對(duì)的非監(jiān)督深度學(xué)習(xí)是不存在的,即便弱監(jiān)督深度學(xué)習(xí)都是很少的。因此視覺(jué)識(shí)別和檢測(cè)障礙物很難做到實(shí)時(shí)。而激光雷達(dá)云點(diǎn)則擅長(zhǎng)探測(cè)檢測(cè)障礙物3D輪廓,算法相對(duì)深度學(xué)習(xí)要簡(jiǎn)單的多,很容易做到實(shí)時(shí)。激光雷達(dá)擁有強(qiáng)度掃描成像,換句話說(shuō)激光雷達(dá)可以知道障礙物的密度,因此可以輕易分辨出草地,樹(shù)木,建筑物,樹(shù)葉,樹(shù)干,路燈,混凝土,車輛。這種語(yǔ)義識(shí)別非常簡(jiǎn)單,只需要根據(jù)強(qiáng)度頻譜圖即可。而視覺(jué)來(lái)說(shuō)要準(zhǔn)確的識(shí)別,非常耗時(shí)且可靠性不高。
視覺(jué)深度學(xué)習(xí)最致命的缺點(diǎn)是對(duì)視頻分析能力極弱,而無(wú)人駕駛汽車面對(duì)的視頻,不是靜態(tài)圖像。而視頻分析正是激光雷達(dá)的特長(zhǎng)。視覺(jué)深度學(xué)習(xí)在視頻分析上處于最初的起步階段,描述視頻的靜態(tài)圖像特征,可以采用從ImageNet上學(xué)習(xí)得到的深度模型;難點(diǎn)是如何描述動(dòng)態(tài)特征。以往的視覺(jué)方法中,對(duì)動(dòng)態(tài)特征的描述往往依賴于光流估計(jì),對(duì)關(guān)鍵點(diǎn)的跟蹤,和動(dòng)態(tài)紋理。如何將這些信息體現(xiàn)在深度模型中是個(gè)難點(diǎn)。最直接的做法是將視頻視為三維圖像,直接應(yīng)用卷積網(wǎng)絡(luò),在每一層學(xué)習(xí)三維濾波器。但是這一思路顯然沒(méi)有考慮到時(shí)間維和空間維的差異性。另外一種簡(jiǎn)單但更加有效的思路是通過(guò)預(yù)處理計(jì)算光流場(chǎng),作為卷積網(wǎng)絡(luò)的一個(gè)輸入通道。也有研究工作利用深度編碼器(deepautoencoder)以非線性的方式提取動(dòng)態(tài)紋理,而傳統(tǒng)的方法大多采用線性動(dòng)態(tài)系統(tǒng)建模。
光流只計(jì)算相鄰兩幀的運(yùn)動(dòng)情況,時(shí)間信息也表述不充分。two-stream只能算是個(gè)過(guò)渡方法。目前CNN搞空域,RNN搞時(shí)域已經(jīng)成共識(shí),尤其是LSTM和GRU結(jié)構(gòu)的引入。RNN在動(dòng)作識(shí)別上效果不彰,某些單幀就可識(shí)別動(dòng)作。除了大的結(jié)構(gòu)之外,一些輔助的模型,比如visual hard/softattention model,以及ICLR2016上的壓縮神經(jīng)網(wǎng)絡(luò)都會(huì)對(duì)未來(lái)的深度學(xué)習(xí)視頻處理產(chǎn)生影響。
目前深度學(xué)習(xí)對(duì)視頻分析還不如手工特征,而手工特征的缺點(diǎn),前面已經(jīng)說(shuō)過(guò),準(zhǔn)確率很低,誤報(bào)率很高。未來(lái)恐怕也難以提升。
MODAT首先要對(duì)視頻分析,實(shí)時(shí)計(jì)算出地平面,這對(duì)點(diǎn)云為主的激光雷達(dá)來(lái)說(shuō)易如反掌,對(duì)視覺(jué)來(lái)說(shuō)難比登天。
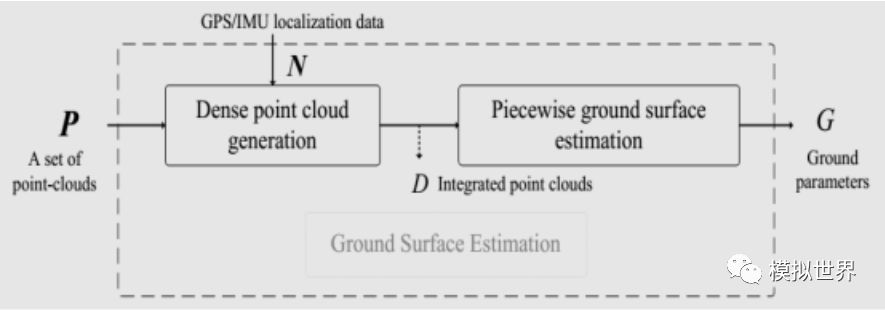
用分段平面擬合和RANSAC算法計(jì)算出真實(shí)地平面。實(shí)際單靠激光雷達(dá)的強(qiáng)度掃描成像,一樣可以得出準(zhǔn)確的地平面,這也是激光雷達(dá)用于遙感的主要原因,可以排除植被的干擾,獲得準(zhǔn)確的地形圖,大地基準(zhǔn)面。
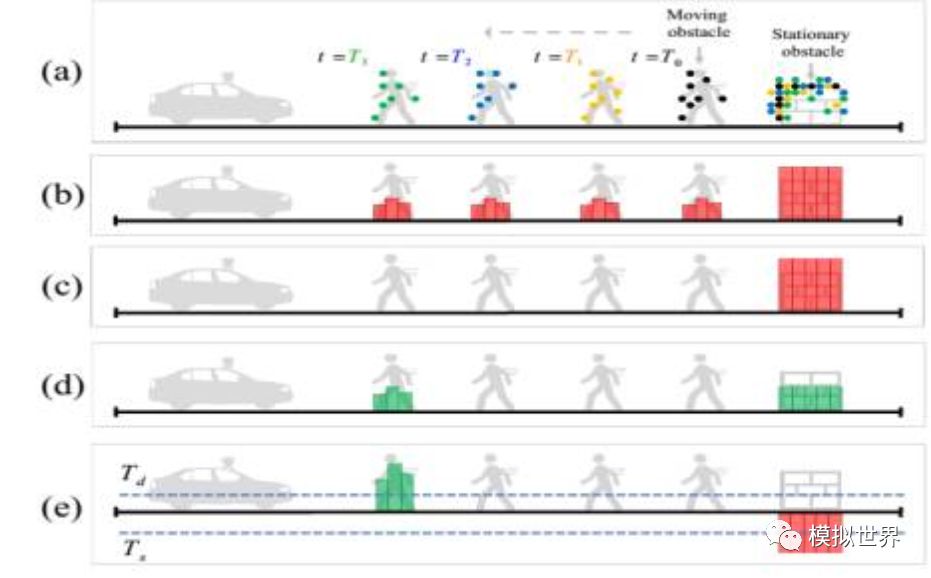
用VOXEL GRID濾波器將動(dòng)靜物體分開(kāi),黑棕藍(lán)綠是激光雷達(dá)發(fā)射到行人身上的每個(gè)時(shí)間段的假設(shè),與動(dòng)態(tài)物體比,靜態(tài)物體捕獲的點(diǎn)云數(shù)自然要多。
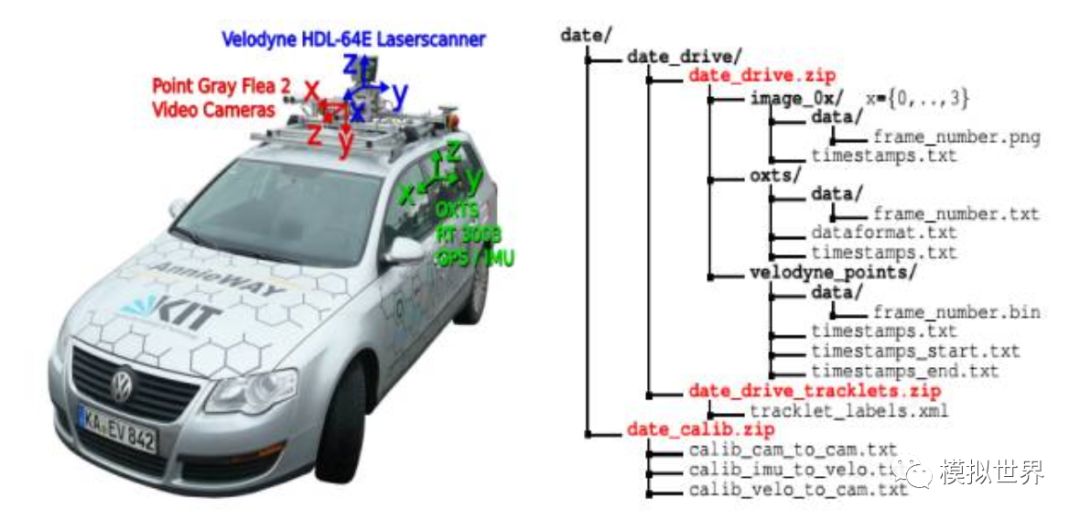
左邊是深度學(xué)習(xí)領(lǐng)域人盡皆知的權(quán)威Kitti數(shù)據(jù)集的采集車,右邊是數(shù)據(jù)集的數(shù)據(jù)格式和內(nèi)容。Kitti對(duì)其Ground Truth有一段描述:
To generate 3Dobject ground-truth we hired a set of annotators, and asked them to assigntracklets in the form of 3D bounding boxes to objects such as cars, vans,trucks,trams, pedestrians and cyclists. Unlike most existing benchmarks, we donot rely on online crowd-sourcing to perform the labeling. Towards this goal,we create a special purpose labeling tool, which displays 3D laser points aswell as the camera images to increase the quality of the annotations.
這里Kitti說(shuō)的很明確,其訓(xùn)練數(shù)據(jù)的標(biāo)簽加注不是人工眾包,而是打造了一個(gè)自動(dòng)標(biāo)簽軟件,這個(gè)軟件把3D激光云點(diǎn)像光學(xué)圖像一樣顯示出來(lái),以此來(lái)提高標(biāo)注的質(zhì)量。很簡(jiǎn)單,激光雷達(dá)是3D ObjectDetection的標(biāo)準(zhǔn),即使視覺(jué)深度學(xué)習(xí)再?gòu)?qiáng)大,與激光雷達(dá)始終有差距。
再來(lái)說(shuō)一下Stixel(sticks abovethe ground in the image), 中文一般叫棒狀像素,這是2008年由奔馳和法蘭克福大學(xué)Hern′an Badino教授推出的一種快速實(shí)時(shí)檢測(cè)障礙物的方法,尤其適合檢測(cè)行人,每秒可做到150甚至200幀,這也是奔馳和寶馬雙目的由來(lái)。Hern′an Badino后來(lái)被卡梅隆大學(xué)的機(jī)器人實(shí)驗(yàn)室挖走了,Uber的無(wú)人車主要就是基于卡梅隆大學(xué)機(jī)器人實(shí)驗(yàn)室開(kāi)發(fā)的。Stixel的核心是計(jì)算棒狀物的上下邊緣和雙目視差,構(gòu)建一個(gè)Stixel, 可以準(zhǔn)確快速地檢測(cè)障礙物,特別是行人。這是奔馳寶馬大規(guī)模使用雙目的主要原因,相對(duì)單目的行人識(shí)別,雙目Stixel擁有碾壓性優(yōu)勢(shì)。
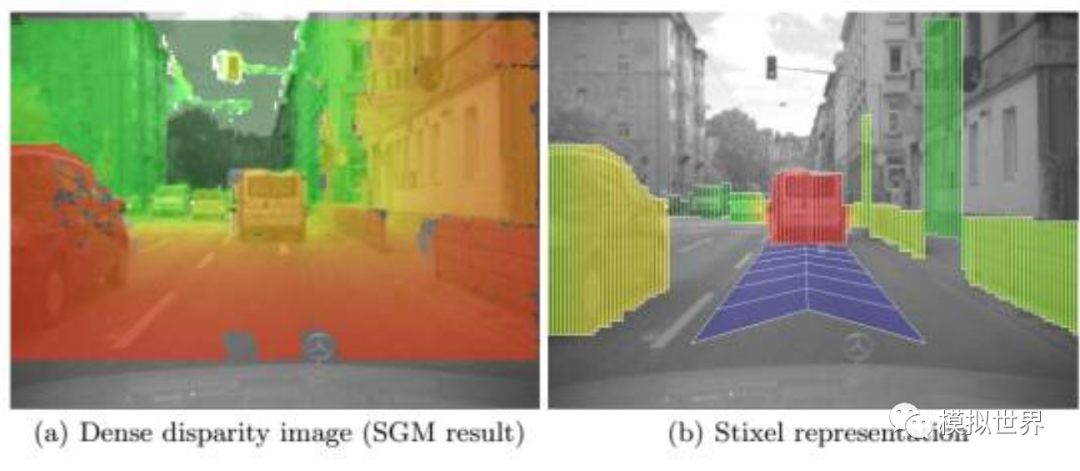
通過(guò)激光雷達(dá),可以更容易獲得相應(yīng)的3D距離信息,而且也更準(zhǔn)確,因此由此來(lái)建立Steixel也更加快捷準(zhǔn)確。
現(xiàn)在該說(shuō)Tracking了,現(xiàn)在不少人把跟蹤(tracking)和計(jì)算機(jī)視覺(jué)中的目標(biāo)跟蹤搞混了。前者更偏向數(shù)學(xué),是對(duì)狀態(tài)空間在時(shí)間上的變化進(jìn)行建模,并對(duì)下一時(shí)刻的狀態(tài)進(jìn)行預(yù)測(cè)的算法。例如卡爾曼濾波,粒子濾波等。后者則偏向應(yīng)用,給定視頻中第一幀的某個(gè)物體的框,由算法給出后續(xù)幀中該物體的位置。最初是為了解決檢測(cè)算法速度較慢的問(wèn)題,后來(lái)慢慢自成一系。因?yàn)樽兂闪藨?yīng)用問(wèn)題,所以算法更加復(fù)雜,通常由好幾個(gè)模塊組成,其中也包括數(shù)學(xué)上的tracking算法,還有提取特征,在線分類器等步驟。
在自成一系之后,目標(biāo)跟蹤實(shí)際上就變成了利用之前幾幀的物體狀態(tài)(旋轉(zhuǎn)角度,尺度),對(duì)下一幀的物體檢測(cè)進(jìn)行約束(剪枝)的問(wèn)題了。它又變回物體檢測(cè)算法了,但卻人為地把首幀得到目標(biāo)框的那步剝離出來(lái)。在各界都在努力建立end-to-end系統(tǒng)的時(shí)候,目標(biāo)跟蹤卻只去研究一個(gè)子問(wèn)題,選擇性無(wú)視"第一幀的框是怎么來(lái)的"的問(wèn)題。
激光雷達(dá)的Tracking則很容易做到,以IBEO為例,IBEO每一款激光雷達(dá)都會(huì)附送一個(gè)叫IBEOObject Tracking的軟件,這是一個(gè)基于開(kāi)曼濾波器的技術(shù),最多可實(shí)時(shí)跟蹤65個(gè)目標(biāo),是實(shí)時(shí)喲,這可是視覺(jué)類根本不敢想的事。Quanergy也有類似的軟件,叫3DPerception。
-
激光雷達(dá)
+關(guān)注
關(guān)注
967文章
3938瀏覽量
189593 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
783文章
13682瀏覽量
166136 -
環(huán)境感知
+關(guān)注
關(guān)注
0文章
24瀏覽量
7985
原文標(biāo)題:自動(dòng)駕駛技術(shù)之——環(huán)境感知
文章出處:【微信號(hào):IV_Technology,微信公眾號(hào):智車科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
未來(lái)已來(lái),多傳感器融合感知是自動(dòng)駕駛破局的關(guān)鍵
FPGA在自動(dòng)駕駛領(lǐng)域有哪些應(yīng)用?
藍(lán)牙核心技術(shù)概述
自動(dòng)駕駛真的會(huì)來(lái)嗎?
自動(dòng)駕駛的到來(lái)
無(wú)人駕駛與自動(dòng)駕駛的差別性
即插即用的自動(dòng)駕駛LiDAR感知算法盒子 RS-Box
UWB主動(dòng)定位系統(tǒng)在自動(dòng)駕駛中的應(yīng)用實(shí)踐
如何讓自動(dòng)駕駛更加安全?
自動(dòng)駕駛汽車中傳感器的分析
UWB定位可以用在自動(dòng)駕駛嗎
網(wǎng)聯(lián)化自動(dòng)駕駛的含義及發(fā)展方向
自動(dòng)駕駛系統(tǒng)設(shè)計(jì)及應(yīng)用的相關(guān)資料分享
自動(dòng)駕駛技術(shù)的實(shí)現(xiàn)
自動(dòng)駕駛發(fā)展歷史及核心技術(shù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論